


目标检测-Selective Search
前几天tensorflow开源了诸多目标检测模型,包括Faster RCNN、SSD等,恰巧自己的论文用的也是目标检测网络,是时间把以前刷过的检测网络祭出来了。自己看过的主要包括基于region proposal的RCNN系列:RCNN、Fast RCNN、Faster RCNN,基于区域划分的YOLO、SSD,基于强化学习的AttentionNet等,还有最新的Mask RCNN。我们将用一周时间先详细介绍每个模型然后通过Tensorflow跑一遍模型。说到基于region proposal的目标检测方法不得不提到RCNN所使用的Selective Search方法,就让我们从这篇文章开始入手好了。
文章地址:http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
摘要
为了了解目标检测区域建议的复杂性,我们先看一组图片:
 由于我们事先不知道需要检测哪个类别,因此第一张图的桌子、瓶子、餐具都是一个个候选目标,而餐具包含在桌子这个目标内,勺子又包含在碗内。这张图展示了目标检测的层级关系以及尺度关系,那我们如何去获得这些可能目标的位置呢。常规方法是通过穷举法,就是在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置。而这样做的缺点也显而易见,就是计算量实在是太大了,而且由于不可能每个尺度都兼顾到,因此得到的目标位置也不可能那么准。那么我们能不能通过视觉特征去减少这种分类的可能性并提高精确度呢。这就是本文想做的事情。
由于我们事先不知道需要检测哪个类别,因此第一张图的桌子、瓶子、餐具都是一个个候选目标,而餐具包含在桌子这个目标内,勺子又包含在碗内。这张图展示了目标检测的层级关系以及尺度关系,那我们如何去获得这些可能目标的位置呢。常规方法是通过穷举法,就是在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置。而这样做的缺点也显而易见,就是计算量实在是太大了,而且由于不可能每个尺度都兼顾到,因此得到的目标位置也不可能那么准。那么我们能不能通过视觉特征去减少这种分类的可能性并提高精确度呢。这就是本文想做的事情。
可用的特征有很多,到底什么特征是有用的呢?我们看第二副图片的两只猫咪,他们的纹理是一样的,因此纹理特征肯定不行了。而如果通过颜色则能很好区分。但是第三幅图变色龙可就不行了,这时候边缘特征、纹理特征又显得比较有用。而在最后一幅图中,我们很容易把车和轮胎看作是一个整体,但是其实这两者的特征差距真的很明显啊,无论是颜色还是纹理或是边缘都差的太远了。而这这是几种情况,自然图像辣么多,我们通过什么特征去区分?应该区分到什么尺度?
selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个,不然总是产生那么多你也用不完不是吗?好了这就是整篇文章的思路了,那我们一点点去看。
产生多尺度的区域建议
 首先通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块。然后我们使用贪心策略,计算每两个相邻的区域的相似度,然后每次合并最相似的两块,直到最终只剩下一块完整的图片。然后这其中每次产生的图像块包括合并的图像块我们都保存下来,这样就得到图像的分层表示了呢。那我们如何计算两个图像块的相似度呢?
首先通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块。然后我们使用贪心策略,计算每两个相邻的区域的相似度,然后每次合并最相似的两块,直到最终只剩下一块完整的图片。然后这其中每次产生的图像块包括合并的图像块我们都保存下来,这样就得到图像的分层表示了呢。那我们如何计算两个图像块的相似度呢?
保持多样性的策略
为了尽最大可能去分割所有情景的图片我们得保持特征的多样性啊,该文章主要通过两种方式保持特征多样性,一方面是通过色彩空间变换,将原始色彩空间转换到多达八中的色彩空间。然后通过多样性的距离计算方式,综合颜色、纹理等所有的特征。
- 颜色空间变换
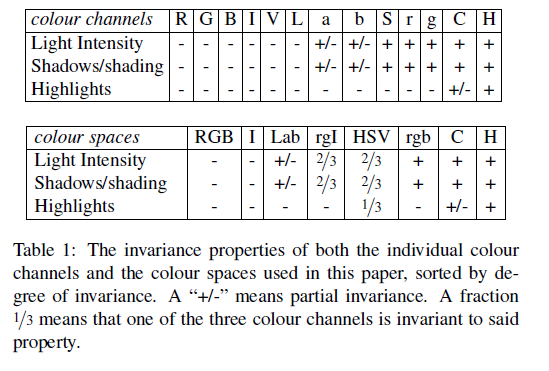
这么多的颜色空间,反正我认识的不认识的都在里面了。
- 距离计算方式
距离计算方式需要满足两个条件,其一速度得快啊,因为毕竟我们这么多的区域建议还有这么多的多样性。其二是合并后的特征要好计算,因为我们通过贪心算法合并区域,如果每次都需要重新计算距离,这个计算量就大太多了。
- 颜色距离
我们费劲心思搞了这么多的色彩空间,首先当然就是应该计算颜色的距离了啊。
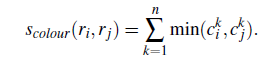 距离的计算方式很简单,就是对各个通道计算颜色直方图,然后取各个对应bins的直方图最小值。这样做的话两个区域合并后的直方图也很好计算,直接通过直方图大小加权区域大小然后除以总区域大小就好了。
距离的计算方式很简单,就是对各个通道计算颜色直方图,然后取各个对应bins的直方图最小值。这样做的话两个区域合并后的直方图也很好计算,直接通过直方图大小加权区域大小然后除以总区域大小就好了。
2.纹理距离
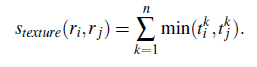 纹理距离计算方式和颜色距离几乎一样,我们计算每个区域的快速sift特征,其中方向个数为8,3个通道,每个通道bins为10,对于每幅图像得到240维的纹理直方图,然后通过上式计算距离。
纹理距离计算方式和颜色距离几乎一样,我们计算每个区域的快速sift特征,其中方向个数为8,3个通道,每个通道bins为10,对于每幅图像得到240维的纹理直方图,然后通过上式计算距离。
3.优先合并小的区域
如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
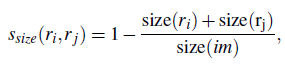 4.区域的合适度度距离
4.区域的合适度度距离
不仅要考虑每个区域特征的吻合程度,区域的吻合度也是重要的,吻合度的意思是合并后的区域要尽量规范,不能合并后出现断崖的区域,这样明显不符合常识,体现出来就是区域的外接矩形的重合面积要大。因此区域的合适度距离定义为:
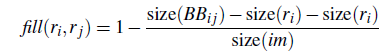 5.综合各种距离
5.综合各种距离
现在各种距离都计算出来,我们要做的就是整合这些距离,通过多种策略去得到区域建议,最简单的方法当然是加权咯:
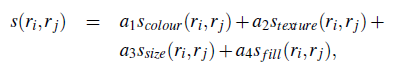 6.参数初始化多样性
6.参数初始化多样性
我们基于基于图的图像分割得到初始区域,而这个初始区域对于最终的影响是很大的,因此我们通过多种参数初始化图像分割,也算是扩充了多样性。
给区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选区域建议个数啦。
这篇文章做法是,给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,排序不好搞啊。文章做法是给他们乘以一个随机数,毕竟3分看运气嘛,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
基于Selective Search的目标识别
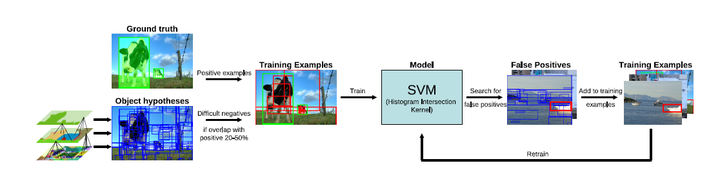 这就是典型的一个应用了,我们得到了区域的很多建议,提取区域的空间金字塔的多样特征,组合成一个特征向量,然后训练SVM就可以分类出哪个区域是真正我们想要的目标啦。当然也可以用以目标检测,我们接下来要说的RCNN就是这样干的。不过比相比这篇文章的sift特征啊啥的要高级一些,毕竟CNN的特征表达能力还是很强势的。
这就是典型的一个应用了,我们得到了区域的很多建议,提取区域的空间金字塔的多样特征,组合成一个特征向量,然后训练SVM就可以分类出哪个区域是真正我们想要的目标啦。当然也可以用以目标检测,我们接下来要说的RCNN就是这样干的。不过比相比这篇文章的sift特征啊啥的要高级一些,毕竟CNN的特征表达能力还是很强势的。
通过前面的区域合并,可以得到一些列物体的位置假设L。接下来的任务就是如何从中找出物体的真正位置并确定物体的类别。 常用的物体识别特征有HOG(Histograms of oriented gradients)和 bag-of-words 两种特征。在穷举搜索(Exhaustive Search)方法中,寻找合适的位置假设需要花费大量的时间,能选择用于物体识别的特征不能太复杂,只能使用一些耗时少的特征。由于选择搜索(Selective Search)在得到物体的位置假设这一步效率较高,其可以采用诸如SIFT等运算量大,表示能力强的特征。在分类过程中,系统采用的是SVM。

