深度模型压缩技术在智能座舱方案的探索与实践——知识蒸馏 也是teacher student模型
1. 概况
1.1 背景
近年来,随着人工智能、通信、汽车电动化等技术发展,智能汽车的概念已经成为了主流的发展趋势。在自动驾驶到来之前,汽车座舱的场景正在成为智能汽车发展中的不可或缺环节。将汽车座舱智能化可以提高整体乘客乘坐品质和驾驶员行驶体验,因而智能座舱产品逐步走进大众视野,相关市场也得到较快发展。据统计,2019 年中国智能座舱行业市场规模高达百亿元,随着中国市场的消费升级,大众对驾驶与乘坐的体验的需求不断提升,中国智能座舱行业的市场规模将保持高速增长,预计到 2025 年,市场规模可达千亿元。

1.2 技术挑战
智能座舱的功能丰富,其中绝大多数核心算法是基于深度学习的视觉算法。但是,在智能座舱终端上运行多种不同任务的深度模型是一个很大的挑战。由于终端的运算资源有限,包括内存、CPU、存储等,深度模型往往尺寸庞大、计算量需求大,因此,当同时运行多个深度模型算法时,会导致终端运算资源不足,算法响应慢,很难满足实时性的需求。为了解决在运算资源有限的终端上运行深度模型并保证其实时性,深度模型压缩成为至关重要的技术。
2. 深度模型压缩技术
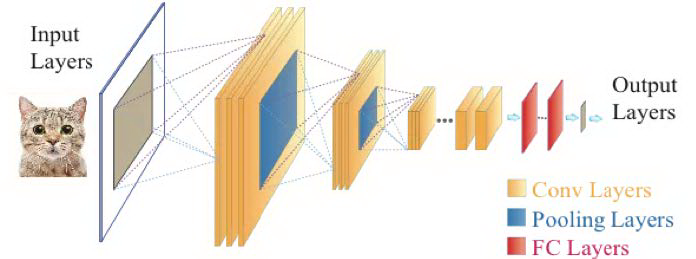
随着深度学习在视觉领域的飞速发展,越来越多的深度模型算法在不同任务上的性能表现超越了传统的视觉算法。首先,我们先介绍视觉领域中常见的深度模型。图 2 展示了一个通用的深度卷积模型,深度卷积模型主要组成部分有卷积层(Conv Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。其中,卷积层的主要作用是特征提取,在一个卷积层中,通常由若干个卷积核(filter)构成。卷积核也包含各类参数,例如卷积核大小(1x1,3x3 等)、步长大小(stride)等。池化层的作用主要是降低特征图的维度。全连接层一般是负责对提取的特征进行分类。
深度模型压缩技术主要是压缩什么呢?最主要是找到模型中不同层面的冗余,其中包括权重的数量以及权重的表达位数。我们将介绍三种主流的深度模型压缩技术,模型剪枝、模型量化以及知识蒸馏。
2.1 剪枝(weight pruning)
深度模型实际是由若干的权重矩阵所构成,其中有些权重对结果影响比较小,甚至有负面影响,深度模型剪枝技术可以将这些不重要的权重进行裁剪, 减少深度模型结构中的参数量的冗余,从而达到压缩模型的目的。
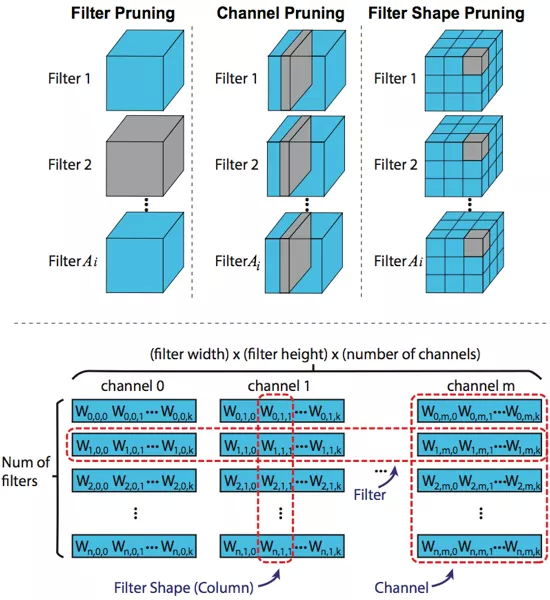
剪枝可以对任意位置的权重进行剪枝,通常叫做非结构化剪枝(unstructured pruning),对权重进行结构性的剪枝即为结构化剪枝(structured pruning)。图 3 上半部分展示了不同维度的三种结构化剪枝,包括输出通道剪枝(filter pruning),输入通道剪枝(channel pruning)以及输出通道形状剪枝(filter shape/column pruning)。输出通道剪枝是直接删除一个卷积层中的一个卷积核。输入通道剪枝是删除一个卷积层中每个卷积核对应的相同位置的输入通道。输出通道形状剪枝是删除一个卷积层中每个卷积核上相同位置的权重。图 3 下半部分展示了推理过程中卷积层展开的通用矩阵乘法(GEMM,General Matrix Multiply)的权重矩阵。在该矩阵中,每行代表一个卷积核(对应 filter pruning),每列对应的是每个卷积核上相同位置的权重(对应 filter shape pruning)。一段连续列则代表一个输入通道(对应 channel pruning)。
在深度模型中,评价权重的重要程度的方式有多种,最常见的就是计算权重的绝对值(之和),即 L1 范数(L1 norm),通过该值的大小来判断是否重要。也有其他的方式,例如根据 batch norm 层的参数作为评估标准并进行卷积核剪枝等。很多模型剪枝算法都需要手工设计裁剪阈值或者比率,例如设置|w| < 0.01,或者设置每层的剪枝率。这种人为的设计过程需要依赖很多专业的经验,并且该过程需要反复尝试。因此人为设计剪枝的方案往往难以达到最优的效果并且浪费人工成本。
2.1.1 自动化剪枝
如何解决这个问题呢?我们基于 AutoML 的思想,提出了自动结构化剪枝的算法框架 AutoCompress,能自动化的去寻找深度模型剪枝中的超参数,去除模型中不同层的参数冗余,替代人工设计的过程,从而满足嵌入式端上运行深度模型的实时性能需求。
如图 4 所示,整个自动化通用流程主要可以分为四步。步骤一是行为抽样,步骤二是快速评估,步骤三是确定决策,步骤四是剪枝操作。由于超参数的搜索空间巨大,考虑到训练资源使用及时间成本,步骤一和步骤二需要快速进行,因此无法进行再训练(re-training)后去评估其效果。算法根据每层中量级最小的一部分权重直接进行剪枝评估。步骤三是根据搜索过程中产生的抽样和评估的集合对超参数进行决策。步骤四利用了动态正则的核心剪枝算法(ADMM,Alternating Direction Method of Multipliers)对模型进行结构化剪枝并生成结果。
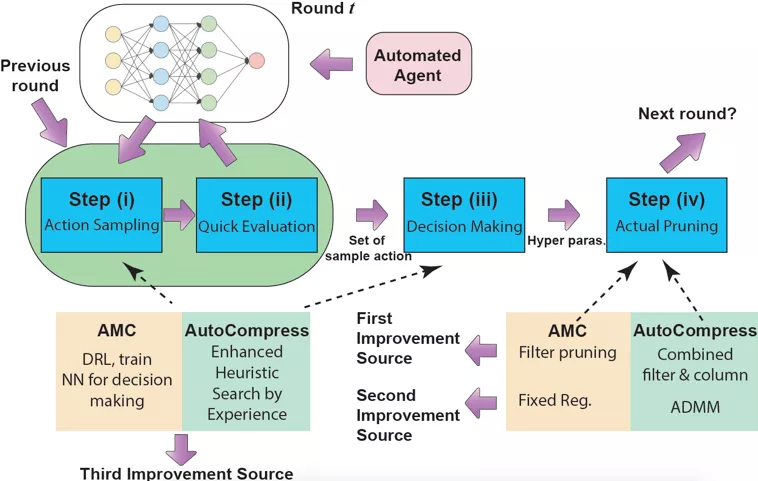
前三个步骤本质上是一个抽样 - 验证的搜索过程,因此,我们采用了启发式的模拟退火算法进行搜索。具体流程是,首先给定一个原始预训练大模型,我们会设置两种目标函数,根据权重数量或者根据运算数量(FLOPs,floating point operations)。整体搜索过程将进行若干轮,例如第一轮目标为压缩两倍权重数量,第二轮为四倍权重数量等。在每一轮搜索过程中,首先初始化一个动作(超参数),每次对动作进行一个扰动(超参数的小幅变化)生成新的动作,根据模拟退火算法原理,评估两个动作,如果新的动作评估结果好则接受,如果新的动作评估结果比原来差则以一定概率接受。每一轮算法中的温度 T 会下降,直到温度下降到某个阈值后停止搜索。
2.1.2 ADMM 剪枝算法
交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)是一种求解凸优化问题的非常强大的方法。在非凸优化问题,ADMM 虽然可能无法收敛到全局最优,但在很多应用中也表现的十分优异。这种方法的主要优势是:
- 将原问题的目标函数分解成若干可求解的子问题
- 子问题可以独立并高效的被求解
- 子问题可以迭代的求解
我们将深度模型的剪枝问题构建成一个带有表达稀疏要求限制的非凸问题。具体来讲,在一个深度模型中,其损失函数通用形式如下:
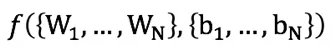
其中 W 表示权重,b 表示 bias。为了进行剪枝,在损失函数中对权重加入约束, e.g., Wi∈Si=Wi∈Si= {小于阈值 αiαi 的非零权重数量}
加入约束后的损失函数由如下两部分组成,原始损失函数 f(⋅)f(⋅) 和约束项的指示函数 g(⋅)g(⋅),公式如下:

上述优化问题的增广拉格朗日函数如下:
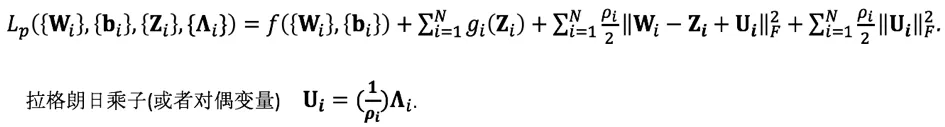
通过 ADMM,将迭代地求解以下子问题实现深度模型稀疏化:
- 子问题(1):更新权重
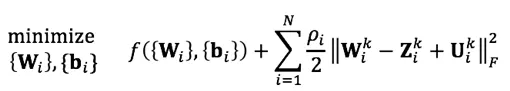
- 子问题(2): 更新正则化目标
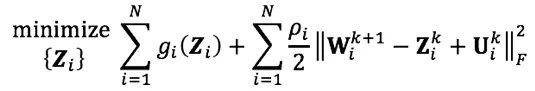
g(⋅)g(⋅) 的 SiSi 指示函数,其解析解是:
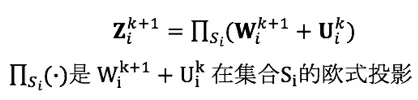
更新缩放的对偶变量 U:
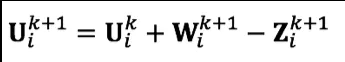
算法终止条件:
ADMM 核心剪枝算法的相关工作 [1] 发表在计算机视觉领域国际会议 ECCV 2018 (The 15th European Conference on Computer Vision),自动化结构剪枝框架 AutoCompress[2] 发表在人工智能领域国际会议 AAAI 2020(The 34th AAAI Conference on Artificial Intelligence)。在实践中,通过剪枝算法,深度模型可以压缩数倍参数量并且准确率保持几乎不变。
2.2 量化
在深度模型中,常用的权重的表达方式是连续的浮点数,其所需的表达位数往往会比较高,例如 float32。权重量化是将权重的表达位数变得更少,从而减少其存储需求,加快模型推理速度。常用的量化方式是将 float32 量化为半精度浮点(FP16)和 8 位定点整数(int8)。量化具体来讲是对权重做映射分类,例如用 8 位定点整数来表示权重,总共可以有类别,量化过程即把原本的连续值映射到这的离散值。这种方式会产生信息损失,量化也往往会产生精度的损失。量化大致可分为两种方式:后量化(post-training quantization)和感知量化训练(quantization-aware training)。后量化是对已训练好的模型进行,这种方式往往会产生较大的精度损失,感知量化是在训练过程中对权重进行量化,因此精度损失较小。
常见的量化是均匀量化过程。所谓的均匀量化是将整体浮点值域区间均匀的映射在定点值域区间内。给定一个浮点数 R,和量化后的数 Q,其映射关系为 R=S∗(Q−Z)R=S∗(Q−Z)。其中 SS(scale)是浮点类型,是浮点数量化成定点数的最小刻度(可以理解为浮点量化时对应的区间)。Z(zero-point)是定点类型,表示的是浮点值为 0 所对应的量化定点值。
计算的公式为:
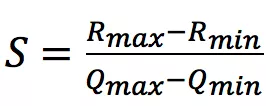
其中,RmaxRmax 表示最大的浮点值,RminRmin 表示最小的浮点值,QmaxQmax 表示最大的定点值,QminQmin 表示最小的定点值。
计算 Z 的公式为:Z=Qmax−Qmax÷SZ=Qmax−Qmax÷S
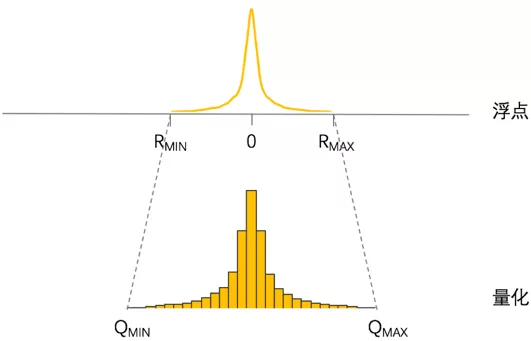
在实践中,常用的方式是将 32 位浮点数(float32)量化为 8 位定点数(int8),这种方式会将存储量降低至原本的 25%,因为寻址一次 float32 相当于四次 int8,因此运算效率更高,在我们实际应用中,端到端推理运行速度可提速高达 30%。
2.3 知识蒸馏
知识蒸馏(knowledge distillation),是 Hilton 于 2014 年在一篇论文里提出的概念 [3]。该论文提出一个方法主要思想是小模型(student)不仅能从给定的、已标签好的数据集中学习知识(训练模型),还能从一个大的深度网络(teacher)中提取知识进行学习。
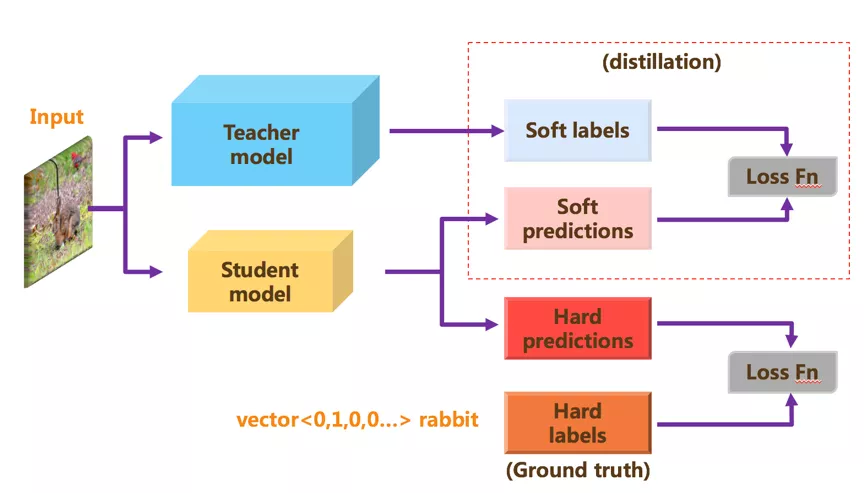
在深度模型中是如何进行的知识蒸馏呢?首先我们要理解知识蒸馏的整体过程是教师与学生。其中教师网络是知识的输出者,提供知识给学生网络。学生网络是知识的接收者,从教师网络中获取知识。图 6 展示了通用的知识蒸馏算法流程框架。通常来讲,教师模型(teacher model)是一个预训练的大模型,学生模型(student model)是压缩后的轻量级小模型。在训练过程中,损失函数(Loss function)由两部分损失(loss)加权组成,一部分是 soft loss,另一部分是 hard loss。Soft loss 是由学生网络预测的 soft predictions 与教师网络预测的 soft labels/targets 计算交叉墒(cross entropy),Hard loss 是由学生网络预测的 hard predictions 与数据真实标签(ground truth)计算交叉墒。通过知识蒸馏的方式,可以有效地提升小模型的性能准确率。
3. 业务与应用场景
3.1 智能座舱
伴随 AI 技术逐步成熟,推动智能座舱沿着机械化 - 电子化 - 智能化不断升级,智能座舱将从满足安全性需求扩展至娱乐体验等个性化需求。智能座舱技术通过感知用户行为,提供个性化及情感化服务,满足更高层级用户需求。
在智能座舱中,存在多种基于深度模型算法的功能,例如基于深度检测模型的驾驶员行为识别(DMS)中的疲劳预警、驾驶行为识别等功能。通过多种深度模型压缩技术的结合,可以将实现智能座舱中多种基于深度模型算法进行压缩,从而达到减少运算数量,达到降低推理加速,从而保证终端上多种深度模型的实时运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号