
yulong-hids 规则引擎,目前看到就是正则表达式和count技术
规则
项目提供的默认规则太简单和宽泛了,甚至包含一些错误,比如:

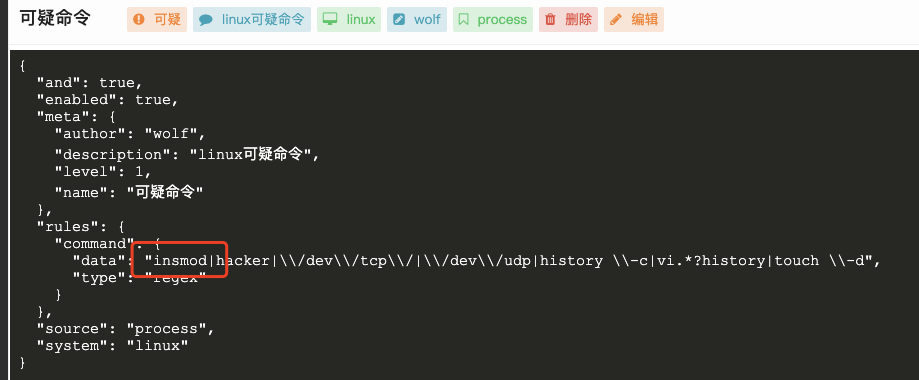
有些不太精确,比如:

另外规则引擎的匹配算法没有做优化,规则或者事件一旦多起来,server的负载会很高
有些太宽泛导致误报非常高:
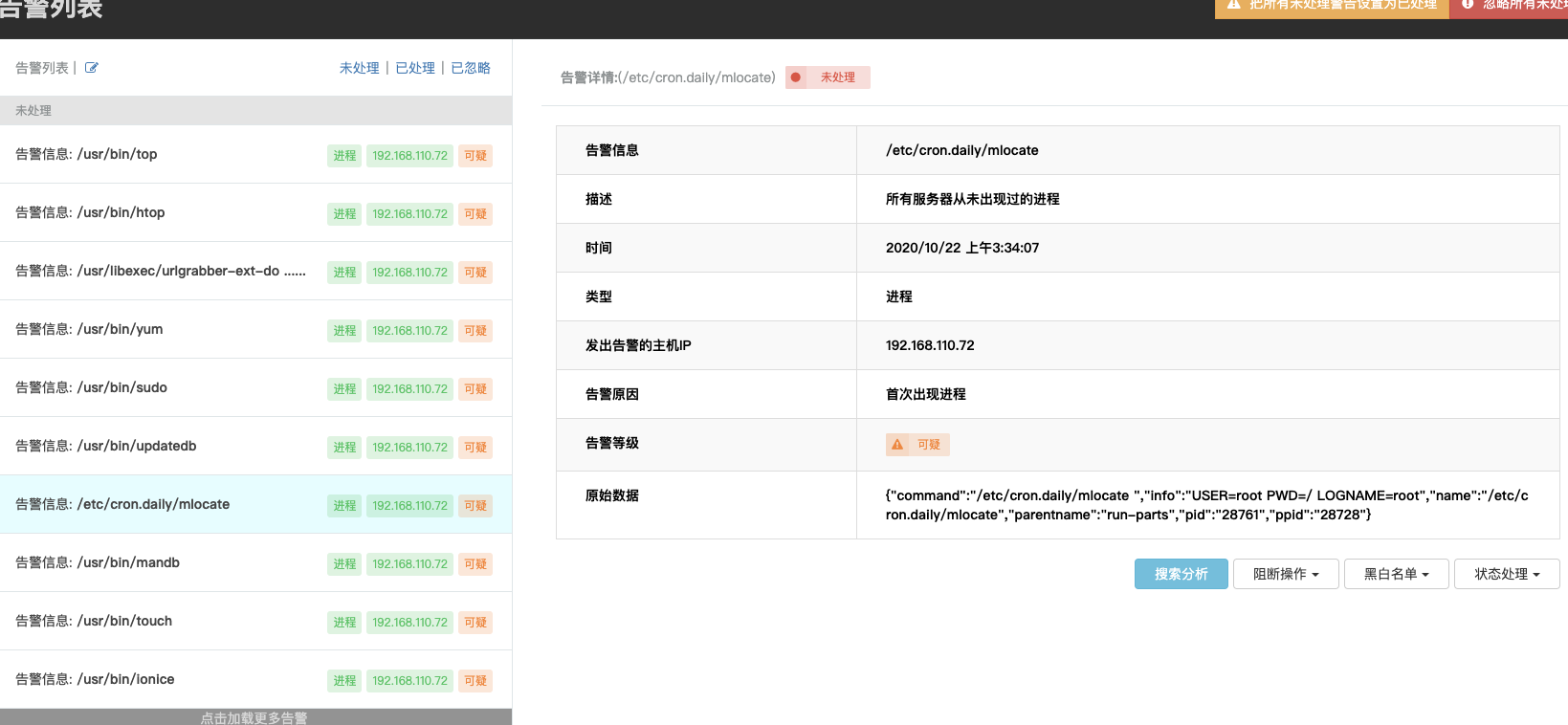
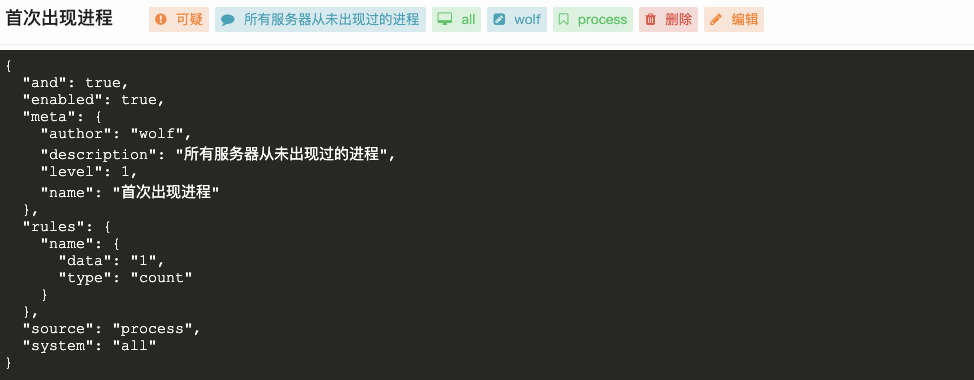
agent在测试机才装2天就有近6w条告警,这是无法运营的,当然,规则支持细粒度控制(开关)还是很不错的
3、功能
功能类型较少,功能模块划分不够细,比如没有单独的入侵检测模块,无法根据危险等级筛选告警,只能一个个去看,根据规则类型判断是否是入侵事件,没有针对性的审计告警是非常耗时的,特别是在告警数量特别庞大的情况下;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号