

目标检测之YOLOv3
YOLOv3没有太多的创新,主要是借鉴一些好的方案融合到YOLO里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。本文主要讲v3的改进,由于是以v1和v2为基础,关于YOLOv1和YOLOv2的分析请移步YOLOv1 深入理解和YOLOv2/YOLO 9000深入理解。
YOLOv3的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
一,YOLOv3算法
YOLOv3 处理流程
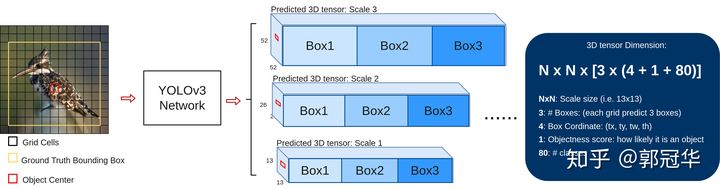
首先如上图所示,在训练过程中对于每幅输入图像,YOLOv3会预测三个不同大小的3D tensor,对应着三个不同的scale。设计这三个scale的目的就是为了能够检测出不同大小的物体。在这里我们以13*13的tensor为例做一个简单讲解。对于这个scale,原始输入图像会被分割成13*13的grid cell,每个grid cell对应着3D tensor中的1*1*255这样一个长条形voxel。255这个数字来源于(3*(4+1+80)),其中的数字代表bounding box的坐标,物体识别度(objectness score),以及相对应的每个class的confidence,具体释义见上图。
其次,如果训练集中某一个ground truth对应的bounding box中心恰好落在了输入图像的某一个grid cell中(如图中的红色grid cell),那么这个grid cell就负责预测此物体的bounding box,于时这个grid cell所对应的objectness score就被赋予1,其余的grid cell 则为0。此外,每个grid cell还被赋予3个不同大小的prior box。在学习过程中,这个grid cell会逐渐学会如何选择哪个大小的prior box,以及对这个prior 波形进行微调(即offset/coordinate)。但是grid cell是如何知道该选取哪个prior box呢?在这里作者定义了一个规则,即只选取与ground truth bounding box的IOU重合度最高的那个prior box。
上面说了有三个预设的不同大小的prior box,但是这三个大小是怎么计算得来的呢?作者首先在训练前,提前将COCO数据集中的所有bbox使用K-means clustering分成9个类别,每3个类别对应一个scale,这样总共3个scale。这种关于box大小的先验信息极大地帮助网络准确的预测每个box的offset/coordinate,因为从直观上,大小合适的box将会使网络更快速精准地学习。
YOLOv2已经开始采用K-means据类得到先验框的尺寸,YOLOv3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。YOLOv3使用logistic regression为每个bounding box预测一个objectness score(用来表示该bounding box包含一个object的可能性)。在训练时,如果该bounding box对应的prior(即anchor box)与一个ground truth box的IOU高于其它任何bounding box prior,那么该bounding box的objectness score就被置为1;如果该bounding box对应的prior不是最好的但是又确实与一个ground truth box的IOU高于设定的阈值,那么该bounding box会被忽略。论文中作者使用的阈值是0.5。另外,YOLOv3在训练时为每个ground truth object只分配一个bounding box prior(相当于一个bounding box,因为每个cell有k个bounding box prior,每个bounding box prior对应一个bounding box)。如果一个bounding box没有分配到ground truth object,那么在计算定位损失和分类损失时它不会被考虑在内,也就是说只有包含ground truth object的bounding box才会参与训练损失的计算。
1.1,网络模型结构
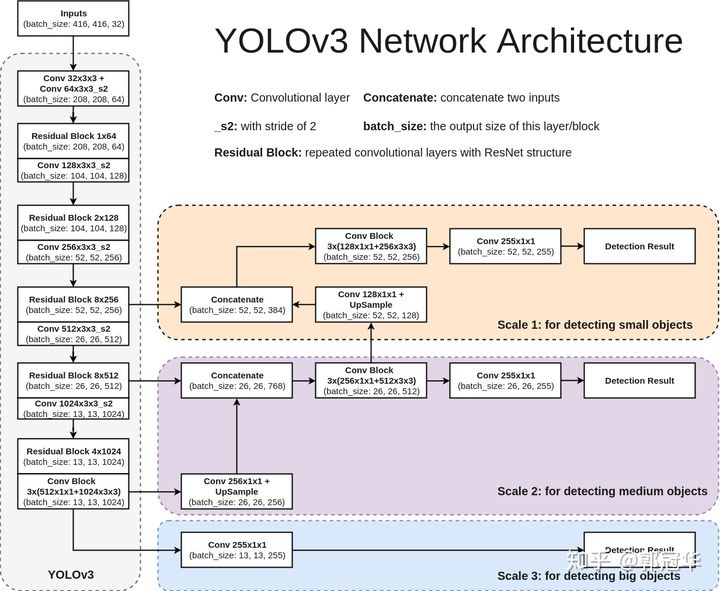
下图是YOLOv3的网络模型结构图,此结构主要由75个卷积层构成,卷积层对于分析物体特征最为有效。由于没有使用全连接层,该网络可以对应任意大小的输入图像。此外,池化层也没有出现在YOLOv3当中,取而代之的是将卷积层的stride设为2来达到下采样的效果,同时将尺度不变特征传送到下一层。除此之外,YOLOv3中还使用了类似ResNet和FPN网络的结构,这两个结构对于提高检测精度也是大有裨益。
1.2 3 Scales:更好的对应不同大小的目标物体
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。并且网络越深,特征图就会越小,所以越往后的物体也就越难检测出来。SSD中的做法是,在不同深度的feature map获得后,直接进行目标检测,这样小的物体会在相对较大的feature map中被检测出来,而大的物体会在相对较小的feature map中被检测出来,从而达到对应不同scale的物体的目的。
然而在实际的feature map中,深度不同所对应的feature map包含的信息就不是绝对相同的。举例说明,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在 不同级别的feature map中进行检测,听起来好像可以对应不同的scale,但是实际上精度并没有期待的那么高。
在YOLOv3中,这一点是通过采用FPN结构来提高对应多重scale的精度的。
多重scale主流方法
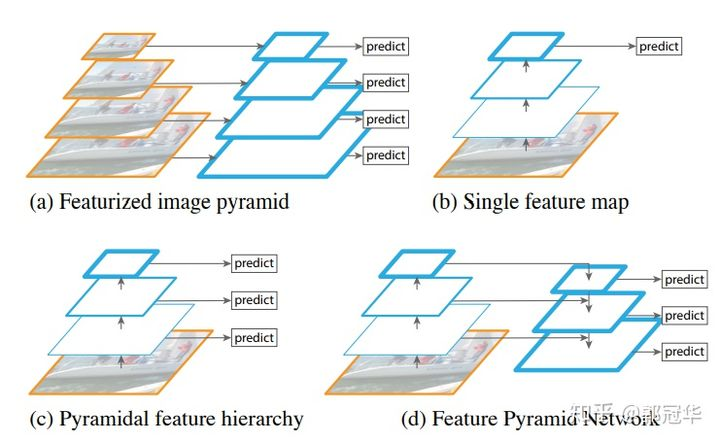
如图所示,对于多重scale,目前主要有以下几种主流方法。
(a) 这种方法最直观。首先对一幅图像建立图像金字塔,不同级别的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢。
(b) 检测直再最后一个feature map阶段进行,这个结构无法检测不同大小的物体。
(c) 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) 与(c)很接近,但有一点不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。这是一个有跨越性的设计。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。
1.3 ResNet残差结构:更好的获取物体特征
YOLOv3中使用了ResNet结构(对应着在上面的YOLOv3结构图中的Residual Block)。Residual Block是有一系列卷积层和一条shortcut path组成。shortcut如下图所示:
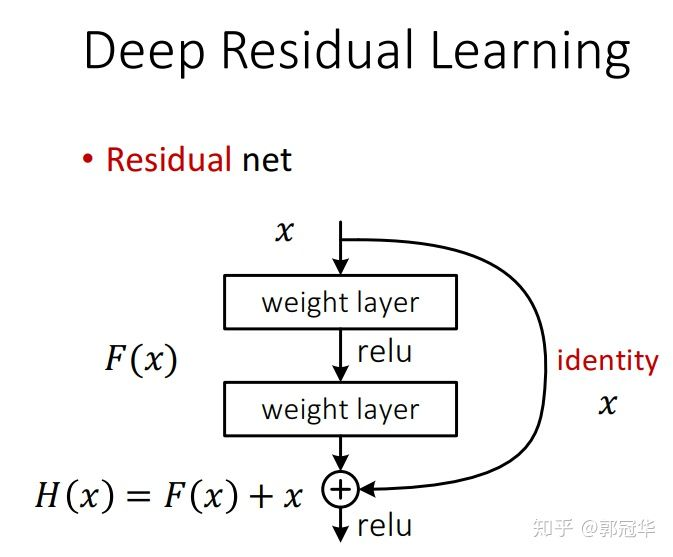
图中曲线箭头代表的便是shortcut path。除此之外,此结构与普通的CNN结构并无区别。随着网络越深,学习特征的难度也就越来越大。但是如果我们加一条shortcut path的话,学习过程就从直接学习特征,变成在之前学习的特征的基础上添加某些特征,来获得更好的特征。这样一来,一个复杂的特征H(x),之前是独立一层一层学习的,现在就变成了这样一个模型H(x)=F(x)+x,其中x是shortcut开始时的特征,而F(x)就是对x进行的填补与增加,成为残差。因此学习的目标就从学习完整的信息,变成学习残差了。这样以来学习优质特征的难度就大大减小了。
1.4 替换softmax层:对应多重label分类
Softmax层被替换为一个1*1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情况(例如woman和person)的数据集中,使用softmax就不能使网络对数据进行很好的拟合。
二,解释输入输出
YOLOv3仅使用卷积层,使其成为一个全卷积网络(FCN)。文章中,作者提出一个新的特征提取网络,Darknet-53。正如其名,它包含53个卷积层,每个后面跟随着batch normalization层和leaky ReLU层。没有池化层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,这样可以有效阻止由于池化层导致的低层级特征的损失。
输入:输入是(m, 416, 416, 3),m是batch-size大小
输出:带有识别类的边界框列表,每个边界框由$(p_c, b_x, b_y, b_h, b_w, c)$六个参数表示,c表示类别数。在YOLO中,预测过程使用一个1*1卷积,输入是一个特征图。1*1卷积只是用于改变通道数。从YOLOv3开始,每个锚点对应三个锚框(锚框大小和尺寸比例可以通过K-means聚类得到)。由于FPN结构,如1.1图中scale1, scale2和scale3每层分别负责3个锚框。因此,输出大小为3*(5+C),例如预测类别为80,scale3输出深度为 13*13*255.
摘自:
参考:
https://www.cnblogs.com/Lilu-1226/p/10587987.html
https://zhuanlan.zhihu.com/p/76802514

 浙公网安备 33010602011771号
浙公网安备 33010602011771号