
[LeetCode] Network Delay Time 网络延迟时间——最短路算法 Bellman-Ford(DP) 和 dijkstra(本质上就是BFS的迭代变种) 动态规划,要会模板!
https://leetcode.com/problems/network-delay-time/
There are N network nodes, labelled 1 to N.
Given times, a list of travel times as directed edges times[i] = (u, v, w), where u is the source node, v is the target node, and w is the time it takes for a signal to travel from source to target.
Now, we send a signal from a certain node K. How long will it take for all nodes to receive the signal? If it is impossible, return -1.
Note:
Nwill be in the range[1, 100].Kwill be in the range[1, N].- The length of
timeswill be in the range[1, 6000]. - All edges
times[i] = (u, v, w)will have1 <= u, v <= Nand1 <= w <= 100.
这道题给了我们一些有向边,又给了一个结点K,问至少需要多少时间才能从K到达任何一个结点。这实际上是一个有向图求最短路径的问题,我们求出K点到每一个点到最短路径,然后取其中最大的一个就是需要的时间了。
可以想成从结点K开始有水流向周围扩散,当水流到达最远的一个结点时,那么其他所有的结点一定已经流过水了。最短路径的常用解法有迪杰克斯特拉算法Dijkstra Algorithm, 弗洛伊德算法Floyd-Warshall Algorithm, 和贝尔曼福特算法Bellman-Ford Algorithm,其中,Floyd算法是多源最短路径,即求任意点到任意点到最短路径,而Dijkstra算法和Bellman-Ford算法是单源最短路径,即单个点到任意点到最短路径。这里因为起点只有一个K,所以使用单源最短路径就行了。这三种算法还有一点不同,就是Dijkstra算法处理有向权重图时,权重必须为正,而另外两种可以处理负权重有向图,但是不能出现负环,所谓负环,就是权重均为负的环。为啥呢,这里要先引入松弛操作Relaxtion,这是这三个算法的核心思想,当有对边 (u, v) 是结点u到结点v,如果 dist(v) > dist(u) + w(u, v),那么 dist(v) 就可以被更新,这是所有这些的算法的核心操作。Dijkstra算法是以起点为中心,向外层层扩展,直到扩展到终点为止。根据这特性,用BFS来实现时再好不过了。
class Solution(object):
def networkDelayTime(self, times, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
inf = float('inf')
dp = [inf]*(N+1)
dp[K] = 0
for i in range(1, N): # N+1 is not neccessary
for u,v,w in times:
#if v == i:
dp[v] = min(dp[v], dp[u]+w)
max_d = max(dp[1:])
return -1 if max_d == inf else max_d
注意:(1) 我以为是要加一个if判断,实际上是错的。迭代是针对图里所有边,第一次迭代找到的是source点走一次直接连接的最短路。第二次是走二次的最短路迭代。一直到第n-1次走的最短路。
(2)为啥是1,N而不是N+1。
为什么要循环n-1次?图有n个点,又不能有回路,所以最短路径最多n-1边。又因为每次循环,至少relax一边所以最多n-1次就行了!
dijkstra解法:
class Solution(object):
def networkDelayTime(self, times, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
return self.dijkstra(times, N, K)
def dijkstra(sefl, times, N, k):
G = collections.defaultdict(dict)
for n1, n2, w in times:
G[n1][n2] = w
inf = float('inf')
dist = {node:inf for node in range(1, N+1)}
dist[k] = 0
nodes = set(range(1, N+1))
while nodes:
node = min(nodes, key=dist.get)
# update dist
for n in G[node]:
dist[n] = min(dist[n], dist[node] + G[node][n])
# node visited
nodes.remove(node)
max_dist = -1
for node in dist:
if node != k:
max_dist = max(max_dist, dist[node])
return max_dist if max_dist != inf else -1
或者将dist数据结构修改为list
class Solution(object):
def networkDelayTime(self, times, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
return self.dijkstra(times, N, K)
def dijkstra(sefl, times, N, k):
G = collections.defaultdict(dict)
for n1, n2, w in times:
G[n1][n2] = w
inf = float('inf')
dist = [inf]*(N+1)
dist[k] = 0
nodes = set(range(1, N+1))
while nodes:
node = min(nodes, key=dist.__getitem__)
# update dist
for n in G[node]:
dist[n] = min(dist[n], dist[node] + G[node][n])
# node visited
nodes.remove(node)
max_dist = max(dist[1:])
return max_dist if max_dist != inf else -1
==》dj的见bfs模板,上面自己写的不优雅!
787. K 站中转内最便宜的航班
有 n 个城市通过一些航班连接。给你一个数组 flights ,其中 flights[i] = [fromi, toi, pricei] ,表示该航班都从城市 fromi 开始,以价格 pricei 抵达 toi。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到出一条最多经过 k 站中转的路线,使得从 src 到 dst 的 价格最便宜 ,并返回该价格。 如果不存在这样的路线,则输出 -1。
示例 1:
输入: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 1 输出: 200 解释: 城市航班图如下
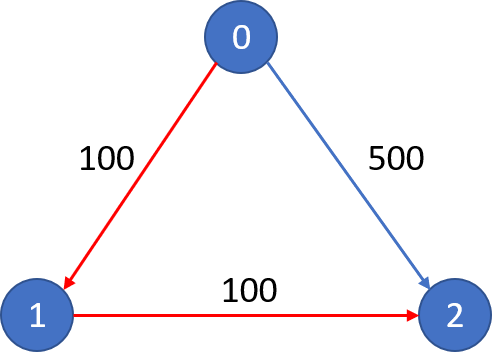
从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
示例 2:
输入: n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] src = 0, dst = 2, k = 0 输出: 500 解释: 城市航班图如下
从城市 0 到城市 2 在 0 站中转以内的最便宜价格是 500,如图中蓝色所示。
解题思路见:https://leetcode.cn/problems/cheapest-flights-within-k-stops/solution/k-zhan-zhong-zhuan-nei-zui-bian-yi-de-ha-abzi/
本质上 就是Bellman-Ford(DP) ,
from collections import defaultdict
from heapq import heappush, heappop
class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, k: int) -> int:
pre = [float("inf")] * n
pre[src] = 0
for _ in range(k + 1):
cur = pre[:]
for i, j, p in flights:
if pre[i] + p < cur[j]:
cur[j] = pre[i] + p
pre = cur[:]
return pre[dst] if pre[dst] < float("inf") else -1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号