

如何训练神经网络
今天看yolov5官网教程的Tips for Best Training Results,看到文章介绍Recipe for Training Neural Networks,做为“厨神”的我,看到“Recipe”灰常激动,赶紧记录,翻译水平有限,主要为了做个笔记:
一,神经网络普遍存在的问题:(好吧,这块受训练水平的影响,还是借鉴另一篇博客的翻译:神经网络六大坑)
1,you didn't try to overfit a single batch first
这句话是说再用大数据集训练之前先用小数据集试一下,排除一些明显的错误。(batch-size是很重要的超参数,需要仔细调节)
2,you forgot to toggle train/eval mode for the net
忘了为网络切换训练/评估模式。这个是针对model在训练和评估时,batchsize大小不同和Dropout中keep_prob值得不同。
3,you forgot to .zero_grad() (in pytorch) before .bachward()
这个错误我真正碰到过,忘记了写.zero_grad()各种nan,导致结果非常差,最后找了一天才找到。大家可以在实在找不到原因的是,打印梯度出来看看,是不是有某些层参数为0,几乎没有学习,有些为nan了,去逐步找原因。
4, you passed softmaxed outputs to a loss that expects raw logits
将softmaxed输出传递给损失函数,本来期望是logits值,而不是过了softmax之后的值。
大白话讲就是给函数传进去的参数错啦!!我们在编写代码的时候很容易犯这种错误,因为最后run起来的时候,它不报错啊,哥,不报错,只是结果很差,这很难受啊,我们很难发现错误,第一感觉,我去,idea不work,所以大家效果不好的时候,不要放弃啊,仔细看看有没有常见的bug!
5, you didn’t use bias=False for your Linear/Conv2d layer when using BatchNorm, or conversely forget to include it for the output layer. This one won’t make you silent fail, but they are spurious parameters.
使用BatchNorm时,您没有对线性/ 二维卷积层使用bias = False,或者反过来忘记将其包含在输出层中。 这个倒不会让你失败,但它们是虚假的参数。如果线性或者卷积层后面跟着BatchNorm, 线性或者卷积层不需要偏置项,即令bias=False,而只需要权重参数W。
为什么有BN的时候,就不用bias了呢?接下来是明白的过程:首先,看bias的有无到底会不会对BN的结果造成影响?
BN操作的关键一步可以简写为:$y_i = \frac{x_i - \bar{x}}{\sqrt{D(x)}}$,当加上偏执之后,为:$y_i^b=\frac{x_i^b-\bar{x^b}}{\sqrt{D(x^b)}}$,其中:$x_i^b=x_i+b$,然后,我们对公式进行化简:
而:
所以:$y_i^b = y_i$,好了,那么为什么没有bias的卷积层能够对BN后的输入学习到很好的决策面呢?当然啦,BN本身就是将数据归一化到标准分布的呀~
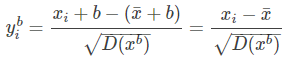
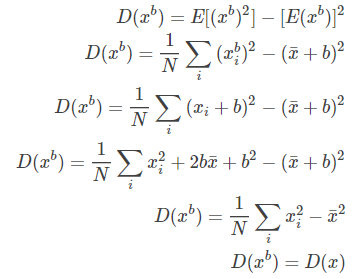
二,A Recipe for Training Neural Networks
几周前,我发表了一篇“神经网络常见错误”的推文,罗列了一些训练神经网络中常见的问题。这篇推文得到了比我期望更多的支持(包括网络研讨会:))。显然,很多人都遇到了从“这就是卷积层如何工作的”到“我们的卷积神经网络获得了最先进的结果”的盲区。
所以我觉得整理下我的博客来扩展一下之前的推文是件很有趣的事情。然而,我不会仅仅列举一些更多的错误或仅仅是更详细的解释一下之前的内容,我想介绍得更深入一些并聊一聊如何避免反这些错误(或快速的修正它们)。这样做的秘诀在于遵循某个特殊的过程,据我所知,这个过程还没有被记录下来。让我们从两个重要的观察开始:
2.1 Neural net training is a leaky abstraction
据说开始训练神经网络非常容易。很多库和框架都可以轻松的用30行代码片段来解决数据问题,给人一种(错误)的假象,认为这东西是即插即用的。经常会像这样:
>>> your_data = # plug your awesome dataset here >>> model = SuperCrossValidator(SuperDuper.fit, your_data, ResNet50, SGDOptimizer) # conquer world here
这些库和例子使得(神经网络)代码像我们大脑熟悉的普通代码一样——可以获得简洁的APIs和abstractions。用Requests库来举例:
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass')) >>> r.status_code 200
这非常酷!一个厉害的开发者扛起了:查询字符串,urls, GET/POST请求,HTTP连接,等等的重担,将这些复杂的知识大部分隐藏在几行代码之后。这是我们熟悉并且希望的。然而,神经网络却不是这样。当您稍微偏离训练ImageNet分类器之后,它们就不再是现成的技术。我试着在我的文章“Yes you should understand backprop”中说明这个观点,并称其为“弱抽象”,但不幸的是,情况更糟糕一些。反向传播+SGD 不能像魔法般的使你的网络工作。BN也不能像魔法般是你的网络收敛的更快。RNNs也不能像魔法一样使你“插入”文本。而且只是因为你可以将你的问题采用增强学习来建模,并不意味着你应该如此做。如果你不理解这些技术的原理却坚持使用他们,你很可能会失败,因此我将....
2.2 Neural net training fails silently
如果你中断或错误的配置代码时通常会导致一些异常的发生。比如应该是整型你输入了字符串;function只需要3个参数(而你输入多了或少了);都会引入失效。key不存在;两个数组的元素数不一致;另外,经常会为一些特定的功能创建一些单元测试(也会引发错误)。
这些(错误)只是开始训练神经网络的基础。每个人都能在语法上纠正这些错误,但是如果整个结构没有妥善安排,(这个错误)是很难被找出来的。“可能的错误面”非常大,而且是逻辑上的(相比较语法错误来说),对单元测试来说也非常棘手。比如,当你在做图像增强时左右翻转图像,却忘记了翻转标注。你的网络仍然可以工作的很漂亮(很吃惊吧?),因为你的网络可以自动的学习去识别翻转的图像并左右翻转预测结果。或者由于缓冲问题你的自回归模型意外的把待预测的东西当成输入了。或者在训练时你本来想要修剪梯度却意外的修剪了损失,造成了一些需要忽略的异常数据。或者当你使用预训练的参数来初始化权重时,但却没使用原来的均值。或者你只是配错了正则化权重,学习率,衰减率,模型大小等等。然而,(遇到这些问题)你错误配置的神经网络只有在幸运的时候才会抛出错误,通常情况下它只是默默的学习,但效果会差一些。
结论就是,用一个“速度与激情”的方法来训练神经网络是不可行的,只是会给你带来痛苦。现在,虽然痛苦是让神经网络正常工作的必经之路,但它可以通过完全彻底的可视化所有可能的细节来减轻。
The recipe
根据前面所述的两个事实,我在使用神经网络解决新问题时为自己总结了一个具体的流程,接下来我会具体介绍。你会发现我将会很重视上面说的两个原则。特别是,它从简单到复杂,在每一步中,我们都对将要发生的事情做出具体的假设,然后用实验来验证它们,或者进行调查,直到我们发现一些问题。 我们竭力避免的是同时引入大量“未经验证的”复杂性,这势必会引入漏洞/错误配置,而这些漏洞/错误配置将永远无法找到(如果有的话)。 如果编写神经网络代码就像训练一样,那么您可能希望使用很小的学习率,并在每次迭代后猜测并评估整个测试集。
1. Become one with the data
训练神经网络的第一步是先不要碰任何的神经网络代码,应该要彻底的观察你的数据。第一步是非常重要的。我喜欢花费大量的时间(通常是按小时来记)将上千个例子彻底观察,了解它们的分布并找出模式。幸运的是,你的大脑非常擅长做这个工作。有一次我发现数据包含了很多重复的例子。还有一次我发现了被损坏的图像/标注。我寻找数据的不平衡状态和偏置状态。我通常还会关注我自己对数据进行分类的过程,这暗示了我们最终将探索的架构类型。 举个例子,非常局部的特性就足够了吗?还是我们需要全局上下文? 有多少变化,它采取什么形式? 什么变异是假的,可以被预处理出来? 空间位置重要吗,还是我们要把它平均出来? 细节有多重要,我们能在多大程度上对图像进行取样? 标签有多少噪声?
此外,由于神经网络是数据集的有效压缩/编译版本,您将能够查看您的网络(错误)预测,并了解它们可能来自哪里。 如果你的网络给你的预测与你在数据中看到的不一致,那就有问题了。
一旦你有了定性的感觉,你就可以编写一些简单的代码来搜索/过滤/排序(例如标签类型、注释的大小、注释的数量等),并将它们的分布和异常值呈现在任意轴上。 异常值几乎总是能发现数据质量或预处理中的一些bug。
2. Set up the end-to-end training/evaluation skeleton+get dumb baselines
现在,我们了解了数据,可以开始训练完美的Multi-scaleASPP FPN ResNet模型了吗?肯定不行。那是通往痛苦的道路。我们的下一步是建立一个完整的训练+评估框架,并通过一系列的实验来保证其正确性。在这个阶段,最好选择一些你不可能搞砸的简单模型,例如一个线性分类器,或一个非常小的ConvNet。我们将训练它,可视化损失,任何其他指标(如准确性),模型预测,并使用具体的假设进行一系列的排除实验。
这个阶段的小窍门:
- fix random seed. 始终使用固定的随机化种子,以确保代码被运行两次时得到同样的结果。这可以排除随机的干扰使你不会太抓狂。
- simplify. 确保去掉任何不必要的“装饰”。例如,在这个阶段一定要关掉所有的数据增强,数据增强是我们要在后面用到的项正则化策略,但就现在来说,它只是一个会引入无声bug的因素。
- add significant digits to your eval. 在绘制测试损失时,在整个(大)测试集中运行评估。不要只是对批进行损失绘制,并依赖于在Tensorboard上对它们进行平滑。我们追求正确,也很乐意为了保持理智而放弃时间。
- verify loss @ init。 验证你的损失函数是从损失值的正确开始的。例如,如果你正确初始化最后一层,你需要初始化时在softmax层测量 -log(1/n_classes) 值,同样的默认值也可以用于L2 正则化,Huber损失等等。
- init well. 正确初始化最终层权重。 例如,如果你正在回归一些平均值为50的值,那么初始化最终偏差为50。 如果你有一个正负比为1:10的不平衡数据集,在你的logits上设置偏差,使你的网络在初始化时预测概率为0.1。 正确设置这些参数将加速收敛并消除“曲棍球”损失曲线,即在最初的几次迭代中,你的网络基本上只是学习偏差。
- human baseline. 监控人类可解释和可检查的损失之外的指标(例如准确性)。 在任何可能的情况下,评估你自己(人类)的准确性并与之进行比较。 或者,对测试数据进行两次注释,对于每个示例,将一个注释视为预测,将第二个注释视为基本事实。
- input-indepent baseline. 训练一个与输入无关的基线(例如,最简单的方法是将所有输入设置为零)。 这应该比实际插入数据而不将其归零时的性能更差。 不是吗? 例如,你的模型是否学会从输入中提取任何信息?
- overfit one batch. 使得单个包含少量样本的批次过拟合(例如,只有两个样本)。 为此,我们增加模型的容量(例如添加层或过滤器),并验证我们可以达到最低可达到的损失(例如零)。 我还喜欢把标签和预测在同一个图中形象化,并确保一旦我们达到最小损失,它们就会完美地对齐。 如果没有,那就说明某个地方有漏洞,我们就不能继续下一阶段了。
- verify decreasing training loss. 在这个阶段,您可能会在数据集上不合适,因为您使用的是一个玩具模型。 试着增加一点容量。 你的训练损失是否像它应该的那样有所减少?
- visualize prediction dynamics. 在训练阶段,我喜欢对一个固定的测试批次的模型预测进行可视化操作。预测值的“动态”变化可以让你对训练方向有个很好的直觉。很多时候,如果网络以某种方式摆动太多,显示出不稳定性,你可能会感到网络在“努力”适应你的数据。 非常低或非常高的学习率也很容易在抖动量中被注意到。
- use backprop to chart dependencies. 你的深度学习代码经常会包含复杂的,矢量化的和广播的操作。我遇到的一个相对常见的错误是人们弄错了(例如他们使用视图而不是某处的转置/置换)并且无意中混合了batch的维度信息。不巧的是,您的网络通常仍然可以正常训练,因为它会学会忽略其他示例中的数据。调试此问题(以及其他相关问题)的一种方法是将某个示例的损失设置为1.0,将反向传递一直运行到输入,并确保仅在该样本上获得非零梯度。更一般地说,梯度为您提供了网络中数据的依赖关系信息,这对调试很有用。
- generalize a special case.这是一个更通用的编码技巧,但我经常看到人们因为贪心,从头开始编写相对一般的功能,而导入bug。我喜欢为我现在正在做的事情编写一个专门的函数,让它工作,然后在确保我得到相同的结果再将其重构成一般功能的函数。这通常适用于矢量化代码,其中我几乎总是首先写出完全循环的版本,然后一次一个循环地将它转换为矢量化代码。
3. Overfit
在这个阶段,我们应该对数据有了很好的理解并且我们也有了完全训练+评估过,且正常工作的代码流水。对于任何给定的模型,我们都可以(重复地)计算一个我们信任的度量。 我们也有一个与输入无关的基线,一些差劲的基线的性能(我们最好打败这些),我们有一个人类表现的粗略感觉(我们希望达到这个)。 这个阶段是为了迭代一个好的模型。
我喜欢采用的得到一个好的模型的方法有两个阶段:首先得到一个足够大的模型,它可以过拟合(即关注训练损失),然后适当地将它规则化(放弃一些训练损失,以改善验证损失)。 我喜欢这两个阶段的原因是,如果我们不能在任何模型上达到低错误率,这可能再次表明一些问题、bug或配置错误。
这个阶段的小窍门:
- picking the model. 为了获得良好的训练损失,您需要为数据选择合适的体系结构。 说到选择这个,我的第一条建议是:不要逞英雄。 我见过很多人渴望疯狂和创造性地将神经网络工具箱中的乐高积木堆在各种对他们有意义的奇异建筑中。 在项目的早期阶段要强烈地抵制这种诱惑。 我总是建议人们简单地找到最相关的论文,复制粘贴他们最简单的架构,实现良好的性能。 例如,如果你正在对图像进行分类,不要逞英雄,只要在你的第一次运行时复制粘贴一个ResNet-50即可。 你可以在以后做一些更定制的事情,打败这个。
- adam is safe. 在设定baselines的早期阶段,我喜欢使用学习率为3e-4的Adam。 根据我的经验,adam对超参数更宽容,包括糟糕的学习率。 对于ConvNets来说,调优的SGD几乎总是会略强于Adam,但最优学习率区域要窄得多,而且是针对特定问题的。 (注意:如果你使用rnn和相关的序列模型,更常见的是使用Adam。 在你的项目的初始阶段,再次强调,不要逞英雄,遵循最相关的论文所做的一切。)
- complexify only one at a time. 如果你有多个信息要插入你的分类器,我建议你一个接一个地插入它们,每次都确保你得到预期的性能提升。 不要一开始就对你的模型太激进了。 还有其他方法来增加复杂性——例如,你可以尝试先插入较小的图像,然后使它们更大,等等。
- do not trust learning rate decay defaults. 如果你重新使用其他领域的代码,一定要小心学习速率的下降。 您不仅希望对不同的问题使用不同的衰减调度,而且——更重要的是——在典型的实现中,调度将基于当前的epoch数,这可能仅仅取决于您的数据集的大小而有很大的不同。 ImageNet在epoch 30时1衰减10。 如果您没有训练ImageNet,那么您几乎肯定不想要这个。 如果您不小心,您的代码可能会过早地将您的学习率降为零,从而使您的模型无法收敛。 在我自己的工作中,我总是完全禁用学习速率衰减(我使用一个恒定的LR),并在最后进行调整。
4. Regularize
理想情况下,我们现在有一个大的模型,至少适合训练集。 现在是时候将其规范化,并通过放弃一些训练准确性来获得一些验证准确性了。
一些小窍门:
- get more data. 首先,到目前为止,在任何实际设置中正则化模型的最好和首选方法是添加更多的真实训练数据。 这是一个非常常见的错误,当你可以收集更多的数据时,却花费大量的工程周期试图从一个小数据集中榨取能量。 据我所知,添加更多的数据几乎是唯一能保证单调地提高配置良好的神经网络性能的方法。 另一种是集成(如果你可以负担的起的话),但也会在大约5个模型之后达到极限。
- data augment. 仅次于真实数据的是半假数据——尝试更积极的数据扩充。
- creative augmentation. 如果半假数据不能做到这一点,那么假数据也可能会有些帮助。 人们正在寻找创造性的方法来扩展数据集; 例如,随机化领域,模拟器的使用,聪明的数据混合,如插入(很可能是模拟的)数据到背景中,甚至GAN。
- pretrain. 在任何情况下,即使你有足够的数据,使用预训练模型也没有坏处,只要你可以。
- stick with supervised learning. 不要对无监督预训练过于激动。不像是2008年那篇博客说的一样,据我所知,在现阶段的计算机视觉中没有任何版本的无监督训练模型有很好的结果(though NLP seems to be doing pretty well with BERT and friends these days, quite likely owing to the more deliberate nature of text, and a higher signal to noise ratio)
- smaller input dimensionality. 去除可能包含虚假信息的特征。 如果数据集很小,任何添加的虚假输入都只是另一个过度拟合的机会。 类似地,如果低层次的细节不重要,尝试输入更小的图像。
- smaller model size. 在许多情况下,您可以使用网络的领域知识约束来减小其规模。 举个例子,在ImageNet的主干顶部使用全连接层曾经是一种时尚,但现在这些已经被简单的平均池取代,消除了过程中的大量参数。
- decrease the batch size. 由于批范数内的归一化,较小的batch size在某种程度上对应较强的正则化。 This is because the batch empirical mean/std are more approximate versions of the full mean/std so the scale & offset “wiggles” your batch around more.
- drop. 增加dropout, 对ConvNets使用dropout2d(spatial dropout)。用dropout的时候必须小心谨慎,因为dropout好像和BN在一起使用结果并不是特别好。
- weight decay. 增加weight 衰减惩罚
- early stopping. 根据你的验证损失值来提前停止训练,以确保模型不会过拟合。
- try a larger model. 我最后才提到这一点,而且是在early stopping后才提到的,但我发现过去有几次较大的模型当然最终会过你和,但它们的“early stopping”性能通常会比较小的模型好得多。
最后,为了进一步确信您的网络是一个合理的分类器,我喜欢可视化网络的第一层权值,并确保得到合理的边缘值。 如果你的第一层滤波器看起来像噪声,那么有些东西可能是关闭的。 类似地,网络内部的激活函数有时会显示的很奇怪并暗示问题。
5. Tune
现在你应该处在一个使用数据集来探索未知的模型空间来获得低验证损失的循环中。
一些小窍门:
- random over grid search. 对于同时调优多个超参数,使用grid search来确保所有设置的覆盖可能听起来很诱人,但请记住,最好使用随机搜索。 从直觉上看,这是因为神经网络对某些参数比其他参数更敏感。 在极限情况下,如果参数a很重要,但改变b没有影响,那么你宁愿对a进行更彻底的采样,而不是在几个固定的点上多次采样。
- hyper-parameter optimization. 现在有大量的贝叶斯hyper-parameter优化工具箱,我的朋友也有过使用它们的成功案例。但我个人的经验是,当你使用最先进的方法来探索一个漂亮和大的空间模型时,hyper-parameters就是实习生:)。 只是开玩笑。
6. Squeeze out the juice
一旦你找到了最好的架构类型和超参数,你仍然可以使用更多的技巧来将系统的最后提升一点点:
- ensembles. 模型集成是一种几乎可以保证获得2%精确度提升的方法。 如果您负担不起测试时的计算,那么可以使用暗知识将您的集成集成到一个网络中。
- leave it training. 我经常看到人们在验证损失似乎趋于稳定的时候试图停止模型训练。 根据我的经验,网络会持续训练很长时间。 有一次我在寒假期间不小心错过了一个模型的训练,当我在1月份回来的时候,那是SOTA(“state of the art”)。
Conclusion
一旦你成功了,你就拥有了成功的所有要素: 您已经对技术、数据集和问题有了深刻的理解,您已经建立了整个培训/评估基础设施,并对其准确性有了很高的信心,您已经探索了越来越复杂的模型,并以您预测的每一步的方式获得了性能改进。 现在您已经准备好阅读大量的论文,尝试大量的实验,并得到您的SOTA(state of the art)结果。 好运!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号