

LeetCode297:hard级别中最简单的存在,java版,用时击败98%,内存击败百分之九十九
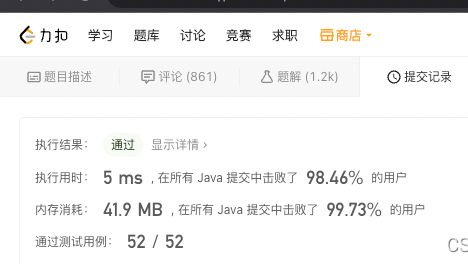 LeetCode的hard题都很难吗?不一定,297就非常简单,随本文一起,用最基础的知识写代码,执行用时能击败98.46%,与此同时,内存消耗击败99.73%
LeetCode的hard题都很难吗?不一定,297就非常简单,随本文一起,用最基础的知识写代码,执行用时能击败98.46%,与此同时,内存消耗击败99.73%
1.Java程序员的MacBookPro(14寸M1)配置备忘录2.群晖DS218+部署PostgreSQL(docker)3.Codespaces个性化后台服务器配置指南4.桌面版vscode用免费的微软4核8G服务器做远程开发(编译运行都在云上,还能自由创建docker服务)5.20天等待,申请终于通过,安装和体验IntelliJ IDEA新UI预览版6.LeetCode46全排列(回溯入门)7.LeetCode952三部曲之一:解题思路和初级解法(137ms,超39%)8.win11安装ubuntu(by wsl2)9.精选版:用Java扩展Nginx(nginx-clojure 入门)10.LeetCode买卖股票之一:基本套路(122)
11.LeetCode297:hard级别中最简单的存在,java版,用时击败98%,内存击败百分之九十九
12.支持JDK19虚拟线程的web框架,之一:体验13.支持JDK19虚拟线程的web框架,之三:观察运行中的虚拟线程14.支持JDK19虚拟线程的web框架,之四:看源码,了解quarkus如何支持虚拟线程15.支持JDK19虚拟线程的web框架,之五(终篇):兴风作浪的ThreadLocal16.快速搭建云原生开发环境(k8s+pv+prometheus+grafana)17.strimzi实战之一:简介和准备18.云端golang开发,无需本地配置,能上网就能开发和运行19.Go语言基准测试(benchmark)三部曲之一:基础篇20.Go语言基准测试(benchmark)三部曲之二:内存篇21.Go语言基准测试(benchmark)三部曲之三:提高篇本篇概览
- 因为欣宸个人水平有限,在刷题时一直不敢面对hard级别的题目,生怕出现一杯茶一包烟,一道hard做一天的窘境

- 这种恐惧心理一直在,直到遇见了它:LeetCode297,建议不敢做hard题的新手们速来围观,拿它练手,轻松找到自信
题目简介
-
- 二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
- 提示
提示:
树中结点数在范围 [0, 104] 内
-1000 <= Node.val <= 1000
- 接下来,先开始轻松愉快的分析工作
分析
- 小结一下题目要求,需要做两件事:
- serialize方法:输入二叉树根节点,返回字符串
- deserialize方法:输入字符串,方法内部根据字符串构建一棵二叉树,然后返回根节点
- 说实话,当时读题后的第一反应是:这是二叉树的基本操作嘛,一定是个easy,结果发现官方设定的难度是hard,当时就觉得赚大了!!!
- 简单的说,解题思路只有四个字:前序遍历
- 前序遍历是啥?很简单,是指一种遍历二叉树的顺序,看着下面的图,咱们一起默念:根左右,所以前序遍历下图二叉树的结果是:1,2,3
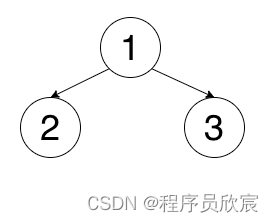
- 类似的还有中序遍历,中序遍历要求根节点在输出位置的中间,也就是左根右,还是上面那个二叉树,中序遍历的结果是:2,1,3
- 还有后续遍历是左右根,上面那个二叉树,后序遍历的结果是:2,3,1
- 至于本题为何要选前序遍历,因为字符串转二叉树时,会涉及到数组,而将根节点放在数组的最前面,这样既便于处理也便于理解
- 再来看看前序遍历的代码一般怎么写?或者说套路是什么?
- 伪代码如下,可见是个非常简单的递归操作
private void dfs(TreeNode root) {
// 终止条件是发现入参为空
if(null==root) {
return;
}
// 1. 根
处理root的代码
// 2. 左
dfs(root.left);
// 3. 右
dfs(root.right);
}
- 以前面那个图上的二叉树为例,分析上述代码如何执行:调用dfs的时候传入的是根节点,在dfs方法中,处理完根节点后,立即调用dfs处理左节点,在处理左节点的时候还会再递归一次,不让过左节点的子节点都是null,所以这个递归啥事也没做,处理完左节点后再调用dfs处理右节点,这样就完成了根左右的处理
- 没错,二叉树遍历的套路就是这么简单,至于中序和后续遍历的代码,和上面的差不多,无非是将三段代码的调用顺序调整一下即可
- 接下来,编码
编码:序列化
- 先看序列化的代码
- 首先准备一个StringBuilder类型的成员变量serializeRes,遍历到的每一个元素都存放在serializeRes的尾部,用逗号分隔
private StringBuilder serializeRes;
- 然后是serialize方法的实现,首先要判断root为空的特殊情况,另外就是serializeRes的初始化,然后就会调用serializeDfs方法,这个serializeDfs就是遍历二叉树的具体实现
public String serialize(TreeNode root) {
if (null==root) {
return null;
}
serializeRes = new StringBuilder();
serializeDfs(root);
return serializeRes.toString();
}
- 遍历二叉树的核心逻辑,serializeDfs方法如下,可见和咱们刚才的伪代码很像,每一个节点都会被存入serializeRes,并且以逗号分隔,只有一处需要注意,就是每当遇到root等于null,就在serializeRes尾部追加一个n,这样在serializeRes中就相当于每个节点没有左子节点或者右子节点的标志,这很重要!
private void serializeDfs(TreeNode root) {
if(null==root) {
serializeRes.append("n,");
return;
}
// 1. 根
serializeRes.append(root.val).append(",");
// 2. 左
serializeDfs(root.left);
// 3. 右
serializeDfs(root.right);
}
- 以前面图中那个最简单的二叉树为例是,上述代码输出的字符串内容如下,3在2,n,n之后,显然是将2和2的子节点都处理完毕后,才去处理3,这就是典型的根左右:
1,2,n,n,3,n,n,
编码:反序列化
- 接下来的反序列化,也是严格准守根左右的顺序实现的,关键是注意对字符n的处理,它表示一个节点没有左子节点或者右子节点了
- 首先是两个环境变量,deserializeArray是个数组,字符串用逗号分割之后生成的数组,代表整个要恢复的二叉树的所有元素,deserializeOffset用于记录数组中已经有多少个元素已经被回复到二叉树中了:
private String[] deserializeArray;
private int deserializeOffset;
- 然后是最外层的发序列化方法,可见首先是处理异常逻辑,然后就会用字符串分割生成数组,再调用构建二叉树的核心逻辑deserializeDfs:
public TreeNode deserialize(String data) {
if (null==data) {
return null;
}
deserializeArray = data.split(",");
deserializeOffset = 0;
return deserializeDfs();
}
- 最后看构建二叉树的核心逻辑deserializeDfs方法,不要以为构建二叉树的代码会比遍历二叉树的代码复杂,仔细看,发现还是严格准守根左右的顺序去处理的,先生成根节点,然后递归生产左子树和右子树,要注意的地方就是遇到字符n的时候就不要继续递归了,深度上已经到底了,需要返回上层,完成上层左子节点和右子节点的创建:
private TreeNode deserializeDfs() {
if (deserializeOffset>=deserializeArray.length) {
return null;
}
if ("n".equals(deserializeArray[deserializeOffset])) {
deserializeOffset++;
return null;
}
// 1. 根
TreeNode treeNode = new TreeNode(Integer.valueOf(deserializeArray[deserializeOffset++]));
// 2. 左
treeNode.left = deserializeDfs();
// 3. 右
treeNode.right = deserializeDfs();
return treeNode;
}
- 最后贴出完整的代码
public class Codec {
// 本题的整体思路是前序遍历,即:根左右
private StringBuilder serializeRes;
private String[] deserializeArray;
private int deserializeOffset;
private void serializeDfs(TreeNode root) {
if(null==root) {
serializeRes.append("n,");
return;
}
// 1. 根
serializeRes.append(root.val).append(",");
// 2. 左
serializeDfs(root.left);
// 3. 右
serializeDfs(root.right);
}
private TreeNode deserializeDfs() {
if (deserializeOffset>=deserializeArray.length) {
return null;
}
if ("n".equals(deserializeArray[deserializeOffset])) {
deserializeOffset++;
return null;
}
// 1. 根
TreeNode treeNode = new TreeNode(Integer.valueOf(deserializeArray[deserializeOffset++]));
// 2. 左
treeNode.left = deserializeDfs();
// 3. 右
treeNode.right = deserializeDfs();
return treeNode;
}
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if (null==root) {
return null;
}
serializeRes = new StringBuilder();
serializeDfs(root);
return serializeRes.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
if (null==data) {
return null;
}
deserializeArray = data.split(",");
deserializeOffset = 0;
return deserializeDfs();
}
}
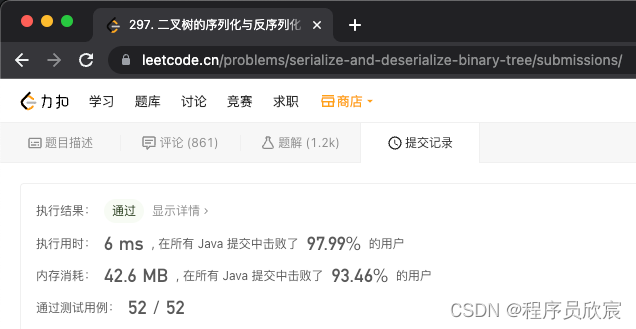
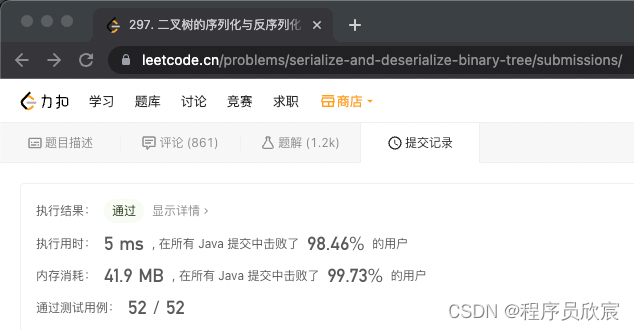
- 提交代码,如下图,顺利AC,速度超97%,同时内存超93%,感觉美滋滋的,这可个是一道hard呀!
小幅度优化
- 回顾此题,似乎还有一丁点优化空间:在序列化的时候,咱们用字符n作为子节点为空的标志,例如
1,2,n,n,3,n,n,
- 如果用空字符串取代n,那岂不是省掉了一些空间?
- 说干就干,一共有两处,第一处在序列化的时候,用n做结束标志的那段代码,改动如下图

- 第二处是反序列化的时候,判断是否为n的那段代码,改动如下图
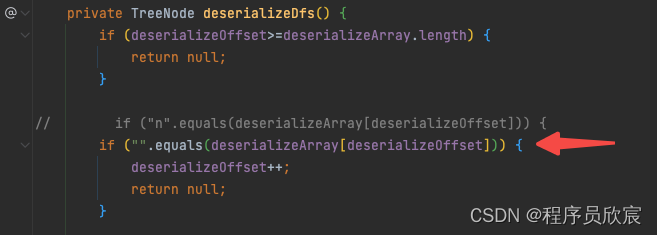
- 改完提交代码,效果如下图,速度和内存都有小幅度优化,第一次距离双百这么近!
- 至此,297的分析和实战已经完成,hard题能如此简单,实属不易遇到,所以不要错误哦,希望本文能给您一些思路,助您用最基础的代码,跑出最耀眼的成绩


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2021-09-09 client-go实战之四:dynamicClient
2019-09-09 在docker上编译openjdk8