06.深度学习--分类模型
输入对象x,输出是这个对象属于哪一个类class,这样的应用同样有很多,比如:在金融上可以通过分类模型来决定是否贷款给某人;图像识别方面;人脸辨识方面,等等。
这里依然使用宝可梦的例子来进行说明, 我们可以通过宝可梦的几个属性来具体判断宝可梦是属于什么属性
如果按照一贯的三步走的方法,首先确定function,发现可以在f里面内置一个函数g将input放入后如果g>0则输出1,小于零则为1,适应于二分类问题,loss函数也是如果预测分类和真是类别不同则记一个数,否则不计数。

使用朴素贝叶斯公式可以计算出,这个神奇宝贝是来自于哪个类别的概率
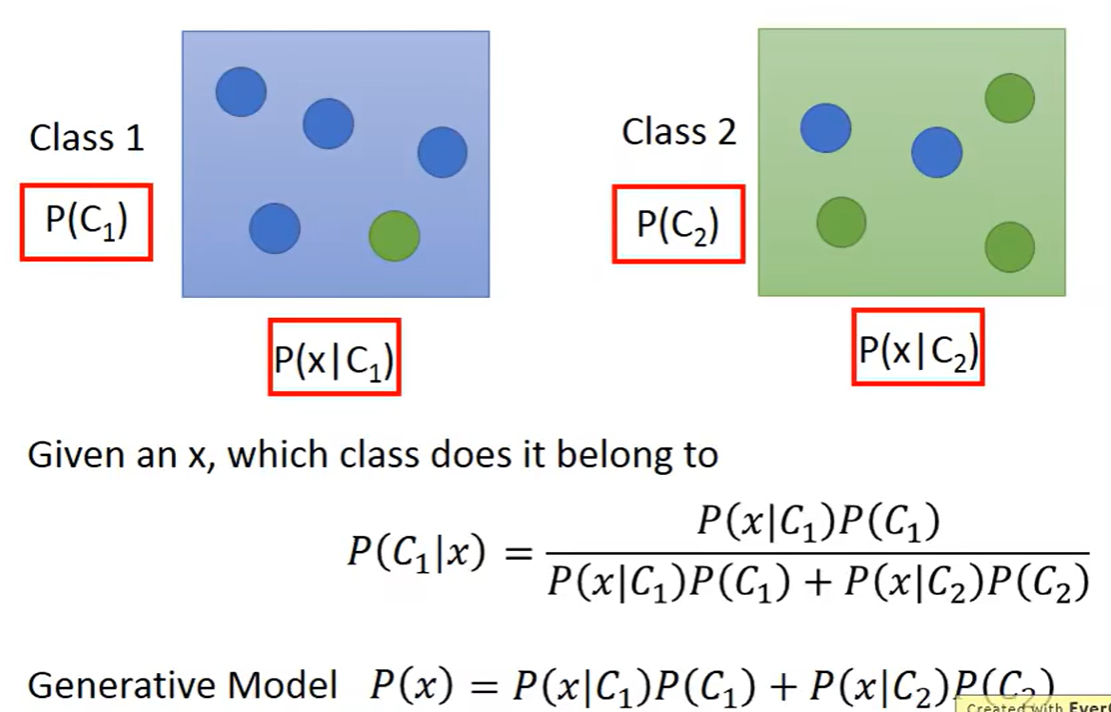

逻辑回归
第一步:找到function set
根据上面的计算,我们可以得出初步的function,通过推导得出的结果就是一个sigmoid function,其输出的结果就是属于某一个类别的概率是多少

第二步:判断函数的好坏
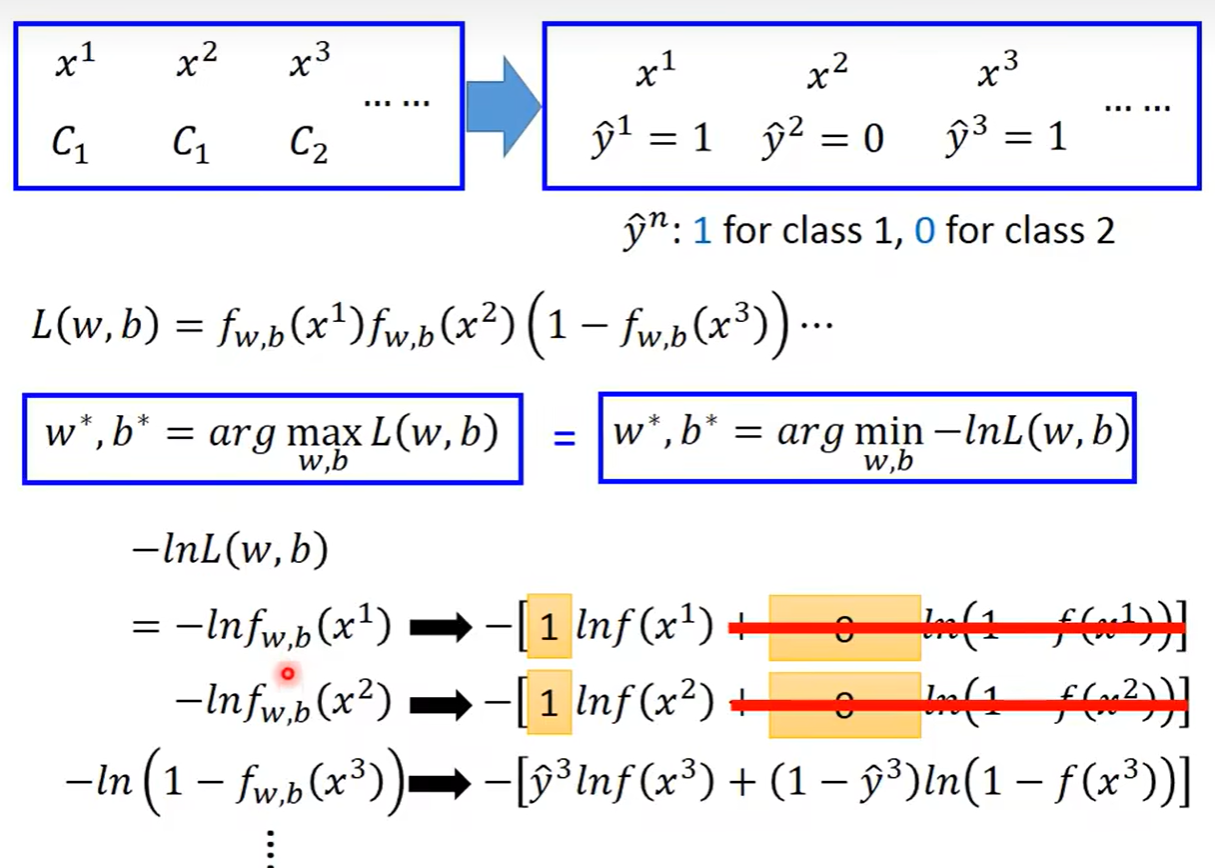
加入我们有一个训练集有N个数据,这些数据都被标记好是属于第一类还是第二类,于是我们的L函数就是属于第一类的概率最大化即可,属于第一类的样本点直接用f(x)表示,是与第二类的在L函数里面用1-f(x)表示于是只要找到一组w和b让整个函数最大化即可

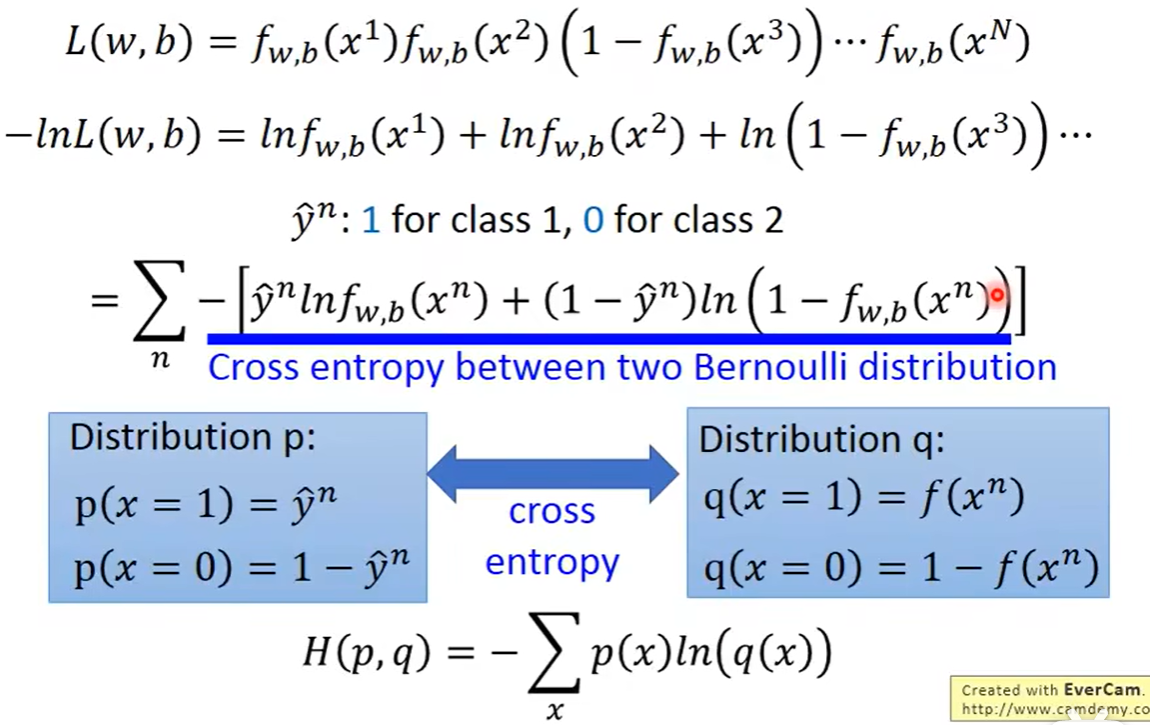
如果想要让计算变得更容易,那就通过一个数学变化取对数并且加上负号,只需要找到最小值即可,并且把y做一个符号上的转换,将第一类表示为1,将第二类表示是为0,于是可以用统一的格式将L函数写出来
写成一般式之后可以发现,一般式是两个伯努利分布的交叉熵
之后再用梯度下降的办法算出来


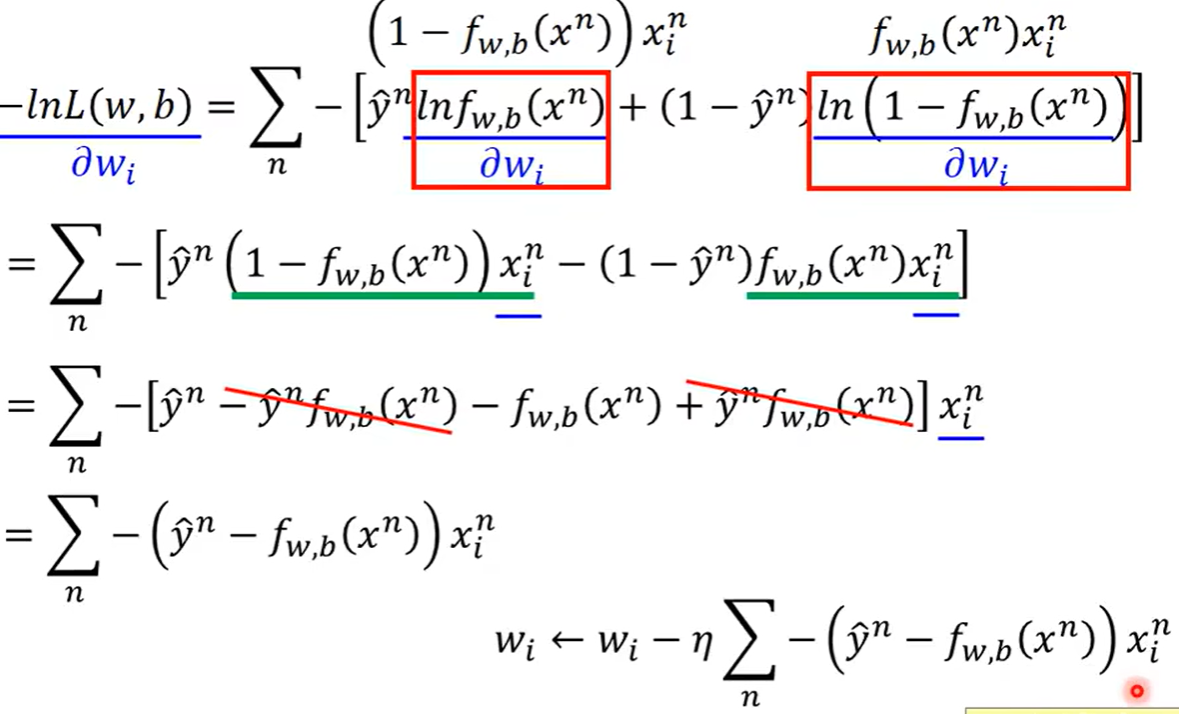
判别器和生成器
判别器:逻辑回归的方法,称为discriminative,判别式模型是直接建模,并根据某一数据直接预测
生成器:用Gaussian来描述后验概率这件事,称为generative,生成模型是模型先对联合概率分布P(X,Y)建模,能够学习出联合概率分布,然后由贝叶斯公式得出条件分布P(y|x),进而进行判断。
判别器和生成器所得参数值是不同的,因为生成器会有很多假设,比如使用的是高斯分布还是其他的概率模型等等。所以他们的回归结果是不同的。所以准确率会有所不同。

很多文献会说判别器的准确率会高于生成器。原因的话,看下面的例子,这个例子是用生成器来判断检验数据是哪一类别。所得概率居然小于0.5,而实际上人眼判断肯定是class1.为什么会出现这一情况呢?是因为生成器假设这些data来自于一个概率模型,它假设了全1的情况会出现在class2——脑补。而且这个概率也受到data数量的影响。
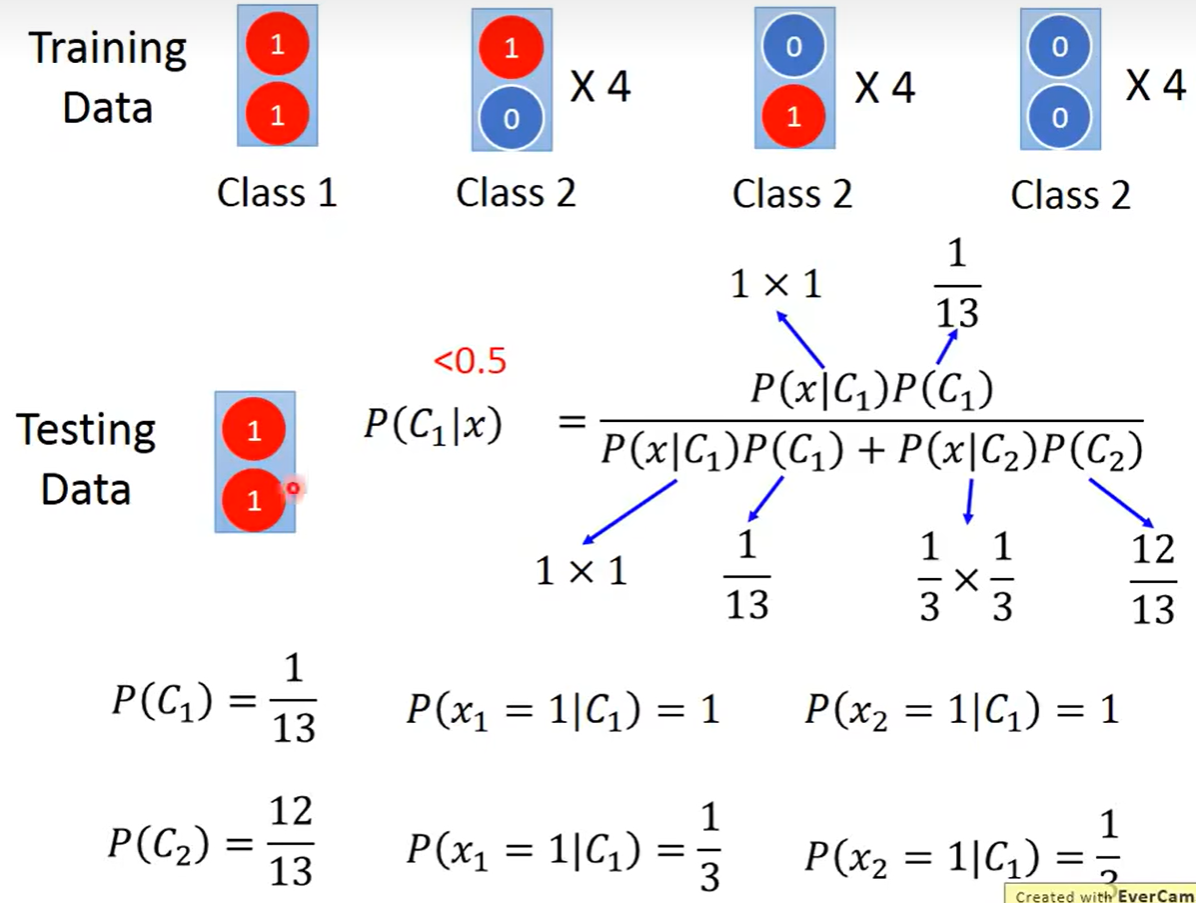
但其实有时候判别器也不总是高于生成器的:
-
训练数据比较少的时候
-
标签本来就有问题的时候,脑补会避免很多问题
-
先验概率(priors)和类别相关概率(class-dependent probabilities)可以用不同的数据来源预估
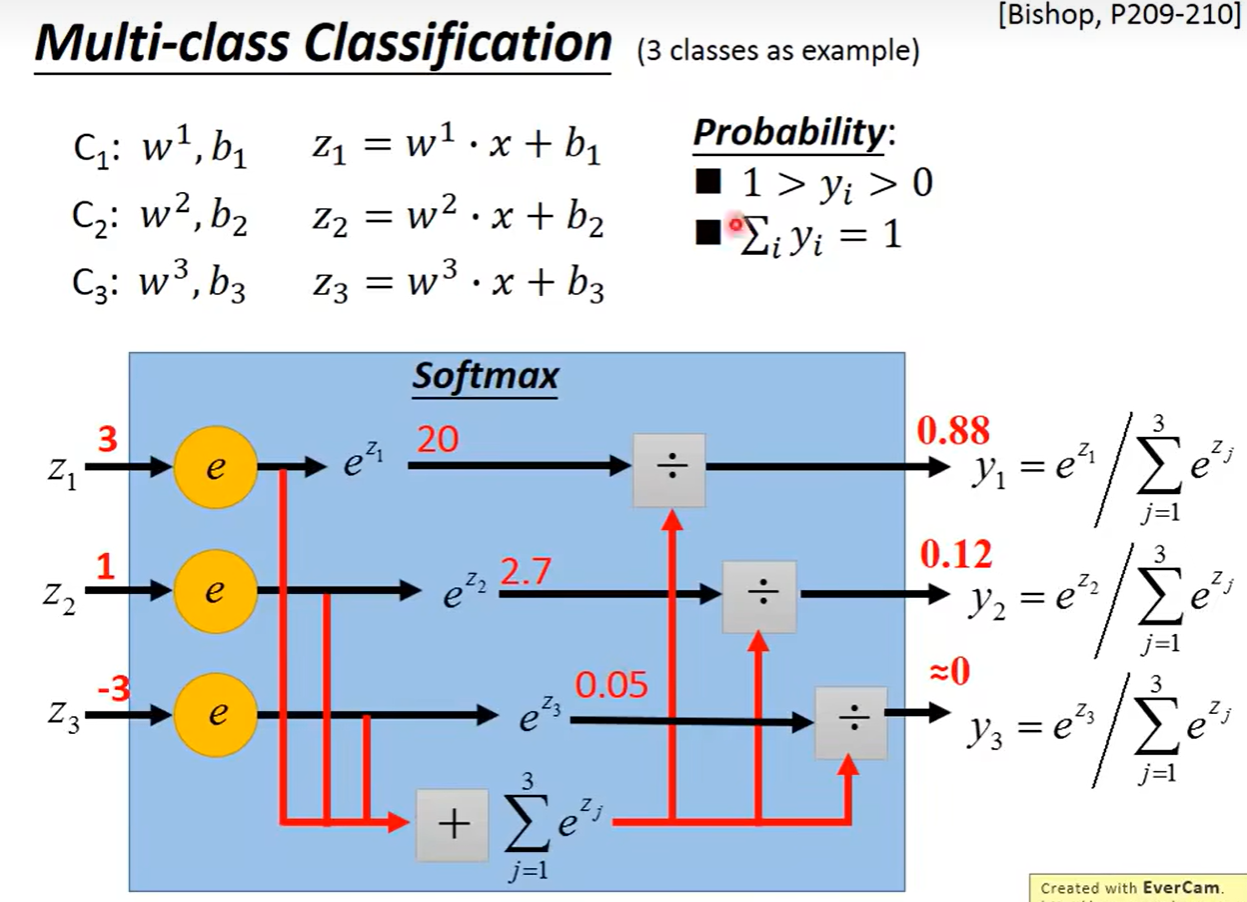
多分类模型
用三种类别的分类进行举例
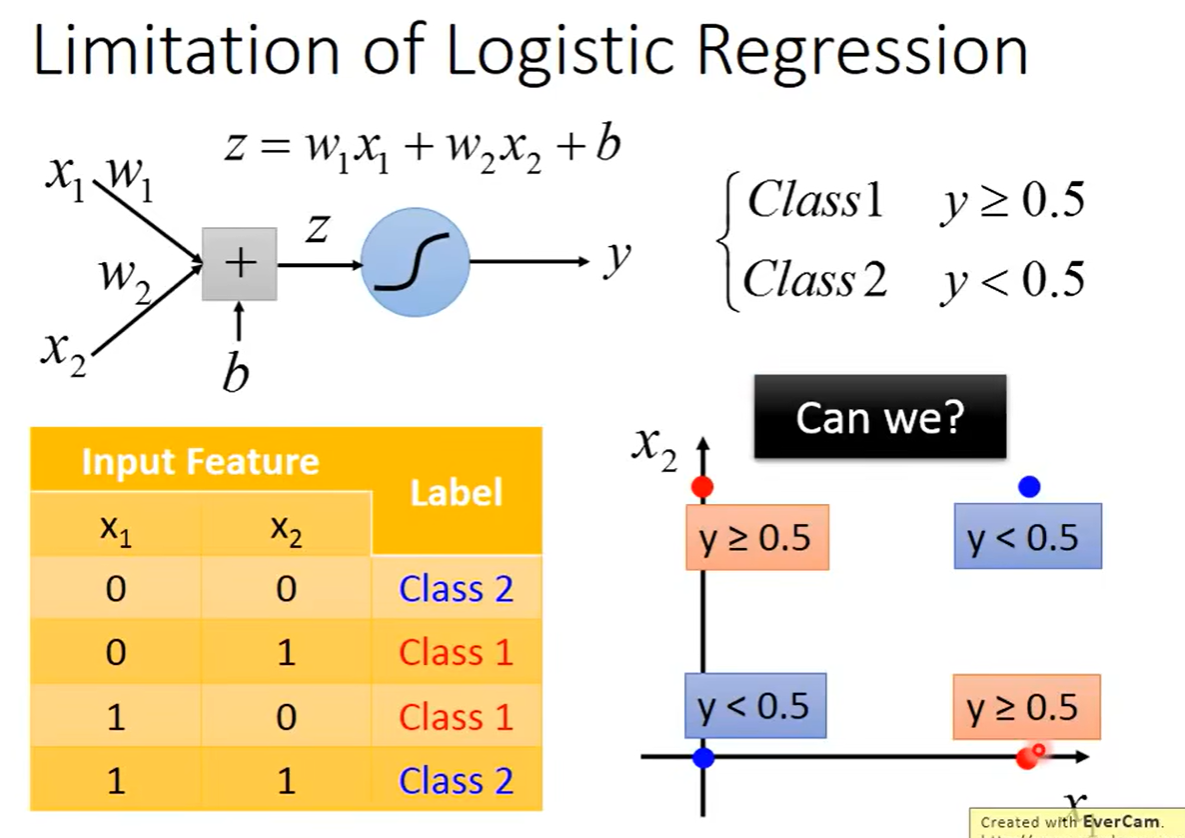
逻辑回归的局限性
在某些情况下,普通的逻辑回归并不能做到分类要求,所以需要有所改变。举个例子:正常来讲,我们更加希望如果是class1的话我们希望预测出来的y要大于0.5,如果是class2的话我们预测出来的y要小于0.5
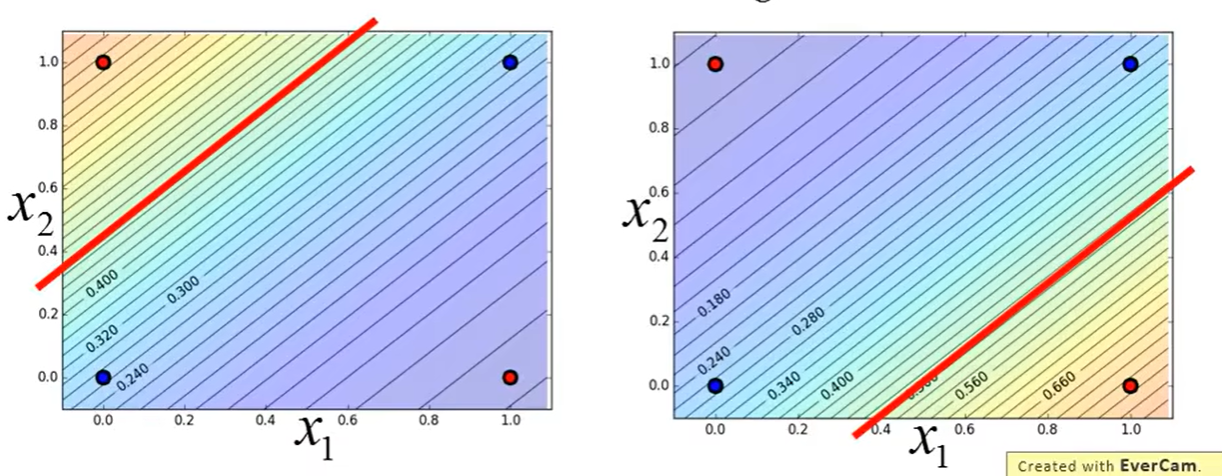
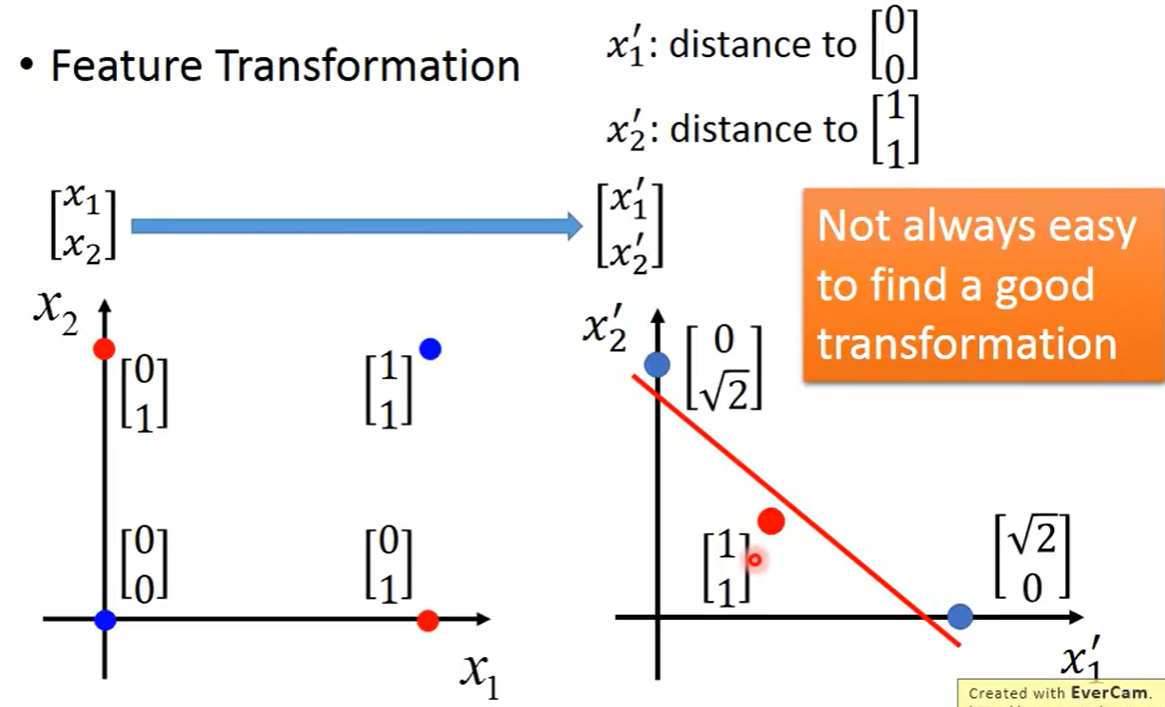
无论如何设置分割线,都无法将两个类别清晰的分割在直线的两边
有两个办法:
-
Feature Transformation 特征转换
但是特征的转换还是人工进行转换,依然具有一定的局限性
![]()
-
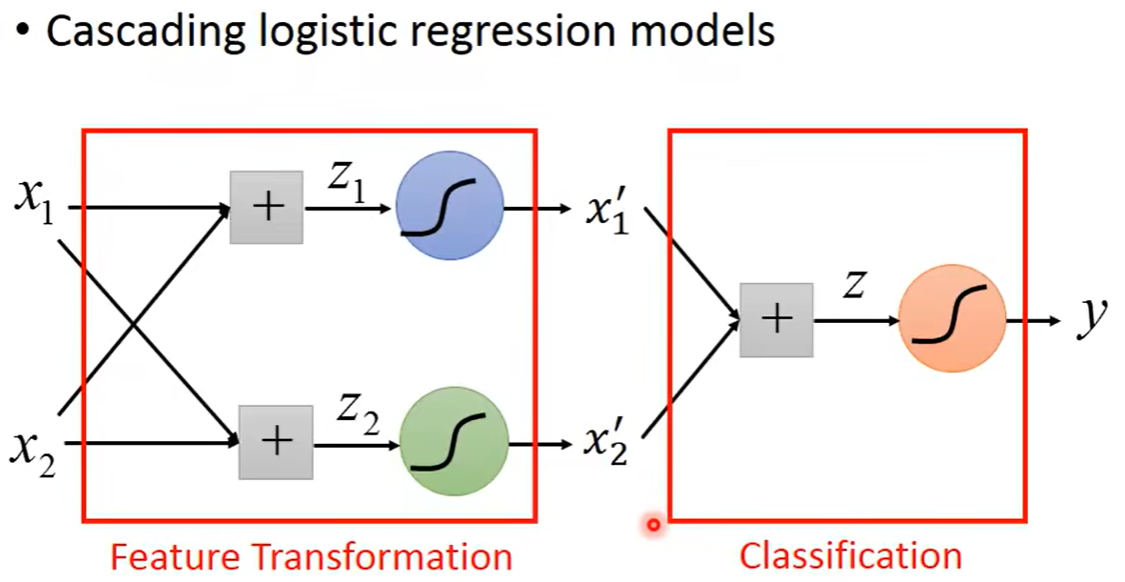
Cascading logistic regression models 级联逻辑回归模型
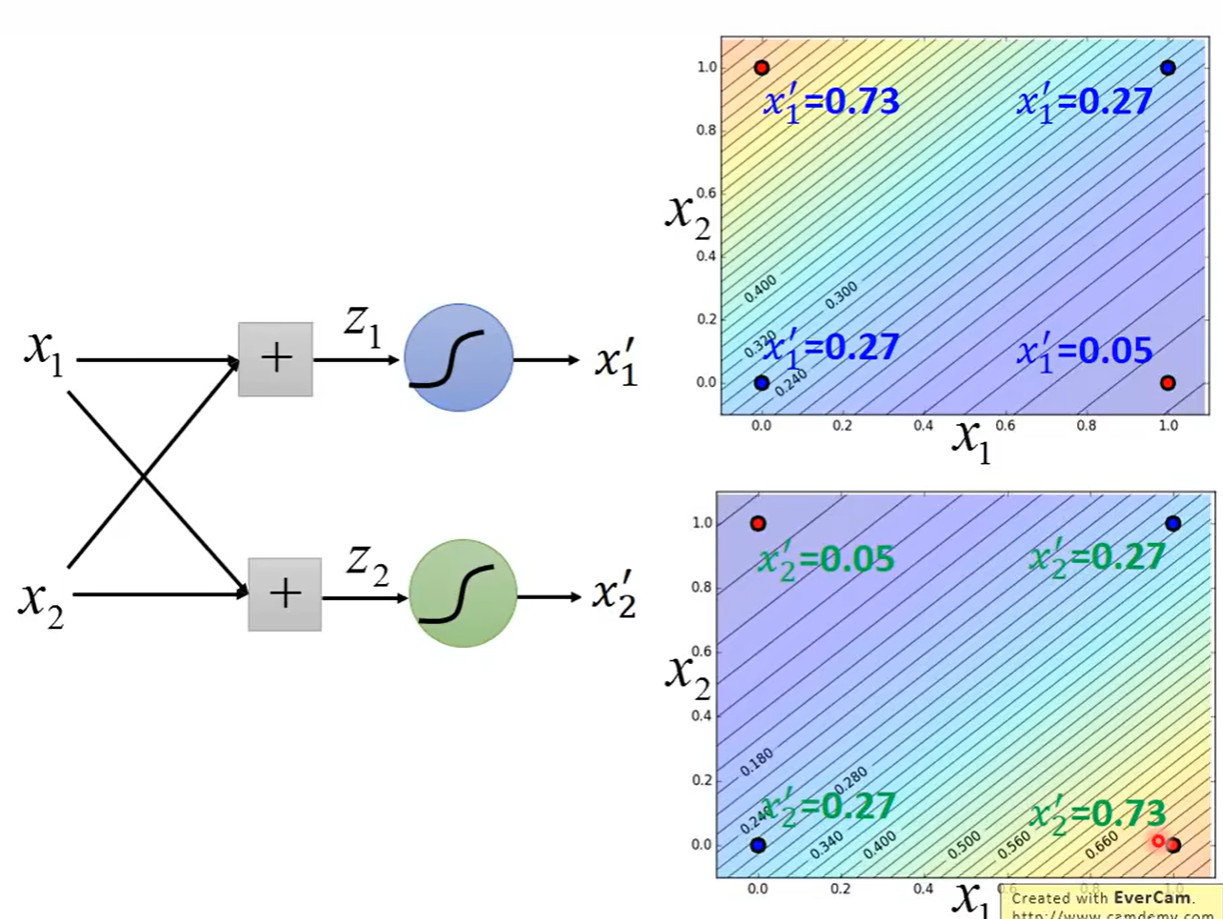
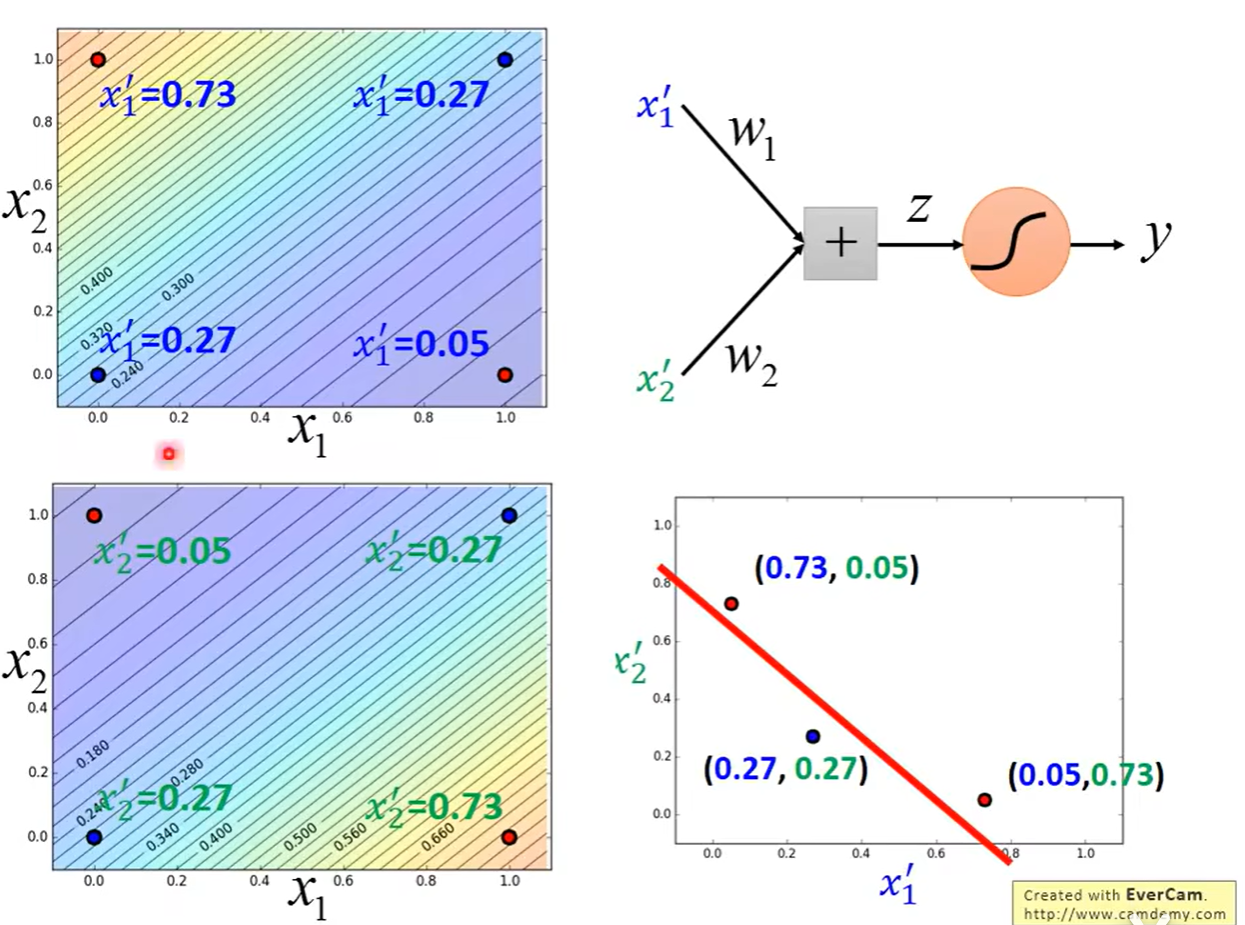
可以理解为神经网络的另一种表示,将多个逻辑回归进行级联,前面的逻辑回归用来特征转换,后面的用来进行分类
![]()
![]()
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号