
Nebula入门学习——day2 初次使用实践
快速入门¶
快速入门将介绍如何简单地使用 Nebula Graph,包括部署、连接 Nebula Graph,以及基础的增删改查操作。
文档¶
按照以下步骤可以快速部署并且使用 Nebula Graph。
-
使用 RPM 或 DEB 文件可以快速安装 Nebula Graph。关于其它部署方式及相应的准备工作,参见安装部署章节。
-
部署好 Nebula Graph 之后需要启动 Nebula Graph 服务。
-
启动 Nebula Graph 服务后即可使用客户端连接。Nebula Graph 支持多种客户端,快速入门中介绍使用原生命令行客户端 Nebula Console 连接 Nebula Graph 的方法。
-
首次连接 Nebula Graph 后需要先注册 Storage 服务才能正常查询数据。
-
注册 Storage 服务之后即可使用 nGQL(Nebula Graph Query Language)进行增删改查。
步骤 1:安装 Nebula Graph¶
RPM 和 DEB 是 Linux 系统下常见的两种安装包格式,本文介绍如何使用 RPM 或 DEB 文件在一台机器上快速安装 Nebula Graph。
Note
部署 Nebula Graph 集群的方式参见使用 RPM/DEB 包部署集群。
Enterpriseonly
企业版请发送邮件至 inquiry@vesoft.com。
前提条件¶
安装 wget
下载安装包¶
-
下载适用于
ubuntu 1804的3.1.0安装包:wget https://oss-cdn.nebula-graph.com.cn/package/3.1.0/nebula-graph-3.1.0.ubuntu1804.amd64.deb wget https://oss-cdn.nebula-graph.com.cn/package/3.1.0/nebula-graph-3.1.0.ubuntu1804.amd64.deb.sha256sum.txt
安装 Nebula Graph¶
-
例如安装3.1.0版本的 DEB 包:
sudo dpkg -i nebula-graph-3.1.0.ubuntu1804.amd64.deb步骤 2:启动 Nebula Graph 服务¶
Nebula Graph 支持通过脚本或 systemd 管理服务。本文详细介绍这两种方式。
Enterpriseonly
仅企业版支持使用 systemd 管理服务。
Danger
这两种方式互不兼容,选择使用其中一种。
使用脚本管理服务¶
使用脚本
nebula.service管理服务,包括启动、停止、重启、中止和查看。Note
nebula.service的默认路径是/usr/local/nebula/scripts,如果修改过安装路径,请使用实际路径。语法¶
$ sudo /usr/local/nebula/scripts/nebula.service [-v] [-c <config_file_path>] <start | stop | restart | kill | status> <metad | graphd | storaged | all>参数 说明 -v显示详细调试信息。 -c指定配置文件路径,默认路径为 /usr/local/nebula/etc/。start启动服务。 stop停止服务。 restart重启服务。 kill中止服务。 status查看服务状态。 metad管理 Meta 服务。 graphd管理 Graph 服务。 storaged管理 Storage 服务。 all管理所有服务。
启动 Nebula Graph 服务¶
非容器部署¶
对于非容器部署的 Nebula Graph,执行如下命令启动服务:
$ sudo /usr/local/nebula/scripts/nebula.service start all [INFO] Starting nebula-metad... [INFO] Done [INFO] Starting nebula-graphd... [INFO] Done [INFO] Starting nebula-storaged... [INFO] Done或者:
$ systemctl start nebula如果需要设置开机自动启动,命令如下:
$ systemctl enable nebula停止 Nebula Graph 服务¶
Danger
请勿使用
kill -9命令强制终止进程,否则可能较小概率出现数据丢失。非容器部署¶
执行如下命令停止 Nebula Graph 服务:
$ sudo /usr/local/nebula/scripts/nebula.service stop all [INFO] Stopping nebula-metad... [INFO] Done [INFO] Stopping nebula-graphd... [INFO] Done [INFO] Stopping nebula-storaged... [INFO] Done或者:
$ systemctl stop nebula查看 Nebula Graph 服务¶
非容器部署¶
执行如下命令查看 Nebula Graph 服务状态:
$ sudo /usr/local/nebula/scripts/nebula.service status all-
如果返回如下结果,表示 Nebula Graph 服务正常运行。
[INFO] nebula-metad(33fd35e): Running as 29020, Listening on 9559 [INFO] nebula-graphd(33fd35e): Running as 29095, Listening on 9669 [WARN] nebula-storaged after v3.0.0 will not start service until it is added to cluster. [WARN] See Manage Storage hosts:ADD HOSTS in https://docs.nebula-graph.io/ [INFO] nebula-storaged(33fd35e): Running as 29147, Listening on 9779Note
正常启动 Nebula Graph 后,
nebula-storaged进程的端口显示红色。这是因为nebula-storaged在启动流程中会等待nebula-metad添加当前 Storage 服务,当前 Storage 服务收到 Ready 信号后才会正式启动服务。从 3.0.0 版本开始,在配置文件中添加的 Storage 节点无法直接读写,配置文件的作用仅仅是将 Storage 节点注册至 Meta 服务中。必须使用ADD HOSTS命令后,才能正常读写 Storage 节点。更多信息,参见管理 Storage 主机。
- 如果返回类似如下结果,表示 Nebula Graph 服务异常,可以根据异常服务信息进一步排查,或者在 Nebula Graph 社区寻求帮助。
[INFO] nebula-metad: Running as 25600, Listening on 9559 [INFO] nebula-graphd: Exited [INFO] nebula-storaged: Running as 25646, Listening on 9779
也可以使用
systemctl命令查看 Nebula Graph 服务状态:$ systemctl status nebula ● nebula.service Loaded: loaded (/usr/lib/systemd/system/nebula.service; disabled; vendor preset: disabled) Active: active (exited) since 一 2022-03-28 04:13:24 UTC; 1h 47min ago Process: 21772 ExecStart=/usr/local/ent-nightly/scripts/nebula.service start all (code=exited, status=0/SUCCESS) Main PID: 21772 (code=exited, status=0/SUCCESS) Tasks: 325 Memory: 424.5M CGroup: /system.slice/nebula.service ├─21789 /usr/local/ent-nightly/bin/nebula-metad --flagfile /usr/local/ent-nightly/etc/nebula-metad.conf ├─21827 /usr/local/ent-nightly/bin/nebula-graphd --flagfile /usr/local/ent-nightly/etc/nebula-graphd.conf └─21900 /usr/local/ent-nightly/bin/nebula-storaged --flagfile /usr/local/ent-nightly/etc/nebula-storaged.conf 3月 28 04:13:24 xxxxxx systemd[1]: Started nebula.service. ...Nebula Graph 服务由 Meta 服务、Graph 服务和 Storage 服务共同提供,这三种服务的配置文件都保存在安装目录的
etc目录内,默认路径为/usr/local/nebula/etc/,用户可以检查相应的配置文件排查问题。 -
-
步骤 3:连接 Nebula Graph¶
-
本文介绍如何使用原生命令行客户端 Nebula Console 连接 Nebula Graph。
Caution
首次连接到 Nebula Graph 后,必须先注册 Storage 服务,才能正常查询数据。
Nebula Graph 支持多种类型的客户端,包括命令行客户端、可视化界面客户端和流行编程语言客户端。详情参见客户端列表。
前提条件¶
- Nebula Graph 服务已启动。
- 运行 Nebula Console 的机器和运行 Nebula Graph 的服务器网络互通。
-
Nebula Console 的版本兼容 Nebula Graph 的版本。
Note
版本相同的 Nebula Console 和 Nebula Graph 兼容程度最高,版本不同的 Nebula Console 连接 Nebula Graph 时,可能会有兼容问题,或者无法连接并报错
incompatible version between client and server。
操作步骤¶
-
在 Nebula Console 下载页面,确认需要的版本,单击 Assets。
Note
建议选择最新版本。
-
在 Assets 区域找到机器运行所需的二进制文件,下载文件到机器上。
-
(可选)为方便使用,重命名文件为
nebula-console。Note
在 Windows 系统中,请重命名为
nebula-console.exe。 -
在运行 Nebula Console 的机器上执行如下命令,为用户授予 nebula-console 文件的执行权限。
Note
Windows 系统请跳过此步骤。
-
$ chmod 111 nebula-console -
在命令行界面中,切换工作目录至 nebula-console 文件所在目录。
-
执行如下命令连接 Nebula Graph。
-
Linux 或 macOS
-
-
$ ./nebula-console -addr <ip> -port <port> -u <username> -p <password> [-t 120] [-e "nGQL_statement" | -f filename.nGQL] -
Windows
-
> nebula-console.exe -addr <ip> -port <port> -u <username> -p <password> [-t 120] [-e "nGQL_statement" | -f filename.nGQL]
参数说明如下。
| 参数 | 说明 |
|---|---|
-h/-help |
显示帮助菜单。 |
-addr/-address |
设置要连接的 Graph 服务的 IP 地址。默认地址为 127.0.0.1。如果 Nebula Graph 部署在 Nebula Cloud 上,需要创建 Private Link,并设置该参数的值为专用终结点的 IP 地址。 |
-P/-port |
设置要连接的 Graph 服务的端口。默认端口为 9669。 |
-u/-user |
设置 Nebula Graph 账号的用户名。未启用身份认证时,可以使用任意已存在的用户名(默认为root)。 |
-p/-password |
设置用户名对应的密码。未启用身份认证时,密码可以填写任意字符。 |
-t/-timeout |
设置整数类型的连接超时时间。单位为秒,默认值为 120。 |
-e/-eval |
设置字符串类型的 nGQL 语句。连接成功后会执行一次该语句并返回结果,然后自动断开连接。 |
-f/-file |
设置存储 nGQL 语句的文件的路径。连接成功后会执行该文件内的 nGQL 语句并返回结果,执行完毕后自动断开连接。 |
-enable_ssl |
连接 Nebula Graph 时使用 SSL 加密。 |
-ssl_root_ca_path |
指定 CA 证书的存储路径。 |
-ssl_cert_path |
指定 CRT 证书的存储路径。 |
-ssl_private_key_path |
指定私钥文件的存储路径。 |
更多参数参见项目仓库。
我的连接方式:
bonelee@bonelee-VirtualBox:~/Desktop$ ./nebula-console-linux-amd64-v3.0.0 -addr localhost -P 9669 -u root -p root Welcome to Nebula Graph! (root@nebula) [(none)]>
因为他说了首次密码随便设置。。。
-
注册 Storage 服务¶
首次连接到 Nebula Graph 后,需要先添加 Storage 主机,并确认主机都处于在线状态。
Compatibility
- 从 Nebula Graph 3.0.0 版本开始,必须先使用
ADD HOSTS添加主机,才能正常通过 Storage 服务读写数据。 - 在此前的版本中,无需执行该操作。
前提条件¶
操作步骤¶
-
添加 Storage 主机。
执行如下命令添加主机:
ADD HOSTS <ip>:<port> [,<ip>:<port> ...];示例:
- 从 Nebula Graph 3.0.0 版本开始,必须先使用
-
nebula> ADD HOSTS 192.168.10.100:9779, 192.168.10.101:9779, 192.168.10.102:9779;Caution
请确保添加的主机 IP 和配置文件
nebula-storaged.conf中local_ip配置的 IP 一致,否则会导致添加 Storage 主机失败。关于配置文件的详情,参见配置管理。 -
检查主机状态,确认全部在线。
nebula> SHOW HOSTS;
+------------------+------+-----------+----------+--------------+---------------------- +------------------------+---------+
| Host | Port | HTTP port | Status | Leader count | Leader distribution | Partition distribution | Version |
+------------------+------+-----------+----------+--------------+---------------------- +------------------------+---------+
| "192.168.10.100" | 9779 | 19669 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.1.0" |
| "192.168.10.101" | 9779 | 19669 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.1.0" |
| "192.168.10.102" | 9779 | 19669 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.1.0" |
+------------------+------+-----------+----------+--------------+---------------------- +------------------------+---------+
在返回结果的 Status 列,可以看到所有 Storage 主机都在线。
(root@nebula) [(none)]> ADD HOSTS 127.0.0.1:9779 Execution succeeded (time spent 725/994 us) Mon, 23 May 2022 21:40:57 CST
(root@nebula) [(none)]> show hosts +-------------+------+-----------+----------+--------------+----------------------+------------------------+---------+ | Host | Port | HTTP port | Status | Leader count | Leader distribution | Partition distribution | Version | +-------------+------+-----------+----------+--------------+----------------------+------------------------+---------+ | "127.0.0.1" | 9779 | 19669 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.1.0" | +-------------+------+-----------+----------+--------------+----------------------+------------------------+---------+ Got 1 rows (time spent 480/803 us) Mon, 23 May 2022 21:41:59 CST
步骤 4:使用常用 nGQL(CRUD 命令)¶
本文介绍 Nebula Graph 查询语言的基础语法,包括用于 Schema 创建和常用增删改查操作的语句。
如需了解更多语句的用法,参见 nGQL 指南。
图空间和 Schema¶
一个 Nebula Graph 实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。
为了在图空间中插入数据,需要为图数据库定义一个 Schema。Nebula Graph 的 Schema 是由如下几部分组成。
| 组成部分 | 说明 |
|---|---|
| 点(Vertex) | 表示现实世界中的实体。一个点可以有 0 到多个标签。 |
| 标签(Tag) | 点的类型,定义了一组描述点类型的属性。 |
| 边(Edge) | 表示两个点之间有方向的关系。 |
| 边类型(Edge type) | 边的类型,定义了一组描述边的类型的属性。 |
更多信息,请参见数据结构。
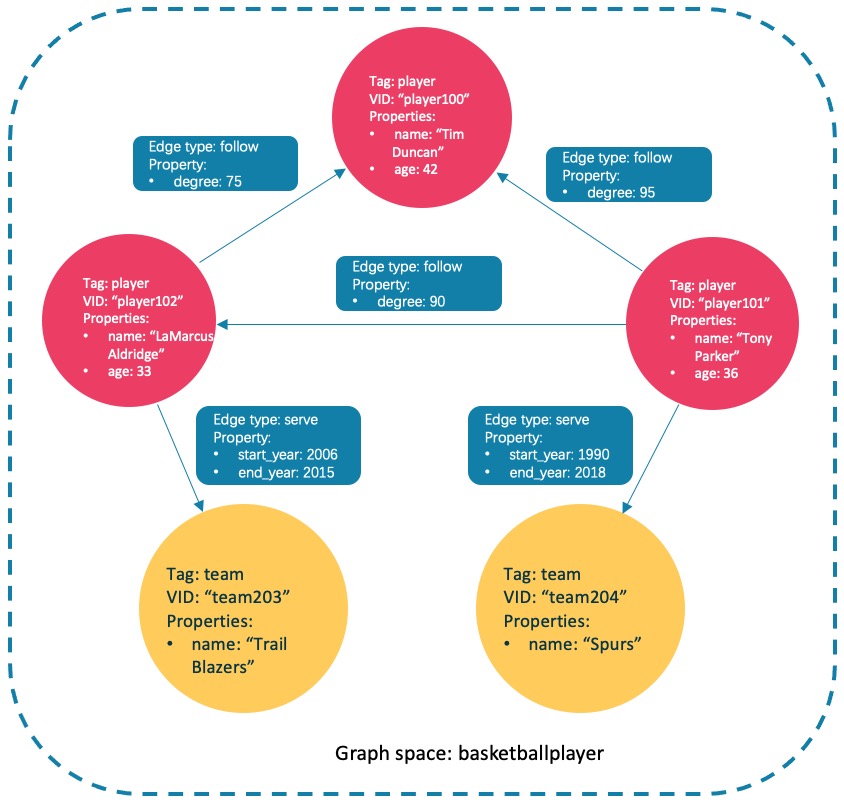
本文将使用下图的数据集演示基础操作的语法。
异步实现创建和修改¶
Caution
Nebula Graph 中执行如下创建和修改操作,是异步实现的。要在下一个心跳周期之后才能生效,否则访问会报错。为确保数据同步,后续操作能顺利进行,请等待 2 个心跳周期(20 秒)。==》这种让用户等待的操作设计很蛋疼啊!!!
CREATE SPACECREATE TAGCREATE EDGEALTER TAGALTER EDGECREATE TAG INDEXCREATE EDGE INDEX
Note
默认心跳周期是 10 秒。修改心跳周期参数heartbeat_interval_secs,请参见配置简介。
创建和选择图空间¶
nGQL 语法¶
- 创建图空间
-
CREATE SPACE [IF NOT EXISTS] <graph_space_name> ( [partition_num = <partition_number>,] [replica_factor = <replica_number>,] vid_type = {FIXED_STRING(<N>) | INT64} ) [COMMENT = '<comment>'];参数详情请参见 CREATE SPACE。
- 列出创建成功的图空间
-
nebula> SHOW SPACES;
- 选择数据库
-
USE <graph_space_name>;
酱紫:(root@nebula) [(none)]> CREATE SPACE basketballplayer (vid_type=FIXED_STRING(32)); Execution succeeded (time spent 3881/4059 us) Mon, 23 May 2022 21:50:30 CST (root@nebula) [(none)]> show spaces; +--------------------+ | Name | +--------------------+ | "basketballplayer" | +--------------------+ Got 1 rows (time spent 450/777 us) Mon, 23 May 2022 21:50:36 CST (root@nebula) [(none)]> USE basketballplayer; Execution succeeded (time spent 575/785 us) Mon, 23 May 2022 21:50:43 CST
示例¶
-
执行如下语句创建名为
basketballplayer的图空间。==》逗我呢!!!要在前面先创建space。。。
nebula[(none)]> USE basketballplayer;
用户可以执行命令SHOW SPACES查看创建的图空间。
-
nebula> SHOW SPACES; +--------------------+ | Name | +--------------------+ | "basketballplayer" | +--------------------+
创建 Tag 和 Edge type¶
nGQL 语法¶
CREATE {TAG | EDGE} [IF NOT EXISTS] {<tag_name> | <edge_type_name>}
(
<prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];
参数详情请参见 CREATE TAG 和 CREATE EDGE。
示例¶
创建 Tag:player和team,以及 Edge type:follow和serve。说明如下表。
| 名称 | 类型 | 属性 |
|---|---|---|
| player | Tag | name (string), age (int) |
| team | Tag | name (string) |
| follow | Edge type | degree (int) |
| serve | Edge type | start_year (int), end_year (int) |
nebula> CREATE TAG player(name string, age int);
nebula> CREATE TAG team(name string);
nebula> CREATE EDGE follow(degree int);
nebula> CREATE EDGE serve(start_year int, end_year int);
插入点和边¶
用户可以使用INSERT语句,基于现有的 Tag 插入点,或者基于现有的 Edge type 插入边。
nGQL 语法¶
- 插入点
-
INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...] VALUES <vid>: ([prop_value_list]) tag_props: tag_name ([prop_name_list]) prop_name_list: [prop_name [, prop_name] ...] prop_value_list: [prop_value [, prop_value] ...]vid是 Vertex ID 的缩写,vid在一个图空间中是唯一的。参数详情请参见 INSERT VERTEX。
- 插入边
-
INSERT EDGE [IF NOT EXISTS] <edge_type> ( <prop_name_list> ) VALUES <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ) [, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...]; <prop_name_list> ::= [ <prop_name> [, <prop_name> ] ...] <prop_value_list> ::= [ <prop_value> [, <prop_value> ] ...]参数详情请参见 INSERT EDGE。
示例¶
- 插入代表球员和球队的点。
-
nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42); nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36); nebula> INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33); nebula> INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
- 插入代表球员和球队之间关系的边。
-
nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95); nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90); nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75); nebula> INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
查询数据¶
- GO 语句可以根据指定的条件遍历数据库。
GO语句从一个或多个点开始,沿着一条或多条边遍历,返回YIELD子句中指定的信息。
- FETCH 语句可以获得点或边的属性。
nGQL 语法¶
GO
-
GO [[<M> TO] <N> STEPS ] FROM <vertex_list> OVER <edge_type_list> [{REVERSELY | BIDIRECT}] [ WHERE <conditions> ] YIELD [DISTINCT] <return_list> [{ SAMPLE <sample_list> | <limit_by_list_clause> }] [| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>] [| ORDER BY <expression> [{ASC | DESC}]] [| LIMIT [<offset>,] <number_rows>];
-
FETCH-
查询 Tag 属性
-
-
FETCH PROP ON {<tag_name>[, tag_name ...] | *} <vid> [, vid ...] YIELD <return_list> [AS <alias>];
-
查询边属性
-
-
FETCH PROP ON <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid> ...] YIELD <output>;
-
LOOKUP
-
LOOKUP ON {<vertex_tag> | <edge_type>} [WHERE <expression> [AND <expression> ...]] YIELD <return_list> [AS <alias>]; <return_list> <prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];
MATCH
-
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
GO语句示例¶
- 从 VID 为
player101的球员开始,沿着边follow找到连接的球员。
-
nebula> GO FROM "player101" OVER follow YIELD id($$); +-------------+ | id($$) | +-------------+ | "player100" | | "player102" | | "player125" | ==》逗我呢,这个数据都没有!!!我的返回仅前面2个数据!!! +-------------+
- 从 VID 为
player101的球员开始,沿着边follow查找年龄大于或等于 35 岁的球员,并返回他们的姓名和年龄,同时重命名对应的列。
-
nebula> GO FROM "player101" OVER follow WHERE properties($$).age >= 35 \ YIELD properties($$).name AS Teammate, properties($$).age AS Age; +-----------------+-----+ | Teammate | Age | +-----------------+-----+ | "Tim Duncan" | 42 | | "Manu Ginobili" | 41 | +-----------------+-----+子句/符号 说明 YIELD指定该查询需要返回的值或结果。 $$表示边的终点。==》这解释蛋疼,不就是图的节点V吗! \表示换行继续输入。
-
从 VID 为
player101的球员开始,沿着边follow查找连接的球员,然后检索这些球员的球队。为了合并这两个查询请求,可以使用管道符或临时变量。-
使用管道符
-
-
nebula> GO FROM "player101" OVER follow YIELD dst(edge) AS id | \ GO FROM $-.id OVER serve YIELD properties($$).name AS Team, \ properties($^).name AS Player; +-----------------+---------------------+ | Team | Player | +-----------------+---------------------+ | "Spurs" | "Tim Duncan" | | "Trail Blazers" | "LaMarcus Aldridge" | | "Spurs" | "LaMarcus Aldridge" | | "Spurs" | "Manu Ginobili" | +-----------------+---------------------+子句/符号 说明 $^表示边的起点。 |组合多个查询的管道符,将前一个查询的结果集用于后一个查询。==>interesting!!! $-表示管道符前面的查询输出的结果集。
-
使用临时变量
Note
当复合语句作为一个整体提交给服务器时,其中的临时变量会在语句结束时被释放。
-
-
nebula> $var = GO FROM "player101" OVER follow YIELD dst(edge) AS id; \ GO FROM $var.id OVER serve YIELD properties($$).name AS Team, \ properties($^).name AS Player; +-----------------+---------------------+ | Team | Player | +-----------------+---------------------+ | "Spurs" | "Tim Duncan" | | "Trail Blazers" | "LaMarcus Aldridge" | | "Spurs" | "LaMarcus Aldridge" | | "Spurs" | "Manu Ginobili" | +-----------------+---------------------+
我这边的返回结果如下:为啥?因为只有player102才有server球队!player100毛都没有!(root@nebula) [basketballplayer]> GO FROM "player101" OVER follow YIELD dst(edge) AS id +-------------+ | id | +-------------+ | "player100" | | "player102" | +-------------+ Got 2 rows (time spent 514/740 us) Mon, 23 May 2022 22:05:34 CST (root@nebula) [basketballplayer]> GO FROM "player101" OVER follow YIELD dst(edge) AS id | \ -> GO FROM $-.id OVER serve YIELD properties($$).name AS Team, \ -> properties($^).name AS Player; +-----------------+---------------------+ | Team | Player | +-----------------+---------------------+ | "Trail Blazers" | "LaMarcus Aldridge" | +-----------------+---------------------+ Got 1 rows (time spent 1455/1716 us) Mon, 23 May 2022 22:06:26 CST
-
FETCH语句示例¶
查询 VID 为player100的球员的属性。
nebula> FETCH PROP ON player "player100" YIELD properties(vertex);
+-------------------------------+
| properties(VERTEX) |
+-------------------------------+
| {age: 42, name: "Tim Duncan"} |
+-------------------------------+
Note
LOOKUP和MATCH的示例在下文的索引 部分查看。
修改点和边¶
用户可以使用UPDATE语句或UPSERT语句修改现有数据。
UPSERT是UPDATE和INSERT的结合体。当使用UPSERT更新一个点或边,如果它不存在,数据库会自动插入一个新的点或边。
Note
每个 partition 内部,UPSERT 操作是一个串行操作,所以执行速度比执行 INSERT 或 UPDATE 慢很多。其仅在多个 partition 之间有并发。
nGQL 语法¶
UPDATE点
-
UPDATE VERTEX <vid> SET <properties to be updated> [WHEN <condition>] [YIELD <columns>];
UPDATE边
-
UPDATE EDGE <source vid> -> <destination vid> [@rank] OF <edge_type> SET <properties to be updated> [WHEN <condition>] [YIELD <columns to be output>];
UPSERT点或边
-
UPSERT {VERTEX <vid> | EDGE <edge_type>} SET <update_columns> [WHEN <condition>] [YIELD <columns>];
示例¶
- 用
UPDATE修改 VID 为player100的球员的name属性,然后用FETCH语句检查结果。
-
nebula> UPDATE VERTEX "player100" SET player.name = "Tim"; nebula> FETCH PROP ON player "player100" YIELD properties(vertex); +------------------------+ | properties(VERTEX) | +------------------------+ | {age: 42, name: "Tim"} | +------------------------+
- 用
UPDATE修改某条边的degree属性,然后用FETCH检查结果。
-
nebula> UPDATE EDGE "player101" -> "player100" OF follow SET degree = 96; nebula> FETCH PROP ON follow "player101" -> "player100" YIELD properties(edge); +------------------+ | properties(EDGE) | +------------------+ | {degree: 96} | +------------------+(root@nebula) [basketballplayer]> FETCH PROP ON follow "player101" -> "player100" YIELD properties(edge); +------------------+ | properties(EDGE) | +------------------+ | {degree: 95} | +------------------+ Got 1 rows (time spent 717/1043 us) Mon, 23 May 2022 22:11:36 CST (root@nebula) [basketballplayer]> UPDATE EDGE "player101" -> "player100" OF follow SET degree = 96; Execution succeeded (time spent 933/1134 us) Mon, 23 May 2022 22:11:46 CST (root@nebula) [basketballplayer]> FETCH PROP ON follow "player101" -> "player100" YIELD properties(edge); +------------------+ | properties(EDGE) | +------------------+ | {degree: 96} | +------------------+ Got 1 rows (time spent 730/998 us) Mon, 23 May 2022 22:11:51 CST
- 用
INSERT插入一个 VID 为player111的点,然后用UPSERT更新它。
-
nebula> INSERT VERTEX player(name,age) VALUES "player111":("David West", 38); nebula> UPSERT VERTEX "player111" SET player.name = "David", player.age = $^.player.age + 11 \ WHEN $^.player.name == "David West" AND $^.player.age > 20 \ YIELD $^.player.name AS Name, $^.player.age AS Age; +---------+-----+ | Name | Age | +---------+-----+ | "David" | 49 | +---------+-----+
删除点和边¶
nGQL 语法¶
- 删除点
-
DELETE VERTEX <vid1>[, <vid2>...]
- 删除边
-
DELETE EDGE <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid>...]
示例¶
- 删除点
-
nebula> DELETE VERTEX "player111", "team203";
- 删除边
-
nebula> DELETE EDGE follow "player101" -> "team204";
索引¶
用户可以通过 CREATE INDEX 语句为 Tag 和 Edge type 增加索引。
使用索引必读
MATCH和LOOKUP语句的执行都依赖索引,但是索引会导致写性能大幅降低(降低 90%甚至更多)。请不要随意在生产环境中使用索引,除非很清楚使用索引对业务的影响。
必须为“已写入但未构建索引”的数据重建索引,否则无法在MATCH和LOOKUP语句中返回这些数据。参见重建索引。
nGQL 语法¶
- 创建索引
-
CREATE {TAG | EDGE} INDEX [IF NOT EXISTS] <index_name> ON {<tag_name> | <edge_name>} ([<prop_name_list>]) [COMMENT = '<comment>'];
- 重建索引
-
REBUILD {TAG | EDGE} INDEX <index_name>;
Note
为没有指定长度的变量属性创建索引时,需要指定索引长度。在 utf-8 编码中,一个中文字符占 3 字节,请根据变量属性长度设置合适的索引长度。例如 10 个中文字符,索引长度需要为 30。详情请参见创建索引。
基于索引的LOOKUP和MATCH示例¶
确保LOOKUP或MATCH有一个索引可用。如果没有,请先创建索引。
找到 Tag 为player的点的信息,它的name属性值为Tony Parker。
// 为 name 属性创建索引 player_index_1。
nebula> CREATE TAG INDEX IF NOT EXISTS player_index_1 ON player(name(20)); ==》因为要搜索player.name的话,肯定是没有索引的,只有vid才建立了索引。。。
// 重建索引确保能对已存在数据生效。
nebula> REBUILD TAG INDEX player_index_1
+------------+
| New Job Id |
+------------+
| 31 |
+------------+
// 使用 LOOKUP 语句检索点的属性。
nebula> LOOKUP ON player WHERE player.name == "Tony Parker" \
YIELD properties(vertex).name AS name, properties(vertex).age AS age;
+---------------+-----+
| name | age |
+---------------+-----+
| "Tony Parker" | 36 |
+---------------+-----+
// 使用 MATCH 语句检索点的属性。
nebula> MATCH (v:player{name:"Tony Parker"}) RETURN v;
+-----------------------------------------------------+
| v |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+-
nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); -
执行命令
SHOW HOSTS检查分片的分布情况,确保平衡分布。 -
nebula> SHOW HOSTS; +-------------+-----------+-----------+-----------+--------------+----------------------------------+------------------------+---------+ | Host | Port | HTTP port | Status | Leader count | Leader distribution | Partition distribution | Version | +-------------+-----------+-----------+-----------+--------------+----------------------------------+------------------------+---------+ | "storaged0" | 9779 | 19669 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | "3.1.0" | | "storaged1" | 9779 | 19669 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | "3.1.0" | | "storaged2" | 9779 | 19669 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | "3.1.0" | +-------------+-----------+-----------+-----------+--------------+----------------------------------+------------------------+---------+如果 Leader distribution 分布不均匀,请执行命令
BALANCE LEADER重新分配。更多信息,请参见 Storage 负载均衡。 -
选择图空间
basketballplayer。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号