如何利用AI识别未知——加入未知类(不太靠谱),检测待识别数据和已知样本数据的匹配程度(例如使用CNN降维,再用knn类似距离来实现),将问题转化为特征搜索问题而非决策问题,使用HTM算法(记忆+模式匹配预测就是智能),GAN异常检测,RBF
https://www.researchgate.net/post/How_to_determine_unknown_class_using_neural_network 里面有讨论,说是用rbf神经网络,O-SVM可以搞定
https://www.reddit.com/r/MachineLearning/comments/7t3xei/d_detecting_unknown_classes/ reddit上的讨论,有人专门提到svm是最适合解决这个问题的模型。
I've spent lots of time on that exact subject. i.e. detecting whether or not something will fit into any existing classes.
I was working from a 50,000 text sample, with 600 classes, and with a new class added roughly every two to three days, and the system had to be better than human level.
I've tried almost every standard ML technique, including some of my own.
By far the most successful process was to use an SVM.
I tuned things so that once I had determined that an observation was classifiable, I got 100% classification accuracy on the classifiable observation.
Obviously the train/test split isn't as straightforward as would usually be the case, since I had to segregate items on a class basis.
The SVM left me with around 5% of 'unclassifiable' observations which could in fact have been classifiable, so effectively 95% accuracy. The figure could have been improved if I was happy to also accept incorrectly classified data.
I tried adding a single class SVM on-top of the logits and that seemed to work reasonably well. I also tried using the final dense layer which worked about the same.
from:https://www.zybuluo.com/sambodhi/note/1208157
解决方案是什么?——加入未知类(不太靠谱),检测待识别数据和已知样本数据的匹配程度,
不幸的是,我并不知道如何简单地解决这个问题。好消息是,有一些策略让我看到了希望的曙光。最明显的开始是在训练数据中添加“未知”类。坏消息是,这将带来一系列完全不同的问题,如下:
- 那个类应该包括哪些样本?潜在的自然图像几乎是无限的,所以你要如何选择包括哪些样本呢?
- 在未知类中,你需要多少种不同类型的物体?
- 对于看起来与你关心的类非常相似的位置物体,你应该如何处置?例如,添加一个不在ImageNet 1000中的犬种,但它看起来跟数据集中的犬种几乎相似,可能会强制许多正确的匹配进入“未知桶”中。
- 你的训练数据中,有多少比例应该是由未知类的样本组成?
上述最后一点实际上涉及到了一个更大的问题。从图像分类网络得到的预测值不是概率。它们假设看到的任何特定类的几率等于这个类在训练数据中出现的频率。如果你尝试使用包括亚马逊丛林的企鹅在内的动物分类器,你就会遇到这个问题,因为(可能)所有的企鹅的目击报告都是误报。即使是美国城市的犬种,在ImageNet训练数据中,稀有品种出现的频率也要高于出现在狗狗公园的品种,因此它们经常被误报。通常的解决方案是计算出在生产中遇到的情况下的先验概率是多少,然后使用它们将校准值应用于网络的输出,从而得到更接近实际概率的结果。
有助于解决实际应用中整体问题的主要策略是,将模型的使用限制在对将要出现的物体的假设与训练数据相匹配的情况下。一种简单的方法是通过产品设计来解决问题。你可以创建一个用户界面,指导人们在运行分类器之前,使设备关注你所感兴趣的物体,就像要求你拍摄支票或其他文档的应用一样。
更复杂一点的话,你可以编写一个单独的图像分类器,尝试识别主图像分类器没有为之设计的条件。这与添加一个“未知”类不同,因为它更像是一个级联,或者详细模型之前的一个过滤器。在作物发生病害的情况下,操作环境在视觉上足够清晰,因此,只需训练模型来区分叶片和随机选择的其他照片即可。由于有足够的相似之处,门控模型至少应该能够判断图像是否在不受支持的场景中拍摄。这个门控模型将在完整的图像分类器之前运行,如果它没有检测到看起来像是一个植物的东西,它将会提前显示出错误信息,表明没有发现任何作物。
要求你给信用卡拍照或者执行其他类型OCR的应用,通常会结合使用手机屏幕的方向和检测模糊度的模型,或拍照未对准时引导用户正确拍照可成功处理的照片,还有一种“是否存在叶片”的模型,是这个界面模式的简单版本。
这可能不是一组非常令人满意的答案,但是这正反映出了,当机器学习超出了一定的研究问题范围,用户所期望的结果是各不相同的。人们对物体的识别,有很多常识和外部知识,而在经典的图像分类任务中并没有这些知识。为了得到满足用户期望的结果,我们必须围绕我们的模型设计一个完整的系统,该系统能够理解将要部署到的世界,并且不仅仅是基于模型输出即可作出明智的决策。
下文使用了CNN降维,再用knn类似距离来实现。
基于深度学习的未知调制类型的信号识别
【学位级别】:硕士
【学位授予年份】:2018
【分类号】:TN911.7;TP181
在这里我们可以得出一个结论:如果分类器在测试域中不是分类完全的,那么分类器在测试域中未定义的类别,如果被强制分类那么一定会被错分。
我们知道人对于任意概念如果知道其类别那么将其分类,如果不知道其类别那么分类为"未见过类别"。所以我们引申出一个问题,对于算法F,任意的概念C在训练域中是PAC可学习的,且测试域的某些概念X不属于训练域,也就是训练域中没有关于概念X的数据,在训练域中训练出的算法F如何将概念X分类为"未见过类别"?
分类与域描述
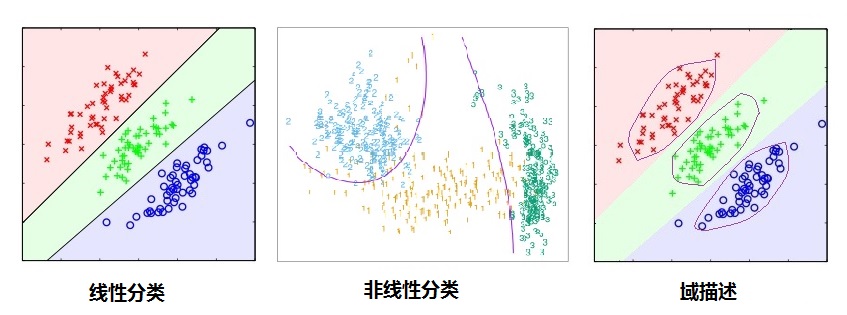
如上图所示,我们可以明显看到分类(判别)算法比数据域描述(data domain description)有更松弛的界(boundary),即分类只需要划类间的界限,只要分类算法达到小的分类误差就可以了,而没有具体的描述类别的边界,所以在未见过类别需要区别的时候,分类算法只能决策到已知类别(在低概率拒绝分类的决策分类算法仍然有较大的问题),所以很容易被愚弄[8],而域描述恰恰因为描述了类别的边界,所以能在界之内的数据点分类为已知类别标记,界之外的数据被分类为未见过类别。(不正式的说,在标记类别趋向于无穷大的时候分类算法的界收敛到域描述的界)。
显式优化类间与类内距离
对于分类任务即是优化一个函数F(x)使得代价函数最小,如下Cross Entropy 代价函数
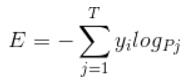
这样得到的决策面就如上图1,2。
为了得到类似于上图域描述的效果,我们可以显式优化内间距离和类内距离,如Contrast Loss[9-11]
或者Triple Loss[12]
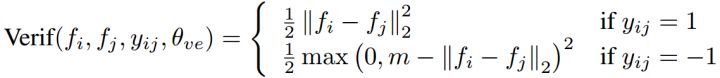
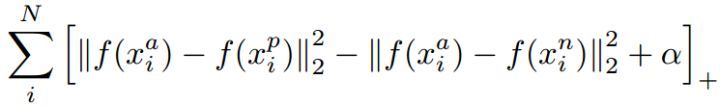
这也是人脸识别面对广域问题(Open-Set)所提出的算法,在人脸识别领域广泛使用,而人脸识别更类似人类大脑识别,其更像是一个特征搜索问题而非决策问题,所以很多人脸识别算法能够解决未见过类别的问题,不管是1:1的对比还1:N的搜索。
判别模型与生成模型
判别模型(discriminative model),判别模型是直接学习p(y|x),即输入输出映射,我们通常的分类算法就是判别模型,如SVM,LR,NN...;
生成模型(generative model)是对p(x,y)进行学习,即学习p(y|x)和p(x),最后p(x,y)=p(y|x)p(x),可以认为p(y|x)为判别模型给出的后验概率,而p(x)为先验概率(也可以叫上下文或者熟悉度,比如是否是熟悉的输入,不熟悉[即不属于训练数据分布的数据] 有较小的p(x)值),而p(x,y)可以理解为给定 x 时 y 的综合置信度,所以生成模型更不容易像判别模型那样将未见过类别分类为错误类别[8]。
---------------------
原文:https://blog.csdn.net/u010165147/article/details/54429644
美国Numenta公司2016年11月14日宣布,实际导入了该公司提出的基于大脑模型的独创神经网络理论“Hierarchical Temporal Memory(HTM)”,与已有的多种DNN(Deep Neural Network,深度神经网络)技术进行了性能比较,获得了良好结果(参阅)。并且该公司还发表了相关。
| 图1:对纽约出租车乘客数量的预测精度超过其他AI技术 左侧为预测误差的比较,HTM的误差最小。右侧为中途变更输入数据的条件时出现的预测误差。4月1日将早晨出租车的需求减少了2成,将夜间需求增加了2成。LSTM6000(绿线)基本不能应对这一变更,而HTM(红线)花了两周左右的时间来学习,之后预测误差逐渐降低。(图片出自Numenta公司) |
Numenta是由美国Palm Computing公司的创始人杰夫·霍金斯(Jeff Hawkins)在2005年创建的企业,从事HTM理论的研发及实用化。据霍金斯介绍,HTM是一种以脑科学的最新知识为基础,以再现大脑新皮质(Neo-Cortex)的功能为目标的神经网络模型。
与已有的DNN最大的不同之处是,“神经元”之间作为开关及存储器的“突触”多很多倍。在以前的DNN中,每个神经元上相当于突触功能的部分最多只有数百个,处于配角地位。而HTM会向1个“神经元”分配数千个“突触”。研究人员认为大脑中实际的神经元每个具有1万个左右的突触。
Numenta提出的HTM算法在性能上的特点是:(1)与已有DNN相比,在时序数据处理上也有很强的能力;(2)可在学习这些时序数据的同时进行推断(也就是能够实现“在线训练”);(3)可同时实施多项推断;(4)不对每个任务做细致调整也可获得良好结果。HTM将大量“突触”用于记录及辨别时序数据的前后逻辑关系。
HTM最近被美国国防高级研究计划局(DARPA)的“Cortical Processor”项目采用,引起了一定的关注。此次Numenta首次实际导入了3月份发表的理论(),通过与竞争技术比较,确认了其工作性能。
迅速跟随数据的变更
通过实验对比了AutoRegressive Integrated Moving Average(ARIMA)、Extreme Learning Machine(ELM)、Long Short Term Memory(LSTM)、Echo State Networks(ESN)等与HTM的工作性能。具体来说,比较了对纽约市的出租车乘客数量做出预测的精度。
结果显示,HTM的预测误差平均值最小(图1左),而且凭借在线训练功能,即使中途变更输入数据的模式,也可迅速学习,降低预测误差(图1右)。而LSTM不能降低预测误差。
霍金斯表示,“我们的第一个目标是查明大脑新皮质的机制。第二个目标是在神经科学与人工智能(AI)之间做桥接。此次的实验结果显示,我们现在正朝着这一目标前进”。
HTM算法的白皮书:https://numenta.com/assets/pdf/biological-and-machine-intelligence/zh-cn/BaMI-HTM-Overview.pdf 有中文翻译版,可以看下。
富士通开发了基于对抗式训练的深度学习技术
针对训练样本缺失的未知类别进行检测
富士通研究开发中心有限公司
富士通研究开发中心有限公司(注1)(以下简称:FRDC)开发出了一项基于对抗式深度学习训练的未知类检测技术。利用该技术在缺失未知类别训练样本数据的情况下,可实现高精度的未知类检测。这项技术通过结合两种数据对同一个识别引擎进行学习,一种数据是已知类别的训练数据,使用常规深度学习对识别引擎进行训练。另一种数据是辅助数据,使用生成对抗式训练方法对识别引擎进行训练。与传统方法相比,在最近的一项对古文献汉字识别的研究中,该技术将未知类检测的相对错误率减少了20%以上。我们希望此项技术能够有助于扩展深度学习的应用范围和客户群体,并且为以后实现通用人工智能平台做出贡献。
【 课题 】
为了能让深度学习系统能进行未知类检测,我们开发了基于对抗式训练的深度学习模型。深度学习系统是基于数据驱动的,训练数据对未知类的检测能力有着重要的作用,如图1第一排所示,训练数据只包含白色的狗和棕色猫的图像,基于闭集识别的深度学习模型将一只白熊(测试图像)错误地标记为狗。相对训练数据集来说白熊是未知的类,用只含狗和猫的训练数据训练的网络难以检测到未知类白熊。如图1中第二排所示,我们开发的基于对抗式训练的深度学习模型采用外部辅助数据让模型学习到未知类的相关特征,从而检测到未知类。
 图1 基于对抗式训练的深度学习模型能检测未知类别
图1 基于对抗式训练的深度学习模型能检测未知类别【 开发的技术 】
1.利用已知类数据学习特征的表达和分类
对于已知类别的数据训练一个基于卷积神经网络的分类器,在获得高精度识别率的同时得到对已知类别的特征表示。为了提高深度学习系统检测未知类的能力,我们采用两个策略来训练卷积神经网络,一个策略保证分类的准确性,另一个策略提升已知类样本特征之间的相似性,从而有利于未知类的检测。
2.利用辅助数据增强特征表达
为了深度学习系统更好地检测未知类别,我们尝试使用辅助数据来增强特征。我们算法的特点是辅助数据无需数据标注,适应性广。算法采用生成对抗网络(Generative Adversarial Network)进行特征学习。我们利用前面提到的已知类数据和辅助数据联合优化网络以得到用于未知类检测的特征表达。最后,我们从训练好的网络模型中提取特征用于未知类检测。
 图2 基于对抗式训练的特征提取框架
图2 基于对抗式训练的特征提取框架【 效果】
所开发的技术应用于敦煌古文献汉字字符集(注2),当错误接受率为10%,未知类的检测率从52%提高到了63%的检测率;当错误接受率为20%,检测率从73%提高到82%。错误接受率是指待检测样本为已知类,但系统将它归类为未知类的比例。
 图3 针对敦煌古文献未知汉字检测结果
图3 针对敦煌古文献未知汉字检测结果【 将来 】
该技术的目标是在2018年度应用到富士通的人工智能技术平台(Zinrai)当中,同时也将继续把此项技术应用于各种不同的图像识别任务中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号