小样本学习领域的几篇优秀文章解读——都是度量学习
论文笔记:Few-Shot Learning
2019-12-08 https://www.zmonster.me/2019/12/08/few-shot-learning.html目录
相关概念
Few-Shot Learning 泛指从少量标注数据中学习的方法和场景,理想情况下,一个能进行 Few-Shot Learning 的模型,也能快速地应用到新领域上。Few-Shot Learning 是一种思想,并不指代某个具体的算法、模型,所以也并没有一个通用的、万能的模型,能仅仅使用少量的数据,就把一切的机器学习问题都解决掉,讨论 Few-Shot Learning 时,一般会聚焦到某些特定的问题上,比如 Few-Shot Learning 思想应用到分类问题上时就称之为 Few-Shot Classification。
本文涉及的论文都是 Few-Shot Classification 相关的。
在 Few-Shot Classification 里,问题是这样的:
- 已有一定量的标注数据,数据中包含较多个类别,但每个类别的数据量不多,将这个数据称之为 train set
- 用 train set 通过某种方法得到一个模型 MM
- 给定一个新的标注数据,有 NN 个类,每类中有 kk 个样本,称之为 support set,注意 support set 中的类别和 train set 的不存在交叉(???这个交叉理解起来很蛋疼!!!)
- 要求借助 support set 但不修改模型 M 的参数,使之在给定一个新的输入时,能将其识别为 NN 个类中的一个
上述问题称之为 NN-way kk-shot 问题,kk 一般较小(10 以下)。特别的,当 k=1k=1 时称之为 one-shot,当 k=0k=0 时称之为 zero-shot。
本文涉及的论文,都是在相同的框架下来解决这个问题的,具体来说,模型 MM 具有两大块能力
- 将一个类别的数据表示为一个向量,作为这个类的 representation
- 将一个输入和一个类的 representation 进行比较,判断两者的匹配程度
第 1 点的存在,让其产生的模型能处理任意新的类别,不管你给什么样的 support set,它总能产生 NN 个向量表示这 NN 个类别。
最简单的办法是用 train set 进行表示学习,然后对给定的 suppor set,将每个类中的 k 个样本的向量加和或平均作为类的 representation,待预测的数据也编码成向量和,和这些类的 representation 计算相似或距离就好了。之后可以看到本文中涉及的论文,其方法就是这个简单想法的扩充和改进。
为了尽量和实际使用时接近,Few-Shot Classification 在训练时引入一个叫做 episode 的概念,每个 episode 包含从 train set 中采样出来的一部分数据,以及用这部分数据进行训练的过程:
- 首先从 train set 的类别集合中随机选取 NN 个类别
- 然后,对每个类别,从 train set 中采样 kk 个样本,这 N×kN×k 个样本,同样称之为 support set,用来模拟实际的 support set
- 然后,对每个类别,在上一步采样后剩余的样本里,采样 NqNq 个样本,这 N×NqN×Nq 个样本,称之为 query set,用来模拟实际使用时的待预测输入
- 模型 MM 作用于 support set 上,得到 NN 个向量 C={c1,c2,…,cN}C={c1,c2,…,cN}
- 模型 MM 作用于 query set 上,得到每个样本的向量,并和 cici 计算距离,选择距离最小的作为预测类别
- 根据 query set 上样本的预测结果与期望结果,得到损失,然后使用优化算法去调整模型 MM
模型测试时通常会在一个和 train set 类别不交叉的标注数据集上进行,称这个数据集为 test set。测试过程同样以 episode 为基础,一般是采样若干个 episode 计算 query set 的预测精度,然后地多个 episode 的结果平均作为整体结果。
相关数据集
-
Omniglot: 一个手写字符数据集,包含 50 个类共 1623 个样本
![20191208_15571575791863screenshot.png]()

- miniImageNet: ImageNet 数据集的子集,包含 100 个类,每类 6 个样本,共 600 个样本
-
CUB-200-2011: 一个图像分类数据集,包含 200 个不同的鸟类共 11788 个样本
![20191208_16011575792067screenshot.png]()
- Amazon Review Sentiment Classification: 按产品类型组织的亚马逊评论数据集

论文笔记
五、A Closer Look at Few-Shot Classification13
这篇 ICLR 2019 的论文旨在分析现有 Few-Shot Classification 方法的一些问题。
观点
- Few-Shot Classification 虽然在最近取得了不少进展,但是各个方法由于复杂的模型设计和不同的实现细节,导致他们很难互相比较
- Few-Shot Classification 所使用的 baseline 方法效果被显著地低估了
-
目前的 Few-Shot Classification 模型评估,都是从同样的数据集中采样出来进行的,导致模型的领域迁移性较低
我理解之所以这么说,是因为 Few-Shot Learning 本来宣称的一个目标就是能应付新的类别的数据,而如果这个所谓的「新的类别」必须是在同一个领域内的,那么其实会很受限制。
这点在 Matching Networks 那篇论文里也有提到。
模型和方法
这篇论文的目标不是提出一个新的模型来在 Few-Shot Classification 问题上得到更好的效果,所以在模型部分,只是对一个简单的 baseline 模型做了增强得到了 baseline++ 模型,用来在之后和其他模型对比,以论证前面的「baseline 方法效果被显著低估了」这个观点。
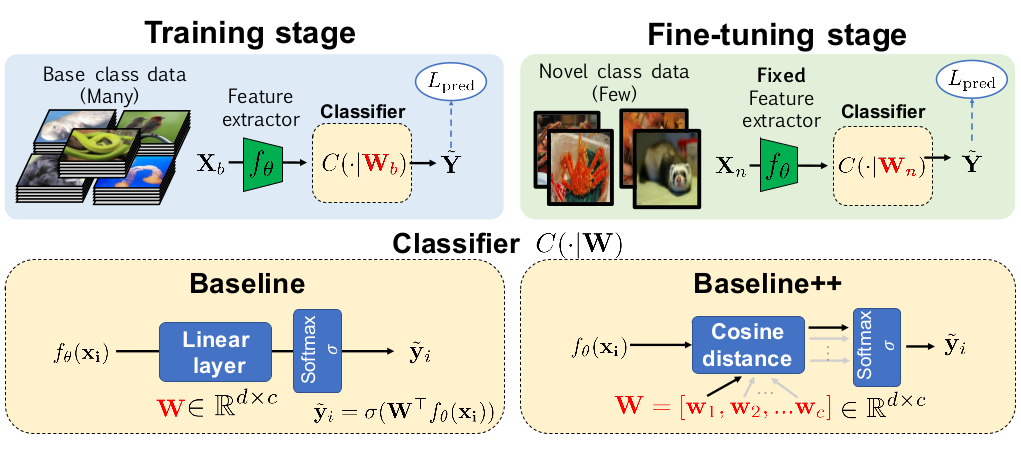
如上图所示,baseline 模型由一个 feature extractor 或者说 encoder 和一个分类模块组成,作者之所以认为之前的一些工作里 baseline 模型效果被低估了,是因为之前的一些论文,在分类模块这里,用的是一个固定的、简单的距离函数(如余弦距离、欧式距离)。
作者在这里做了一些改动,包括:
- baseline 模型的分类模块使用一个全连接层,训练好后,用于新类别数据时,会用新的 support set 进行 fine tuning (之前一些工作里是不做的)
-
baseline++ 在 baseline 模型的基础上对全连接层的计算做了简单的调整
记权重矩阵 W=[w1,w2,…,wc]W=[w1,w2,…,wc],最终分类模块会输出一个长度为 cc 的向量,表示预测为各个类别的概率,记为 s=[s1,s2,…,sc]s=[s1,s2,…,sc]。
在 baseline 模型里,是这么计算的:s=softmax(WTfθ(x))s=softmax(WTfθ(x))
而在 baseline 模型里,则是这么计算的:si=fθ(x)Twi∥fθ(x)∥∥wi∥si=fθ(x)Twi∥fθ(x)∥∥wi∥
当然,作者在这里强调,这个 baseline++ 模型并不是他们的贡献,而是来自于 2018 年的一篇论文14。
实验和结论
作者对比了 Matching Networks、Prototypical Networks、Relation Networks 和一个 meta learning 的方法 MAML 模型。
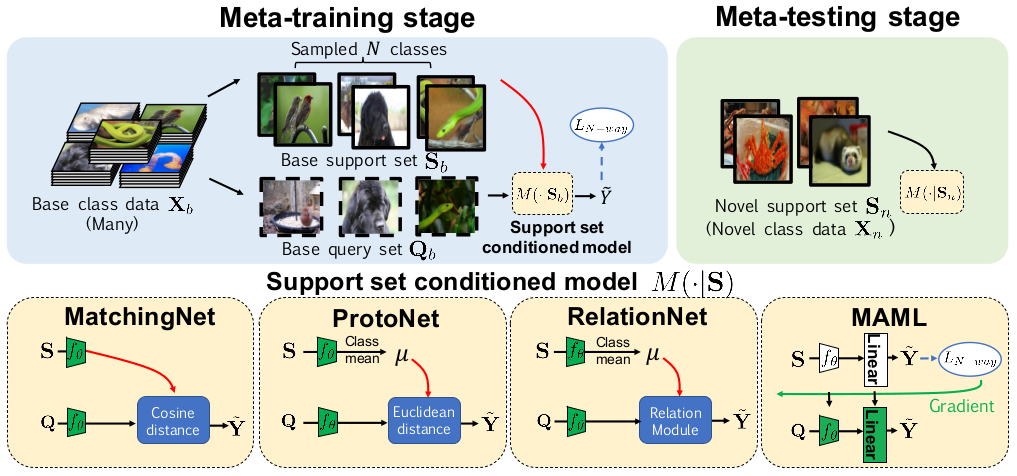
这个对比图还是挺直观的,对于理解不同模型之间的差异挺有帮助。
图上的 meta-training 和 meta-testing,其实就是指训练和测试。但是 Few-Shot Classification 的训练用数据和实际使用是要预测的类别原则上是不一样的,学到的更多的是区分不同类别的能力而不是区分某个指定类别的能力,这个还有监督分类问题是不太一样的,这里加个 meta 是和普通的分类模型的训练、测试进行区分,不用太在意。b
进行了三个实验:
- 使用 miniImageNet 数据集进行一般的图像分类实验
- 使用 CUB-200-2011 数据集(后面简称为 CUB 数据集)进行细粒度图像分类实验
- 使用 miniImageNet 数据集训练,在 CUB 数据集上进行验证和测试,对比各个模型的跨领域适应能力
实验的通用设置为:
- 分别进行 5-way 1-shot 和 5-way 5-shot 实验,训练时的 query set 每类 16 个样本
- 对 1-shot 实验,训练 60000 个 episodes;对 5-shot 实验,训练 40000 个 episodes
- 测试时,将 600 个 episodes 上测平均测试结果作为整体结果
- baseline 模型和 baseline++ 模型训练时设置 batch size 为 16,训练 400 个 epochs
- baseline 模型和 baseline++ 模型,在测试时,让 encoder 参数不变,用 support set 对分类模块进行 fine tuning,batch size 设置为 4 训练 100 次
- 所有模型训练时都使用 Adam 优化算法,初始学习率设置为 0.001
由于作者自己重新实现了用于对比的几个模型,所以先和原作者论文中报告的结果做了对比,如下图所示:
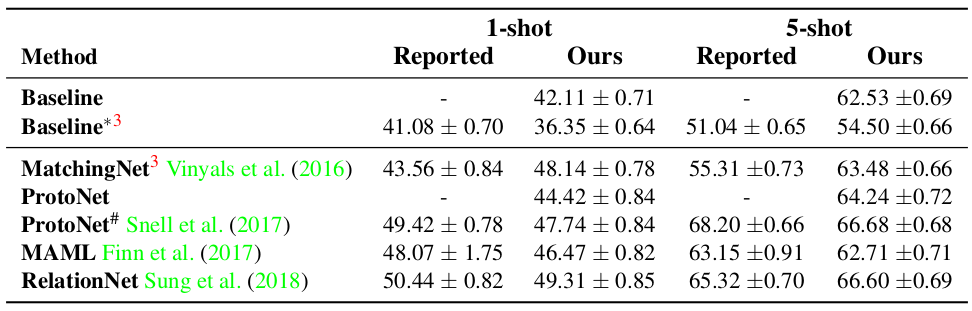
可以看到作者实现的这几个模型和它们的原实现的效果相比,大部分是稍差一些,也有些表现更好的。
在 CUB 和 miniImageNet 两个数据集上做实验时,使用四层 CNN 作为 encoder,实验结果如下图所示:
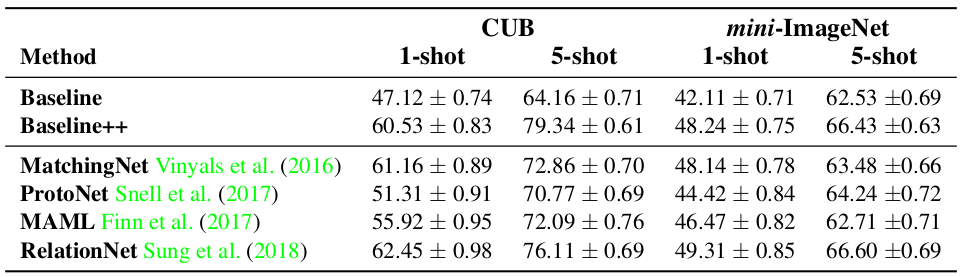
可以看到,baseline++ 模型和这些 SOTA 的模型相比并没有很大的差距,甚至在一些情况下比 SOTA 的模型还要好。baseline++ 模型仅仅是对 baseline 模型的一个简单修改,所以作者说 baseline 模型的能力被显著地低估了。
接着,作者认为 encoder 是很重要的,所以尝试了将 encoder 替换成更深的网络,结果显示使用更深的网络后大部分模型的效果都有了显著的提升。
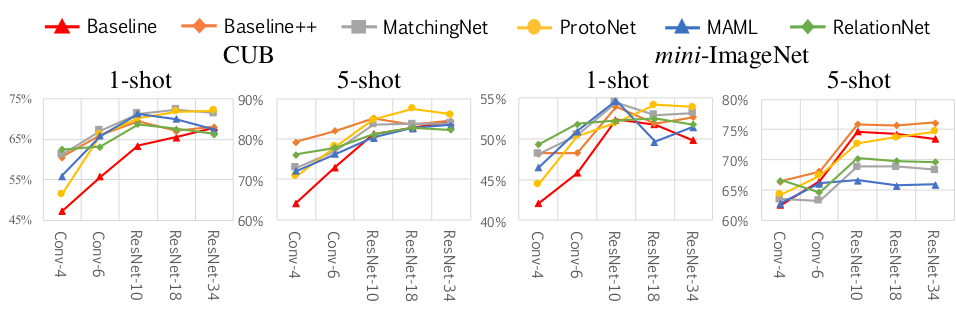
第三个实验 —— 也就是那个先在 miniImageNet 数据集上训练然后在 CUB 数据集上测试的实验,统一使用更深的 ResNet-18 作为 encoder,结果显示 baseline 模型的效果最好。

由于 CUB 数据集都是鸟类的数据,所以训练与测试时的领域差异性很小;miniImageNet 数据集包含了很多不同类别的物体,所以领域差异性比 CUB 要大;当训练使用 miniImageNet 数据集而测试时使用 CUB 时,领域差异性是最大的。同样使用 ResNet-18 作为 encoder 时,三个不同的 5-way 5-shot 实验对比结果也说明了目前这些 Few-Shot Classification 模型在领域迁移上的问题,如下图所示:
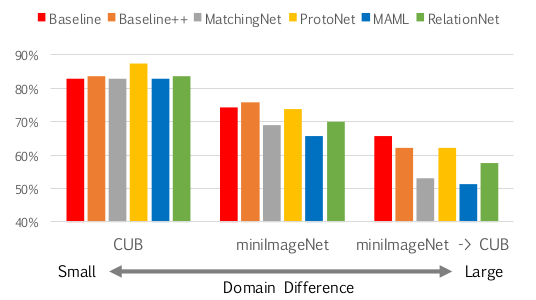
而之所以 baseline 模型会最好,有可能是因为 baseline 模型进行了 fine tuning,所以作者再进一步实验,在其他模型上也加上 fine tuning 操作,结果显示领域差异性大时,fine tuning 是很有必要的,如下图所示:
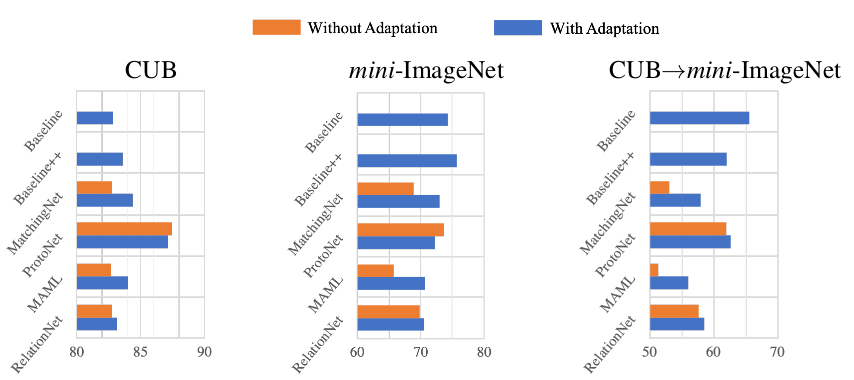
总结
Few-Shot Learning 这个概念最早是李飞飞提出来的15,不过早先的一些工作方法都比较复杂,除了上述我看的一些论文外,还有一些从 meta learning 的方向来做的。目前看来,Few-Shot Learning 特别是 Few-Shot Classification 的方法,主要都是在 2016 年 Matching Networks 提出的框架下使用越来越复杂的模型,比如还有一篇我没有通读的微软的论文16的做法就是使用复杂的 attention 模型,我相信 ELMo、BERT 等更强大的预训练模型也会逐步用到这个领域里。
回到这几篇论文,可以看到 Few-Shot Learning 应用到分类问题上时,能取得一定的成果,但也还是有一些问题或者限制的
- train set 中需要有足够多的类别,虽然每类的数据可以不多 —— 一定要认识清楚这点,不要以为 Few-Shot Learning 就真的只需要很少很少的数据就够了
- 领域迁移能力不够好 —— 当然这是目前几乎所有模型的问题,但 Few-Shot Learning 本来就想要去解决新类别的学习问题,希望未来能看到在这方面更多的一些讨论吧
我个人对于数据稀缺时该如何训练模型这个话题是很感兴趣的,除了 Few-Shot Learning,目前了解到的一些方法还有:数据增强、远程监督、多任务学习。从这几篇论文来看,表示学习也是很重要的一环,一个表示能力很强的预训练模型,也会很有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号