


布隆过滤器 php实现
1.抛砖引玉
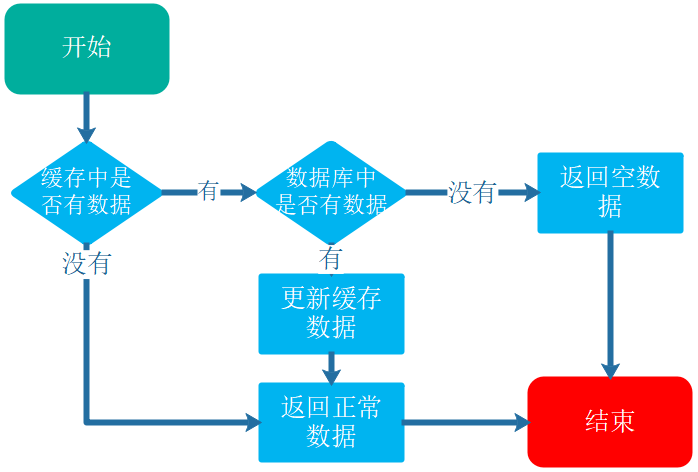
有些项目中,缓存可能是这样设计的:
前端用户查询数据时:
- 先去缓存或nosql(redis mongodb等)里面查。如果能找到,就直接把数据返回给用户。
- 如果缓存里面也没有(缓存没命中),才去数据库中查找。
上面这个设计的目的,是为了用缓存给mysql降低访问压力。
缓存命中率越高, 需要查询mysql的可能性就越小,mysql压力就越小。
那么现在问题来了, 如果攻击者,经常查询一些不会存在的数据, 比如查询商品id= -1,那么缓存里面不可能会有商品id=-1的数据,缓存没命中, 最终要到mysql里面查询, 加重了mysql的负担。 绕过缓存给你的mysql增加访问压力, 构成了缓存穿透, 严重的可能直接压爆数据库。
解决:
其实,我们可以在访问mysql之前,先访问一下布隆过滤器。布隆过滤器能够判断某个值的存在情况, 如果布隆过滤器说-1这个值不存在, 那么这个肯定就不存在,这时候, 我们就没必要访问mysql了。
这样就成功把这些对mysql的恶意攻击进行过滤。
2.布隆过滤器场景
- Google著名的分布式数据库Bigtable以及Hbase使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
- 检查垃圾邮件地址 假定我们存储一亿个电子邮件地址,我们先建立一个十六亿二进制(比特),即两亿字节的向量,然后将这十六亿个二进制全部设置为零。对于每一个电子邮件地址 X,我们用八个不同的随机数产生器(F1,F2,...,F8) 产生八个信息指纹(f1, f2, ..., f8)。再用一个随机数产生器 G 把这八个信息指纹映射到 1 到十六亿中的八个自然数 g1, g2, ...,g8。现在我们把这八个位置的二进制全部设置为一。当我们对这一亿个 email 地址都进行这样的处理后。一个针对这些 email 地址的布隆过滤器就建成了。
- Google chrome 浏览器使用bloom filter识别恶意链接(能够用较少的存储空间表示较大的数据集合,简单的想就是把每一个URL都可以映射成为一个bit)
- 文档存储检索系统也采用布隆过滤器来检测先前存储的数据
- 爬虫URL地址去重 A,B 两个文件,各存放 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4G,让你找出 A,B文件共同的 URL。如果是三个乃至 n 个文件呢? 分析 :如果允许有一定的错误率,可以使用 Bloom filter,4G 内存大概可以表示 340 亿 bit。将其中一个文件中的 url 使用 Bloom filter 映射为这 340 亿 bit,然后挨个读取另外一个文件的 url,检查是否与 Bloom filter,如果是,那么该 url 应该是共同的 url(注意会有一定的错误率)。
- 解决缓存穿透问题 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
其它:
- 在比特币中用来判断是不是属于钱包
- 敏感词判断,在布隆过滤器中查找敏感词
3.布隆过滤器原理
3.1 常规思路(不使用布隆过滤器如何解决数据过滤问题)
- 数组
- 哈希表
虽然上面描述的这几种数据结构配合常见的排序、二分搜索可以快速高效的处理绝大部分判断元素是否存在集合中的需求。但是当集合里面的元素数量足够大,如果有500万条记录甚至1亿条记录呢?这个时候常规的数据结构的问题就凸显出来了。数组、哈希等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。有的可能会问,哈希表不是效率很高吗?查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。
3.2 哈希函数
哈希函数的概念是:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。下面是一幅示意图:
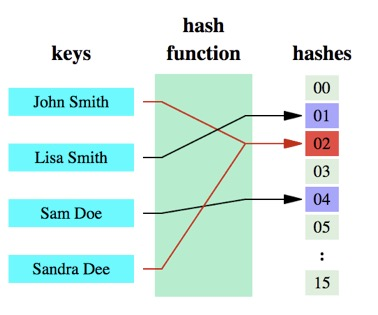
可以明显的看到,原始数据经过哈希函数的映射后称为了一个个的哈希编码,数据得到压缩。哈希函数是实现哈希表和布隆过滤器的基础。
试验:
分别往BloomFilter和HashSet中插入UUID,总计插入100w个UUID,BloomFilter误判率为默认值0.03。每插入5w个统计下各自的占用空间。结果如下,横轴是数据量大小,纵轴是存储空间,单位kb。
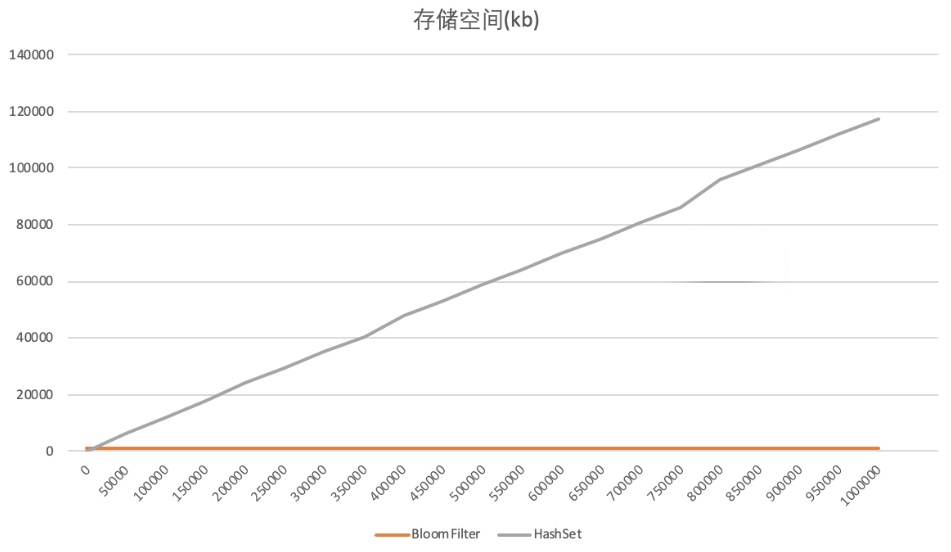
可以看到BloomFilter存储空间一直都没有变,这里和它的实现有关,事实上你在告诉它总共要插入多少条数据时BloomFilter就计算并申请好了内存空间,所以BloomFilter占用内存不会随插入数据的多少而变化。相反,HashSet在插入数据越来越多时,其占用的内存空间也会越来越多,最终在插入完100w条数据后,其内存占用为BloomFilter的100多倍。
3.3 布隆过滤器原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
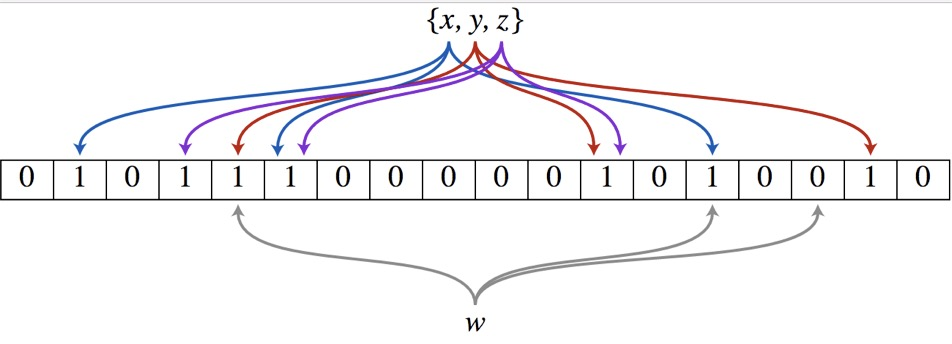
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
3.3.1 添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
3.3.2 查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
3.4 布隆过滤器特点
- 巴顿.布隆于一九七零年提出
- 一个很长的二进制向量 (位数组)
- 一系列随机函数 (哈希)
- 空间效率和查询效率高
- 有一定的误判率(哈希表是精确匹配)
3.5 布隆过滤器误判率统计
如果m代表位向量长度,n代表需要判断的元素个数, k代表hash函数个数。
下表是m与n比值在k个hash函数下面的误判率
误判率统计:
| m/n | k | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 | k=8 |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 1.39 | 0.393 | 0.400 | ||||||
| 3 | 2.08 | 0.283 | 0.237 | 0.253 | |||||
| 4 | 2.77 | 0.221 | 0.155 | 0.147 | 0.160 | ||||
| 5 | 3.46 | 0.181 | 0.109 | 0.092 | 0.092 | 0.101 | |||
| 6 | 4.16 | 0.154 | 0.0804 | 0.0609 | 0.0561 | 0.0578 | 0.0638 | ||
| 7 | 4.85 | 0.133 | 0.0618 | 0.0423 | 0.0359 | 0.0347 | 0.0364 | ||
| 8 | 5.55 | 0.118 | 0.0489 | 0.0306 | 0.024 | 0.0217 | 0.0216 | 0.0229 | |
| 9 | 6.24 | 0.105 | 0.0397 | 0.0228 | 0.0166 | 0.0141 | 0.0133 | 0.0135 | 0.0145 |
| 10 | 6.93 | 0.0952 | 0.0329 | 0.0174 | 0.0118 | 0.00943 | 0.00844 | 0.00819 | 0.00846 |
| 11 | 7.62 | 0.0869 | 0.0276 | 0.0136 | 0.00864 | 0.0065 | 0.00552 | 0.00513 | 0.00509 |
| 12 | 8.32 | 0.08 | 0.0236 | 0.0108 | 0.00646 | 0.00459 | 0.00371 | 0.00329 | 0.00314 |
| 13 | 9.01 | 0.074 | 0.0203 | 0.00875 | 0.00492 | 0.00332 | 0.00255 | 0.00217 | 0.00199 |
| 14 | 9.7 | 0.0689 | 0.0177 | 0.00718 | 0.00381 | 0.00244 | 0.00179 | 0.00146 | 0.00129 |
| 15 | 10.4 | 0.0645 | 0.0156 | 0.00596 | 0.003 | 0.00183 | 0.00128 | 0.001 | 0.000852 |
| 16 | 11.1 | 0.0606 | 0.0138 | 0.005 | 0.00239 | 0.00139 | 0.000935 | 0.000702 | 0.000574 |
| 17 | 11.8 | 0.0571 | 0.0123 | 0.00423 | 0.00193 | 0.00107 | 0.000692 | 0.000499 | 0.000394 |
| 18 | 12.5 | 0.054 | 0.0111 | 0.00362 | 0.00158 | 0.000839 | 0.000519 | 0.00036 | 0.000275 |
| 19 | 13.2 | 0.0513 | 0.00998 | 0.00312 | 0.0013 | 0.000663 | 0.000394 | 0.000264 | 0.000194 |
| 20 | 13.9 | 0.0488 | 0.00906 | 0.0027 | 0.00108 | 0.00053 | 0.000303 | 0.000196 | 0.00014 |
| 21 | 14.6 | 0.0465 | 0.00825 | 0.00236 | 0.000905 | 0.000427 | 0.000236 | 0.000147 | 0.000101 |
| 22 | 15.2 | 0.0444 | 0.00755 | 0.00207 | 0.000764 | 0.000347 | 0.000185 | 0.000112 | 7.46e-05 |
| 23 | 15.9 | 0.0425 | 0.00694 | 0.00183 | 0.000649 | 0.000285 | 0.000147 | 8.56e-05 | 5.55e-05 |
| 24 | 16.6 | 0.0408 | 0.00639 | 0.00162 | 0.000555 | 0.000235 | 0.000117 | 6.63e-05 | 4.17e-05 |
| 25 | 17.3 | 0.0392 | 0.00591 | 0.00145 | 0.000478 | 0.000196 | 9.44e-05 | 5.18e-05 | 3.16e-05 |
| 26 | 18 | 0.0377 | 0.00548 | 0.00129 | 0.000413 | 0.000164 | 7.66e-05 | 4.08e-05 | 2.42e-05 |
| 27 | 18.7 | 0.0364 | 0.0051 | 0.00116 | 0.000359 | 0.000138 | 6.26e-05 | 3.24e-05 | 1.87e-05 |
| 28 | 19.4 | 0.0351 | 0.00475 | 0.00105 | 0.000314 | 0.000117 | 5.15e-05 | 2.59e-05 | 1.46e-05 |
| 29 | 20.1 | 0.0339 | 0.00444 | 0.000949 | 0.000276 | 9.96e-05 | 4.26e-05 | 2.09e-05 | 1.14e-05 |
| 30 | 20.8 | 0.0328 | 0.00416 | 0.000862 | 0.000243 | 8.53e-05 | 3.55e-05 | 1.69e-05 | 9.01e-06 |
| 31 | 21.5 | 0.0317 | 0.0039 | 0.000785 | 0.000215 | 7.33e-05 | 2.97e-05 | 1.38e-05 | 7.16e-06 |
| 32 | 22.2 | 0.0308 | 0.00367 | 0.000717 | 0.000191 | 6.33e-05 | 2.5e-05 | 1.13e-05 | 5.73e-06 |
大家可以根据上表,结合需求进行设计一个和需求吻合又不怎么占用资源的布隆过滤器
4.布隆过滤器设计分析
以mysql+ 布隆过滤器为例
4.1 总体图:
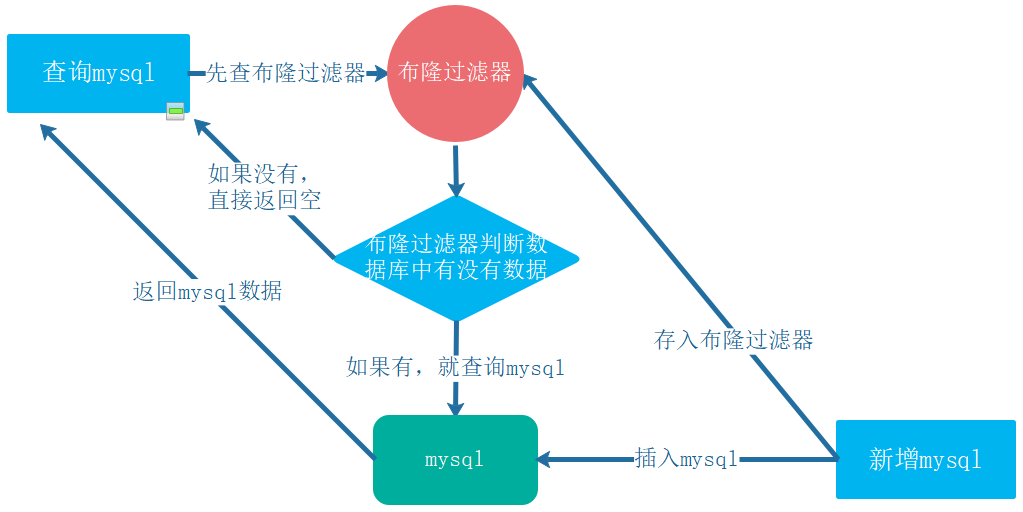
4.2 图解:
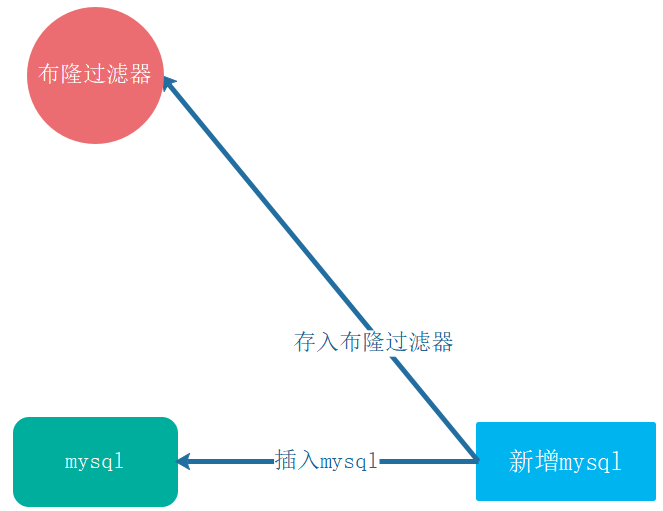
新增数据:
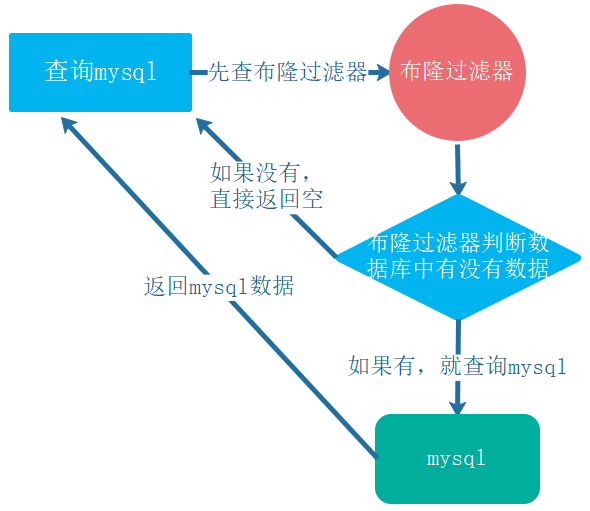
查询数据:
5.布隆过滤器实现
5.1用redis插件bloom-filter实现
下载最新的包
wget https://github.com/RedisBloom/RedisBloom/archive/refs/tags/v2.2.4.tar.gz
解压包
tar -zxvf v2.2.4.tar.gz
进入文件然后安装,生成so文件
cd RedisBloom-2.2.4
make
将模块加载到redis.conf文件里
vim redis.conf
.
.
.
#加上模块
loadmodule /root/RedisBloom-2.2.4/redisbloom.so
保存后,重启服务即可
布隆过滤器主要命令:
bf.add 添加元素
bf.exists 查询元素是否存在
bf.madd 一次添加多个元素
在 redis 中有两个值决定布隆过滤器的准确率:
error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve test 0.1 100000000
第一个值是过滤器的名字。
第二个值为 error_rate 的值。
第三个值为 initial_size 的值。
注意必须在add之前使用bf.reserve指令显式创建,如果对应的 key 已经存在,bf.reserve会报错。同时设置的错误率越低,需要的空间越大。如果不使用 bf.reserve,默认的error_rate是 0.01,默认的initial_size是 100。
示例:
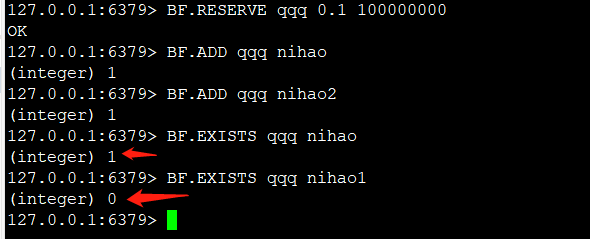
#新建一个过滤器
bf.reserve test 0.1 100000000 # test是布隆过滤器名称,0.1是误判率,100000000是位向量长度
#向过滤器中添加元素
127.0.0.1:6379> bf.add test abc123 #test是布隆过滤器名称,abc123是需要判断的元素
#判断元素是否在过滤器中
127.0.0.1:6379> bf.exists test abc123 #test是布隆过滤器名称,abc123是需要判断的元素
1
PHP代码就简单一点跟执行redis命令一样即可:
$redis = new \Redis();
$redis->connect('127.0.0.1', 6379);
$re = $redis->rawCommand('bf.exists', 'qqq', 'nihao');
var_dump($re);

