
python-函数
打算今天花三个小时学习一下python ,要不然强化学习的很多内容看不懂
一、参数
1.形式参数和实际参数
形式参数:定义函数的时候在括号中 的参数,在函数内部会使用这个参数进行代码的
编写;
实际参数:函数调用时传进来的参数,函数返回的结果根据这个实际参数来代替形式参数
1 2 3 4 5 6 7 | >>> A = 30>>> def get_salary(days):... salary = days * 300... print(salary)...>>> get_salary(A)9000 |
days:形式参数 A是实际参数
2.位置参数
创建函数的时候可以在括号中定义多个形式参数,我们在调用的时候,参数的数量和位置需要和创建的时候保持一致;
如果传入参数的位置不一样的时候,会出现两种错误,一种是直接报错,因为在传参的时候根据参数的性质而定义不同的类型,如果传入的参数的数据类型是对的,但是位置错的,就会出现错误的输出结果。
3.关键字参数
为了提高程序的可读性,在函数调用的时候还可以使用关键字参数调用。
1 2 3 4 5 6 | >>> def volume(length,width,height):... volume = length * width * height... print('体积为:',volume)...>>> volume(length=20,width=30,height=3)体积为: 1800 |
关键字参数的位置不同不影响使用结果
4.参数默认值
在定义一个参数的时候,可以给函数的参数定义一个初始值,在调用参数的时候如果没有给出实际参数,函数就会默认使用初始值
1 2 3 4 5 6 7 | >>> def volume(length=100,width=100,height=10):... volume = length * width * height... print(volume)...>>> volume()#不给出实际参数的时候会使用默认参数100000>>> volume(10,10,10)#给出实际参数会传递实际参数给出输出结果1000 |
5,函数中的可变参数
可变参数就在在传递的时候参数的个数是可变的
如果在参数前面加*,这种方式的可变参数在传递的时候以元组的方式传递
如果在参数面前加**,这种方式的可变参数在传递的时候是字典
一*元组二*字典
1 2 3 4 5 6 7 8 | >>> def add_number(*number):... add_num = 0... for i in number:... add_num += i... print(add_num)...>>> add_number(1,2,3,4,5)15 |
所以在使用可变参数的时候,可以用遍历或者索引值的方式进行使用
参数在函数中非常重要!!!!!!!!!!!!!
二、返回值
函数在被调用的时候,函数中的内容会依次进行执行,但是有时候需要从这个执行后的函数中获取一些变量,因此在使用函数的时候增添一个返回值来获取函数中的一些数据。
1.语法结构
Python中关于返回值需要使用return语句,它的语法结构:
1 | return data |
1 2 3 4 5 6 7 | def get_sum(a,b): sum = a + b print('调用了这个函数') return sum print('完成返回值的传递')s = get_sum(1,2)print(s) |
输出结果:
1 2 | 调用了这个函数3 |
语句s=get_sum(1,2)中,显示调用get_sum的函数,然后在函数顺序往下执行时,到了return语句之后,return会将sum的值赋给s,幅值之后,函数里return之后的句子不再执行。
2.多值返回
在返回多个值时,多个值是被存储在元组中的
1 2 3 4 5 6 7 8 | def get_data(): a = 1 b = 2 c = 3 d = 4 return a,b,c,dprint('返回值的类型:',type(get_data()))print('返回值:',get_data()) |
1 2 | 返回值的类型: <class 'tuple'>返回值: (1, 2, 3, 4) |
可以对上面的数据直接进行使用:
1 2 | 返回值的类型: <class 'tuple'>返回值: (1, 2, 3, 4) |
1 | 1 2 3 4 |
对元组可以通过循环的方式打印出返回值:
1 2 | for i in get_data(): print('这是返回的第%d个数据'%i) |
返回值在函数中非常重要!!!
三、变量的作用域
变量的作用域指的是一个变量能够有效的区域,因为我们在使用函数的时候,有的变量是在主程序中定义的,有的是在调用的函数中定义的,当我们的主程序使用函数中定义的变量时,就会出现异常。
1.局部变量
作用在局部区域的变量,如果是在函数中定义的变量,那么就只在函数中起作用,如果在函数外部使用函数内部的变量,就会出现异常。
1 2 3 4 5 | def test(): data = '局部变量' print('在函数内部输出data为:',data)test()print('在主程序中输出data:',data) |
1 2 3 4 5 | 在函数内部输出data为: 局部变量Traceback (most recent call last): File "C:/Users/轻烟/PycharmProjects/untitled/venv/Include/ts.py", line 6, in <module> print('在主程序中输出data:',data)NameError: name 'data' is not defined |
由于变量data是在函数内部定义的,我们在主程序中使用变量data则会出现访问的变量不存在的问题。
2.全局变量
1) 在主程序中定义全局变量
我们在主程序中定义的变量的作用域是全局的,我们在定义的函数中也是可以直接使用这些变量:
1 2 3 4 5 | data = '全局变量data'def test(): print('这是作用在函数中的全局变量:',data)test()print('这是作用在函数外的全局变量:',data) |
输出结果:
1 2 | 这是作用在函数中的全局变量: 全局变量data这是作用在函数外的全局变量: 全局变量data |
在主程序中定义的变量可以在函数内部直接进行使用
2) 使用global关键字
我们在函数内定义的变量也可以编程全局变量,这时候我们就要使用到global关键字。
1 2 3 4 5 6 7 8 | data = '这里是全局变量data'print(data)def test(): global data data = '这里是局部变量data' print(data)test()print('再检查一下全局变量data:',data) |
1 2 3 | 这里是全局变量data这里是局部变量data再检查一下全局变量data: 这里是局部变量data |
通过global关键字,在局部中声明告诉这个函数global是一个全局变量,那么修改了之后,全局中的变量都做了修改,global关键字就是可以使一个变量变成全局变量。
所以说从上面这个例子可以看出来,当函数中的变量名和全局中一样时,用global声明局部变量为全局变量,该局部变量会替代全局变量。
四、匿名函数
匿名函数对于数据筛选非常重要,它能够很快的帮助我们来解决数据复杂繁琐的问题,同时它可以优化我们的代码,使得代码的整体更为简洁。
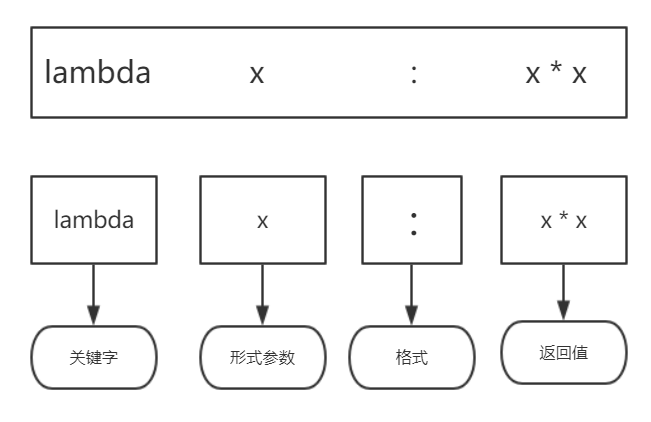
1.匿名函数的定义
我们通过一个例子来介绍一下lambda函数的简单使用,变量m为我们输入的值,我们需要采用匿名函数来返回m的平方和,也就是输入2要返回值为4。
1 2 3 | m = int(input('请输入一个数字:'))#m为输入的值a = lambda x : x * x #使用变量a来构成一个表达式print('返回值为:',a(m)) |
1 2 | 请输入一个数字:6返回值为: 36 |
1 2 3 | m = int(input('请输入一个数字:'))#m为输入的值a = lambda x : x + 10 * 10 + x * xprint('返回值为:',a(m)) |
1 2 | 请输入一个数字:5返回值为: 130 |
通过上面两个例子我们可以了解到lambda表达式等同于把函数压缩为一行代码,然后通过变量的定义直接来调用这个函数,这种方式可以简化我们的代码。
2.序列调用匿名方法
我们在序列中同样可以使用匿名函数,使用匿名函数可以帮助我们进行很快的数据筛选,看下面的例子:
已知一个列表为[1,4,6,9,12,23,25,28,36,38,41,56,63,77,88,99],我们需要返回它里面的偶数并存放在列表当中。
我们可以使用filter函数来进行过滤。
代码如下:
1 2 | my_list = [1,4,6,9,12,23,25,28,36,38,41,56,63,77,88,99]print(list(filter(lambda x : x % 2 == 0,my_list))) |
输出结果:
1 | [4, 6, 12, 28, 36, 38, 56, 88] |
filter()函数中的对象前者为我们的筛选方式,后者为我们要筛选的对象,然后我们把这些数据使用list()函数存放在了列表当中,最后打印出来,这种方式可以帮助我们很快的进行数据的整合。
我们在进行排序的时候也可以通过匿名函数来制定规则。
首先我们已知一组列表为[('元组甲',15,33),('元组乙',25,26),('元组丙',7,7)],列表中每个元素中的元组中包含每个元组的名字和最小值以及最大值,我们要根据每个人的元组最大值和最小值的差值来将列表进行排序,看下面代码:
1 2 3 | my_list = [('元组甲',15,33),('元组乙',25,26),('元组丙',7,7)]my_list.sort(key=lambda x : x [2] - x[1])#使用key关键字来引入排序方式,排序方式根据第三个元素减去第二个元素的差值,对应索引为2和1print(my_list) |
输出结果:
1 | [('元组丙', 7, 7), ('元组乙', 25, 26), ('元组甲', 15, 33)] |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?