02.transformer
transformer说白了就是一个sequence-to-sequence的模型,输入一个sequence,输出一个sequence,并且由机器自己决定要输出的长度是多少,比如语音辨识、机器翻译、语音翻译等任务,输出的sequence都是由机器自己决定。
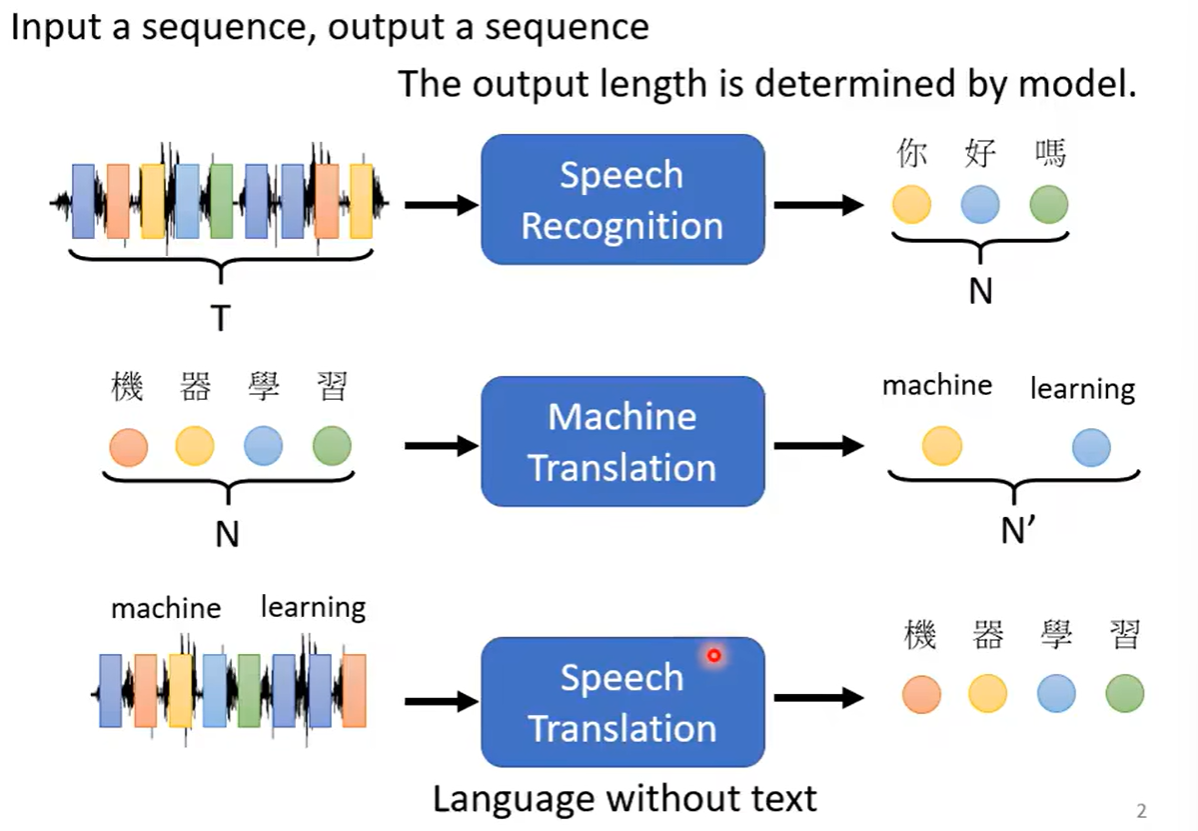
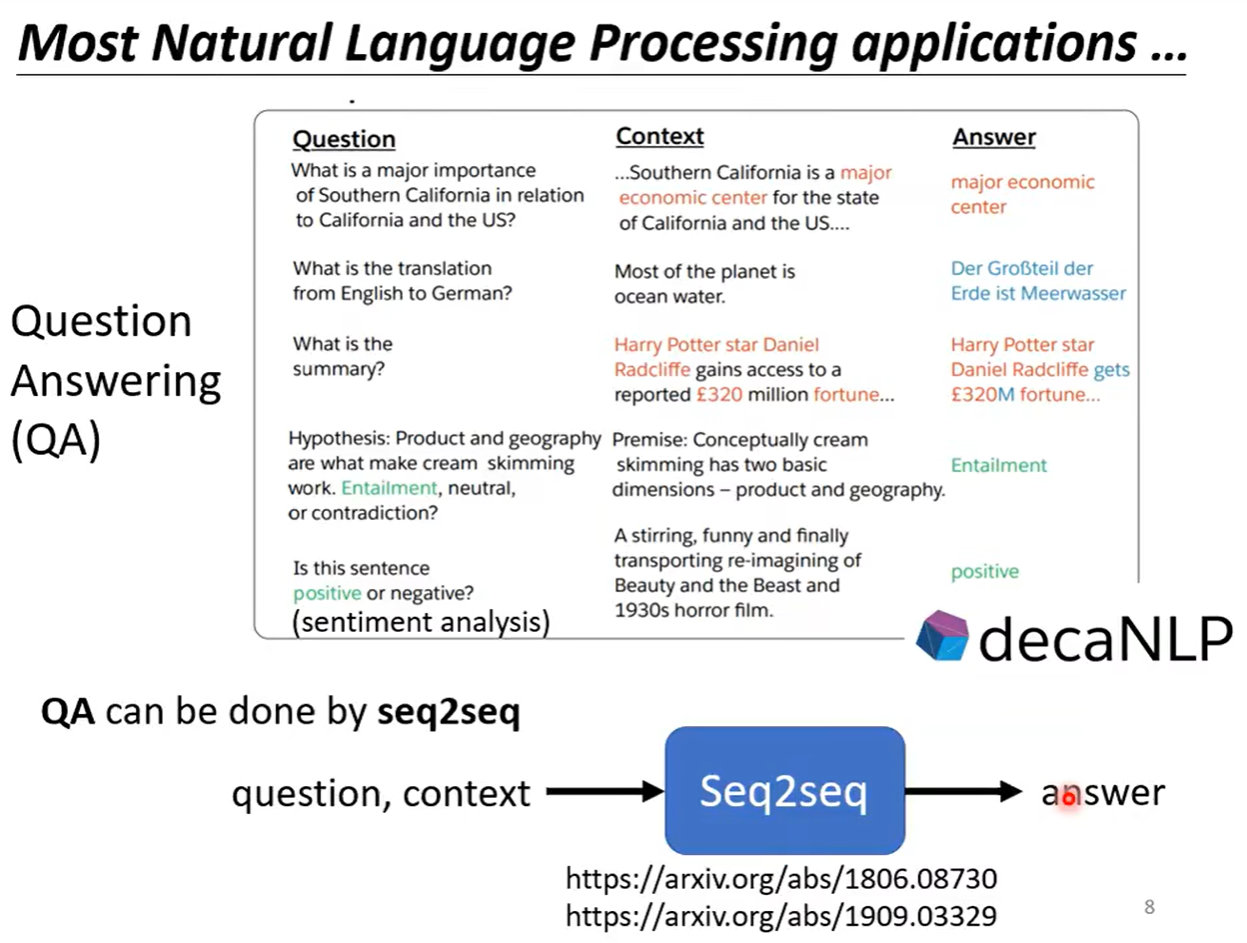
很多种类的NLP的问题都是可以看成QA的问题,而QA的问题都可以用seq2seq的模型来进行解决,但是很多nlp的任务可以通过不同的任务来特定制作模型,效果会更好一些。
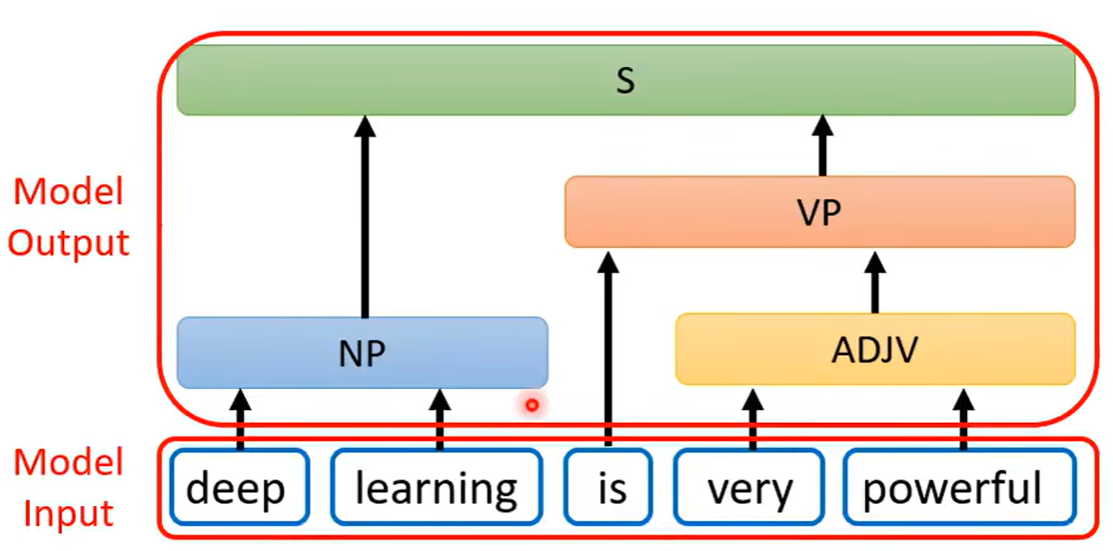
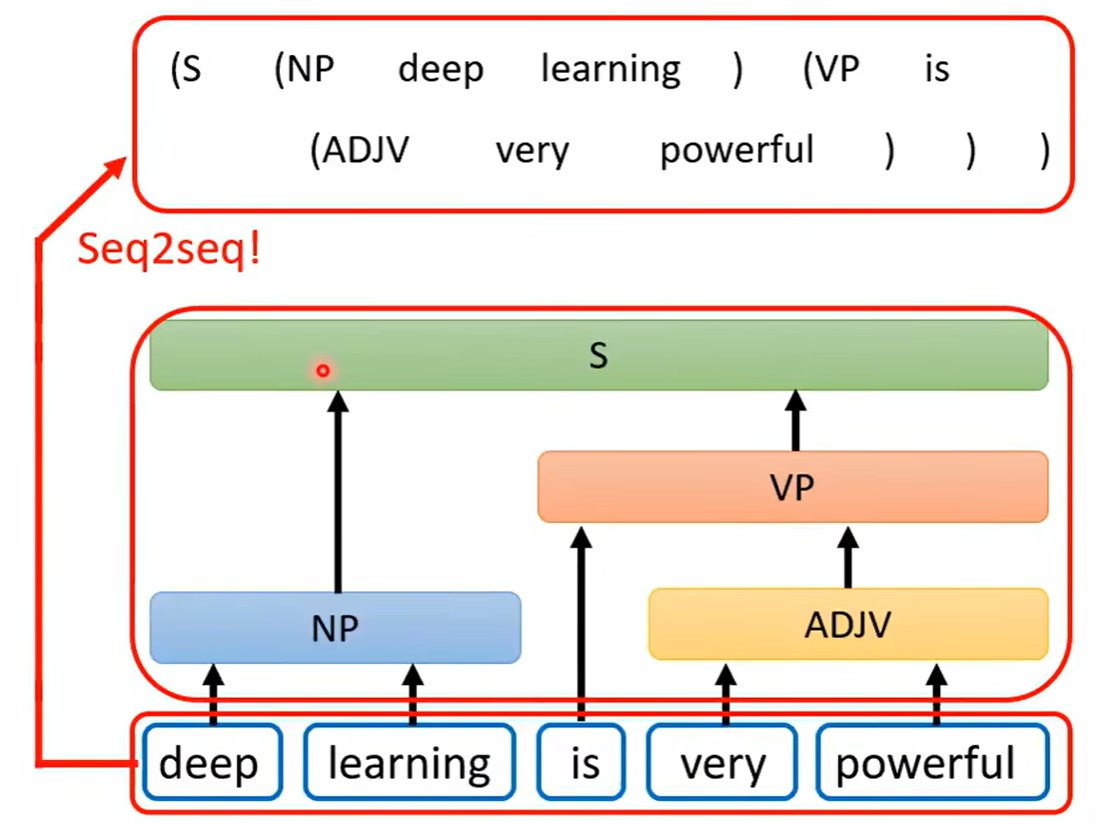
还有一些问题,表面上看并不是seq2seq的问题,但依然是可以使用seq2seq的模型来进行解答,比如文法剖析,可以看到下图中的文法剖析任务中得到的输出是一个树状结构,但树状结构也是可以硬是看作是一个sequence
多标签分类任务也可以使用seq2seq的模型,但是要清楚什么是多标签分类(Multi-label Classification)和多分类任务(Multi-class Classification)
-
多分类任务是可以从多个class里面选择一个出来让要分类的对象属于它
-
多标签分类是同一个东西可能属于多个class,所以叫多标签
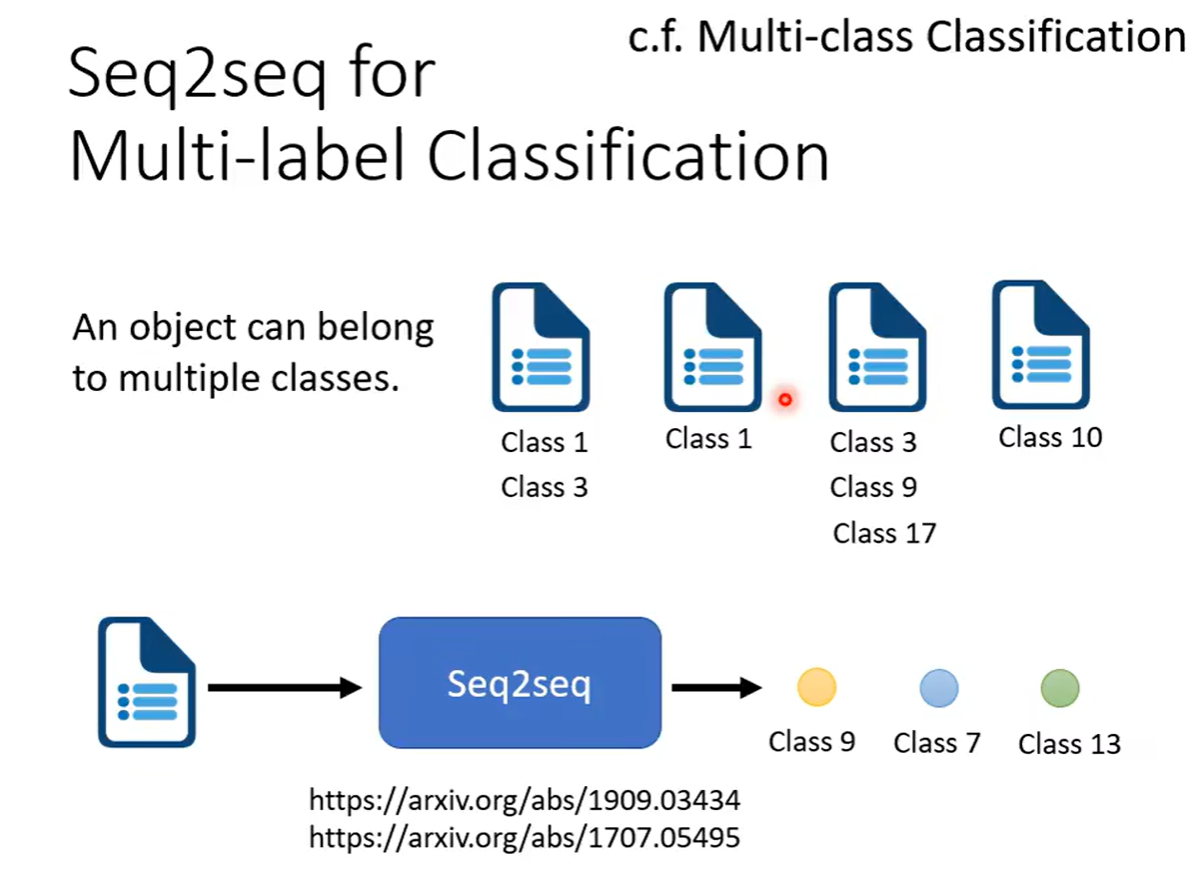
举了这么多例子,那么seq2seq究竟怎么运作?
输入将sequence丢给encoder,之后传给decoder,后面在输出一个sequence
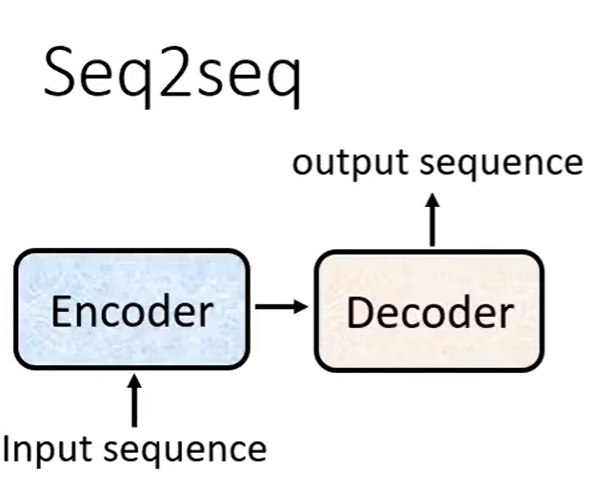
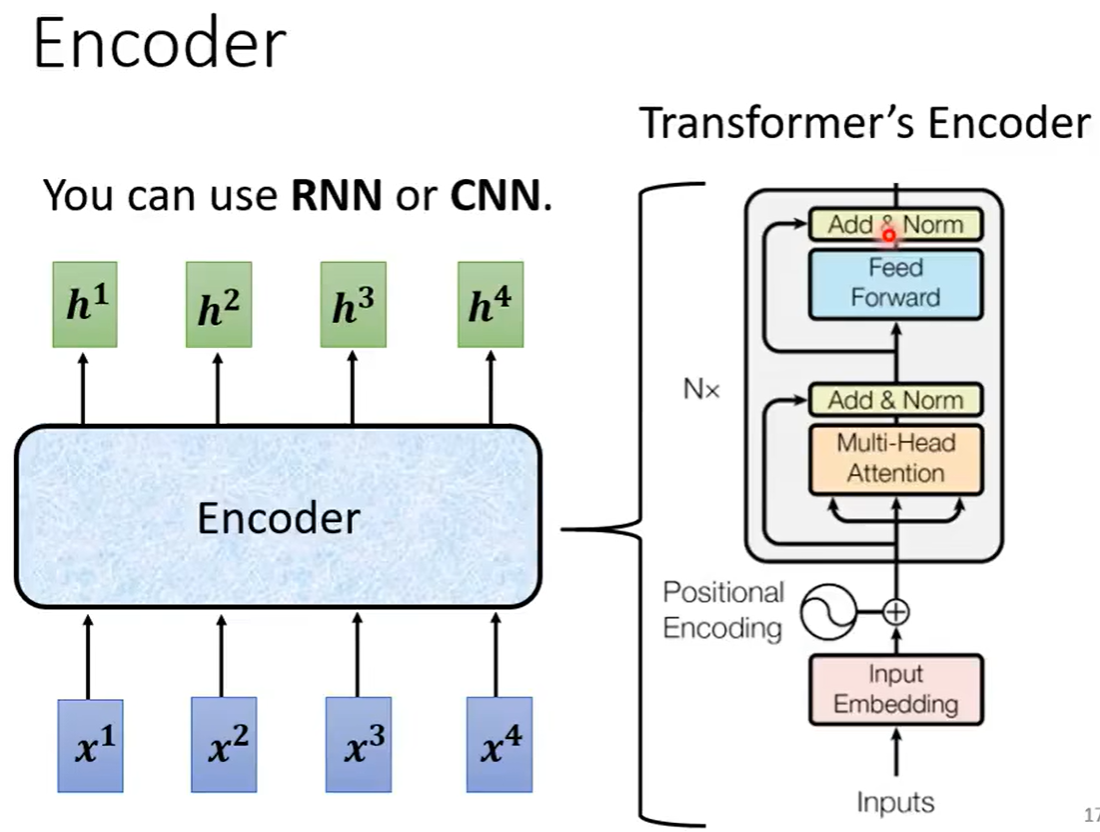
Encoder
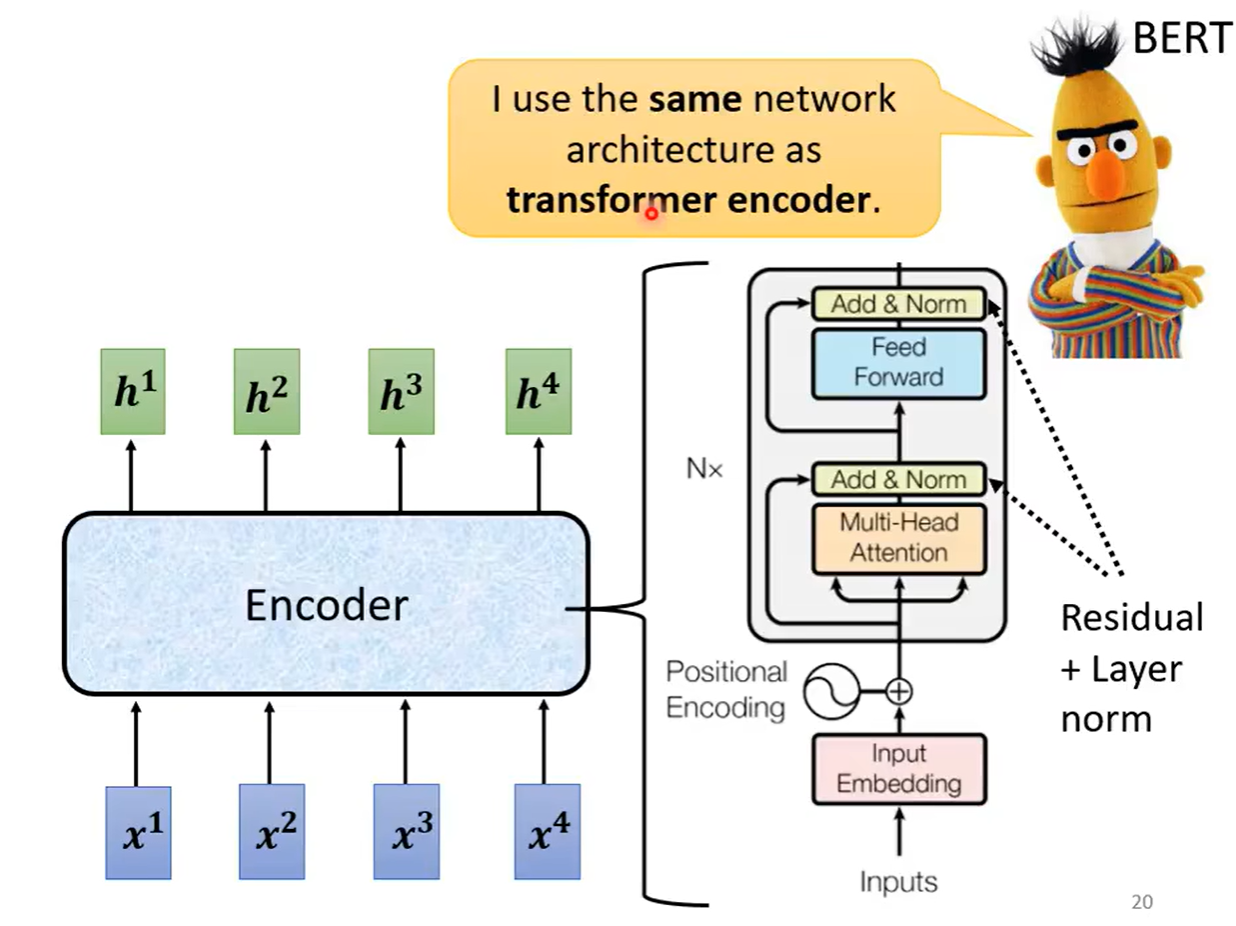
Encoder要做的事情就是,给定一排向量,输出另外一排向量,这样的效果是很多模型都可以做到的,RNN、CNN和self-attention都是可以做到的,那么在transformer中使用的就是self-atention模型。
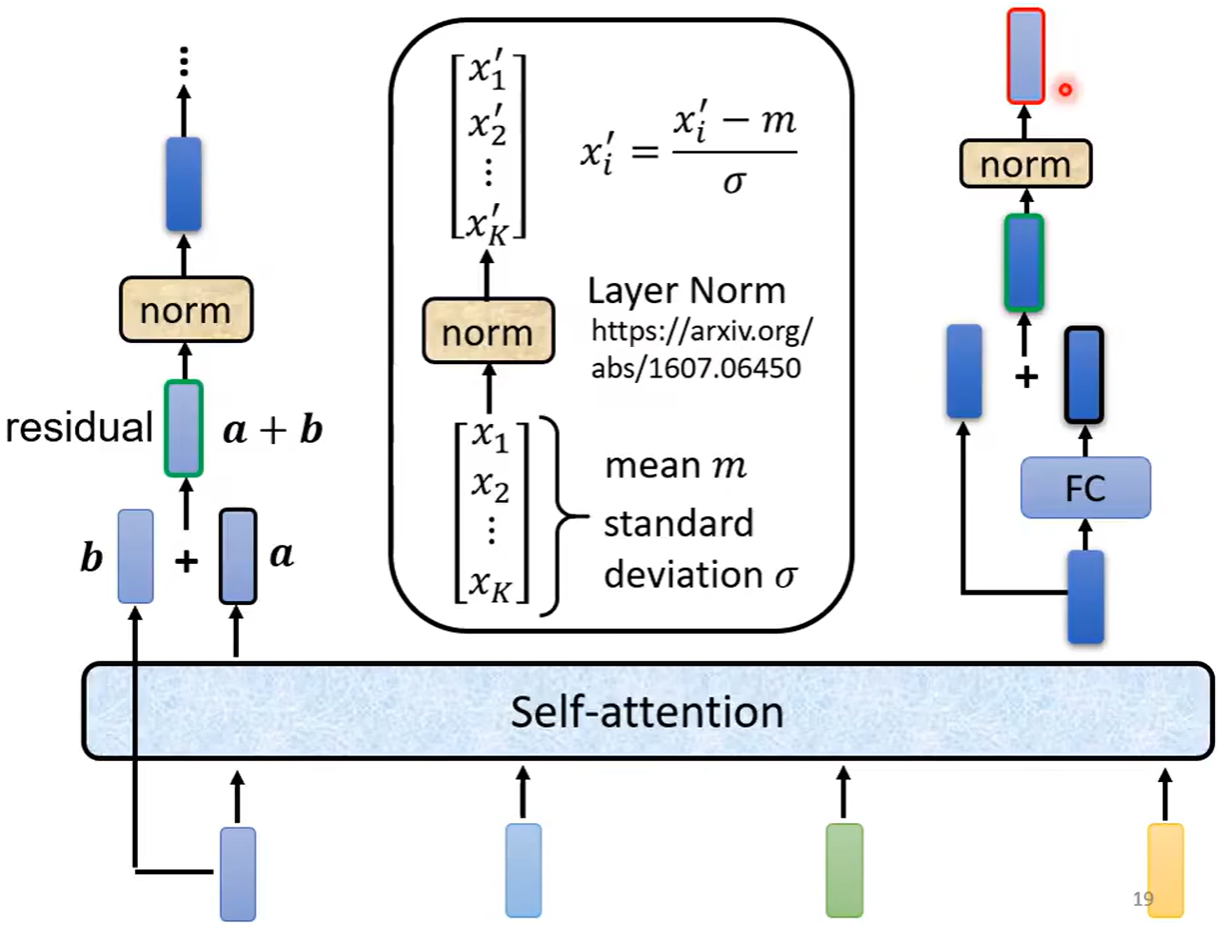
简化一下模型是如下图所示,给定一排向量经过一个block之后输出的向量再进入下一个block,之后经过多个如此循环之后得到最后的向量。但是每个block并不是只做一层做的事情,它先做一个self-attention,之后输出再丢到一个全连接层之中,再输出的一排向量,才是一个block输出的向量
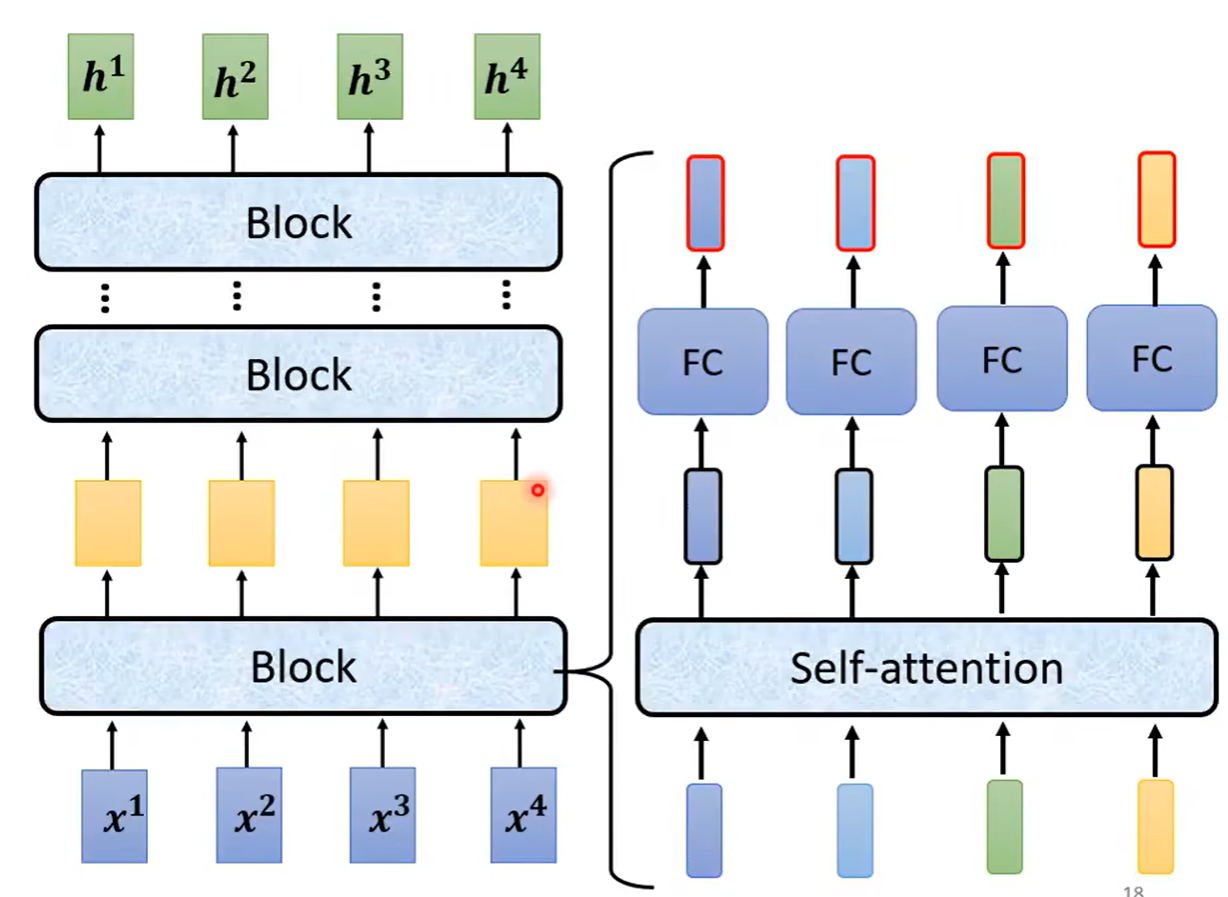
但是在原来的transformer之中,做的事情是更复杂的,每个经历过self-attention的向量都会再加上输入之前的向量,再得到新的输出,之后再进行layer norm(防止梯度消失和特征退化),之后这个标准化的输出才是全连接层的输入,后面全连接层也是有residual的架构(加上input本身),之后再做一次标准化,这个输出才是一个block的输出
Decoder
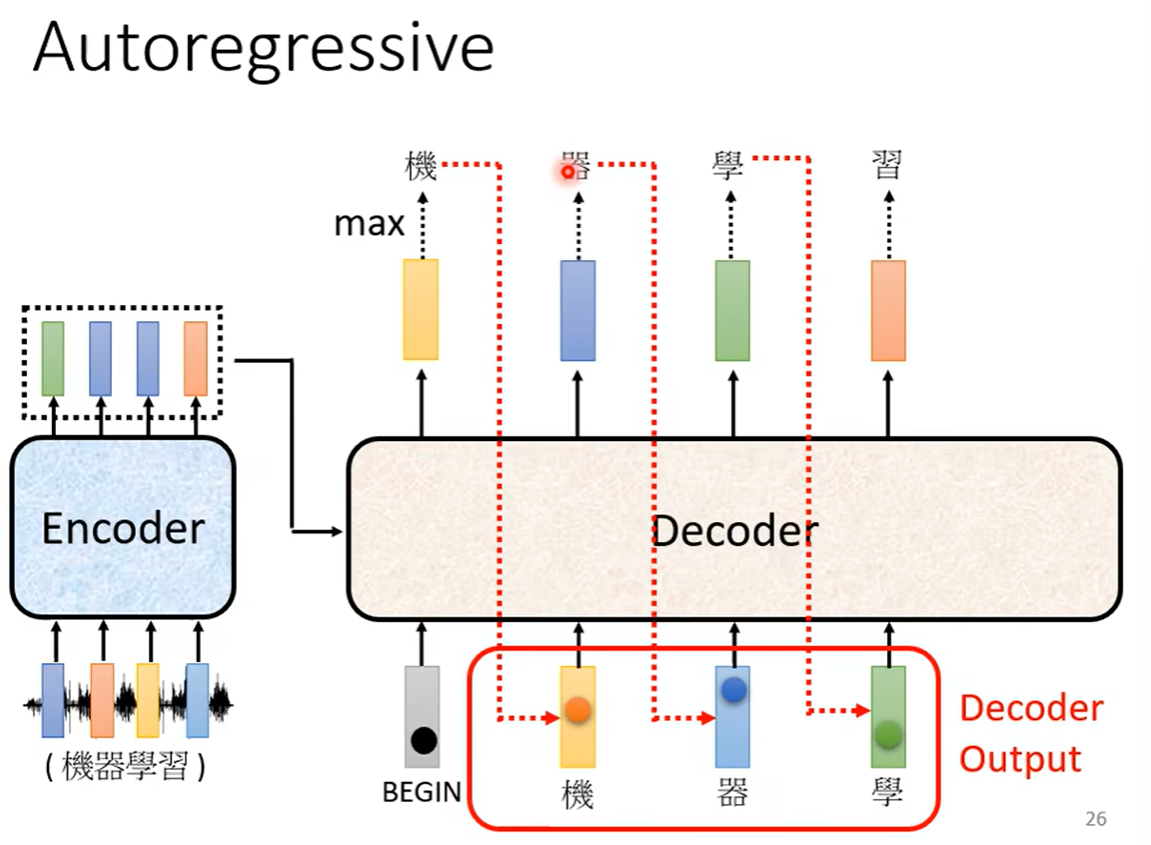
Decoder其实有两种,这里主要介绍常见的Autoregressive,这里使用语音辨识进行举例,语音辨识就是输入一段声音输出一段文字,上面讲的encoder就是把输入的语音向量进行编码之后,输出一排向量,decoder要做的就是encoder的输出先读进去,再产生一段文字。那decoder又是如何产生一段文字呢?
-
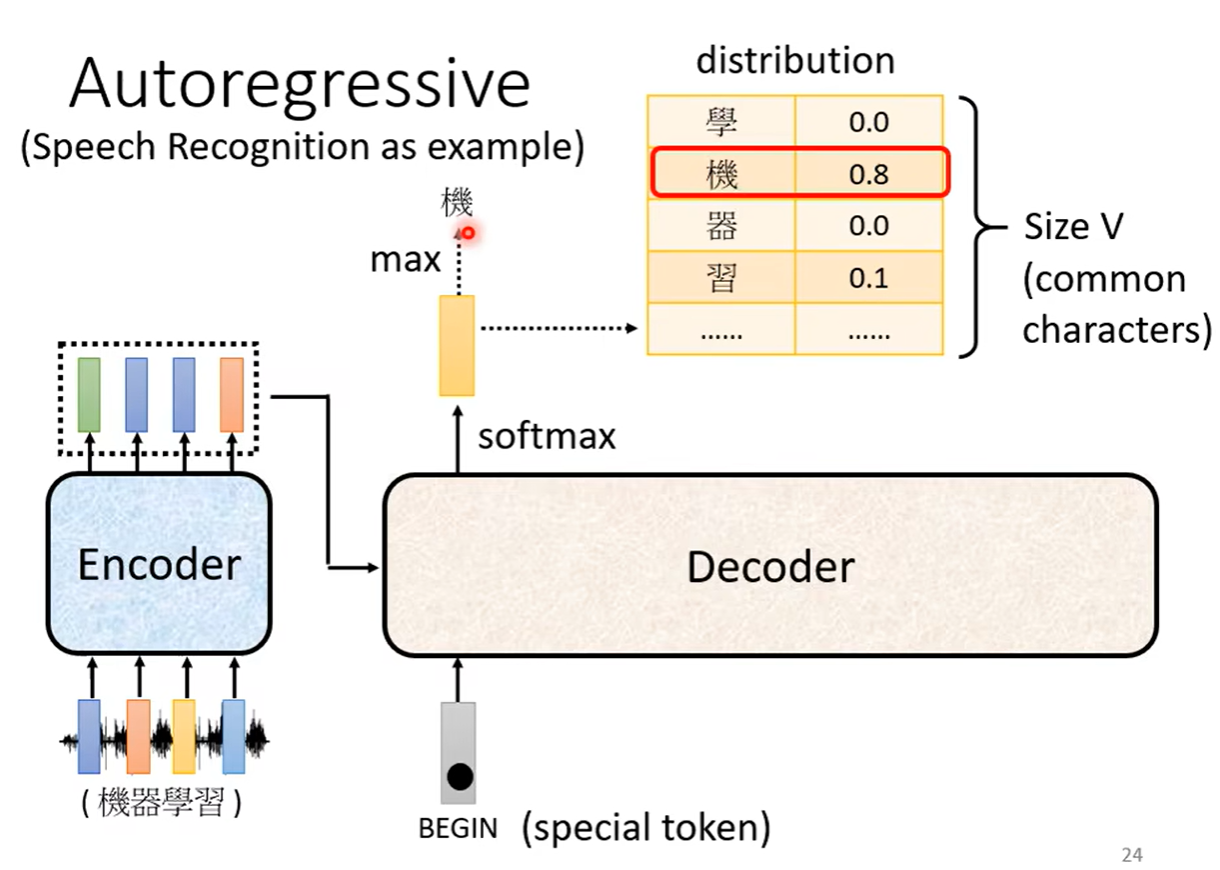
首先先给它一个特殊的符号,这个符号代表开始(BEGIN),这个给符号也可以用独热编码进行表示
-
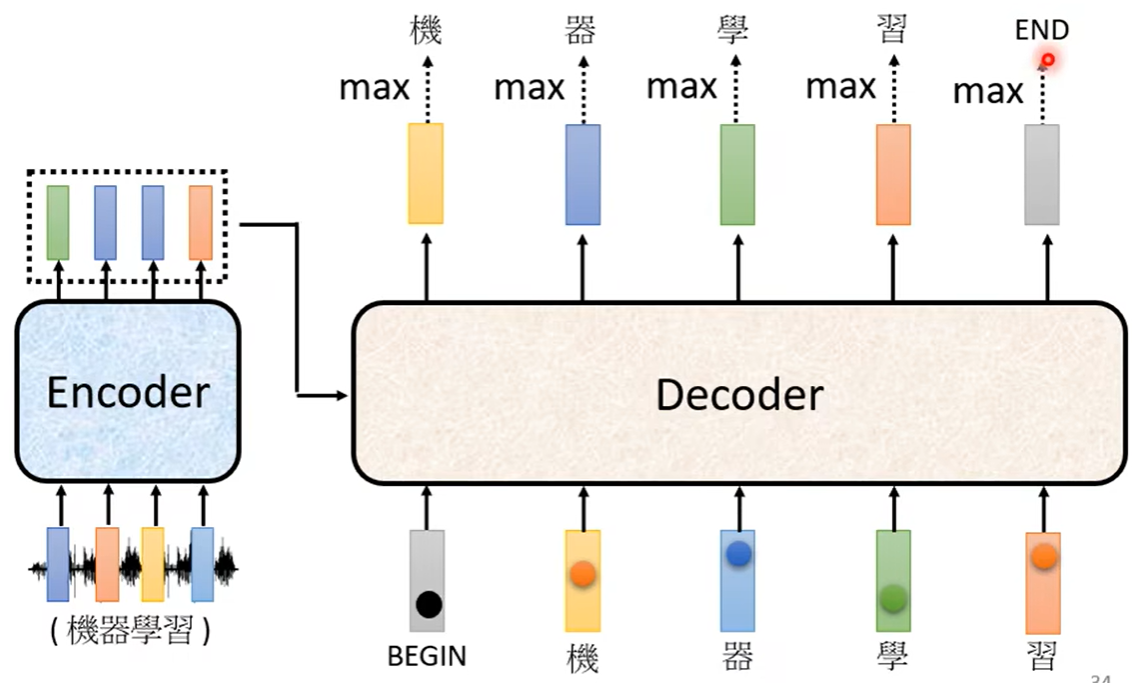
之后decoder输出一个向量,这个向量有很长(向量长度是我们要输出的内容的总长度,比如要输出汉字,那么长度就是汉字的总个数),比如下图中我们选取3000个常见汉字,所以汉字那一列就要列举3000个汉字,每一个汉字后面都会对应一个数值,就是做了一个softmax。所以这个向量后面数字的总和会是1。得到的数值最高的就是最后的输出
![]()
-
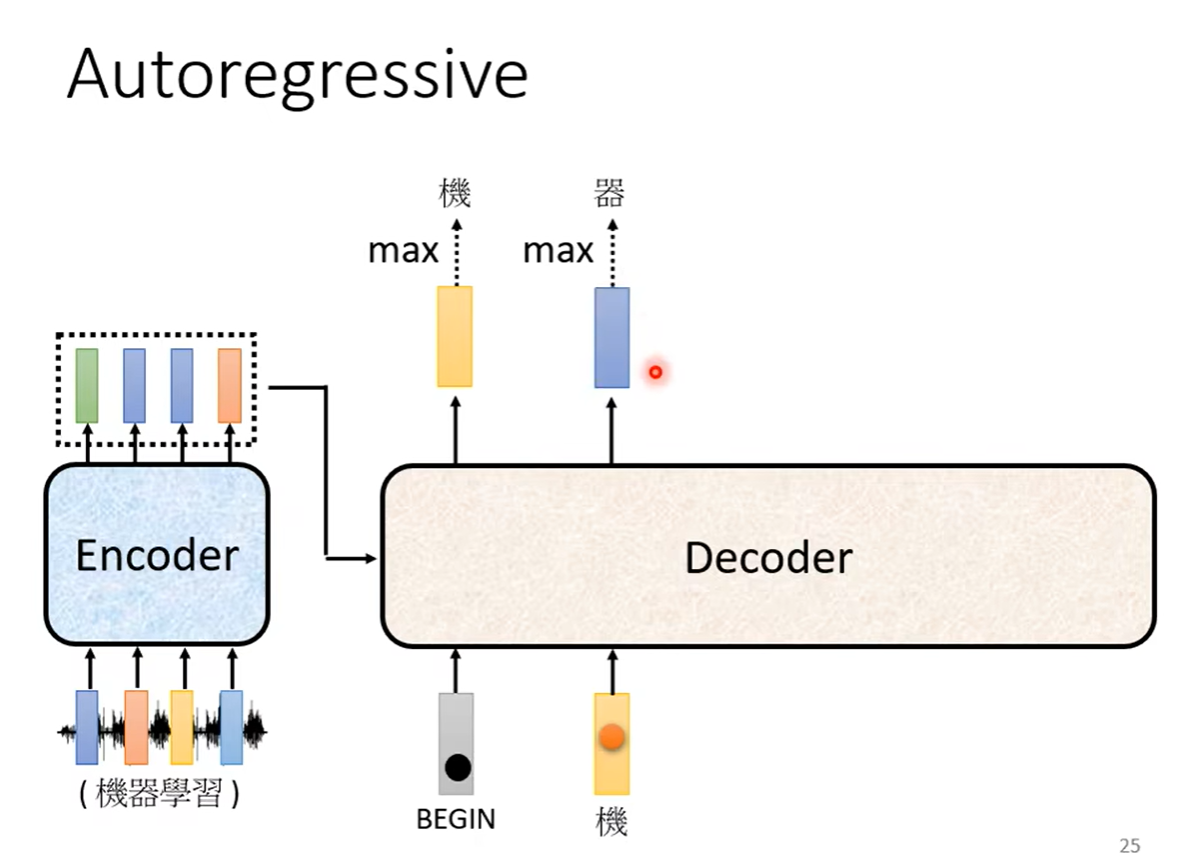
可以看到在这个里面输出的应该是“机”,之后再把这个输出当作decoder新的input,也是把这个字表示成独热向量作为输入,于是此时有两个输入,一个是begin符号一个是机字,根据这两个输入再输出一个向量“器”
![]()
-
同理继续进行下去,也就是说decoder看到的输入,其实是自己前一个时间点自己的输出
![]()
那么decoder的内部结构是什么样的呢?相较于encoder还更为复杂一些
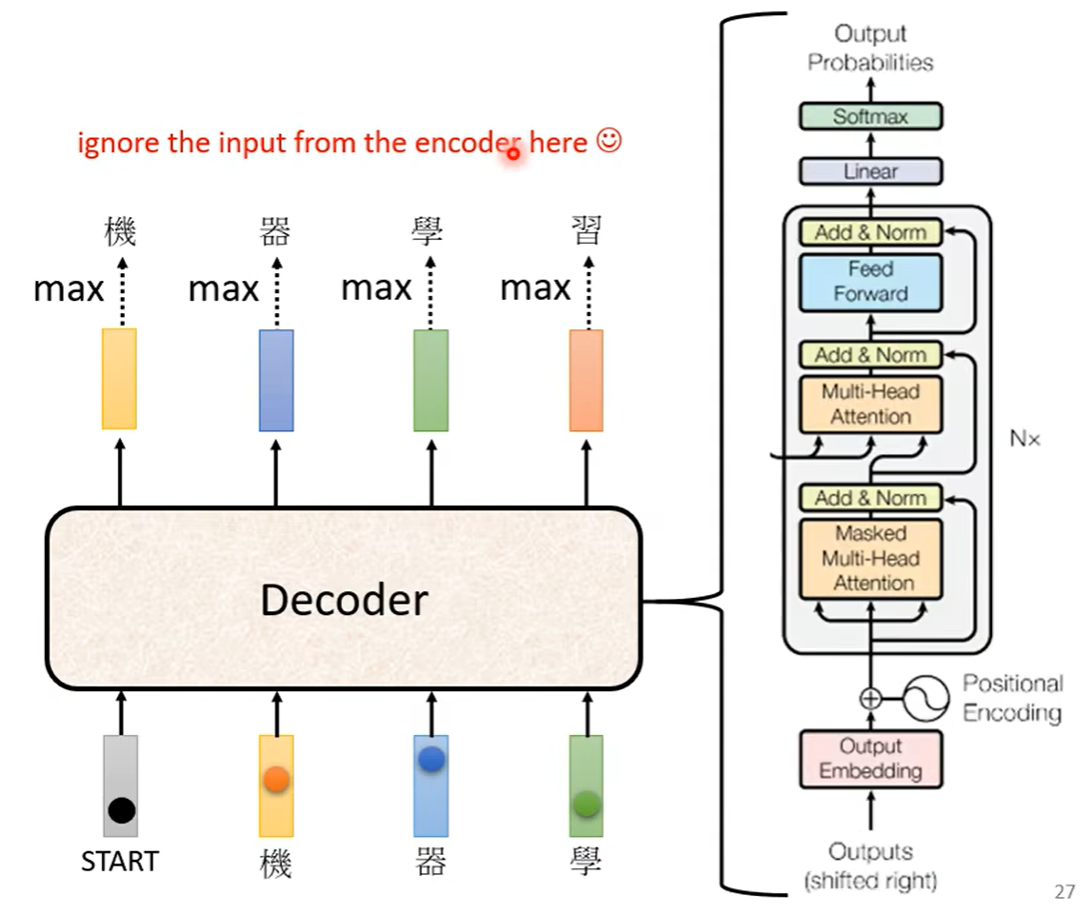
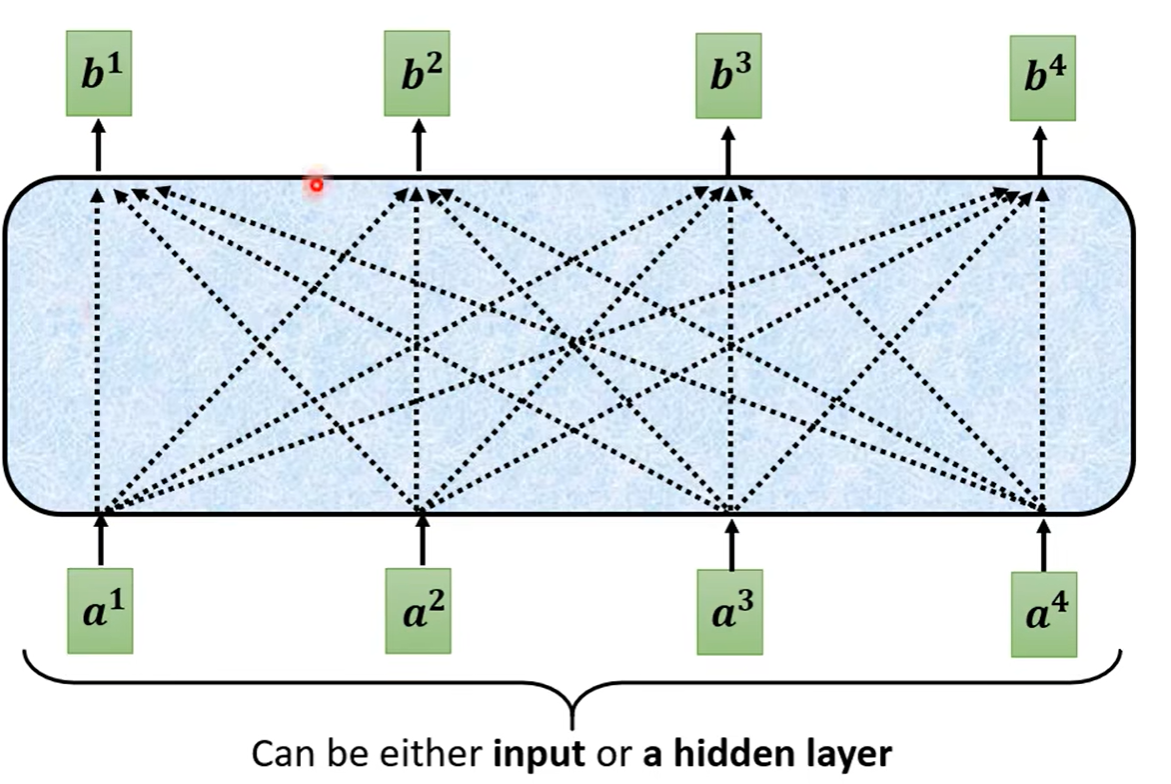
可以发现,在self-attention之中有一个masked self-attention,那么什么是masked呢?常规的self-attention之中,输出的每一个向量都要考虑过完整的input之后才会做决定。
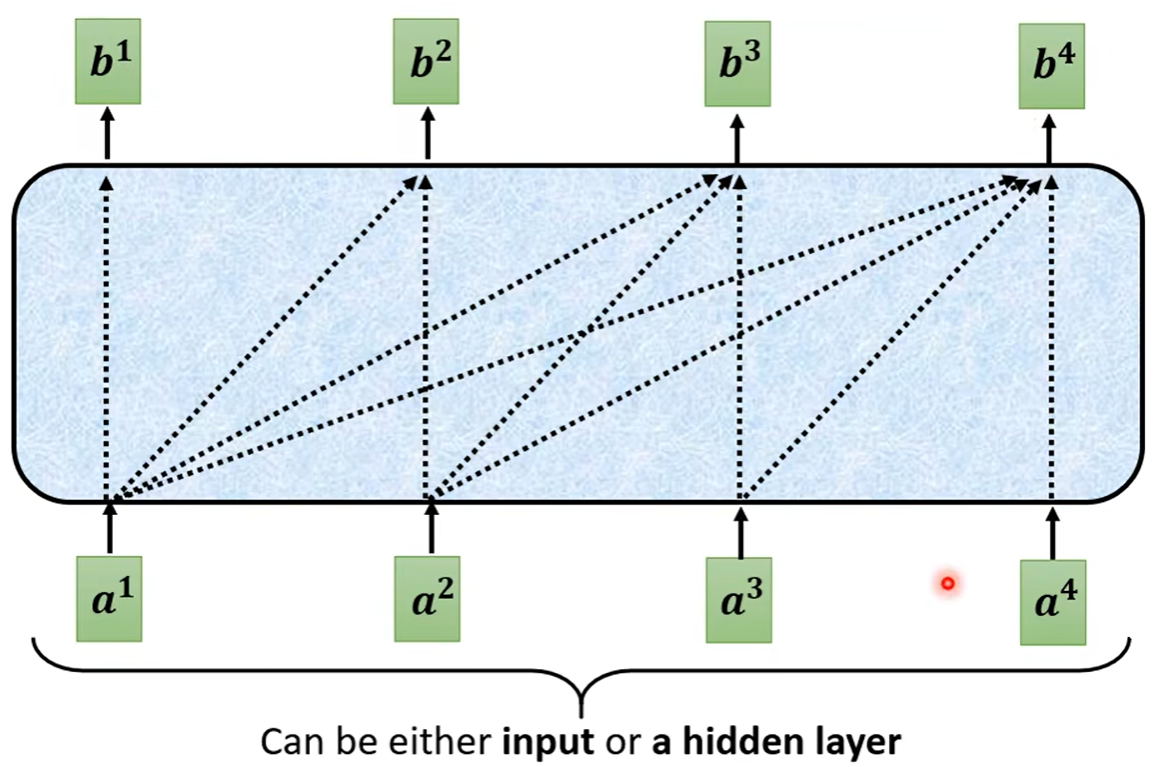
但是masked self-attention的意思也就是不能再考虑右边的部分,也就是产生b1的时候只能考虑a1,产生b2的时候只能考虑a1和a2,如下图所示
那为什么要加masked机制呢?
decoder的向量是一个一个产生出来的,一个产生的向量又被作为下一个要产生的向量的输入。encoder是一次性的把所有输入都读进去的。所有在decoder中的self-attention,才不会把右边的输出考虑进去,是因为a1到a4是按照顺序一个个产生的所以产生b2时并没有后面的a3和a4,也就没办法考虑进去了
decoder必须自己决定输出的sequence的长度。所以为了阻止decoder会一直持续下去生成向量,我们需要准备一个特备的符号“END”。
上面介绍了常见的autoregressive,后面介绍不常见的Non-autoregressive。常见的AT可以理解为一个字一个字的产生,而NAT可能是输入一整排的begin的token,一次产生一排的结果。
但是由于我们并不清楚要输出多少个结果,所以如何确定要输入多少个begin呢?
-
另外找一个预测器predictor来吃encoder的输出,判断有多少个长度,再决定decoder之中要放几个begin
-
假设句子有一个上限,直接输入上线个个数的begin,之后找到哪个地方输除了end,之后后面的都不要了
Encoder和Decoder如何传递信息
encoder的输出得到的向量a之后乘上矩阵得到k,decoder经过self-attention之后得到向量,在乘上矩阵变成decoder的向量q,再和encoder的k进行点乘得到相关系数α,再把α乘上encoder的向量v1...之后再相加得到向量v,之后这个v再做全连接层的处理。上述这个步骤如下图所示,其中k和v来自于encoder,q来自于decoder。这个过程叫做Cross attention
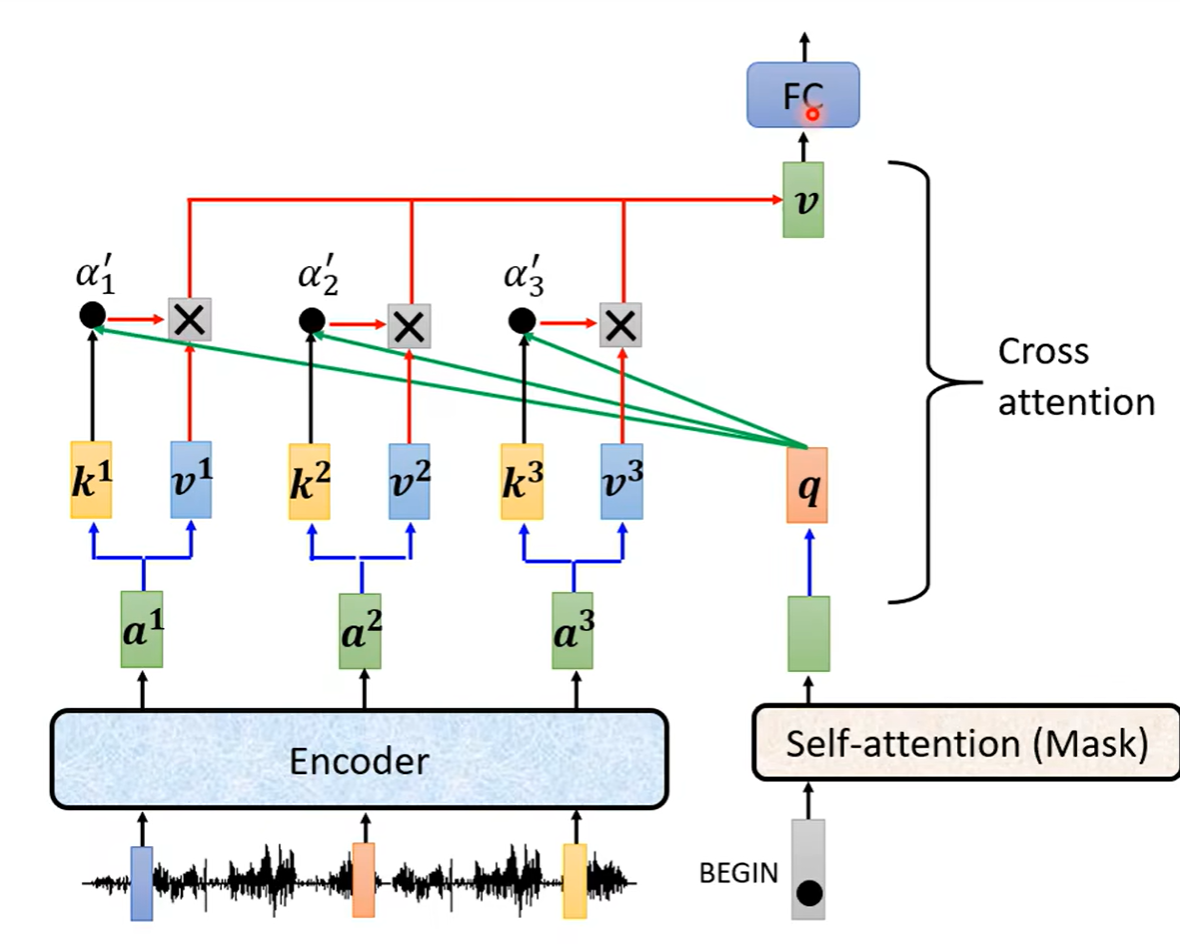
之后每次decoder得到一个向量,都重复一次上述过程
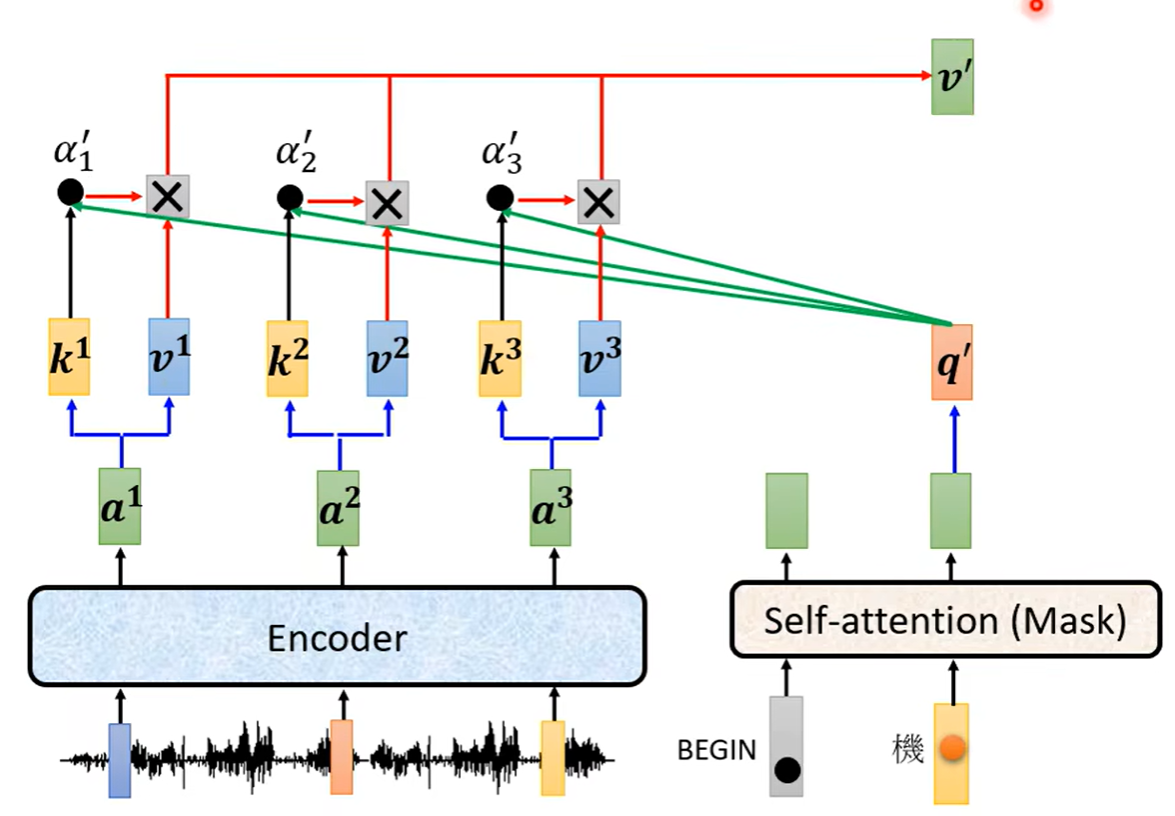
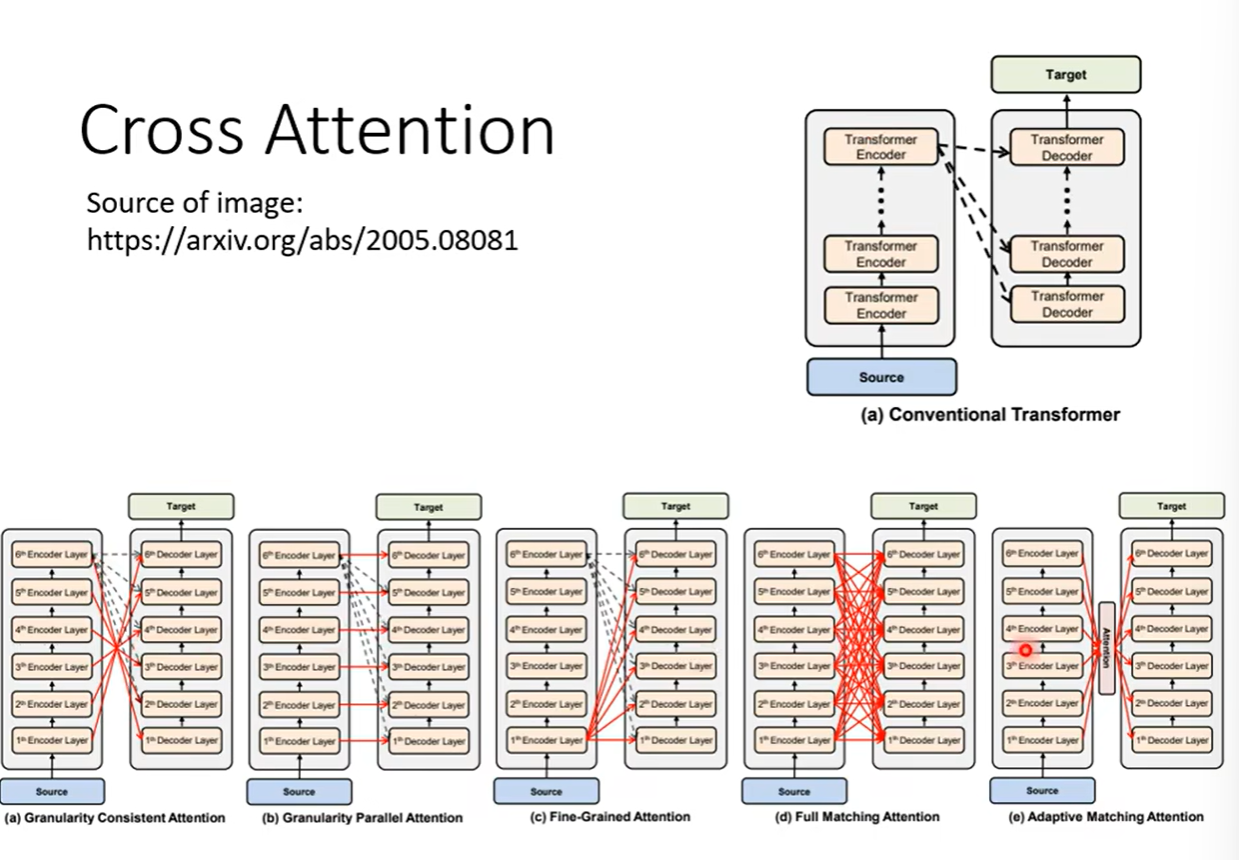
decoder并不是一定要用encoder最后一层的输出,其实可以有很多样式的搭配
训练
还是上面的例子,我们知道第一个字是机器学习的机,所以我们需要第一个输出要跟机越接近越好,由于输出的是一个softmax处理之后的概率分配表格distribution, 所以我们想要的结果是机对应的概率是1,其余的都是0,所以要计算真实值和机器产生的结果之间的误差
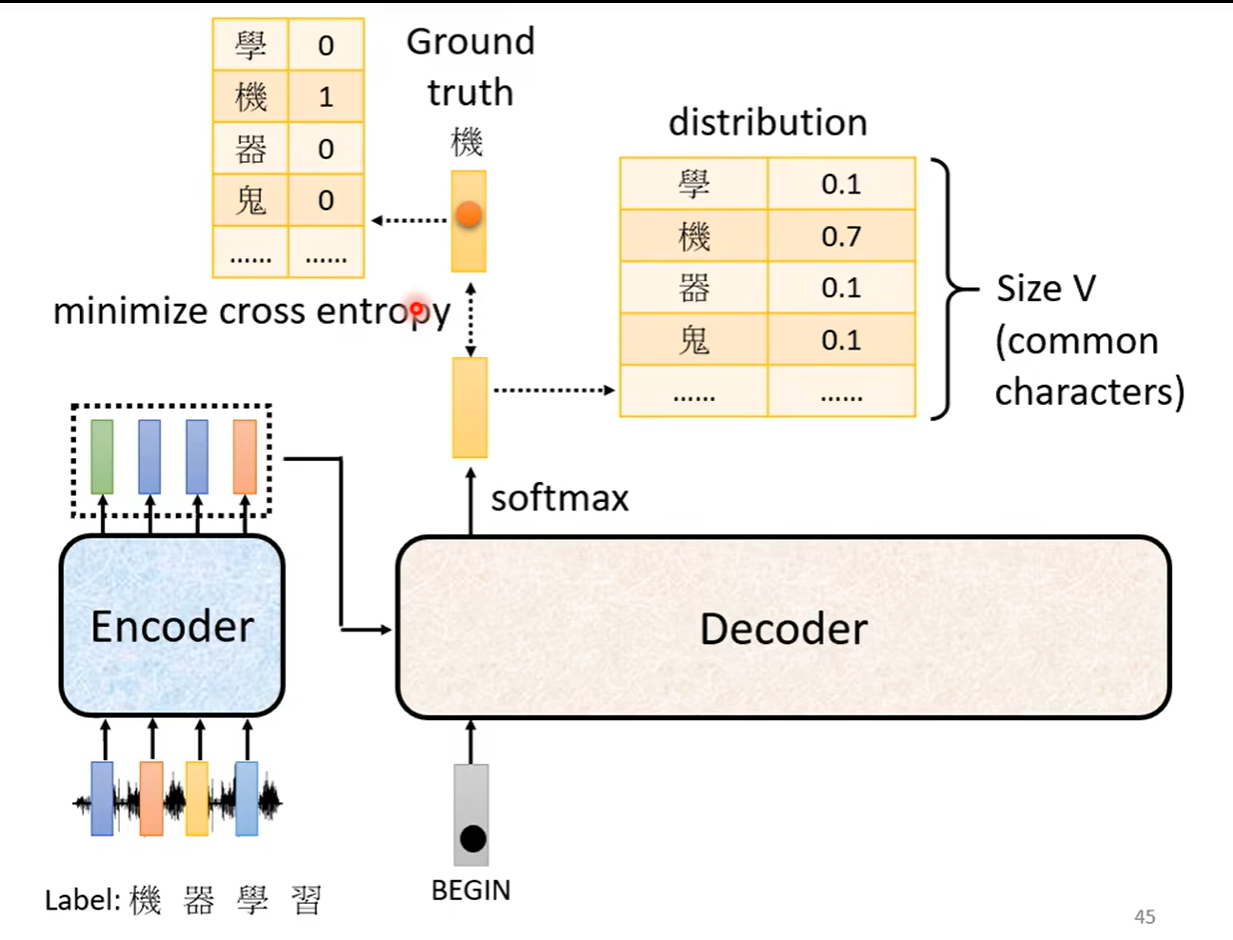
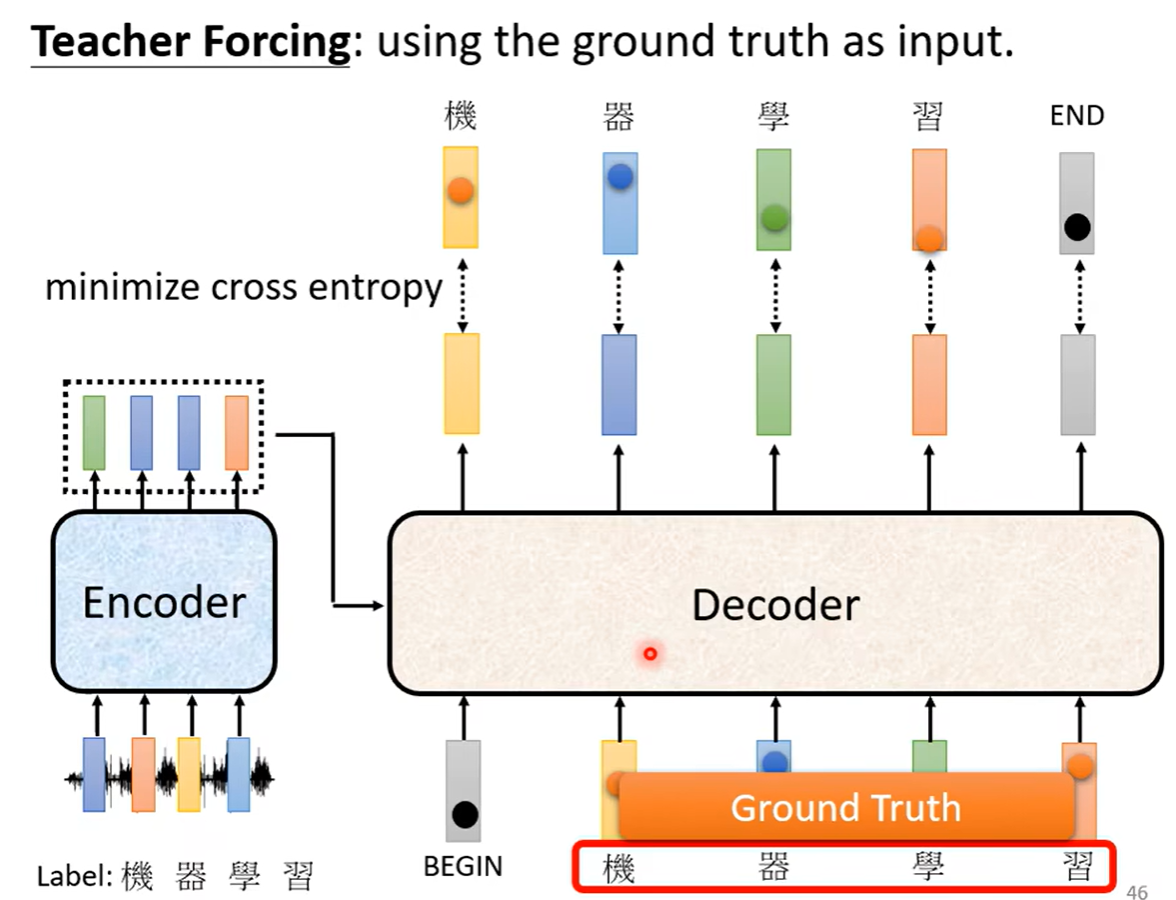
我们产生了几个向量(包含end),就要计算几个向量产生的误差的总和,并使其最小。decoder训练的时候,我们会把上一个正确的答案作为下一个输出,这个过程叫做teacher forcing,但是我们并不知道这个输入是不是正确的答案,所以这中间也有一个误差。
训练seq2se模型的tips
上述例子我们要求decoder自己产生输出,但是很多时候decoder并不需要产生输出,仅仅是从输入的一些东西里面复制一些出来,比如对话系统中,提问者一些怪异的或者不常见的文字等,可以直接复制


 浙公网安备 33010602011771号
浙公网安备 33010602011771号