
04.一种基于金融文本情感分析的股票指数预测新方法
研究目标:对媒体报道、公司新闻等非结构化数据进行文本分析,并应用于股票价格波动预测
研究方法:基于金融文本情感分析的指数预测模型SA-BERT-LSTM,对沪深300指数进行预测
研究发现:
-
情感分析特征能有效提高模型的准确率
-
三种对照模型(BP神经网络、支持向量机、XGBoost),SA-BERT-LSTM的预测精准度更高,且同样适用于个股价格预测
研究创新:将BERT模型应用到财经新闻情感分析中,将情感特征与股市行情交易数据相结合,提高了股指趋势预测的准确率。
一、问题的提出
股票行情数据属于金融时间序列,具有非线性、非平稳和高噪声等特点,导致股票指数趋势预测一直难以取得令人满意的效果。并且还有许多重要金融信息可能分散在其他文本数据中,这些非结构化文本数据的分析与使用,进一步加剧了金融时间序列预测的难度。
早些年有些学者,引入人工神经网络ANN后发现,当模型变很复杂之后,传统的机器学习算法不一定有效。
过拟合问题是过去十几年困扰高度参数化监督机器学习方法的最大问题之一
此外,即使模型是准确的,自由度的增加还有可能会导致训练过程陷入高维函数空间的某个局部最小值
近些年出现了新的正则化的方法,和更快的训练技术,如使用分段线性激活函数,而非超越函数,使得具有大量隐藏层的神经网络变得容易训练,由此诞生了深度学习。
深度学习能够根据数据特征进行一般化学习,在模型学习过程中无需人工构造特征,网络表达能力更强。长短期记忆网络LSTM方法这种特殊类型的递归神经网络在人工手写识别、语言预测和语音识别等任务中效果显著。Xiong等人在2015年利用LSTM对S&P500波动率进行了建模,结果表明LSTM模型对包含噪声的金融时间序列数据具有很好的效果
目前的研究成果,文献中多用传统的机器学习方法来预测股票价格,但方法上较为传统,BP神经网络、随机森林和支持向量机等。从数据上来看,已有的模型中所用的数据多为财务报表数据、股票行情数据等结构化数据,忽略了以财经新闻为代表的非结构化文本数据。比如财经新闻也是股价变化的重要推手,一般而言如果新闻是正面的股票上涨的可能性很高,如果是负面的股价就可能下跌。所以,股票市场除了会受到政治,经济,军事等因素影响还会受到“情感”因素影响,然而对于股票市场而言,情感分析尚处于起步阶段。
本文使用2015年3月27日--2021年4月30日的沪深300股票数据(包括股票行情交易数据和财经新闻文本数据)为研究对象,提出一种基于金融文本情感分析的指数预测模型SA-BERT-LSTM该模型通过东方财富网获取新闻文本,然后用NLP领域的知名文本分析模型BERT结合LSTM模型进行情感分析,提取情感极性特征;然后将股票行情交易数据与情感特征融合一起输入LSTM,对沪深300指数涨跌进行预测
本文的贡献:
-
本文丰富了经济学研究的工具箱,关于深度学习的方法天然适合金融领域时序问题的研究
-
本文在预测过程中引入财经新闻文本等非结构化数据,拓展了可用数据的范围
-
创新性的将BERT模型应用到财经新闻情感分析中,在此基础上,基于LSTM网络构建指数预测模型并通过实证研究证明,将情感特征与股市行情交易数据结合,有效提高了股指趋势预测的准确率,为金融时间序列预测人物的数据预处理以及BERT在金融领域的应用提供了思考
-
本文采用不同时间窗口提取特征对预测结果的影响。在实际交易中,投资者一般会参考多个时间尺度的股价信息,现有的研究忽略了不同时间尺度数据的信息特征,往往采用同一频率的数据进行预测
二、文献综述和研究方法评述
1.基于机器学习的金融市场预测
Atiya和Ji(1997)使用ANN模型作为预测工具,发现其预测结果可以在一定程度上指导投资者进行股票买卖
Guresen等(2011)基于纳斯达克股票指数,利用多层感知机MLP、动态人工神经为网络和广义自回归条件异方差构建混合神经网络,评价了动态神经网络模型在股票市场预测中的有效性
金融时间序列数据具有高维、非线性和不稳定等特点,一方面传统的机器学习方法对复杂高维度数据的学习效果较差,且存在维度灾难和特征表示无效的缺陷,另一方面,对于复杂非线性数据的建模能力有限,难以对股票价格数据进行有效拟合
深度学习在拥有足够多神经元的情况下,能够以任何精度逼近任何连续非线性函数,经过研究表明,通过堆叠非线性特征提取器获得的数据表示通常会产生更好的机器学习效果,深度学习可以处理更高维度的数据
深度学习在金融时间序列数据中的应用优势:
-
不受维度限制,可以将相关数据都作为输入数据纳入模型之中
-
具备更好的非线性拟合能力,更适合用于金融序列数据的自身特点
-
有效的减少归你和以及陷入局部最优解问题(Heaton2017)
主流研究方法
近年来,股票预测的研究方法从主要利用SVM、RF等传统机器学习方法,逐步转向利用卷积神经网络CNN和循环神经网络RNN等方法。Wei和Chaudhary提出了结合人工选择、分割算法和训练误差反馈的系统方法(TST方法),使用RNN识别股票价格时间序列的趋势特征,然而RNN模型训练过程中存在梯度消失和梯度爆炸的问题,导致模型无法学习长期依赖,而LSTM模型通过引入门控制机制来缓解梯度消失问题,可以有效地学习金融时间序列的长期走势
国外很多学者已经将LSTM应用到股价预测领域,Akita(2016)等探索了深度学习模型、段落向量和LSTM在金融时间序列预测中的应用,使用东京交易所50家公司的数据进行检验,实验证明文本信息的分布式表示优于数字数据方法
Wei(2017)等提出了一种新的深度学习框架,首次将层次化提取深层特征的结构方程引入股票价格预测中,其预测精准程度优于其他对比模型
杨青和王晨蔚(2019)分别使用LSTM、SVR、MLP、ARIMA模型对全球三十个股票指数进行了预测(另一篇博客中有关于这篇文章的详细解析)
为了解决单一神经网络泛化性较弱的问题陈国华和徐国祥(2018)采用EEMD方法将价格序列分成多个本征模态分量(IMF)以及趋势项,将Adaboost和LSTM结合后,逐一对IMF和趋势项进行预测,加权相加后得到价格的预测值
2.文本分析在股票预测中的应用
文本分析是指通过对文本内容进行挖掘和数据分析,获得文本提供者的特定立场、观点、价值和利益,并由此推断其意图和目的。
在股价预测研究中,通过对上市公司披露文本、新闻财经报道中与金融市场相关的部分进行挖掘,有助于研究者更加深入地理解和刻画资产价格变动机制
Cowles是一个通过新闻文本进行股票预测的早期例子,他将华尔街日报主编Peter的社会文章归类为“看涨”“看跌”“不确定”,然后使用这些分类来预测道琼斯工业平均指数的未来回报
现代研究股票价格的文本分析文献主要有三类:
-
依靠预先存在的字典
-
Tetlock较早基于词典分析媒体情绪和股市,使用哈佛大学的心理社会词典,每个类别的每日情感得分时间序列被压缩成单个主成分,将其命名为悲观因子
-
Loughran和McDonald发现,哈佛字典不适用于金融学领域,因此他们构建了一个金融学专用词汇词典,记录了其相对现有情感词典改进的预测能力
-
Bollen等使用Opinion Finder和谷歌情绪状态档案记录了推特信息和股市之间的显著预测相关性
-
Wisniewski和Lambe发现媒体对银行业的负面关注,是影响2008年金融危机期间银行股票回报率的重要因素
-
-
使用回归技术
-
Jegadeesh和Wu举例说明了文本回归在资产定价中的应用
-
Manela和Moreira基于华尔街日报1890--2009年的文本,构建了一个新闻隐含市场波动指数,他们发现与市场波动最密切相关的项目包括政府政策和战争
-
-
以及使用生成模型(Antweiler和Frank2004)
-
与Cowles最接近的是Antweiler和Frank的生成建模的方法,生成模型技术可以自动对消息进行分类,使用朴素贝叶斯方法来估计一个概率模型,与Cowles的结论一致,留言板帖子显示出较小预测股票回报的能力,但确实反应了关于股票波动性和交易量信息
-
近年来文本分析中的情绪分析在经济学中的重要性持续增长,所以如何从文本中提取有效信息并研究其对股票价格变动的影响也成为近年的研究热点
国内研究使用的大多是基于股吧、推特、微博等平台上的信息,但这些信息的显著特征是噪声较多且包含较多历史价格走势等无效信息,难以捕获其中有用信息用于股价预测。相较之下财经新闻中的文本数据行文规范,有用信息多、参考价值高
传统文本分析方法并不能充分挖掘金融信息,导致股票预测模型的准确性较低于是LSTM模型更适合建模时许数据,BERT模型在财经新闻文本情感分析任务中具有巨大优势,于是本文将BERT模型应用到我国财经新闻情感分析任务中,并基于LSTM模型提出一种情感分析特征的股票指数预测模型。
LSTM
长短时记忆网络(LSTM)基于反向传播的传统循环神经网络,随着网络层数的增加会出现梯度消失和梯度爆炸的问题,作为RNN的一种变体,LSTM很大程度的缓解了RNN的梯度消失问题,LSTM有三个门的控制单元,输入门,输出门和遗忘门,其中输入门和遗忘门是能够记忆长期依赖的关键,输入门决定了当前网络的状态有多少信息需要保存到内部,遗忘门决定有多少过去的信息需要丢弃,输出门决定当前时刻的内部状态有多少信息需要输出给外部状态.
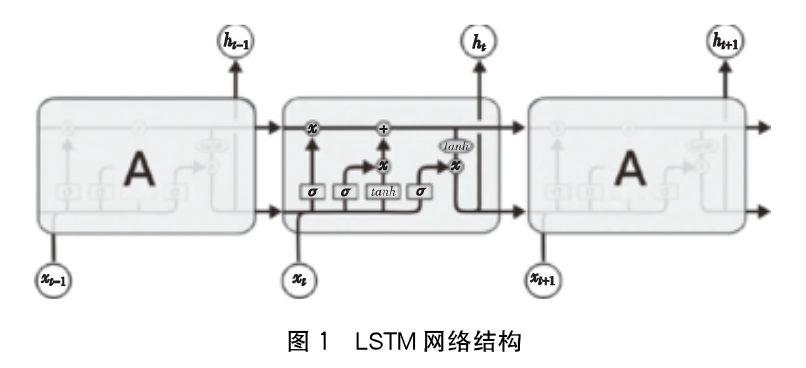
步骤:
-
遗忘门决定丢弃细胞状态的哪些信息,遗忘门通过h(t-1)和x(t)输出一个0到1之间的向量向量决定细胞状态(Ct-1)中信息是否丢弃(W和b分别表示遗忘门的权重和偏置参数)
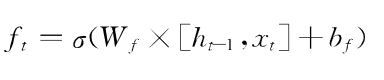
-
输入门决定保存细胞状态的哪些新生信息,输入门包括两部分
-
通过sigmoid激活函数得到i(t),确定哪些信息需要更新进细胞状态
-
通过tanh激活函数创建新的备选值向量Ct,这些信息可能被更新进细胞信息中
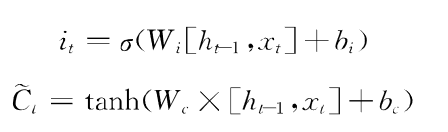
-
-
经过遗忘门和输入门后,原细胞状态从C(t-1)更新到C(t)
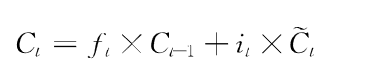
-
输出门决定该时刻记忆单元要输出的信息,首先经过sigmoid函数决定输出细胞状态中的哪些部分,然后将细胞状态的值通过tanh改编成-1到1之间的向量,该向量乘以输入门的判断条件tanh(Ct)得到最终输出.
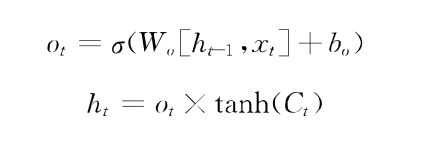
BERT
预训练机制最早应用是在图像领域,基于某些图片数据集(ImageNet数据集),以图象分类为目标使用深度卷积神经网络(如常见的ResNet、VCG、Inception等)进行预训练,得到的模型称为预训练模型。针对目标检测或语义分割等任务,基于这些预训练模型,通过一组新的全连接层与预训练模型进行拼接,利用少量标注数据进行微调,将预训练模型学习到的图像分类能力迁移到新的目标任务
深度学习时代广泛使用的词向量就属于NLP预训练工作
使用DNN对NLP模型预训练时,要先将待处理文本转换为词向量(词嵌入),作为神经网络的输入,词向量的效果会影响到最后模型效果词向量的效果主要取决于训练语料的大小
目前大部分NLP深度学习任务中都会使用预训练好的词向量和CloVe进行网络初始化,从而加快收敛速度。
BERT模型:
E1,E2....En为模型的文本输入,T为模型的输出向量,中间层是双向的Transformer编码器。为了同时捕获词语和句子级别的文本语义表示,BERT采用掩码语言模型和下一句预测两个任务进行预训练
-
掩码语言模型本质上类似于完形填空任务,随机Mask掉文本中的某些字词,然后模型要去预测被Mask掉的词。,通过迭代训练可以学到词的上下文特征、语法特征、句法特征等
-
下一句预测就是输入两个句子A和B,判断B是不是A的下一句,通过迭代训练,可以学习到句子之间的关系
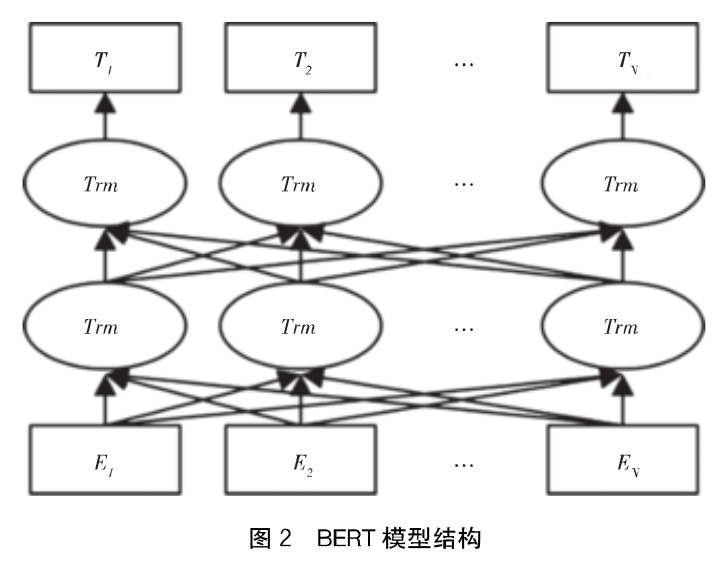
BERT采用双向Transformer作为特征提取器,相较于RNN和LSTM,Transformer结构更强大,学习能力更强,更能融合上下文信息。其本质是一个编码-解码器,其核心是自注意力机制,Self-Attention计算步骤:将输入文本转化成嵌入向量,嵌入向量乘以三个矩阵,得到Query、Key、Value三个向量,然后计算Attention数值,其中dk是向量维度
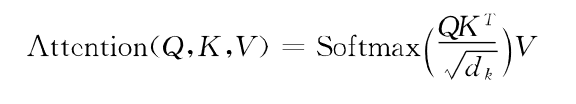
三、基于金融文本情感分析新方法的设计
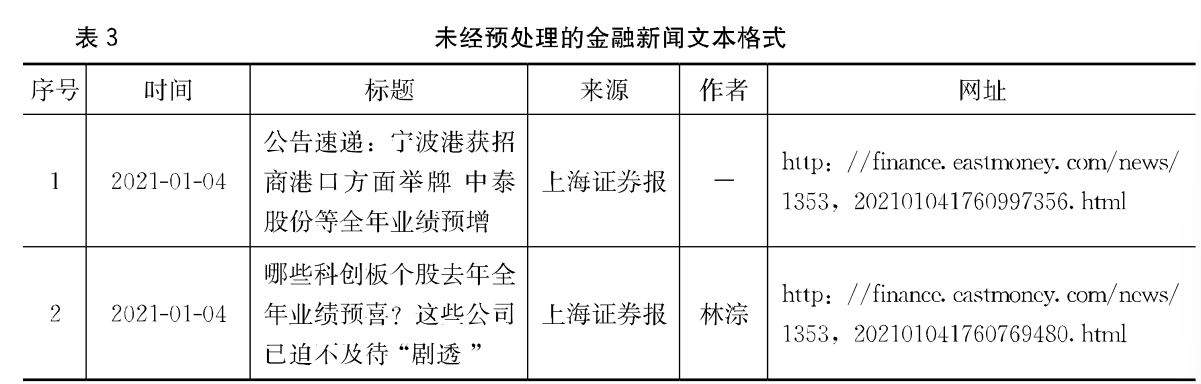
1.数据预处理
本文的数据预处理工作包括对股票交易数据的预处理和文本数据的预处理
(1)股票交易数据预处理
基本技术分析数据主要使用沪深300指数每天的交易行情数据,如当天成交量、最高价、最低价、昨收价、涨跌额、涨跌幅、成交额、开盘价、收盘价等,数据可以使用Tushare开源的Python财经数据接口获取,其返回数据类型是pandas.DataFrame数据类型,仅需要做归一化处理平衡上述多个特征由于不同量纲和量纲单位带来的差异。归一化方法选择最大最小标准化又称离差标准化,将特征映射到0到1之间
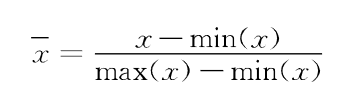
Tushare是一款基于Python语言开发的开源财经数据接口包,主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁和多样的便于分析的数据
x是原始股票价格数据,min是股票价格最小值,max是最大值,
(2)财经新闻文本数据预处理
本文采用的新闻文本数据是《上海证券报》发布的有关沪深300成分股的金融文本信息,对文本数据的预处理**主要是对原始数据进行清洗、去噪声及无关的内容,得到高质量的数据,使之后的情感分析结果更为准确
-
从金融数据库中获取新闻文本数据
-
筛选出与个股相关的新闻
-
取出新闻中的非法字符和无用词语
-
对于一个交易日内存在多条金融新闻的情况,按照日期将每个交易日内的财经新闻合并为一条新闻文本数据,并去除空格
-
提取文本分类结果,正面的打上标签1,负面的标签0
处理前:
处理后

并非每日都有关于某只股票的金融新闻,即在所选日期中存在财经新闻数据的缺失,这部分日期的情感特征输出为空,但是为了让输入股指预测模型的数据不包含空数据,需要进行数据填充。填充时由于某一个交易日的情感特征对投资的导向性不止受当前新闻的影响,也受前几日新闻情感特征影响因此选择前向填充,将交易日的情感分析特征乘以一个衰减率后作为本交易日的情感分析特征,通常设定α=0.2
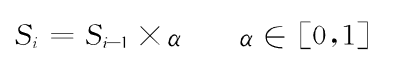
2.基于BERT-BiLISTM的金融文本情感分析模型
传统的基于情感词典的方法,需要人工构建不同领域的特殊情感词典,词典维护和新词的更新需要大量人力物力,该方法已经逐渐不能满足需求。基于机器学习的方法依赖人工人工选择特征,特征选择直接决定模型好坏,模型泛化存在很大难度。
预训练语言模型BERT可以给构建精准的文本向量表示,学习权重分布,加强对有效信息的关注。Bi-LSTM模型在处理时序数据提取上下文文本特征上具有突出优势
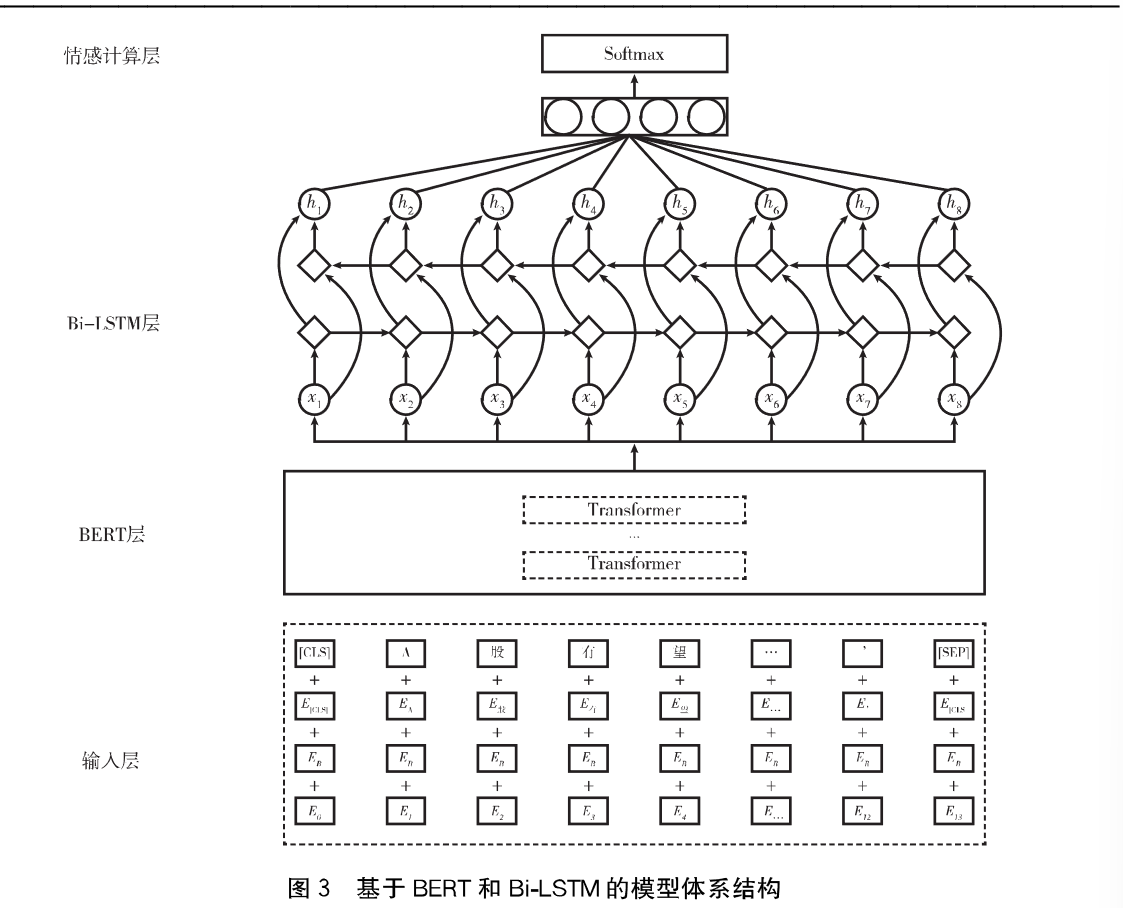
该文章的BERT-Bi-LSTM模型主要包括四层:
-
输入层:通过查询字向量表将文本中的每个字转换成一维向量
-
BERT层:利用Transformer编码器对输入的词向量进行特征提取,获取输入文本对应的融合全文语义信息后的向量表示
-
Bi-LSTM层:利用LSTM获取整条财经新闻的文本特征
-
情感计算层:将LSTM层得到的句子表示经全连接层,利用Softmax激活函数进行整条财经新闻标题的情感计算,最终得到情感分类
(1)BERT获得向量表示
本文选择更适合中文任务的BERT-base-Chinese模型作为预训练模型,财经新闻标题经过分词后输入Encoder编码模块得到对应的词序列转化后的索引,之后将每一条金融文本的索引投入BERT获得每个字的词向量。其中分词过程BERT直接按照单个汉字进行分词。如“证券板块开盘大涨带动市场做多情绪升温”,经分词后会得到词表[证,券,板,块,开,盘,大,涨,带,动,市,场,做,多,情,绪,升,温]分词的目的是将字与其在BERT此表中的索引联系起来
本实验文本最大长度是126个字,长度超过的截断,不够的补0,开头结尾分别添加[CLS],[SEP]标识符,输入部分有三部分相加得到
-
字向量,各个词转换成固定维度的向量,每个词转化成768维的向量
-
段向量,用来区分句子对中的不同句子,适用于多个输入句的情况
-
位置向量,出现在文本中不同位置的字、词语义存在差异(比如,a公司收购了b公司,b公司收购了a公司)
BERT模型通过同时进行Masked LM和NSP两个任务,对输入文本进行预训练
-
Masked LM,BERT随机选择15%的词汇用于预测,具体来讲有80%的概率输入语料会从“证券板块开盘大涨带动市场做多情绪升温”变成“证券板块开盘大[Mask]带动市场做多情绪升温”用mask字符将“涨”遮住,用BERT模型进行预测,10%概率变成跌,10%的概率保持不变
-
Next Sentence Prediction,进行NSP预训练任务时,BERT会选择一半的训练数据为连续的语句对,另一半为不连续的句子对,随后进行监督训练,从而学习到句子关系
(2)Bi-LSTM提取特征
LSTM网络是一种前向传播的算法,对于财经新闻情感特征提取问题而言,除前向序列值会影响情感分析结果,后向序列值也会产生影响,特别针对股票价格走势这类具有时序演化特点的事件,还要综合后向传播算法进行学习
于是采用Bi-LSTM将前向传播和反向传播得到的向量进行拼接,从而同时捕获上下文语义信息。BERT的输入中字符[CLS]对应的C乘以权重W,作为Bi-LSTM网络的输入。
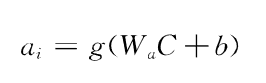
然后将输入向量输入隐层中,Bi-LSTM在两个不同方向的隐层上进行计算,最后将两个方向的结果拼接输出

(3)情感计算
将Bi-LSTM输出的特征向量经过一个全连接层后,输入softmax函数进行情感分类结果预测,对于每一条金融文本,模型最终都会输出一个向量,表示该条文本属于正面和负面文本的概率。采用交叉熵损失函数为目标,采用反向传播机制对情感分析模型中的参数进行训练和更新,以最小化目标函数损失值
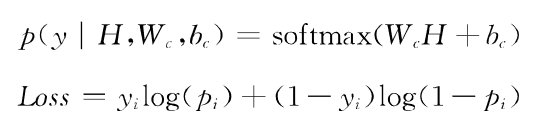
3.融合情感分析特征的指数预测模型
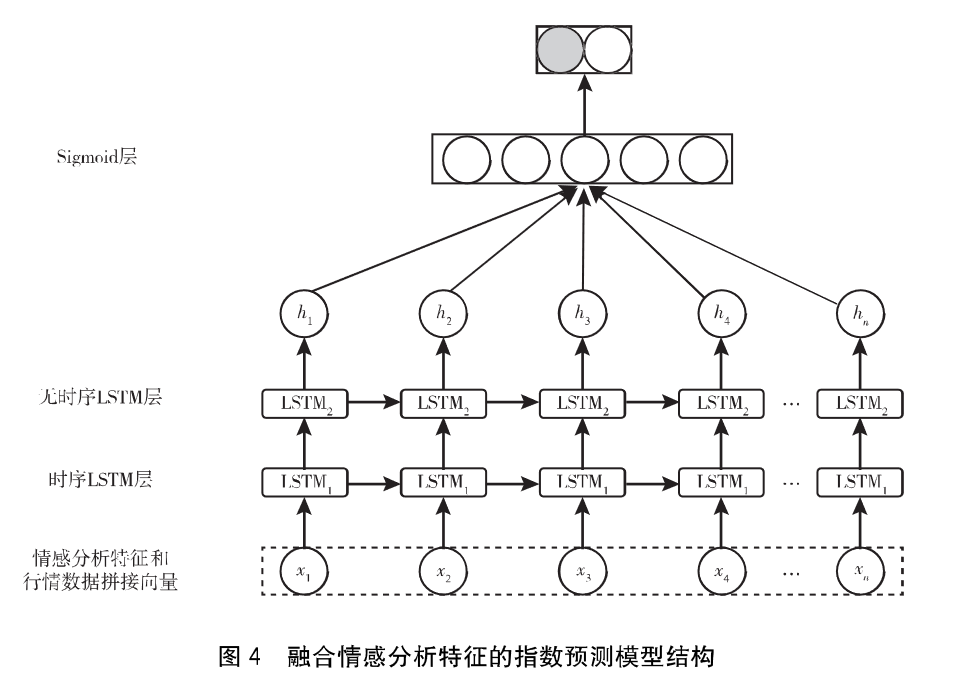
(1)模型结构。模型输入层包括两部分,一部分是股票行情数据,利用上一个交易日股价涨跌信息预测下一个交易日的涨跌情况,利用到了价格信息。另一部分是和财经新闻相关的情感特征序列,表示了新闻情感特征对股价的影响
LSTM网络有两层,第一个隐层是时序LSTM,一共64个单元,输入为第t个交易日行情数据和t个交易日情感分析特征的拼接向量。第二个隐层是无时序LSTM,共32个单元。
LSTM学习的特征向量,先经过全连接层,然后经过sigmoid层输出对应股价在下个交易日上涨还是下跌的概率。
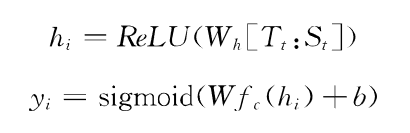
(2)模型参数的学习。为了获得模型中的参数,定义模型的损失函数为
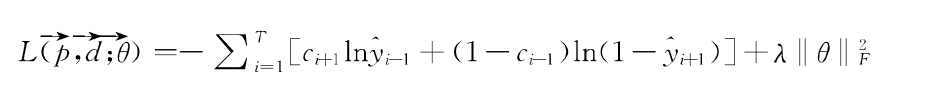
前一部分是交叉熵损失函数,表示模型预测错误的代价,后一部分是L2正则化项,代表对模型自身复杂度的惩罚。前面的θ向量是模型要学习的参数,参数λ是模型的超参数,表示正则化部分的比重。参数学习采用随机梯度下降法
四、新方法的应用实证
训练集:2015.3.27--2021.1.4共1409个交易日的行情日线数据
测试集:2021.1.5--2021.4.30共78个交易日的行情日线数据
九个主要技术指标:当天收盘价、昨收价、涨跌额、开盘价、涨跌幅、成交量、成交额、最高价、最低价
金融文本信息:东方财富旗下的Choice金融终端,其中的“财经要闻”
-
训练集:上述时间内由《上海证券报》发布的有关沪深300成分股的金融文本信息10039条
-
测试集:上述事件内相同来源的1101条
对比模型:选择常用的股指预测模型,BP神经网络、SVM模型和XGBoost模型
评价指标:在分类任务中常用的准确率、精确率、召回率、F1值
-
准确率:总样本中预测正确的样本比例
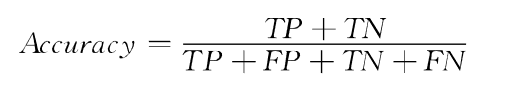
-
精准率:预测上涨样本中实际上涨的样本比例
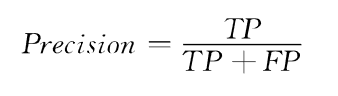
-
召回率:实际上涨的样本中预测上涨的样本比例
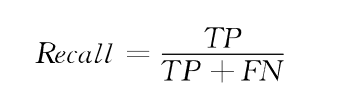
-
F1值:对精确率和召回率的调和平均值
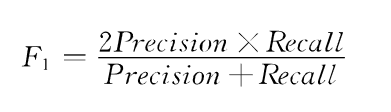
测试选择的原意是在这段时间内,我国A股依次经历了2015年股灾、股灾之后逐步复苏,经历了2020年新冠肺炎疫情导致的股市暴跌,以及疫情得到控制后的股市逐步复苏。该段时间内股市波动幅度较大,涵盖股市形态全面,通过该数据训练得到的股指预测模型泛化能力更强。
五、实验结果
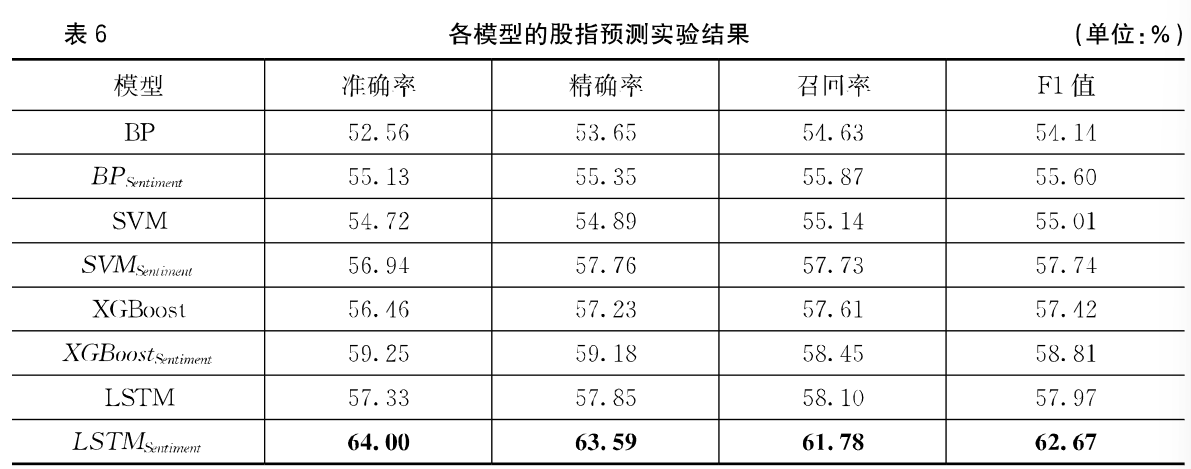
股票信息的时效性明显,通常交易日当天的长得情况与前几天的行情走势以及新闻情感特征密切相关,LSTM具有哦长期记忆能力,所以预测效果要优于其他模型。
此外,包含了情感分析特征的BP神经网络、支持向量机和XGBoost模型与对应的不包含情感分析特征的模型相比,准确率分别提高了2.70%、4.96%、2.24%,证明了股指预测模型中注入情感分析的有效性
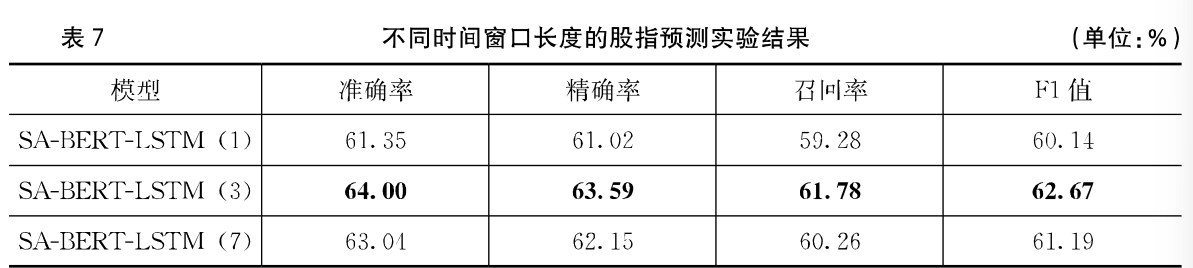
股票信息的时效性明显,通常交易日当天的长得情况与前几天的行情走势以及新闻情感特征密切相关,所以时间窗口长度对模型的预测效果有着重要影响。
使用3天的数据预测下一个交易日的涨跌时效果最好,窗口太小数据不能包括足够多有效信息,窗口太长久远的信息会造成数据冗余
结论
-
股票价格预测时,融合情感分析模型有助于提高准确率
-
本文的SA-BERT-LSTM模型利用语言预训练模型BERT对文本进行向量表示和增大时间窗口长度可进一步提高预测结果
-
该模型对沪深300指数有较高准确率,对沪深指数前五大权重股的预测准确率也很高,因此也可以用到个股分析
方向
-
在情感分析模型中考虑国家政策、市场、突发事件等不确定因素的影响
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律