使用Kestrel 安全分析进行威胁狩猎篇之二——如何利用AI算法分析和情报查询
使用 Kestrel 安全分析进行威胁搜寻
数据分析是威胁追踪过程的核心部分。分析师大部分时间都花在整理和转换从 EDR 和 SIEMS 收集的数据上。Kestrel 旨在通过提供简单的结构来减轻数据分析的负担:
1) 查找内容的简单构造(GET 进程或网络流量 FROM ..)
2) 建立在 STIX-shifter 之上,用于来自多个数据源的标准化数据
3) APPLY 的可扩展范式,用于对收集的数据运行专门构建的分析。
Kestrel 附带一个 docker 分析界面,以及 5 个示例分析,用于 通过 SANS API、 可疑流程评分、 机器学习模型测试、 地理定位可视化和 数据绘图来丰富威胁情报。通过 APPLY 命令使用分析需要 安装docker。用户可以按照https://github.com/openencybersecurityalliance/kestrel-analytics/tree/release/template 中列出的模板构建自己的分析。==》包括情报查询,AI算法分析,见下说明。
官方提供的模板如下:
################################################################ # Kestrel Analytics Container Template # # Build the analytics container: # docker build -t kestrel-analytics-xxx . # # Call the analytics in Kestrel # APPLY xxx ON varX # # Input/output: # - volume "/data" will be mounted by Kestrel runtime # - input: Kestrel variable arguments of APPLY: # - /data/input/0.parquet.gz # - /data/input/1.parquet.gz # - ... # - output: updated Kestrel variables (same index) # - /data/input/0.parquet.gz # - /data/input/1.parquet.gz # - ... # - output display object: # - /data/display/ret.html # ################################################################ FROM python:3 RUN pip install --upgrade pip && \ pip install --no-cache-dir pandas pyarrow WORKDIR /opt/analytics ADD analytics.py . CMD ["python", "analytics.py"]
analytics.py内容:
#!/usr/bin/env python3 import pandas as pd # Kestrel analytics default paths (single input variable) INPUT_DATA_PATH = "/data/input/0.parquet.gz" OUTPUT_DATA_PATH = "/data/output/0.parquet.gz" OUTPUT_DISPLAY = "/data/display/ret.html" def analytics(dataframe): # analyze data in dataframe # provide insights or additional knowledge newattr = ["newval" + str(i) for i in range(dataframe.shape[0])] dataframe["x_new_attr"] = newattr display = "<p>Hello World! -- a Kestrel analytics</p>" # return the updated Kestrel variable return dataframe, display if __name__ == "__main__": dfi = pd.read_parquet(INPUT_DATA_PATH) dfo, disp = analytics(dfi) dfo.to_parquet(OUTPUT_DATA_PATH, compression="gzip") with open(OUTPUT_DISPLAY, "w") as o: o.write(disp)
本质上就是在和docker进程进行交互,交互的方式是通过文件,虽然看起来有些低效。
上述例子效果:要开始使用 Kestrel 分析,首先克隆Kestrel 分析存储库:
$ git clone https://github.com/opencybersecurityalliance/kestrel-analytics.git
存储库中的每个分析都有一个 README.md 来解释如何构建和使用它。例如,可疑评分分析的自述文件显示了如何构建 docker 镜像:
$ docker build -t kestrel-analytics-susp_scoring .
它还显示了使用分析的示例Kestrel 语句:
procs = GET process
FROM file://samplestix.json
WHERE [process:parent_ref.name = 'cmd.exe']
APPLY docker://susp_scoring ON procs
在这个例子中,第一条语句创建一个变量被称为proc该变型的分配实体process(一个STIX网络可观察对象类型从本地)STIX 2.0捆绑匹配该STIX模式 [process:parent_ref.name = 'cmd.exe']。此模式匹配父名为 的进程cmd.exe。接下来,susp_scoring分析应用于该procs变量;它将对实体进行评分process,procs并x_suspicious_score为每个流程添加一个属性(或 STIX 术语中的“属性”)。
以下是运行Kestrel Jupyter Notebook Kernel的Jupyter Notebook 中的示例:

该示例返回一个Kestrel 显示对象——在本例中,是一小段 HTML 内容,上面写着“Hello World!– Kestrel 分析”。它还为输入变量的所有实体添加了一个新属性,procs使用 Kestrel 的DISP 命令可以看出:

再看一个实用的聚类例子。
scikit-learn K-Means Clusting
#!/usr/bin/env python3 import os import pandas as pd from sklearn.cluster import KMeans # Kestrel analytics default paths (single input variable) INPUT_DATA_PATH = "/data/input/0.parquet.gz" OUTPUT_DATA_PATH = "/data/output/0.parquet.gz" # Our analytic parameters from the WITH clause # Kestrel will create env vars for them COLS = os.environ['columns'] N = os.environ['n'] def analytics(df): # Process our parameters cols = COLS.split(',') n = int(N) # Run the algorithm kmeans = KMeans(n_clusters=n).fit(df[cols]) df['cluster'] = kmeans.labels_ # return the updated Kestrel variable return df if __name__ == "__main__": dfi = pd.read_parquet(INPUT_DATA_PATH) dfo = analytics(dfi) dfo.to_parquet(OUTPUT_DATA_PATH, compression="gzip")
Uses https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
Usage
Build it:
docker build -t kestrel-analytics-sklearn-cluster .
Example usage in Kestrel:
conns = GET network-traffic FROM file://samplestix.json where [network-traffic:dst_port > 0]
APPLY docker://sklearn-cluster ON conns WITH n=2, columns=src_byte_count,dst_byte_count
Parameters
n: the number of clusters to form (n_clusters)columns: the Kestrel attributes (columns) to use for clustering. Only these columns will be seen by the clustering algorithm.
APPLY analytics_identifier ON var1, var2, ... WITH x=1, y=abc常量INPUT_DATA_PATH和的值OUTPUT_DATA_PATH是 Kestrel 中用于将 Kestrel 变量传入和传出 docker 容器的约定。Kestrel 运行时会将第一个输入变量的数据(本质上是一个表)写入/data/input/0.parquet.gz. 这是一个 gzip 压缩的Parquet 文件。如果您有不止一个输入变量,替换0为1,2等。
域名查找是一种非常简单的分析,它通过在数据集中查找 IP 地址的域名来丰富上下文。
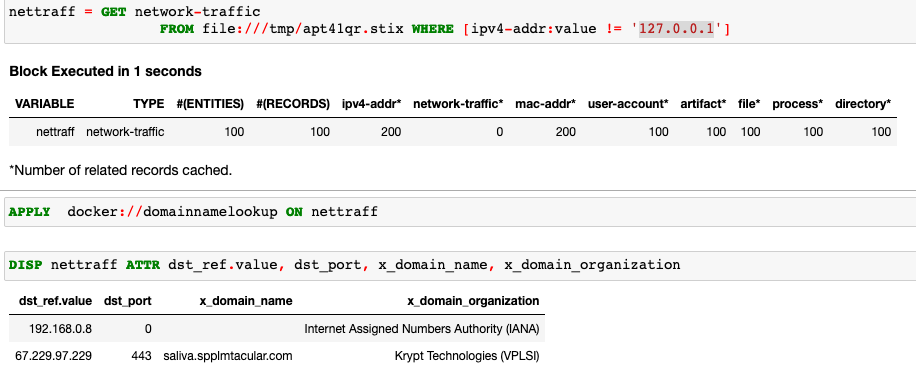
SANS-IP-Enrichment调用SANS API 进行IP 信息检查。这可以扩展为使用许可的威胁情报接口来丰富数据。
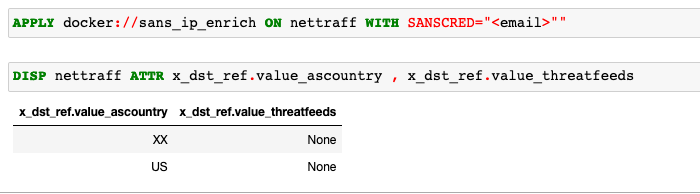
渗漏检测分析提供对数据渗漏可能性的洞察,分析从数据源收集的网络流量数据。
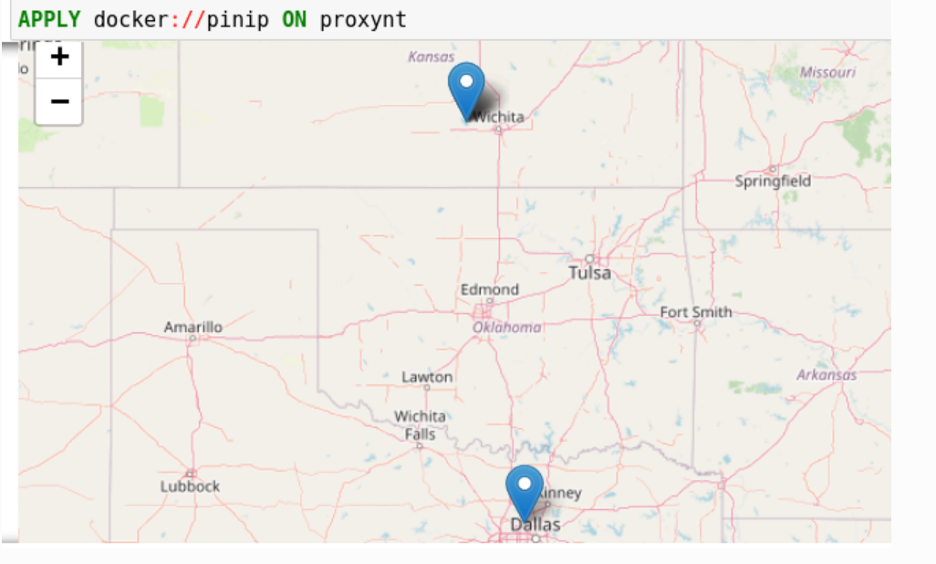
Pinip-on-map分析提供了一种将在变量中找到的 IP 地址放到地图上的方法。此分析首先使用GeoIP2 API获取网络流量中所有 IP 地址的 地理位置。然后它使用 Folium 库将它们固定在地图上。显示对象可以在地图中显示固定对象。
可疑进程评分是另一种有用的分析,它查看包中的进程信息并根据某些属性对其进行评分。例如,如果进程已建立外部网络连接或从 Power Shell 启动或混淆了命令行,则分数将更高。它有助于在威胁搜寻期间隔离可疑进程。
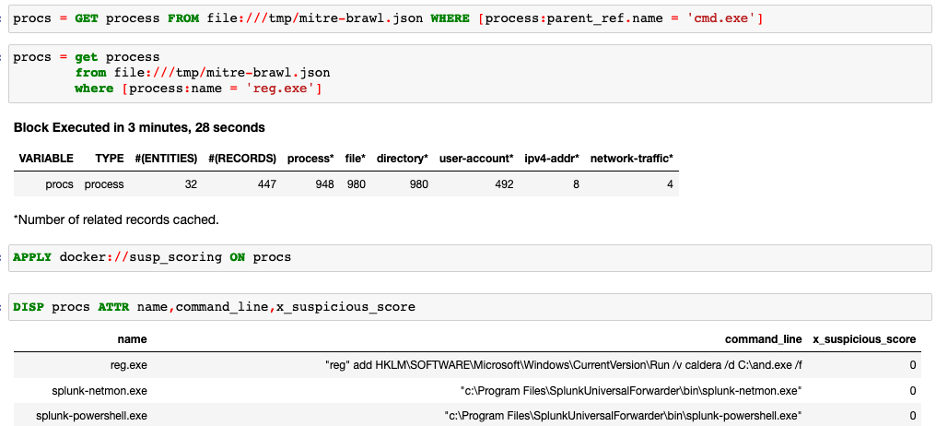

下评分部分的源码实现:
https://github.com/opencybersecurityalliance/kestrel-analytics/tree/release/analytics/suspiciousscoring
Suspicious Process Scoring
Goal
Implement a rule-based analytics to score process regarding how suspicious they are.
Application Scenario
When a user get hundreds of processes in a Kestrel variable, she may want to prioritize the investigation and start from the ones that are most suspicious. The user needs an analytics to provide suspicious scores so she can rank them in Kestrel.
Basic Idea (Open to Discussion And Upgrade)
A process is more suspicious if it has more activities, or more types of activities, such as
- writing to system directory
- network connection
- fork other processes
- known suspicious commands such as https://github.com/Neo23x0/sigma/blob/32ecb816307e3639cf815851fac8341a60631f45/rules/linux/lnx_shell_susp_commands.yml
The analytics can count such significant activities (and how many types) to reason how suspicious a process is. The final score can be normalize into [0,1] and provided as an additional/customized attribute/column in the output Parquet table.
Usage
Build it:
docker build -t kestrel-analytics-susp_scoring .
Then use it in Kestrel:
procs = GET process FROM file://samplestix.json where [process:parent_ref.name = "cmd.exe"]
APPLY docker://susp_scoring ON procs#!/usr/bin/env python3 import fnmatch import json import os import pandas as pd import rule_engine # Kestrel analytics default paths INPUT_DATA_PATH = "/data/input/0.parquet.gz" OUTPUT_DATA_PATH = "/data/output/0.parquet.gz" PATTERNS = [ # Sigma patterns # Source: https://github.com/Neo23x0/sigma/blob/32ecb816307e3639cf815851fac8341a60631f45/rules/linux/lnx_shell_susp_commands.yml # Retrieved: 2020-09-15 # Author: Florian Roth # LICENSE: https://github.com/Neo23x0/sigma/blob/32ecb816307e3639cf815851fac8341a60631f45/LICENSE.Detection.Rules.md 'wget * - http* | perl', 'wget * - http* | sh', 'wget * - http* | bash', 'python -m SimpleHTTPServer', '-m http.server' # Python 3, 'import pty; pty.spawn*', 'socat exec:*', 'socat -O /tmp/*', 'socat tcp-connect*', '*echo binary >>*', '*wget *; chmod +x*', '*wget *; chmod 777 *', '*cd /tmp || cd /var/run || cd /mnt*', '*stop;service iptables stop;*', '*stop;SuSEfirewall2 stop;*', 'chmod 777 2020*', '*>>/etc/rc.local', '*base64 -d /tmp/*', '* | base64 -d *', '*/chmod u+s *', '*chmod +s /tmp/*', '*chmod u+s /tmp/*', '* /tmp/haxhax*', '* /tmp/ns_sploit*', 'nc -l -p *', 'cp /bin/ksh *', 'cp /bin/sh *', '* /tmp/*.b64 *', '*/tmp/ysocereal.jar*', '*/tmp/x *', '*; chmod +x /tmp/*', '*;chmod +x /tmp/*', '*tweet*' # End of sigma patterns ] def get_network_connections(df): if "x_opened_connection_count" in df.keys(): agg_func = pd.Series.sum column = "x_opened_connection_count" elif "opened_connection_ref_0.id" in df.keys(): agg_func = pd.Series.nunique column = "opened_connection_ref_0.id" else: return df if "x_guid" in df.keys(): network = df.groupby("x_guid").agg({column: agg_func}).reset_index() network_susp = df[["x_guid", "command_line"]] network_susp = network_susp.merge(network, left_on="x_guid", right_on="x_guid") network_susp["network_susp_score"] = network_susp.apply( lambda row: row[column] if row["command_line"] else 0, axis=1) df["network_susp_score"] += network_susp["network_susp_score"] return df def get_lu(df, column, method, parameters): if method == 'iqr': k = parameters['k'] if 'k' in parameters else 1.5 q1 = df[column].quantile(0.25) q3 = df[column].quantile(0.75) iqr = q3 - q1 cutoff = iqr * k lower = q1 - cutoff upper = q3 + cutoff else: # Default to method == 'stddev' k = parameters['k'] if 'k' in parameters else 3 mean = df[column].mean() stddev = df[column].std() cutoff = stddev * k lower = mean - cutoff upper = mean + cutoff return lower, upper def score_outliers(df, columns, method, parameters, value): if isinstance(columns, list): column = columns[0] if len(columns) > 1: print('WARN: Only using 1 column "{}" for univariate method "{}"'.format(column, method)) else: column = columns lower, upper = get_lu(df, column, method, parameters) mask = (df[column] < lower) | (df[column] > upper) df.loc[mask, 'x_suspicious_score'] += value def analytics(df): # init suspicious scores df["x_suspicious_score"] = 0 # analytics firs step # - check unknown malicious command line for pattern in PATTERNS: # Convert the pattern to a RE pattern = fnmatch.translate(pattern) # Find all matching rows and convert boolean result to 0 or 1 score = df['command_line'].str.contains(pattern, na=False).astype(int) # Add to score column df["x_suspicious_score"] += score # analytics second step # - check how many network connection with each x_guid df = get_network_connections(df) if 'network_susp_score' in df.columns: score_outliers(df, 'network_susp_score', 'stddev', {'k': 3}, 1) # Apply rules cwd = os.path.dirname(os.path.abspath(__file__)) with open(os.path.join(cwd, 'rules.json'), 'r') as fp: rules = json.load(fp) engine = rule_engine.RuleEngine(rules) def score_rules(row): """Adapter func for passing DataFrame rows to rule engine""" obj = dict(row) # rule engine wants a dict engine.apply_rules(obj) score = obj.get('x_suspicious_score', 0) return score results = df.apply(score_rules, axis=1) df["x_suspicious_score"] = results # return a list of entities/SCOs return df if __name__ == "__main__": dfi = pd.read_parquet(INPUT_DATA_PATH) dfo = analytics(dfi) dfo.to_parquet(OUTPUT_DATA_PATH, compression="gzip")
快乐的威胁狩猎!!
进一步阅读:
https://securityintelligence.com/posts/threat-hunting-guide/
https://kestrel.readthedocs.io/en/latest/tutorial.html#applying-an-analytics

 浙公网安备 33010602011771号
浙公网安备 33010602011771号