Spaceship Titanic | kaggle 泰坦尼克太空飞船kaggle机器学习比赛
任务说明
概述
欢迎来到2912年,在这里需要你的数据科学技能来解决一个宇宙之谜。我们收到了来自四光年外的传输消息,情况看起来并不好。
泰坦尼克号宇宙飞船是一个月前发射的星际客轮。船上有近13,000名乘客,这艘船开始了处女航,将移民从我们的太阳系运送到三颗围绕附近恒星运行的新的可居住的系外行星。
泰坦尼克号宇宙飞船在绕过半人马座阿尔法星前往第一个目的地——55 Cancri E的途中,闯进了隐藏在尘埃云中时空异常区域。可悲的是,它遇到了与1000年前同名游轮相同的命运。虽然飞船完好无损,但几乎一半的乘客被运送到另一个维度!

任务
为了帮助救援人员找回失踪的乘客,您面临的挑战是使用从宇宙飞船损坏的计算机系统中恢复的记录来预测哪些乘客被传送到时空异常区域。
拯救失踪人员改变历史!
数据集说明
数据来源
本文所使用的数据集来自于kaggle网站。
数据集链接 https://www.kaggle.com/competitions/spaceship-titanic/data
数据集简介
本文所使用的数据集中有 sample_submission.csv test.csv train.csv 这三个文件。

train.csvtrain.csv
本文件作为训练集文件,里面包含了从泰坦尼克太空飞船的损坏计算机系统中所恢复的三分之二的数据,大约8700位乘客的个人记录。
PassengerId——乘客编号。每个编号的形式都表示乘客与是否是组团旅行有关,比如家庭出游,集体出差等,因此编号中有部分是表示他们在团队中的号码。但有部分乘客是独自旅行。
HomePlanet——乘客离开的星球,通常是他们的永久居住星球。
CryoSleep——指示乘客是否选择在航行期间进入冷冻睡眠状态。处于冷冻睡眠状态的乘客所在的冷冻睡眠舱位于对应的客舱内。
Cabin——乘客所住的舱号。
Destination——乘客将要前往的星球。
Age——乘客的年龄。
VIP——旅客在航程中是否支付了特殊VIP服务费用。
RoomService,FoodCourt,ShoppingMall,Spa,VRDeck——乘客在泰坦尼克号宇宙飞船的许多豪华设施中所消费的金额。
Name——乘客的名字和姓氏。
Transported——乘客是否被运送到另一个维度。这是我们所需预测的列。
test.csv
本文件作为测试集文件,里面包含了剩下三分之一的数据,大约4300位乘客的个人纪录。
sample_submission.csv
本文件作为所需提交的文件范例。
任务实施
查看数据集
首先使用 train.info() 函数来查看数据集结构。

从上图中我们看到有许多列有存在缺失现象,因此我们下一步需要查看每一列具体的缺失数量。
total = train.isnull().sum().sort_values(ascending=False)
percent = (train.isnull().sum()/train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['缺失数', '缺失率'])
missing_data
运行以上代码得出:

从上图中我们可以看到训练集中每一列的缺失数和缺失率,图中显示只有 PassengerId 和 Transported 是没有缺失的。因此我们下一步需要进行数据清洗。
数据清洗
我们首先从Name列的缺失值入手。我将Unknown填入到缺失值中。
train.Name = train.Name.fillna('Unknown')
print(train.isnull().sum())
运行以上代码得出:

从上图我们可以看到 Name 列从原来缺失200个数据经过填充之后现在已经没有缺失值了。下一步我们开始处理 CryoSleep 列和 VIP 列。
import pandas_profiling as pp
report_train=pp.ProfileReport(train)
report_train
运行以上代码得出:


从上面两张图可以看到 CryoSleep 列和 VIP 列选择False是最多的,因此我将False填入到 CryoSleep 列和 VIP 列缺失值中。
train['CryoSleep']=train['CryoSleep'].fillna(False)
train['VIP']=train['VIP'].fillna(False)
print(train.isnull().sum())

从上图我们可以看到CryoSleep 列和 VIP 列都为0。接下来开始处理 Age 列的缺失值。此列表示年龄,因此我将平均数填入到缺失值中。
train['Age']=train['Age'].fillna(train['Age'].mean())
print(train.isnull().sum())

从上图我们可以看到填充成功。接下来开始处理 RoomService , FoodCourt , ShoppingMall , Spa , VRDeck列的缺失值。在上文中有提到,有些乘客选择了在冷冻睡眠舱中度过旅行时间,因此乘客在冷冻睡眠状态下是无法产生这些费用的,所以将在冷冻睡眠状态下的乘客并且RoomService , FoodCourt , ShoppingMall , Spa , VRDeck列中有缺失值的填入0。
train['RoomService']=train['RoomService'].fillna(train['RoomService'].mean())
train['FoodCourt']=train['FoodCourt'].fillna(train['FoodCourt'].mean())
train['ShoppingMall']=train['ShoppingMall'].fillna(train['ShoppingMall'].mean())
train['Spa']=train['Spa'].fillna(train['Spa'].mean())
train['VRDeck']=train['VRDeck'].fillna(train['VRDeck'].mean())
print(train.isnull().sum())
运行以上代码得出:

从上图我们可以看到还有许多缺失的值,这是由于这些乘客并没有处于冷冻休眠状态,因此我将各列的平均数填入到对应的缺失值中。
train['RoomService']=train['RoomService'].fillna(train['RoomService'].mean())
train['FoodCourt']=train['FoodCourt'].fillna(train['FoodCourt'].mean())
train['ShoppingMall']=train['ShoppingMall'].fillna(train['ShoppingMall'].mean())
train['Spa']=train['Spa'].fillna(train['Spa'].mean())
train['VRDeck']=train['VRDeck'].fillna(train['VRDeck'].mean())
print(train.isnull().sum())
运行以上代码得出:

从上图我们可以看到填充成功。接下来开始处理 HomePlanet 列和 Destination 列。
analys = train.loc[:,['HomePlanet','Destination']]
analys['numeric'] =1
analys.groupby(['Destination','HomePlanet']).count()
运行以上代码得出:

从上图我们可以看到前往TRAPPIST-1e星球的乘客最多,来自于Earth的乘客最多,因此我将 TRAPPIST-1e 和 Earth 填入到 HomePlanet 列和 Destination 列对应的缺失值中。
train['Destination']=train['Destination'].fillna('TRAPPIST-1e')
train['HomePlanet']=train['HomePlanet'].fillna('Earth')
print(train.isnull().sum())
运行以上代码得出:

从上图我们可以看到缺失值填入成功。由于 Cabin 列表示乘客所在船舱,并且任务说明中并没有提到 Cabin 列的编写规范,因此我没有想到合适的方式填充其缺失值。
数据分析
首先我们查看一下本艘飞船所有乘客的年龄分布情况。
plt.figure(figsize=(10, 5))
sns.histplot(data=train, x='Age', binwidth=1, kde=True)
plt.title('Age distribution')
plt.xlabel('Age (years)');
运行以上代码得出:

从上图我们可以看到本艘飞船的乘客年龄在20岁至30岁之间数量最多,其中29岁的乘客最多,另外1岁的乘客也比大多数年龄段的乘客数量多。结合任务说明,我推测本艘飞船有许多乘客是带着自己出生不久的宝宝出游的,因此在2912年的人们可能存在着宝宝出生后年轻夫妻带着宝宝走亲访友的习惯。
接下来分析 Transported 列与其余各个列的关系。
fig, ax = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(18, 12)
fig.subplots_adjust(wspace=0.3, hspace=0.3)
temp = train.fillna(-1)
sns.barplot(x = "HomePlanet", y= "Transported", data=temp, ax = ax[0][0])
sns.barplot(x = "CryoSleep", y= "Transported", data=temp, ax = ax[0][1])
sns.barplot(x = "VIP", y= "Transported", data=temp, ax = ax[1][0])
sns.barplot(x = "Destination", y= "Transported", data=temp, ax = ax[1][1])
运行以上代码得出:
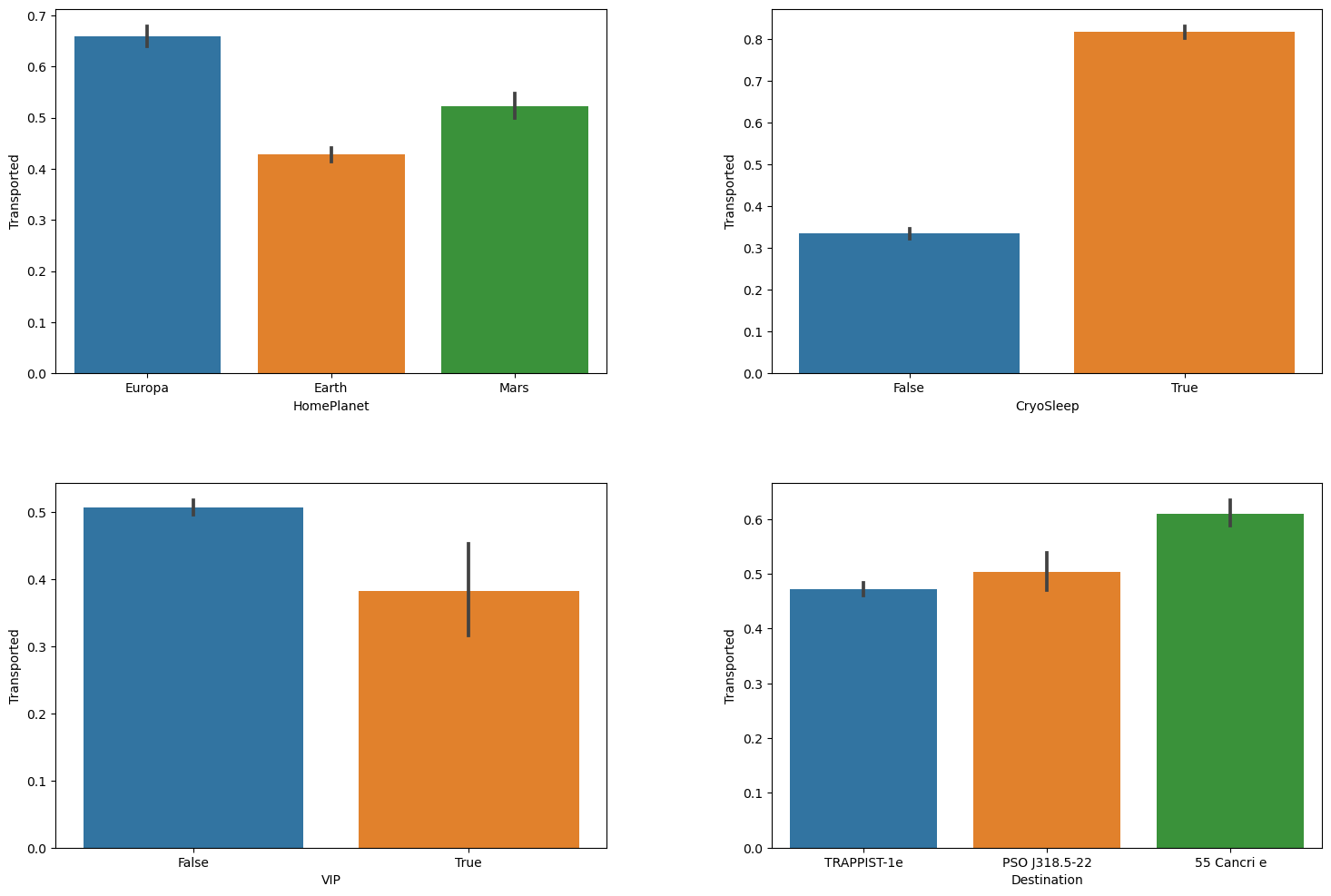
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
corrmat = train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True,annot=True)
plt.show()
运行以上代码得出:
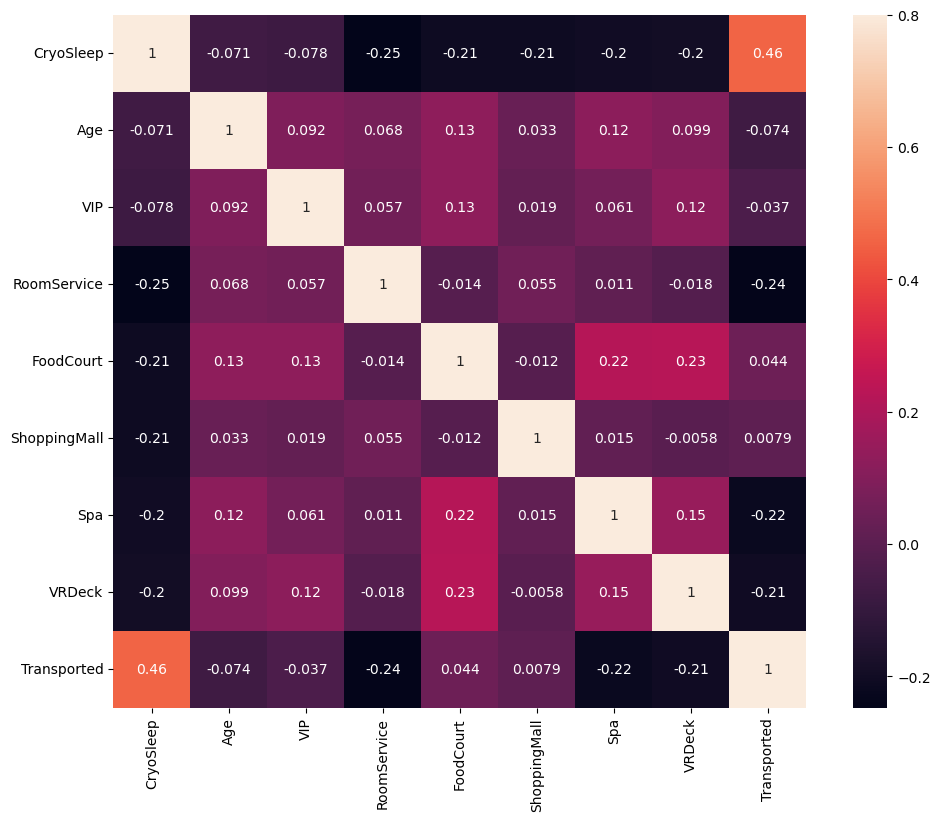
由上面两张图我们可以值观的看到 CryoSleep 列与 Transported 列关联度最高,因此我推测乘客是否进入冷冻休眠状态与是否被传送到另一个维度之间存在关联。接下来查看一下与 Transported 列关联度最高的五个列。
corrmat = train.corr()
k = 6
high_corr_values = corrmat.nlargest(k, 'Transported')['Transported'].index
high_corr_values = high_corr_values.drop('Transported')
high_corr_values
运行以上代码得出:

从上图我们可以看到,CryoSleep , FoodCourt ,ShoppingMall ,VIP , Age 列是与 Transported 列关联度最高的五个列。
训练模型
完成以上步骤后现在开始训练模型的搭建。首先CryoSleep , FoodCourt ,ShoppingMall ,VIP , Age 列是与 Transported 列关联度最高的五个列定义为high_corr_values,以此为训练模型的输入数据定义为X,Transported 列作为训练模型的标签定义为y。我将train.csv文件中80%数据用于训练,剩余20%数据用于测试模型。我把X_train定义为训练用自变量,此中有train.csv文件中80%数据。y_train定义为训练用因变量,此中包含了针对自变量的类别标签。X_test定义为测试用自变量,此中有train.csv文件中20%数据。y_test定义为测试用因变量,此中包含了针对自变量的类别标签。
X = train[high_corr_values]
y = train['Transported']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
接下来我将使用8个不同的训练模型来预测结果。
xgboost模型
from xgboost import XGBClassifier
xgbc = XGBClassifier()
xgbc.fit(X_train, y_train)
xgbc_pred = xgbc.predict(X_test)
print("xgboost accuracy: {}".format(metrics.accuracy_score(y_test,xgbc_pred)))
运行以上代码得出:

xgboost模型精度为0.757
Random forest模型
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=1000)
rfc.fit(X_train,y_train)
rfc_pred = rfc.predict(X_test)
print("Random forest accuracy: {}".format(metrics.accuracy_score(y_test,rfc_pred)))
运行以上代码得出:

Random forest模型精度为0.736
AdaBoost模型
from sklearn.ensemble import AdaBoostClassifier
abc = AdaBoostClassifier()
abc.fit(X_train,y_train)
abc_pred = abc.predict(X_test)
print("Adaboost accuracy: {}".format(metrics.accuracy_score(y_test,abc_pred)))
运行以上代码得出:

Adaboost accuracy模型精度为0.756
Bagging模型
from sklearn.ensemble import BaggingClassifier
bag = BaggingClassifier()
bag.fit(X_train,y_train)
bag_pred = bag.predict(X_test)
print("Bagging accuracy: {}".format(metrics.accuracy_score(y_test,bag_pred)))
运行以上代码得出:

Bagging模型精度为0.725
Hist gradient boosting模型
from sklearn.ensemble import HistGradientBoostingClassifier
hgbc = HistGradientBoostingClassifier()
hgbc.fit(X_train,y_train)
hgbc_pred = hgbc.predict(X_test)
print("Hist gradient boosting accuracy: {}".format(metrics.accuracy_score(y_test,hgbc_pred)))
运行以上代码得出:

Hist gradient boosting模型精度为0.769
Gaussian NB模型
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train,y_train)
gnb_pred = gnb.predict(X_test)
print("Gaussian NB accuracy: {}".format(metrics.accuracy_score(y_test,gnb_pred)))
运行以上代码得出:

Gaussian NB模型精度为0.758
Multinomial NB模型
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
mnb_pred = mnb.predict(X_test)
print("Multinomial NB accuracy: {}".format(metrics.accuracy_score(y_test,mnb_pred)))
运行以上代码得出:

Multinomial NB模型精度为0.48
KNeighbors Classifier模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
knn_pred = knn.predict(X_test)
print("KNeighbors Classifier accuracy: {}".format(metrics.accuracy_score(y_test,knn_pred)))
运行以上代码得出:

KNeighbors Classifier模型精度为0.696
经过以上8个模型训练后得知 Hist gradient boosting 模型精度最高为0.769,因此将使用 Hist gradient boosting 模型来输出最后的预测文件。
输出预测文件
经过以上8个模型训练后我将选用精度最高的 Hist gradient boosting 模型来输出预测文件。
test_ids = test["PassengerId"]
from sklearn.preprocessing import LabelEncoder
categorical_values_test = test.select_dtypes(include=['object']).columns
for i in categorical_values_test:
lbl = LabelEncoder()
lbl.fit(list(test[i].values))
test[i] = lbl.transform(list(test[i].values))
real_predictions = hgbc.predict(test[high_corr_values])
test["PassengerId"] = test_ids
real_predictions = list(map(bool,real_predictions))
output = pd.DataFrame({'PassengerId': test.PassengerId, 'Transported': real_predictions})
output.to_csv('submission.csv', index=False)
运行以上代码获得一个submission.csv文件。接下来我将文件提交到kaggle网站上进行评分。


最终我的比赛得分是0.743,在比赛中排名第2403名。
任务总结
在参加此次kaggle比赛过程中,我对机器学习的步骤有了更加深刻的理解和掌握,对于主流的机器学习模型也拥有了大致的了解,同时也体验了kaggle比赛流程,这使我在数据清洗方面逻辑更加清晰,机器学习原理方面了解更加深刻,文案编写能力得到了锻炼和加强,勾起了我对机器学习浓厚的兴趣。
在本次任务过程中我学习到了很多,同时发现了许多自己不足之处,最主要的方面就是对训练模型了解太少,导致最后比赛成绩并不理想。其次在数据清洗方面,在处理 Cabin 列时,由于我经验不足,并不能想到合适的清洗方案,这也是导致比赛成绩不理想的重要原因之一。因此本次比赛给我敲了警钟,在今后的学习工作生活中,应该更加努力钻研专业知识,努力学习。
完整代码
点击查看代码
#导入所需的库
import pandas as pd
import numpy as np
#导入数据集
train = pd.read_csv(r'C:\Users\19636\Spaceship Titanic Data\train.csv')
test = pd.read_csv(r'C:\Users\19636\Spaceship Titanic Data\test.csv')
#查看训练集
train
#使用describe函数查看训练集
train.describe()
#使用info函数查看训练集基本信息
train.info()
#导入所需的库
import pandas_profiling as pp
#使用ProfileReport查看训练集详细信息
report_train=pp.ProfileReport(train)
report_train
#查看训练集缺失总数以及缺失率
total = train.isnull().sum().sort_values(ascending=False)
percent = (train.isnull().sum()/train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['缺失数', '缺失率'])
missing_data
#数据清洗
#将训练集中缺失的Name填充为Unknown
train.Name = train.Name.fillna('Unknown')
print(train.isnull().sum())
#将训练集中缺失的CryoSlee填充为False
train['CryoSleep']=train['CryoSleep'].fillna(False)
print(train.isnull().sum())
#将训练集中缺失的VIP填充为False
train['VIP']=train['VIP'].fillna(False)
print(train.isnull().sum())
#将训练集中缺失的Age填充为Age平均数
train['Age']=train['Age'].fillna(train['Age'].mean())
print(train.isnull().sum())
#如果CryoSleep状态为True,那么将RoomService,FoodCourt,ShoppingMall,Spa,VRDeck填写为0
Expenses_columns = ['RoomService','FoodCourt','ShoppingMall','Spa','VRDeck']
train.loc[:,Expenses_columns]=train.apply(lambda x: 0 if x.CryoSleep == True else x,axis =1)
print(train.isnull().sum())
#将训练集中缺失的RoomService填充为RoomService平均数
train['RoomService']=train['RoomService'].fillna(train['RoomService'].mean())
#将训练集中缺失的FoodCourt填充为FoodCourt平均数
train['FoodCourt']=train['FoodCourt'].fillna(train['FoodCourt'].mean())
#将训练集中缺失的ShoppingMall填充为ShoppingMall平均数
train['ShoppingMall']=train['ShoppingMall'].fillna(train['ShoppingMall'].mean())
#将训练集中缺失的Spa填充为Spa平均数
train['Spa']=train['Spa'].fillna(train['Spa'].mean())
#将训练集中缺失的VRDeck填充为VRDeck平均数
train['VRDeck']=train['VRDeck'].fillna(train['VRDeck'].mean())
print(train.isnull().sum())
#统计到达各个目的地的旅客的出发地的总数
analys = train.loc[:,['HomePlanet','Destination']]
analys['numeric'] =1
analys.groupby(['Destination','HomePlanet']).count()
#将训练集中缺失的Destination填充为TRAPPIST-1e
#将训练集中缺失的HomePlanet填充为Earth平均数
train['Destination']=train['Destination'].fillna('TRAPPIST-1e')
train['HomePlanet']=train['HomePlanet'].fillna('Earth')
print(train.isnull().sum())
#导入所需的库
import pandas_profiling as pp
#再次使用ProfileReport查看训练集详细信息
report_train=pp.ProfileReport(train)
report_train
#导入所需的库
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#画出热力图
corrmat = train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True,annot=True)
plt.show()
#画出HomePlanet与Transported的条形图
#画出CryoSleep与Transported的条形图
#画出VIP与Transported的条形图
#画出Destinationp与Transported的条形图
fig, ax = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(18, 12)
fig.subplots_adjust(wspace=0.3, hspace=0.3)
temp = train.fillna(-1)
sns.barplot(x = "HomePlanet", y= "Transported", data=temp, ax = ax[0][0])
sns.barplot(x = "CryoSleep", y= "Transported", data=temp, ax = ax[0][1])
sns.barplot(x = "VIP", y= "Transported", data=temp, ax = ax[1][0])
sns.barplot(x = "Destination", y= "Transported", data=temp, ax = ax[1][1])
#画出年龄分布图
plt.figure(figsize=(10, 5))
sns.histplot(data=train, x='Age', binwidth=1, kde=True)
plt.title('Age distribution')
plt.xlabel('Age (years)');
#建立训练模型
corrmat = train.corr()
k = 6
high_corr_values = corrmat.nlargest(k, 'Transported')['Transported'].index
high_corr_values = high_corr_values.drop('Transported')
#查看high_corr_values
high_corr_values
#导入所需的库
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
#定义所需的参数
X = train[high_corr_values]
y = train['Transported']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#使用XGBClassifier模型进行预测并输出精度
from xgboost import XGBClassifier
xgbc = XGBClassifier()
xgbc.fit(X_train, y_train)
xgbc_pred = xgbc.predict(X_test)
print("xgboost accuracy: {}".format(metrics.accuracy_score(y_test,xgbc_pred)))
#使用RandomForestClassifier模型进行预测并输出精度
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=1000)
rfc.fit(X_train,y_train)
rfc_pred = rfc.predict(X_test)
print("Random forest accuracy: {}".format(metrics.accuracy_score(y_test,rfc_pred)))
#使用AdaBoostClassifier模型进行预测并输出精度
from sklearn.ensemble import AdaBoostClassifier
abc = AdaBoostClassifier()
abc.fit(X_train,y_train)
abc_pred = abc.predict(X_test)
print("Adaboost accuracy: {}".format(metrics.accuracy_score(y_test,abc_pred)))
#使用BaggingClassifier模型进行预测并输出精度
from sklearn.ensemble import BaggingClassifier
bag = BaggingClassifier()
bag.fit(X_train,y_train)
bag_pred = bag.predict(X_test)
print("Bagging accuracy: {}".format(metrics.accuracy_score(y_test,bag_pred)))
#使用HistGradientBoostingClassifier模型进行预测并输出精度
from sklearn.ensemble import HistGradientBoostingClassifier
hgbc = HistGradientBoostingClassifier()
hgbc.fit(X_train,y_train)
hgbc_pred = hgbc.predict(X_test)
print("Hist gradient boosting accuracy: {}".format(metrics.accuracy_score(y_test,hgbc_pred)))
#使用GaussianNB模型进行预测并输出精度
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train,y_train)
gnb_pred = gnb.predict(X_test)
print("Gaussian NB accuracy: {}".format(metrics.accuracy_score(y_test,gnb_pred)))
#使用MultinomialNB模型进行预测并输出精度
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
mnb_pred = mnb.predict(X_test)
print("Multinomial NB accuracy: {}".format(metrics.accuracy_score(y_test,mnb_pred)))
#使用KNeighborsClassifier模型进行预测并输出精度
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
knn_pred = knn.predict(X_test)
print("KNeighbors Classifier accuracy: {}".format(metrics.accuracy_score(y_test,knn_pred)))
#查看测试集
test
#导出文件
test_ids = test["PassengerId"]
from sklearn.preprocessing import LabelEncoder
categorical_values_test = test.select_dtypes(include=['object']).columns
for i in categorical_values_test:
lbl = LabelEncoder()
lbl.fit(list(test[i].values))
test[i] = lbl.transform(list(test[i].values))
#由于HistGradientBoostingClassifier模型预测精度最高,因此使用HistGradientBoostingClassifier所预测的文件
real_predictions = hgbc.predict(test[high_corr_values])
print(len(test))
print(len(test.PassengerId))
test["PassengerId"] = test_ids
real_predictions = list(map(bool,real_predictions))
output = pd.DataFrame({'PassengerId': test.PassengerId, 'Transported': real_predictions})
output.to_csv('submission.csv', index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号