
Innodb 存储引擎表
索引组织表
Innodb 存储引擎表中,数据都是根据主键顺序存放,这种结构成为索引组织表,所以数据即索引,索引即数据。如果没有显式定义主键,MySQL将按如下方式选举主键:
-
判断表中是否有唯一非空索引,如果有 以第一个建立索引 的唯一非空索引列为主键,不是表字字段定义顺序。
# 如下的表,c 类最先定义唯一非空主键,所以列c是主键。 create table table_first ( a integer not null, b char(10) not null, c integer not null, UNIQUE KEY(c), UNIQUE KEY(b), UNIQUE KEY(a) ); -
如果无,Innodb 会自动创建一个6字节大小的主键。
-
_rowid 与表的主键列值一致,但是它只使用主键是单个列,且它对MySQL自动生成的主键无效。
B+树索引本身并不能找到某一个具体的行记录,而是找到其所在的页并加载到内存中,再根据页中的信息进行查找。
Innodb逻辑存储结构
Innodb 将所有数据都存放到一个逻辑表空间,表空间由:段、区、页组成。

表空间
表空间是Innodb存储引擎逻辑结构的最高层,表的所有数据都存放在表空间中,默认情况下,Innodb有一个默认表空间ibdata1,所有数据都存放在该共享表空间中。可以通过配置项innodb_file_per_table = ON ,所有表会创建一个自己独立的表空间;此时表的数据、索引、和插入缓冲Bitmap页都存放到自己独立的表空间中,除此之外其它数据如:回滚信息、插入缓冲索引页、系统事务信息、二次写缓冲(double write buffer) 等还是存放于共享表空间中。
段
表空间有各个段组成,段分为:数据段、索引段、回滚段等。数据段存放的是聚集索引B+树的叶子节点;索引段存放的是B+树的非叶节点;回滚段存放的是 undo信息。
区
段由区组成,每个区又是由连续的页组成的空间,每个区固定大小为:1M;一般为保证页的连续性,innodb 存储引擎一般每次会连续申请4~5个区;
页
页是innodb磁盘管理的最小单位,每个页默认16K,也就是说默认一个区有64个页;当让 innodb_page_size 配置项可以配置页的大小:4k、8k、16k,设置该大小后不可变,除非重新建表重新导入数据。

常见的页有:
-
数据页 B-tree Node
-
undo页 undo Log Page
-
系统页 System Page
-
事务数据页 Transaction system Page
-
插入缓冲位图页 Insert Buffer Bitmap
-
插入缓冲空闲页列表页 Insert Buffer Free List
-
未压缩的二进制大对象页 Uncompressed BLOB Page
-
压缩的二进制大对象页 compressed BLOB Page
行
Innodb存储引擎是面向列的,也就是数据是按行就行存储的,每个页最多存放:16Kb / 2 - 200 = 7992 行记录。
Innodb 行记录格式
-
前边提到数据以行的形式存储在页上,那么肯定有一定的格式以便于读取;Innodb内部是通过链表来串接各个行记录的。
-
由于Innodb 是B+树索引组织的,那么需要保证每个页最少存在两条行记录,否则B+树将分裂成链表,这没有任何意义。如果页不能存下两条记录,那么就会进行溢出以确保页上最少两条记录。
例如某个行记录数据合计9k,那么一个页16K,肯定无法保存两条 9k 的数据的,那么保存时就会进行溢出操作,
Innodb 提供如下的行记录格式:
Compact
它的设计目的是为了高效的存储数据(一个页中存放的行数越多,性能越好)。变长字段的长度不超过2字节,所以MySQL中,varchar最大长度限制为:65535。还有一个需要注意的是,这里的变长字段最大长度,指的是:表中所有变长字段长度的总和,如果按照如下方式定义一个表,就会报错,因为两个边长列的长度合计7W:
create table large_name (
a varchar(40000),
b varchar(30000)
);
Compact 格式下NULL值不占用任何空间。
Compact 行记录格式

Compact 记录头信息

看看字段:next_record 长度 16 位,也就是 2byte, 它表示的是下一个字段的位置,所以说长度总和不能超过 65536.
如下表,字段b的起始位置大概就是:65534
create table large_name (
a varchar(65533),
b varchar(2)
);
Redundant
它是MySQL5.0版本之前的行记录存储方式,支持该格式只是问了兼容旧版本行格式。
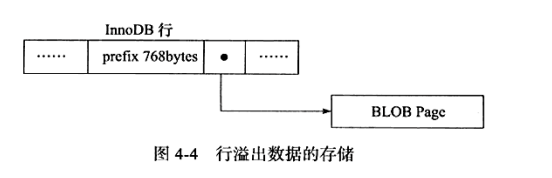
行溢出数据
Innodb 存储引擎可以将行记录的某些数据存储在该行记录所在的页之外,一般会把 BLOB、LOB 等这类大对象列类型的数据存放到页面之外。实际上,由于页的大小为:16K,那么是否溢出完全由数据的大小来决定,当内容足够少,blob 页可能不回溢出当前页,varchar类型当足够大的时候也可能发生溢出。
-
varchar(30000) 值的是3W个字节,而页大小为:16K 也就是 16384 字节,所以完全可能溢出。
-
对行溢出数据,页中行记录会保留其前768个字节的数据。
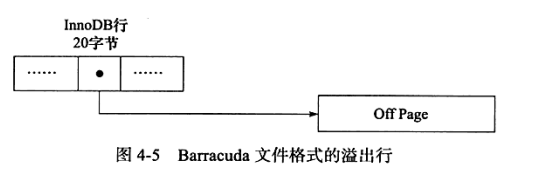
Compressed 和 Dynamic 行记录格式
这是Innodb 中较新的行记录格式,他们对BLOB 数据的存储采用了完全的行溢出方式,数据页中只存放20字节的 指针,实际数据都存放于Off Page 中。
char 的行结构存储
- varchar 指变长字符类型
- char指定长字符类型,计算实际不足,也会分配相应长度的空间
从 MySQL4.1 开始,char(N) 表示N个字符,而不是N个字节的字符,
但是在多字节字符集情况下,char 和 varchar保存方式一致,例如:char (10) 可以存放 10个英文字符,也可以存放 10 个汉字;此时,他们的长度就不一致了,前者共占用10字节,而保存10个汉字则需要20 字节。
当然,不论存放汉字或者英文字符,只要不足定义的10个字符,还是会进行填充。
Innodb 数据页结构

-
File Header 文件头,占用38字节,记录页的一些头信息。
-
Page Header 页头,由14个部分组成,占用56字节,记录数据页的状态信息
-
Infimum和Supremum Record 虚拟的行记录,用来限定记录的边界
Infimum 记录比页中任何主键值都要小的值,Supremum 记录页中比任何主键都要大的值;它们在页串创建时被创建,任何情况下都不会被删除。

-
User Record 用户记录,即行记录,它指实际存储的行记录内容
-
Free Space 页的空闲空间,当一条记录被删除后,该空间会被加入到空闲列表中,它是链表组织结构的
-
Page Directory 页目录,存放记录的相对地址(不是偏移量)
这些记录指针称为:Slots(槽)或者 Directory Slots (目录槽),需要注意的是,Innodb中它是一个稀目录,并不是每个行记录都拥有一个槽,也就是说可能一个槽中包含多个记录;由于它是一个稀目录,二叉查找的结果也只是一个粗略的结果。
B+树索引本身并不能找到某一个具体的行记录,而是找到其所在的页,然后将其加载到内存中,再通过Page Directory进行二叉查找,最后再结合 【行记录头】中的【next record】精确定位到实际的行记录。
行记录头参考上述对Compact 格式行记录的描述。
- File Trailer 文件结尾信息,检测页是否已经完整地写入磁盘,可以理解成它是用来支持做页的校验和的。
视图 View
MySQL中,视图是一个命名的虚表,他由一个SQL查询来定义,可以当作表使用。
分区表
当数据量较大是可以进行分表操作
- 水平拆分,将同一个表中不同行的记录进行拆分,即按行拆分。
- 垂直拆分,将同一个表中不同列的记录进行拆分,即对表按列进行拆分。
看完书,其实MySQL自身支持的分区表功能并不够强大,当数据量膨胀时,可以考虑 当当 共享给apache 的开源项目 shardingspwhere ,目前它已经时apache 的顶级开源项目之一。
本文来自我对 《MySQL技术内幕:InnoDB存储引擎》一书阅读过后的二次创作,文件颇多截图引用书中插图,此外本文主要用作个人学习后的思考感悟的记录,肯定不如原书讲得深入且全面,强烈建议购买原书深入了解更多的细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号