
万字综述 | 一文读懂知识蒸馏
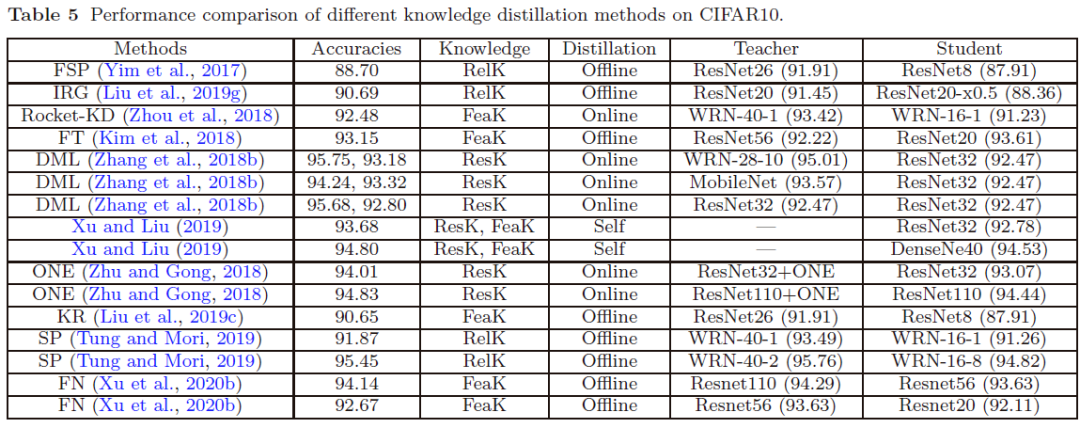
看这个图,就知道现在知识蒸馏的大致做法了。差不多就是在做模型裁剪,有时候我也觉得奇怪,按理说老师教学生不应该青出于蓝而胜于蓝吗?从这里看,student模型除了性能有优势,精确率是没有优势的。
万字综述 | 一文读懂知识蒸馏
知识蒸馏综述
本文梳理了用于简单分类任务的各种知识蒸馏(KD)策略,并实现了一系列经典的知识蒸馏技术。
- 知识蒸馏论文综述: Knowledge Distillation: A Survey
- 知识蒸馏论文分类: https://github.com/FLHonker/Awesome-Knowledge-Distillation
摘要
近年来,深度神经网络在工业界和学术界都取得了成功,尤其是在计算机视觉任务方面。深度学习的巨大成功主要归因于其可扩展性以编码大规模数据并操纵数十亿个模型参数。但是,将这些繁琐的深度模型部署在资源有限的设备(例如,移动电话和嵌入式设备)上是一个挑战,这不仅是因为计算复杂性高,而且还有庞大的存储需求。为此,已经开发了多种模型压缩和加速技术。作为模型压缩和加速的代表类型,知识蒸馏有效地从大型教师模型中学习小型学生模型。它已迅速受到业界的关注。本文从知识类别,训练框架,师生架构,蒸馏算法,性能比较和应用的角度对知识蒸馏进行了全面的调查。此外,简要概述了知识蒸馏中的挑战,并讨论和转发了对未来研究的评论。

知识蒸馏简介
知识蒸馏,已经受到业界越来越多的关注。大型深度模型在实践中往往会获得良好的性能,因为当考虑新数据时,过度参数化会提高泛化性能。在知识蒸馏中,小模型(学生模型)通常是由一个大模型(教师模型)监督,算法的关键问题是如何从老师模型转换的知识传授给学生模型。一个知识蒸馏系统由三个主要部分组成:知识,蒸馏算法,和师生架构。

知识蒸馏框架
用于模型压缩的知识蒸馏类似于人类学习的方式。受此启发,最近的知识蒸馏方法已扩展到师生学习,相互学习,辅助教学,终身学习和自学。知识蒸馏的大多数扩展都集中在压缩深度神经网络上。由此产生的轻量级学生网络可以轻松部署在视觉识别,语音识别和自然语言处理(NLP)等应用程序中。此外,知识蒸馏中的知识从一种模型到另一种模型的转移可以扩展到其他任务,例如对抗攻击,数据增强,数据隐私和安全性。通过知识蒸馏的动机进行模型压缩,知识转移的思想已被进一步用于压缩训练数据,即数据集蒸馏,这将知识从大型数据集转移到小型数据集以减轻深度模型的训练负担。
早期知识蒸馏框架通常包含一个或多个大型的预训练教师模型和小型的学生模型。教师模型通常比学生模型大得多。主要思想是在教师模型的指导下训练高效的学生模型以获得相当的准确性。来自教师模型的监督信号(通常称为教师模型学到的“知识”)可以帮助学生模型模仿教师模型的行为。

在典型的图像分类任务中,logit(例如深层神经网络中最后一层的输出)被用作教师模型中知识的载体,而训练数据样本未明确提供该模型。例如,猫的图像被错误地归类为狗的可能性非常低,但是这种错误的可能性仍然比将猫误认为汽车的可能性高很多倍。另一个示例是,手写数字2的图像与数字3相比,与数字7更相似。这种由教师模型学习的知识也称为暗知识(“dark knowledge”)。
早期的知识蒸馏中转移 dark knowledge 的方法如下。给定对数向量
z作为深度模型的最后一个全连接层的输出,则
zi是第 i 类的对数,则输入属于第 i 类的概率
pi可以为 由softmax 函数估算:
pi=exp(zi)∑jexp(zj)因此,通过教师模型获得的软目标的预测包含暗知识,并且可以用作监督者,以将知识从教师模型转移到学生模型。同样,one-hot 标签也称为硬目标。关于软目标和硬目标的直观示例如图3所示。此外,引入温度因子T来控制每个软目标的重要性:
pi=exp(zi/T)∑jexp(zj/T)较高的温度会在各个类别上产生较弱的概率分布。具体来说,当
T→∞时,所有类别都具有相同的概率。当
T→0时,软目标变为 one-hot 标记,即硬目标。教师模型提供的软目标(distillation loss)和ground-truth label提供的硬目标(student loss)对于提高学生模型的绩效都非常重要。
定义蒸馏损失以匹配教师模型和学生模型之间的 logits ,即:
LD(p(zt,T),p(zs,T))=∑i−pi(zti,T)log(pi(zsi,T))其中
zt和
zs分别是教师和学生模型的logits。教师模型的logits通过交叉熵梯度与学生模型的 logits 匹配, 然后可以将相对于 logit
zsi的梯度评估为:
∂LD(p(zt,T),p(zs,T))∂zsi=pi(zsi,T)−pi(zti,T)T=1T(exp(zsi/T)∑jexp(zs