07.基于文本挖掘和 SVM 的股票市场择时交易研究
1.关键词
量化投资:
上涨市:
下跌市:
震荡市:
空仓:
投资者情绪指数:
择时交易:
文本挖掘:
私募基金:
股票成交量:
百度指数:
多重共线性问题:
Elastic Net变量选择方法:
LASSO变量选择方法:
Ridge回归:
BIC度量标准:
结构风险最小化:
经验风险最小化:
Mercer 核展开定理:
非线性映射:
Hilbert 空间:
高斯核函数:
对偶问题:
主成分分析PCA:通过正交变换,将一系列可能相关的变量转化为彼此线性无关的变量(主成分)的统计学方法。同时此正交变换保证第一主成分有着最大可能的方差,且下一个主成分在与前一主成分正交的条件下有着最大可能的方差。PCA借助基于相关系数矩阵所对应特征值的方差贡献率,可挑选部分主成分以代替原始变量的绝大部分信息,从而实现降为的效果。
2.研究现状
虽然目前中国市场的量化交易占总交易量的比重微乎其微,但是量化投资因其在交易机制的客观理性以及稳定收益的可实现性,将成为金融投资领域未来的主流发展方向。国内一些私募基金也开始将机器学习融入到自己的交易策略之中,机器学习在量化投资领域有着独特的优势。其一是机器学习算法能够高效的分析大量的数据特征,并且在学习过程中自我改进用以适应市场变化,不会被主观因素干扰到。其二是人的情绪会对预测的模式和判断产生某种影响,不同的情绪叠加可能产生截然不同的结果,机器学习可以完美克服这一点。其三伴随着大数据的兴起,尤其是金融领域的数据优势,为“以数据作为灵魂的机器学习”技术提供了很好的应用场景。
研究历程
-
Kalev P S. et al(2004)应用朴素贝叶斯、KNN 和反向神经网络等机器学习 方法,在给定金融词典定义的情况下,根据金融市场与关键词之间的关系生成概 率规则,对于规则技术关于股票的价格走势影响的有效性进行了研究,研究结果 证实了有效性并展示了其预测的准确性。
-
Antweiler W.et al(2004)采用 SVM 算 法分析了股票价格和华尔街日报流行专栏内容之间的关系,研究发现媒体对于股 价的悲观态度会显著导致股价下跌,并且悲观程度会影响交易量的大小。
-
Li F.(2010)通过对雅虎财经和 Raging Bull 网站上关于 45 家公司 150 万条消息挖掘,分析其对公司道琼斯指数的影响,发现股市评论可以对股票市场的价格波 动进行预测,且交易量增加很大程度上和消息的分歧程度相关。
-
张世军等(2013) 通过对网络的评论进行爬取、分类获得网络舆情,结合股票的开盘、收盘价格构 建起了基于网络舆情的 SVM 回归模型,并对股票价格的走势进行了预测。
-
Junqué de Fortuny E.et al(2014)根据 SVM 算法对文本进行分类,并利用 Python 对评 论进行了标注,选用乖离率、心理线、威廉指标和强弱指标等技术指标验证了非 理性指标预测股票价格走势的有效性。
3.研究思路
利用Python编写网络爬虫程序,在东方财富网“股吧”爬取200万条标题文本数据,进行分词处理、词频统计,得到初始关键词库。之后通过百度指数相关搜索词功能将关键词的个数扩充至69个,并通过Elastic Net和主成分分析法构造投资者情绪指数。
同时文本使用上证指数2011年3月24日至2017年5月24日共1500个交易日数据,经过特征工程处理,建立了基于支持向量机SVM的股票市场择时交易模型。使用Sliding Window法进行最优参数的学习,从而对股市的未来趋势进行预测,得到未来每个交易日的操作信号。
最后将基于文本挖掘所构建的投资者情绪指数作为数据的一个特征代入SVM中,探讨其是否能提升模型的预测性能。
数据来源和选择
-
用于投资者情绪指数构建所需数据来源
![]()
-
用于股票市场择时模型构建所需基础数据来源
使用python财经数据接口包TuShare提供的腾讯财经接口,这个接口包是一个免费、开源的python财经数据接口包,主要实现对股票等金融数据从采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速 、整洁和多样的便于分析的数据。本文借助该数据包得到了上证指数自2011.1.1到2017.6.9期间的开盘价、最高价、最低价、成交量等基础数据。

软件说明
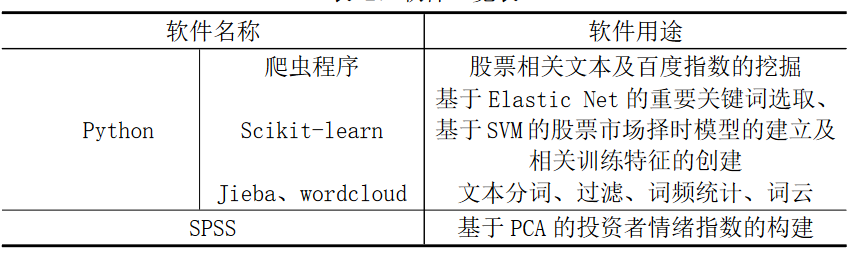
百度指数
百度指数是以百度海量网民行为数据为基础的数据分享平台,是当前互联网乃至整个数据时代最重要的统计分析平台之一。借助于百度指数,可以研究关键词搜索趋势、洞察网民需求变 化、监测媒体舆情趋势、定位数字消费者特征;还可以从行业的角度,分析市场 特点。
本文中使用到了百度指数的两大功能:
-
相关词分类中的搜索指数,反应中心词所有相关词中搜索指数热面的关键词,即于某一关键词相关的的其他关键词。
-
指数趋势:包含 PC 搜索指数和移动搜索指数
4.模型构建、数据选择和评估标准
数据选择:基于 Elastic Net 和 PCA 的投资者情绪指数的构建
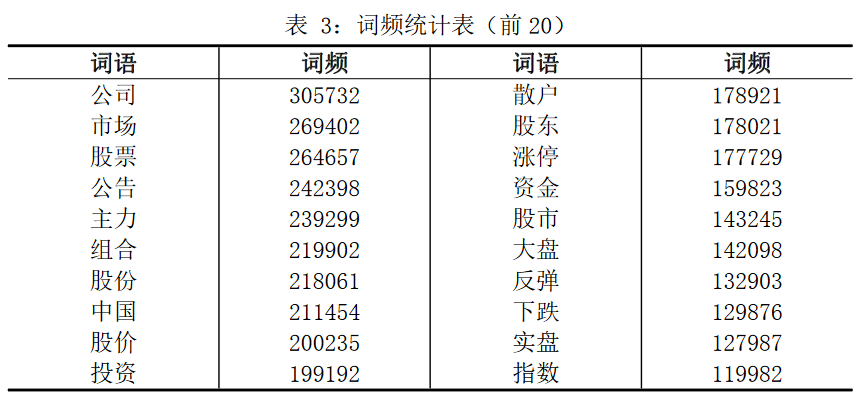
1.基于词频的初始候选关键词库的构造
首先利用 Python 软件的 Requests 库、Re 库、bs4 库等编写“爬虫” 程序,从东方财富“股吧”论坛爬取了 200 万条论坛标题的文本数据。之后,利用 Python 的 Jieba 中文分词库进行分词以及词频统 计,对于无实际意义的词进行滤除,得到词频统计表
利用python的wordcloud库可构建词频统计的词云图

2.利用百度指数进行候选关键词的扩充

3.爬取关键词库词语的百度指数
从网页爬百度指数的 每日搜索量数据并不简单,网站对于其原始数据进行了加密,无法直接取得。因 此本文采用图像识别的间接爬取方式:利用 python 编写程序控制鼠标在浏览器 上的移动,并即时下载其生成的图片并识别其中数字,最终获取每日数据。
4.基于Elastic Net的重要关键词的提取
为了保证所构建的投资者情绪指数与股票市场的价格波动高度相关,需要从候选的关键词库中挑选出重要的关键词,这里初步以上证指数的收盘价,作为响应变量,对69个关键词对应的按日搜索量进行多元线性回归,发现部分关键词之间存在着多重共线性问题,且常规的变量选择方法LASSO不能得到正确的结果,本文使用的是Elastic Net方法,将Lasso和Ridge回归的惩罚项线性组合在一起的正则化形式。
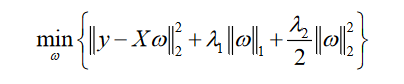
具有强相关变量组的数据,可以有效的将相关变量组全部选入或全部剔除模型
为了便于最优参数选举,可将上述目标函数改为
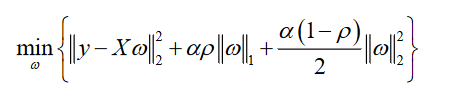
使用BIC作为度量标准,挑选出最优参数α=2500,ρ=0.2,此时筛选出的重要关键词是45个

5.基于PCA的投资者情绪指数的构建
本文利用SPSS软件对基于Elastic Net筛选出的45个关键词所对应的按日搜索量进行主成分分析,在达到降维目的的同时,提取出所有关键词所反映的主要信息。按照特征值大于1的原则,选取了7个主成分分别为:
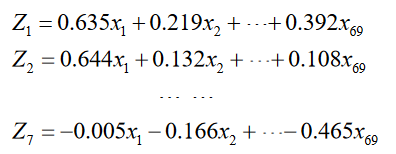
以各主成分所对应的方差贡献率为权重,计算 7 个主成分的加权和作为投资 者情绪指数的代理值,计算结果如下所示:
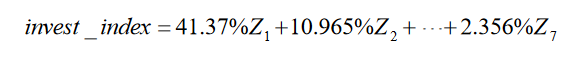
模型构建
1.SVM核心思想和原理
其直观思想是:将原始数据映射到一个高纬空间中,在新的特征空间里选找一个能够最大程度分隔两类样本的超平面。其建立以统计学理论中的VC维理论和结构风险最小原理为基础,根据有限样本信息在模型的复杂度(对特定训练样本集的学习准确率)和学习能力(无错误的识别任意样本的能力)之间选择最佳折中,来获得最好的泛化能力
结构风险最小化原则决定了SVM的预测效果会优于神经网络等以经验风险最小化为优化目标的传统机器学习方法。
其核心思想,SVM是基于Mercer核展开定理,通过非线性映射把原始特征空间映射到Hilbert空间,进而在新的特征空间上使用线性学习方法解决非线性的分类和回归问题。本文使用较为常用的高斯核函数来建立用于预测每个交易日具体交易类型的SVM模型

2.建立模型
1.预测任务
想要通过模型精准的预测到每天价格是极其困难的任务,本文从另一个角度出发,预测未来几天的市场变化趋势进而做出相应的交易策略。未来连续上涨则当天买入,未来趋势下跌,则当天卖出,未来趋势不明显,则继续空仓或持有。
目标是:预测在未来K天中价格的总体变化趋势,且未来某天相对当天价格变动超过p%时认为价格有较大波动

指标T度量了在K日内平均价格百分比变化明显高于目标变化的那些日期的变化之和,大的正T意味着未来K天中存在几天日平均价格比当天收盘价的涨幅明显高于P%,此情况表明有良好的预期价格会上涨。另一方面,大的负T 值表明价格在未来 K 有下跌的趋势,因 此在当天进行卖出操作。如果T 的绝对值较小,我们认为未来 K 天价格平稳波动 或价格涨跌相互抵消,因此继续空仓或持有,不进行额外操作。

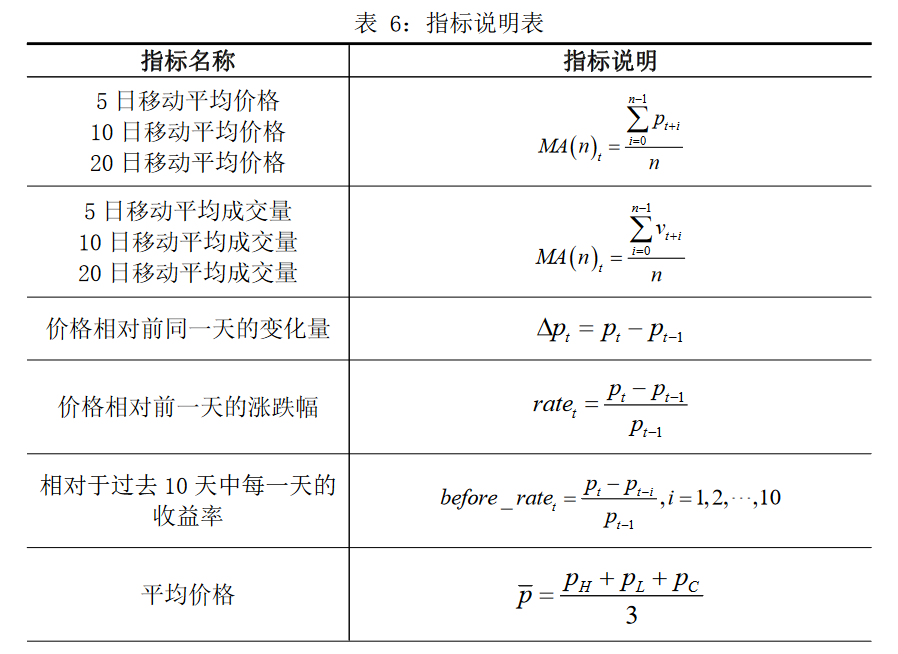
2.特征工程
特征工程是将原始数据转化为特征,并根据所研究问题的领域知识提取、构架、删除或组合变化得到新的特征,以提升模型预测能力的过程。
由于选取的数据集包含了五个特征,对应次昂因素众多、股价无明显特定规律的中国股票市场无法得到一个好的结果,同时在实际应用中机器学习算法的效果严重依赖于数据集特征的选取,所以选取35个指标对初始数据集的特征进行扩展


之后都每个数据样本进行类别标记。将未来10天有上涨趋势的数据样本标记为1,下跌趋势的数据样本标记为-1,无明显趋势的标记为0
SVM对特征尺度较为敏感,因此正式训练和预测之前要对每个特征进行标准化处理,使所有特征均具有0均值和单位标准差
3.最优参数的选取--Sliding Window法
我们所采用的数据数据属于时间序列数据,对于时间序列数据而言,不同时间的数据之间存在相关关系。传统的K-折交叉验证方法用在这些时间序列数据集上会出现使用未开数据预测过去交易的情况。
于是这里采用滑动窗口的方法,考虑到过去很长时间的数据对未来的数据的预测可能不起任何作用甚至还有干扰作用,所以对未来某一固定跨度的时期进行预测时,仅选取过去固定数量的数据进行模拟训练。本文使用240个交易日预测未来60个交易日的交易类型,每进行一次预测后滑动窗就向后移动60个交易日

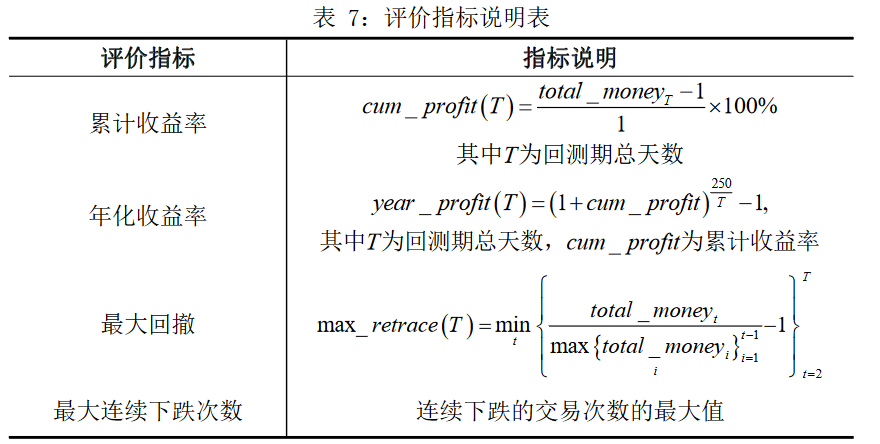
评估标准
传统的机器 学习算法可用准确度、错误率、精度、召回率、AUC等衡量标准,但本文的模型整体性能的衡量需要与经济效益和风险相结合且需重点考虑
5.实验结论
主要的两个结论:
-
经过特征工程对原始数据进行处理后,基于SVM所建立的股票市场择时交易模型对于上涨市、下跌市、震荡市均有较高的预测精度,而且在震荡市捕捉到了更多交易信息,相比买入并持有策略有更高的年化收益率。
-
基于文本挖掘所构建的投资者情绪指数能在一定条件下提升模型对股票市场未来趋势的预测性能。
6.问题和改进方向
本文基于文本挖掘所构建的投资者情绪指数主要依据的是东方财富网“股吧” 的文本和利用百度指数对关键词的扩充,这些数据仅仅是体现股票价格波动的大 数据的一部分,其他结构化或非结构化的数据也能体现股价波动信息。因此,可 完善爬虫程序对数据的种类及量级进行扩充,优化股市情绪关键词选取方案,提 高投资者情绪指数的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号