

目标检测两个基础部分——backbone and detection head
转自:《目标检测》-第2章-Backbone与Detection head
这里简单介绍以下目标检测网络构成的两个基础部分:Backbone 和 Detection head.
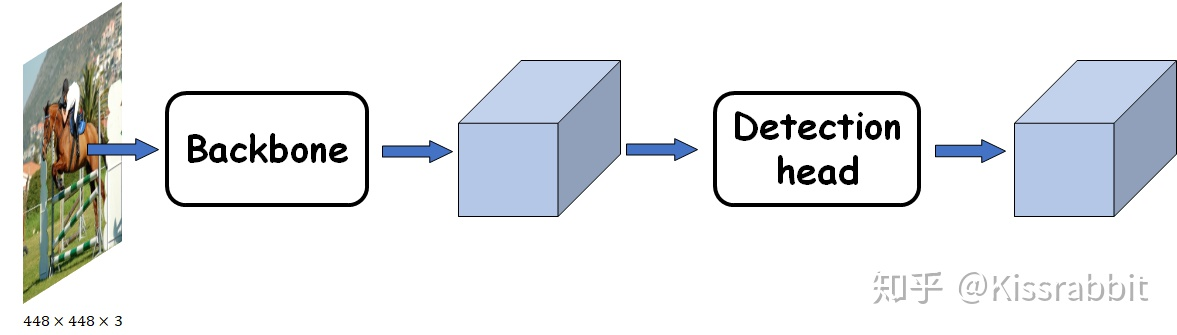
图一,目标检测网络的两个重要组成部分:backbone 和 detection head
一,Backbone 和 Detection head
通常,为了实现从图像中检测目标的位置和类别,我们会先从图像中提取些必要的特征信息,比如HOG特征,然后利用这些特征取实现定位和分类。而在深度学习这一块,backbone部分的网络就是负责从图像中提取特征。当然,这里提出的是什么样的特征,我们是无从得知的,毕竟深度学习的“黑盒子”特性至今还无法真正将其面纱揭开。
那么,如何取设计一个backbone取提取图像中的特征呢?
从某种意义上来说,如何设计好的backbone,更好地从图像中提取信息,是至关重要地,特征提取不好,自然会影响到后续的定位检测。早在目标检测任务之前,深度学习技术就已经在图像分类领域中发挥了重大的作用,大力促进了这一领域的发展,尤其是在ResNet系列的工作问世后,图像分类任务几乎达到了一个顶峰——从ImageNet比赛不再举办这一点就可以窥见一斑。虽然后续这个领域还在陆陆续续地出现些新工作(如GhostNet,ShuffleNet,ResNet各种升级版本,EfficientNet家族等),提供了很多新的idea,不过基本上已经不再是当年那种百花齐放的盛况了。
深度学习技术能够这么出色的完成图像分类任务,基本上验证了其在图像特征提取这一块的出色表现和巨大潜力。
现在,让我们将注意力拉到我们的主人翁来——目标检测。
考虑到在目标检测任务重,也需要对图像中的物体进行类别的识别。因此,一个很直接的想法就是将图像分类的网络拿过来。不过,目标检测除了需要分类,更重要的一点是在于定位,而这一点恰恰是分类任务的网络所不具备的。
因此,直接使用图像分类的网络做目标检测似乎在原理上就存在问题。
随着迁移学习概念的兴起和普及,迁移+微调这一概念成熟,因此,通过在检测任务中的数据集上对分类网络进行微调似乎是一个很不错的想法——所谓的“ImageNet pretrained model”概念就诞生了。简单地来说,就是目标检测和图像分类这两个任务具有一定地相似性,因为可以将分类的网络,比如VGG, ResNet等,用来做特征提取器。这一部分,我们就称其为backbone。也许它们对图像中目标的位置不够敏感,但至少它们能够提取图片中目标的类别特征。
另一方面,在深度学习领域中,有监督学习仍然是主流,尽管这些年诸如自监督、半监督等方兴未艾,仍然难以撼动有监督学习的第位。既然如此,数据量变成了要给不得不考虑的一个点。然而,不幸的是,目标检测领域不存在类似ImageNet这么庞大的数据库(那时候COCO和Object365都还没有放出来)。这一点也使得“与训练+迁移+微调”这一路子成为了必然。
而问题的关键就在于“迁移学习+微调”的“工艺”了。
前面提到了backbone网络这一字眼,所谓的backbone,直接翻译过来就是“骨干”,很明显,这个单词的含义就表明了它并不是整体的网络。既然两个任务具有相似性,再加上迁移学习思想的普及,为什么还会要用这么个单词来描述它呢?事实上,尽管OD和图像分类两个任务具有相似性,但不完全是等价的,OD的目标是实现对物体的定位和分类,而图像分类仅仅是对图像中的物体进行分类,而不会去定位。于时,就在“定位”这一点上,完全将分类网络搬过来使用显然是不恰当的(准确来说,是将ImageNet上训练的参数直接加载进来,作为初始参数再去微调是不恰当的,而不是网络模型本身,网络模型本身只是个架构,完全可以随机初始化去训练的。因为在ImageNet上训练出来的参数已经掉进了分类任务的一个局部最优点,那么在不改变现有模型任何架构——不增加网络层也不删减网络层——的情况下,通过这种局部最优点在OD任务上是否合适呢?或者说,模型能通过微调就跳出这个“旧”的极值点走进“新”的极值点吗?我难以下个普适的定论。仅根据我个人经验,这个过程比较困难。)
从优化目标上来看,分类任务只做分类,而OD还需要做定位,因此,任务驱动不同,目标不同,因此,完全有理由相信二者的优化空间有很大的差异。所以,仅仅是微调网络是无法完成OD任务的,当然,这一点,我们会在后续的实践来验证的。
那么该怎么办?
解决的办法相当简单,既然仅仅靠分类网络的参数是不行的,但是我们还需要它(那时候的数据量和训练tricks还不足以有效直撑train from scratch),那么我们就在后面加一些(训练时随机初始化的)网络层,让这些额外加进来的网络层去弥补分类网络无法定位的先天缺陷。
于是,这条脉络就非常清晰了:分类网络迁移过来,用作特征提取器,后续的网络负责从这些特征中,检测目标的位置和类别。当然,两部分会合到一起在OD数据集上去训练,使得它提取出来的特征更适合OD任务。那么,我们九江分类网络所在的环节称之为“Backbone”也就是情理之中的了。而后续连接的网络层由于主要是服务于detection任务,因此称之为“Detection head”。
随着技术的发展,除了backbone和head这两部分,更多的新奇的技术和模块被提了出来,最著名的,莫过于FPN了——《Feature Pyramid Networks for Object Detection》提出的FPN结构,在不同的尺度(实际上就是不同大小的feature map)上去提取不同尺度的信息,并进行融合,充分利用好backbone提取的所有的特征信息,从而让网络能够更好的检测物体。有了FPN, backbone提取出的信息可以被利用的更加充分,使得detector能够很好的应对多尺度情况——图像中,目标的大小不一,大的、中等的、小的都有,尤其是小物体,几乎成为了目标检测这一块的单独研究点。
除了FPN这种新颖的结构,还有诸如ASFF、RFB、SPP等好用的模块,都可以插在backbone和detection head之间。由于其插入的位置的微妙,故而将其称之为“neck”,有些文章中直接把它翻译成“瓶颈”或“脖子”,无论哪种翻译,都怪怪的,没内味儿……neck这部分的作用就是更好地融合/提取backbone所给出的feature,然后再交由后续的head去检测,从而提高网络的性能。因此,现在一个完整的目标检测网络主要由三部分构成:detector=backbone+neck+head
最后再说一点backbone。
随着目标检测领域的兴起,越来越多的学者和研究员意识到了这一领域中数据集匮乏的弊端,故而既老旧的VOC之后,微软的COCO、旷世Object365,以及其他的该领域数据集,陆续地放了出来。有了充足的数据量,似乎Pretrain on ImageNet就不是必需环节了,迁移+微调也可以省掉了。于是,train from scratch的路线就回来了。注意,这里用的是“回来”,因为这一路线是很朴素的,甚至不值得挂在嘴边。网络参数随机初始化去训练本就是个基本操作,而imagenet pretrained model能在OD领域中盛行,主要还是因为OD本身数据就不够,外加大家还有点舍不得ImageNet这么丰富的图像数据库。当然,也是因为不是每个人都有足够的算力去支撑train from scratch的,这点是不容忽视的~
尽管现在学术界已经知道了不用那些在ImageNet上预训练的模型作为backbone,而是自己搭建backbone网络或者使用随机初始化的分类网络,也能够达到同样的效果,但是这样的代价就是需要花更多的实践来训练,如何对数据进行预处理也是要注意的,换句话说,给调参带来了更多的压力。关于这一点,感兴趣的读者可以阅读Kaming He的《Rethinking ImageNet Pre-training》。
即便如此,大家还是会优先使用预训练模型,毕竟省时省力。不是每个人都有那么充足的算力去调参的。backbone这部分可以说很大程度上决定了detector的性能,所以,这部分的研究意义也很大,不过,很吃GPU这点还是很现实的,毕竟要先在imagenet上去pretrain一下,这就花不少时间,然后再替换现有的detector的backbone网络,去COCO上训练看涨点否,这又得花一大把时间……
PS:原博客评论中作者回答的问题很经典:
Q:大的方面总结的很好,但是从现在的时间来看,总结的都有点过时了。这两年又出了好多新的网络和论文,虽然骨干网络没多大变化,但是各种模块和tricks的结合,又不断刷高了map。我搜到这里的目的是想知道head里面到底是什么,因为看到一篇顶会在讨论全连接head和卷积head。另外看到文中写到的关于backbone的说法,提到分类网络和检测网络的区别,为什么说分类网络不能直接适用于检测网络呢?分类网络不是也要对图像中的各类目标进行查找并根据特征进行类识别吗?为什么说没有定位呢?是不是说没有精确的定位的意思?而现在目标检测的目的肯定是要进行定位和分类识别的,所以两者都要兼顾?是这个意思吗?
A:1,的确,如您所说,从我最初写完这篇文章到现在,有了很多新的工作,不过,我没有跟踪技术发展不断更新此文的目的就是因为我认为当下的绝大多数OD网络还是在backbone+neck+head的这个框架,尽管这里面有了好多新module和新trick,但我认为没有影响到我对这个框架的大的方面的总结。倒是Facebook出的基于transformer做detection 的新思路,我倒一直想单开一章,不过,也是无暇顾及此事了,实属遗憾~我这文章充其量也不过是入门之作,必须承认,凭我自己的阅历和水平,还是难以做到与时俱进的更新,还望见谅!
2,关于head,其实,把整个15年到19年的顶会工作放到一块揣摩揣摩,不难发现,对于head其实并没有backbone这么明确:使用imagenet pretrained model。head这一部分,简单来看就是在backbone部分给出的feature map上做detection任务,为了增加性能,head之前又多了neck部分,整合那些feature map,然后再交由head。所以,head其实就是负责输出detection结果的那些卷积层,看很多代码里,也都是把这部分注释为head。举个例子,YOLOv3或YOLOv4,都是先用neck部分的FPN(+SPP)将backbone输出的三个feature map进行融合,然后再依次接了若干卷积层去在每一个feature map上输出conf,class,bbox。所以,head到底是什么也就不言而喻了,但是很明显,对于head部分大家都没有太关注,这些年大部分的改进都是集中在backbone和neck两部分,没有在意head,而我觉得,head很重要,前两者的作用在于整合出更好的特征,但head才是决定能否将这些特征转换为我们真正需要的bbox参数和class参数。另外,head部分是用全连接更好还是卷积更好呢?我的想法是:全连接可以从全局感受野中来对图像中的物体进行一个检测,而卷积的那种窗口等价于滑动窗口,只关注局部信息,这个局部就是感受野,也就是在“数格子”,一个格子一个格子去看。那么二者哪个更好呢?实在抱歉,我无法解答。
3. 分类网络不适用于做detection,指的是只加载imagenet pretrained的weight,不添加额外的网络层,只对最后一层的输出做下处理(毕竟现在是detection嘛,得带上bbox一起了)。这么做,我在实际中就发现,很难学出好的网络,原因我想大概是分类任务上的权重已经进入了一个局部极小值,这个值在detection的优化空间又处于一个很差的位置,怎么finetune也难。但是呢,我们不用预训练权重,直接随机初始化,然后去学习,那就没问题了。所以,准确来说,分类网络本身可以做detection(要把输出层参数稍稍修改下~),但imagenet上的预训练权重做不好detection,必须添加一些额外的层,而这些层,我认为,就是得到bbox即定位的关键。
4.诚如你所说,分类网络本身也是有“定位”能力的,对于一张图像,它会在要分类的那个物体所处的区域有大的响应,别的地方相对要小,但是问题就在于,分类网络是全局感受野,它这种响应不会有某种平移恒变性,比如一只猫在一张图的各个位置都出现了,分类网络做不到在这些位置都有响应,也就很难泛化到我们想要的定位了,也就是您说的“精确定位”,即bbox的参数。这个gap的原因还是分类任务和detection任务二者之间的区别带来的,没办法,无法抹除这个gap,不然这俩就成一个任务了~因此呢,为了能够实现满足detection任务的精确定位,就得添加几层卷积了。
Q:Training from Scratch 到目前2021.6为止,CNN的目标检测依然是大数据集从头练,小数据集预训练。最新的一篇浙大关于预训练的论文,刚刚阅读完,在COCO上表现可以,VOC差了一大截。
A:现在(2021年)来看,在COCO上从头训练已经不是什么新鲜事了,因为COCO数据集本身规模足够大,往往train from scratch会获得更好的性能,像v5已经都是这么做了。VOC就是差在了数据量上,不过也无所谓,毕竟VOC基本上也没啥用了。对于新手来说,或者自身没有充足计算设备的研究者来说,预训练仍旧是个廉价而有效的方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号