
目录遍历漏洞——本质上是因为php这样的后端代码实现中使用了include这样的模板函数导致
目录遍历
目录遍历(英文:Directory traversal),又名路径遍历(英文:Path traversal)是一种利用网站的安全验证缺陷或用户请求验证缺陷(如传递特定字符串至文件应用程序接口)来列出服务器目录的漏洞利用方式。
此攻击手段的目的是利用存在缺陷的应用程序来获得目标文件系统上的非授权访问权限。与利用程序漏洞的手段相比,这一手段缺乏安全性(因为程序运行逻辑正确)。
目录遍历在英文世界里又名../ 攻击(Dot dot slash attack)、目录攀登(Directory climbing)及回溯(Backtracking)。其部分攻击手段也可划分为规范化攻击(Canonicalization attack)。
目录
示例
下方是一个存在安全隐患的PHP程序示例:
<?php
$template = 'red.php';
if (isset($_COOKIE['TEMPLATE']))
$template = $_COOKIE['TEMPLATE'];
include ("/home/users/phpguru/templates/" . $template);
?>
攻击者可对此程序发送下列HTTP请求:
GET /vulnerable.php HTTP/1.0
Cookie: TEMPLATE=../../../../../../../../../etc/passwd
从而使服务器产生如下的响应:
HTTP/1.0 200 OK
Content-Type: text/html
Server: Apache
root:fi3sED95ibqR6:0:1:System Operator:/:/bin/ksh
daemon:*:1:1::/tmp:
phpguru:f8fk3j1OIf31.:182:100:Developer:/home/users/phpguru/:/bin/csh
/home/users/phpguru/templates/后重复的../导致include()函数遍历Root目录,并向攻击者返回Unix密码文件/etc/passwd。
Unix中的/etc/passwd常用于展示应用程序存在目录遍历问题,黑客及骇客可使用此文件来破解密码。
新版Unix操作系统中,原位于passwd文件中的经散列处理后的密码被移动到了/etc/shadow,其无法被没有特权的用户读取。但攻击者仍可使用此文件来列出系统上的用户账户。
变体
下方是已知的目录遍历攻击方式变体:
Unix上的目录遍历
常见的Unix类目录遍历攻击使用../字符。攻击者可使用glob通配符对Sudo程序进行攻击(如chown /opt/myapp/myconfig/*可通过sudo chown baduser /opt/myapp/myconfig/../../../etc/passwd命令攻击)。
Windows上的目录遍历
对微软Windows及DOS进行目录遍历通常使用..\或../。[1]
在这类系统上,每个分区均有不同的根目录(如C盘则为C:\),不同的盘符之间没有共同的根目录。这意味着对于大多数的目录遍历缺陷而言,其仅仅对单一的分区有效。
这种攻击手段也是此类系统上大多数安全缺陷的异派同源。[2][3]
URI编码目录遍历
此缺陷与规范化问题有关。
部分网页应用程序会检查查询字符串中的危险字符,如:
....\../
这种方法能避免部分目录遍历问题。但是,查询字符串在使用前通常经过URI解码。因此,这些应用程序易受到百分号编码类的目录遍历攻击,如:
%2e%2e%2f将解码为../%2e%2e/将解码为../..%2f将解码为../%2e%2e%5c将解码为..\
Unicode / UTF-8编码目录遍历
同样与规范化问题有关。
布鲁斯·施奈尔与杰弗里·斯特里夫林(Jeffrey Streifling)称UTF-8是安全缺陷与攻击向量的根源。[4]
当微软为其网页服务器添加Unicode支持时,同时添加了一种编码../的全新方式,却绕过了防止目录遍历的补丁。
多个百分号编码,如:
%c1%1c%c0%af
可被解码为/或\ 符。
微软的网页服务器将百分号编码解码为对应的8位字符。这是Windows和DOS的正确行为,因为两者都使用基于ASCII的8位字符集的规范形式。
但是,原版UTF-8并不是规范形式,多个字符串经编码后可被译为相同的字符串。微软在未经UTF-8规范化时即进行防遍历检查,从而导致在字符串比较时忽略了(HEX)C0AF及(HEX) 2F均为同一字符。攻击者可使用%c0%9v字符进行攻击。[5]
Zip/压缩文件遍历攻击
攻击者可使用归档文件(如zip格式)来进行目录遍历攻击:压缩文件中的文件可为攻击者精心制造,利用回溯法来覆盖文件系统上的文件。用于解压缩归档文件的代码应对归档中的文件进行检查,避免目录遍历。
防止目录遍历的方法
下方是防止目录遍历的几种方法:
- 在继续运行下方代码时处理与文件无关的URI请求(如钩入用户代码);
- 当用户请求访问文件/目录时,构造文件/目录(若存在)所在的的完整路径,并标准化所有字符(如
%20转为空格); - 假设文档根目录已合格、被正常化、目录已知且字符串的长度为N。假设此目录外的任何文件都无法被读取/写入;
- 确保请求文件完整目录后的头N个字符与文档根目录完全相同;
- 若相同,则返回指定文件;
- 若不同,则返回错误,因为请求显然超出服务器提供文件范围;
- 将硬编码的预定义文件拓展名添加到目录后将无法限制对此文件拓展名的攻击。
<?php
include($_GET['file'] . '.html');
用户可使用空字符(表示字符串结束)来绕过$_GET后的全部内容(仅限PHP语言)。
另请参阅
参考文献
- ^ Naming Files, Paths, and Namespaces. Microsoft.
File I/O functions in the Windows API convert '/' to '\' as part of converting the name to an NT-style name
- ^ Burnett, Mark. Security Holes That Run Deep. SecurityFocus. December 20, 2004.
- ^ Microsoft: Security Vulnerabilities (Directory Traversal). CVE Details.
- ^ Crypto-Gram Newsletter July 2000
- ^ [2019-07-11]
原文地址:https://en.wikipedia.org/wiki/Directory_traversal_attack
目录遍历攻击
一次目录遍历攻击(directory traversal attack)通常利用了“服务器安全认证缺失”或者“用户提供输入的文件处理操作”,使得服务器端文件操作接口执行了带有“遍历父文件目录”意图的恶意输入字符。
这种攻击的目的通常是利用服务器相关(存在安全漏洞的)应用服务,来恶意的获取服务器上本不可访问的文件访问权限。该攻击利用了程序自身安全的缺失(对于程序本身的意图而言是合法的),因此存在目录遍历缺陷的程序往往本身没有什么逻辑缺陷。
目录遍历攻击也被称为“…/攻击”、“目录爬寻”以及“回溯攻击”。甚至有些形式的目录遍历攻击是公认的标准化缺陷。
示例
一个典型的易受攻击的PHP应用案例如下代码所示:
<?php
$template = 'red.php';
if (isset($_COOKIE['TEMPLATE']))
$template = $_COOKIE['TEMPLATE'];
include ("/home/users/phpguru/templates/" . $template);
?>
- 1
- 2
- 3
- 4
- 5
- 6
译者注:如果有读者看不懂php代码,可以看下面这段nodejs代码,与原文示例中的php代码效果完全一致:
var http=require("http");
var fs=require("fs");
var server=http.createServer(function(req,res){
var $template="red.php";
if(req.headers.cookie){
req.headers.cookie.split(";").forEach(function(index,i){
var map=index.split("=");
if(map[0]=="TEMPLATE"){
$template=map[1];
}
});
}
var stream=fs.createReadStream("/home/users/phpguru/templates/"+$template);
stream.pipe(res);
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
一个针对这个系统的目录遍历攻击即可像如下示例一样发送HTTP请求:
GET /vulnerable.php HTTP/1.0
Cookie: TEMPLATE=../../../../../../../../../etc/passwd
- 1
- 2
译者注:/etc/passwd是某些Unix系统的密码存储文件
进而服务器会发回如下响应:
HTTP/1.0 200 OK
Content-Type: text/html
Server: Apache
root:fi3sED95ibqR6:0:1:System Operator:/:/bin/ksh
daemon:*:1:1::/tmp:
phpguru:f8fk3j1OIf31.:182:100:Developer:/home/users/phpguru/:/bin/csh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
正如上例所示,重复的“…/”字符跟在“/home/users/phpguru/templates/”后面,造成了服务器遍历到了跟目录,并最终访问了Unix密码文件“/etc/passwd”。
为了说明攻击者如何尝试获取服务器密码数据,我们在上例中使用了Unix的“/etc/passwd”公共文件来展示目录遍历攻击(directory traversal)。
不过值得庆幸的是,在较新版本的Unix系统中,“passwd”文件不再包含哈希密码。在新版Unix中,密码被存放在隐藏文件中,这样未授权的用户将无法再轻易查看。尽管如此,目录遍历攻击仍然是遍历服务器账号信息的有效手段,如今的许多账号服务器也确实仍存在类似的安全漏洞。
目录遍历攻击的多样性
本小节我们列出了一些已知的目录遍历攻击字符串组合:
1.Unix目录遍历攻击
通用的类Unix系统的目录遍历攻击字符串形如“…/”。
2.Windows操作系统目录遍历攻击
对于微软的Windows操作系统以及DOS系统的目录结构,攻击者可以使用“…/”或者“…\”字符串。
在这种操作系统中,每个磁盘分区有一个独立的根目录(比如我们会把个人电脑分区成“C盘”、“D盘”等等),并且在所有磁盘分区之上没有更高级的根目录。这意味着Windows系统上的目录遍历攻击会被隔离在单个磁盘分区之内(C盘被攻击,D盘不受影响)。
目录遍历攻击是诸多微软的漏洞之一。
3.URI编码形式的目录遍历攻击
标准化缺陷
一些网络应用会通过查询危险的字符串,例如:
- …
- …\
- …/
来防止目录遍历攻击。然而,服务器检查的字符串往往会被URI编码。因此这类系统将无法避免如下形式的目录遍历攻击: - %2e%2e%2f:解码为…/
- %2e%2e/:解码为…/
- …%2f:解码为…/
- %2e%2e%5c:解码为…\
4.Unicode/UTF-8编码形式的目录遍历攻击
标准化缺陷
UTF-8编码被Bruce Scheneier和Jeffery Streifling标记为一种易受攻击的资源。
当微软向他们的Web服务增加Unicode支持时,一种新的编码方式——“…/”被引入,也正是这一举动最终引入了目录遍历攻击。
许多带百分号的编码方式,例如:
- %c1%1c
- %c0%af
被转换成“/”或“\”字符。
百分号编码字符被微软提供的Web服务解码成相应的8字节字符。正式由于Windows和DOS使用基于ASCII的8字节标准编码方式,这个行为在历史上一度被认为是正确的。
然而,UTF-8本身的源头并非标准化。许多字符串甚至根本就没有对应的编解码字符。微软通过其他一些方式,最终没有使用标准化的编解码方式。许多奇怪的百分号编码形式,例如“%c0%9v”也被引入。
5.Zip/归档文件目录遍历攻击
形如zip这样的归档文件格式也允许目录遍历攻击:就像回溯文件系统一样,在归档文件中的任何文件也会被重写。我们可以编写出查看归档文件内部文件路径的代码来。
几种可能的防御手段
一个用来防御目录遍历攻击的算法应该包含以下几点:
1.针对URI请求的服务功能不应该导致文件系统被操作。举例来说,在继续执行下一步操作之前,在用户代码中执行嗅探钩子。
2.当确实需要提供一个操作文件或目录的URI请求服务时,在访问文件时先生成完整的文件路径(如果相应参数存在的话),并且将路径内的所有的字符都标准化(举例来说,将%20转换成空格)。
3.程序应当设置一个“文档根节点”,以这个确信的、标准化的路径为基准,来确定一个最顶层的目录路径N。并且规定在该目录上层的所有目录或文件不可访问。
4.通过程序来检查客户端请求拼接解码后的目录路径字符串的头部是否和程序规定的“文档根节点”N的头部相同。
5.如果相同,则允许本次文件操作。
6.如果不同,返回一个错误,因为该请求需要访问的文件目录范围已经超出了Web程序服务的文件范围。
7.请注意对文件后缀名进行硬编码,并不能限定所有请求都操作硬编码后缀的文件,例如如下代码:
<?php
include($_GET['file'] . '.html');
- 1
- 2
客户端只要使用形如“\0”(即NULL,表明字符串已经结束。类似的结束符还有很多,详见https://en.wikipedia.org/wiki/Null_character#Representation)的字符来结尾,就能使程序忽略$_GET[php specific]后的所有内容。
[转载]目录遍历攻击解析
文章来源:https://cloud.tencent.com/developer/news/60212
参考文章:https://www.cnblogs.com/AtesetEnginner/p/11064279.html
一.漏洞描述
目录遍历是由于web服务器或者web应用程序对用户输入的文件名称的安全性验证不足而导致的一种安全漏洞,使得攻击者通过利用一些特殊字符就可以绕过服务器的安全限制,访问任意的文件(可以是web根目录以外的文件),甚至执行系统命令。
二.漏洞成因
程序在实现上没有充分过滤用户输入的../之类的目录跳转符,导致恶意用户可以通过提交目录跳转来遍历服务器上的任意文件。
三.漏洞利用
常见目录遍历:
0x01 Unix目录遍历攻击
通用的类Unix系统的目录遍历攻击字符串形如“../”。
0x02 Windows操作系统目录遍历攻击
对于微软的Windows操作系统以及DOS系统的目录结构,攻击者可以使用“../”或者“..\”字符串。
在这种操作系统中,每个磁盘分区有一个独立的根目录(比如我们会把个人电脑分区成“C盘”、“D盘”等等),并且在所有磁盘分区之上没有更高级的根目录。这意味着Windows系统上的目录遍历攻击会被隔离在单个磁盘分区之内(C盘被攻击,D盘不受影响)。
0x03 URI编码形式的目录遍历攻击
一些网络应用会通过查询危险的字符串,例如:- ..- ..- ../
来防止目录遍历攻击。然而,服务器检查的字符串往往会被URI编码。因此这类系统将无法避免如下形式的目录遍历攻击:
-
%2e%2e%2f:解码为../
-
%2e%2e/:解码为../
-
..%2f:解码为../
-
%2e%2e%5c:解码为..\
0x04 Unicode/UTF-8编码形式的目录遍历攻击
UTF-8编码被Bruce Scheneier和Jeffery Streifling标记为一种易受攻击的资源。
当微软向他们的Web服务增加Unicode支持时,一种新的编码方式——“../”被引入,也正是这一举动最终引入了目录遍历攻击。
许多带百分号的编码方式,例如:- %c1%1c- %c0%af 被转换成“/”或“\”字符。
百分号编码字符被微软提供的Web服务解码成相应的8字节字符。正式由于Windows和DOS使用基于ASCII的8字节标准编码方式,这个行为在历史上一度被认为是正确的。
然而,UTF-8本身的源头并非标准化。许多字符串甚至根本就没有对应的编解码字符。微软通过其他一些方式,最终没有使用标准化的编解码方式。许多奇怪的百分号编码形式,例如“%c0%9v”也被引入。
0x05 Zip/归档文件目录遍历攻击
形如zip这样的归档文件格式也允许目录遍历攻击:就像回溯文件系统一样,在归档文件中的任何文件也会被重写。我们可以编写出查看归档文件内部文件路径的代码来。
目录遍历变异:
路径遍历漏洞是很常见的,在Web应用程序编写过程,会有意识的对传递过来的参数进行过滤或者直接删除,存在风险的过滤方式,一般可以采用如下方式进行突破:
0x01 加密参数传递的数据
在Web应用程序对文件名进行加密之后再提交,比如:“downfile.jsp?filename= ZmFuLnBkZg- “,在参数filename用的是Base64加密,而攻击者要想绕过,只需简单的将文件名加密后再附加提交即可。所以说,采用一些有规律或者轻易能识别的加密方式,也是存在风险的。
0x02 编码绕过
尝试使用不同的编码转换进行过滤性的绕过,比如Url编码,通过对参数进行Url编码提交,“downfile.jsp?filename= %66%61%6E%2E%70%64%66“来绕过。
0x03 目录限定绕过
在有些Web应用程序是通过限定目录权限来分离的。当然这样的方法不值得可取的,攻击者可以通过某些特殊的符号““来绕过。形如这样的提交“downfile.jsp?filename=/../boot”。能过这样一个符号,就可以直接跳转到硬盘目录下了。
0x04 绕过文件后缀过滤
一些Web应用程序在读取文件前,会对提交的文件后缀进行检测,攻击者可以在文件名后放一个空字节的编码,来绕过这样的文件类型的检查。
例如:../../../../boot.ini%00.jpg,Web应用程序使用的Api会允许字符串中包含空字符,当实际获取文件名时,则由系统的Api会直接截短,而解析为“../../../../boot.ini”。
在类Unix的系统中也可以使用Url编码的换行符,例如:../../../etc/passwd%0a.jpg如果文件系统在获取含有换行符的文件名,会截短为文件名。也可以尝试%20,例如: ../../../index.jsp%20
0x05 绕过来路验证
Http Referer : HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的
在一些Web应用程序中,会有对提交参数的来路进行判断的方法,而绕过的方法可以尝试通过在网站留言或者交互的地方提交Url再点击或者直接修改Http Referer即可,这主要是原因Http Referer是由客户端浏览器发送的,服务器是无法控制的,而将此变量当作一个值得信任源是错误的。
四.漏洞防御
在防范目录遍历漏洞的方法中,最有效的是权限的控制,谨慎的处理向文件系统API传递过来的参数路径。主要是因为大多数的目录或者文件权限均没有得到合理的配置,而Web应用程序对文件的读取大多依赖于系统本身的API,在参数传递的过程,如果没有得严谨的控制,则会出现越权现象的出现。在这种情况下,Web应用程序可以采取以下防御方法,最好是组合使用。
对用户的输入进行验证,特别是路径替代字符“../”
尽可能采用白名单的形式,验证所有输入
合理配置web服务器的目录权限
程序出错时,不要显示内部相关细节
目录遍历漏洞
文章来源:H3C攻防团队
一、什么是目录遍历漏洞
目录遍历漏洞在国内外有许多不同的叫法,也可以叫做信息泄露漏洞、非授权文件包含漏洞等。目录遍历是针对Windows IIS和Apache的一种常见攻击方法,它可能让攻击者访问受限制的目录,通过执行cmd.exe /c命令来提取目录信息,或者在Web服务器的根目录以外执行命令。
目录遍历漏洞可能存在于Web服务器软件本身,也可能存在于Web应用程序之中。目录遍历攻击比较容易掌握,要执行一个目录遍历攻击,攻击者所需要的只是一个web浏览器,并且掌握一些关于系统的缺省文件和目录所存在的位置的知识即可。
二、目录遍历漏洞原理
目录遍历漏洞原理比较简单,就是程序在实现上没有充分过滤用户输入的../之类的目录跳转符,导致恶意用户可以通过提交目录跳转来遍历服务器上的任意文件。这里的目录跳转符可以是../,也可是../的ASCII编码或者是unicode编码等。
在包含动态页面的Web应用中,输入往往是通过GET或是POST的请求方法从浏览器获得,例如:http://www.test.com/my. jsp?file=abc.html
通过这个URL,浏览器向服务器发送了对动态页面my.jsp的请求,并且伴有值为abc.html的file参数,当请求在Web服务器端执行时,my.jsp会从服务器的文件系统中取得abc.html文件,并将其返回给客户端的浏览器,那么攻击者就可以假定my.jsp能够从文件系统中获取文件并构造如下的恶意URL:
http://www.test.com/my.jsp?file=../../Windows/system.ini
当服务器处理该请求时,将从文件系统中获取system.ini文件并返回给用户。在这里,攻击者需要去猜测需要往上回溯多少层才能找到Windows目录,但显而易见,这其实并不困难,经过几次的尝试后总会找到的。此时攻击者通过改变目录跳转符的数量和请求的文件名称即可读取其他文件。
如果上面恶意请求被检测到并被阻断,我们可以尝试给URL中的目录跳转符里的点或者斜杠进行ASCII编码,这样可能能够绕过检测成功执行,如示:
http://www.test.com/my.jsp?file=%2e./..%2fWindows/system.ini
也可以利用web服务器本身的漏洞进行攻击,如利用Apache Tomcat UTF-8目录遍历漏洞。漏洞CVE编号为CVE-2008-2938,Tomcat处理请求中的编码时存在漏洞,如果在context.xml或server.xml中将allowLinking设置为true且连接器配置为URIEncoding=UTF-8的话,则向Tomcat提交恶意请求就可以通过目录遍历攻击读取服务器上的任意文件。
将目录跳转符里的点编码为%c0%ae,如果服务器使用的受该漏洞影响的Tomcat版本,则可能攻击成功:
http://www.target.com/%c0%ae%c0%ae/%c0%ae%c0%ae/foo/bar
三、目录遍历攻击实例
目录遍历攻击比较容易实施,下面以WeBid目录遍历漏洞(漏洞exploit-db编号为22829)为例,介绍目录遍历漏洞攻击的具体实现。
WeBid是国外一款方便使用和可定制的开源拍卖平台。WeBid 1.0.4和1.0.5版本在实现上存在一个目录遍历漏洞,WeBid不正确的过滤用户提交的请求,远程攻击者可以利用该漏洞进行目录遍历攻击,成功利用可以WEB权限查看包含敏感信息的任意文件。问题代码如图1所示。
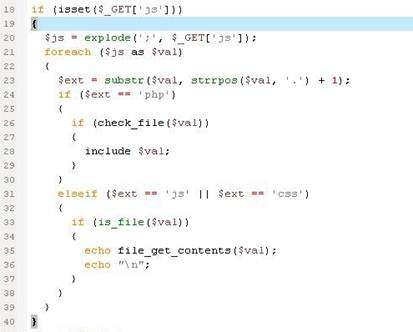
图1 WeBid目录遍历漏洞问题代码
分析图1代码可以发现,/WeBid/loader.php页面没有对用户提交的js参数的文件路径进行过滤,攻击者可通过目录跳转字符“../”进行目录遍历攻击。虽然程序将读取的文件类型限制为“js”和“css”(此处程序虽然支持php文件类型,但是结合上下文可以发现程序通过check_file函数对php文件类型的文件路径和名称都做了严格的限制),但是由于PHP 5.3.4之前的版本中存在空字符截断漏洞,同时程序也未对截断符“%00”进行过滤,攻击者可借助截断符读取任意类型文件。我们分三步来展示非法读取文件。
1、访问敏感文件
敏感文件列表 http://wiki.wooyun.org/pentest:filepath
WeBid系统loader.php页面正常请求是形如http://example.com/WeBid/loader.php?js=abc.js,此时系统会输出目标js文件的内容。攻击者可借助目录跳转字符非法访问文件,如给js参数赋下面的值尝试访问SchedLgU.txt文件:js=../../../../../WINDOWS/SchedLgU.Txt,即发送HTTP请求:GET /WeBid/loader.php?js=../../../../../WINDOWS/SchedLgU.Txt HTTP/1.1。该请求是请求访问Windows操作系统的“计划任务”的“日志”SchedLgU.Txt文件,该文件位于WINDOWS目录下,记录了以往计划任务的执行情况,以及用户每次开机启动Windows系统的信息。我们在测试环境中可以发现该js参数的请求执行结果如图2所示。由于请求的文件类型为txt,并不在系统允许允许访问的文件类型的白名单中,所以目标文件内容并没有被输出,访问失败。
2、绕过系统过滤
为绕过文件类型白名单过滤,可以借助“%00”截断符再进行尝试,这里使用web调试工具Fiddler进行截断。空字符截断是一个比较经典的攻击手法,文件上传、下载、读取等操作都可能利用。运行Fiddler对所有HTTP请求进行监视,同时开启Fiddler的断点功能,再次发送前面的http请求,这时由于断点功能该请求虽然已经生成,但是尚未发送给服务器,在Fiddler里将本次请求的URL里的文件名修改为:SchedLgU.Txt%00.js,如图3右上角红框处所示。
3、执行恶意请求
点击图3中的“Run to Completion”绿色按钮将构造好的恶意请求发送给服务器,此时抓包可以发现向服务器请求的文件是SchedLgU.Txt%00.js(如图4红框处所示)。当服务器收到请求后,程序会提取%00后面的js字符串进行文件类型过滤,恶意请求顺利骗过程序检测。当程序打开../../../../../WINDOWS/SchedLgU.Txt%00.js文件时,由于%00具有截断功能,实际上打开的是WINDOWS目录下的SchedLgU.Txt文件,从图5中我们可以看出该日志文件被成功输出,攻击成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号