YARN Node Lable配置
标签是做什么的?
原汁原味的话,看官网Apache Hadoop-3.1.2
来一个对比,多队列和打标签的区别:
1. 多队列,是将集群汇总的资源按配比划分成多个队列,每个队列的资源对于机器来讲,都是不确定的,比如ABC三个队列每人占总集群资源的30%,A队列的30%是总数的百分比,落实到资源上是不确定哪台机器的,可能是1,2,3号机器,也可能是5,6,7号机器,重点是不确定性
2. 打标签,是按节点打标签的,主要是区分机器作用,比如A程序只能在1,2,3机器上运行,但是MapReduce调度(调度的问题后面写)是不确定机器的,为了实现"只要A程序运行就分发到1,2,3上去运行,不去其他机器上执行",这是打标签的作用
这篇主要写打标签
配置yarn-site.xml
<property> <name>yarn.node-labels.fs-store.root-dir</name> <value>hdfs://namenode:port/path/to/store/node-labels/</value>
<!--也可以是本地文件系统file://home/path/to/store/node-labels/-->
</property> <property> <name>yarn.node-labels.configuration-type</name> <value>centralized</value>
<!--一共有三种,centralized,delegated-centralized,distributed,区别有空再写-->
</property> <property> <name>yarn.node-labels.enabled</name> <value>true</value> </property>
添加标签 lable_1 到YARN集群的known lables collection
hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$ yarn rmadmin -addToClusterNodeLabels "lable_1(exclusive=true)" #双引号里面可以不写()的内容,exclustive默认是true,也就是默认独占整台节点 2020-09-11 16:05:36,290 INFO client.RMProxy: Connecting to ResourceManager at hadoop2/192.168.6.22:8033 hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$
查看集群已有的标签集合
hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$ yarn cluster --list-node-labels 2020-09-11 16:09:18,960 INFO client.RMProxy: Connecting to ResourceManager at hadoop2/192.168.6.22:8032 Node Labels: <lable_1:exclusivity=true>,<z:exclusivity=true> hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$
删除集群标签集合里的标签
hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$ yarn rmadmin -removeFromClusterNodeLabels lable_1 2020-09-11 16:11:39,552 INFO client.RMProxy: Connecting to ResourceManager at hadoop2/192.168.6.22:8033 hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$
将集合内的标签添加到机器上
hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$ yarn rmadmin -replaceLabelsOnNode "hadoop2=lable_1" #hadoop2 这里默认是hadoop2这台机器上的所有nodemanager,如果要特指,用hostname:port即可,port为YARN UI上的Node Address 2020-09-11 16:10:05,841 INFO client.RMProxy: Connecting to ResourceManager at hadoop2/192.168.6.22:8033 hadoop@hadoop2:/opt/hadoop-3.1.2/etc/hadoop$
为调度器添加标签,也就是将标签添加至队列
这里要解释一下,为什么要添加到队列,相当于队列()的标签和节点的标签是一种绑定关系,队列配置标签之后,相同标签的节点才会确切的归属这个队列,独占与否看上述标签的配置是否设置为true
引用官网的栗子
root / | \ engineer sales marketing
5个节点,h1~h5,其中一台有GPU(暂定为h5有GPU),将GPU Lable添加至h5节点(下面的队列的配置最后是要用xml的格式去添加进配置文件的)
yarn.scheduler.capacity.root.queues=engineering,marketing,sales #配置三个队列
yarn.scheduler.capacity.root.engineering.capacity=33 \
yarn.scheduler.capacity.root.marketing.capacity=34 | 三个队列资源之和必须等于100
yarn.scheduler.capacity.root.sales.capacity=33 /
yarn.scheduler.capacity.root.engineering.accessible-node-labels=GPU #允许engineering队列使用GPU标签的机器
yarn.scheduler.capacity.root.marketing.accessible-node-labels=GPU #允许marketing队列使用GPU标签的机器
yarn.scheduler.capacity.root.engineering.accessible-node-labels.GPU.capacity=50 #允许engineering队列使用GPU标签的资源最多50%
yarn.scheduler.capacity.root.marketing.accessible-node-labels.GPU.capacity=50 #允许marketing队列使用GPU标签的资源最多50%
yarn.scheduler.capacity.root.engineering.default-node-label-expression=GPU #如果engineering队列的任务没有指向特定的标签,那默认就使用GPU标签的资源
这些配置一定要仔细,建议用sublime或者nodepad++这种有色文本编辑器编辑,如果多个队列的配置,那这些配置的数量会很多,建议草稿打好,配置完成再写配置文件
配置完之后刷新队列即可
yarn rmadmin -refreshQueues
刷新完成之后即可将GPU标签添加到具体的节点上,添加命令还用之前的即可,添加完成之后即可看到YARN的Web页面上的
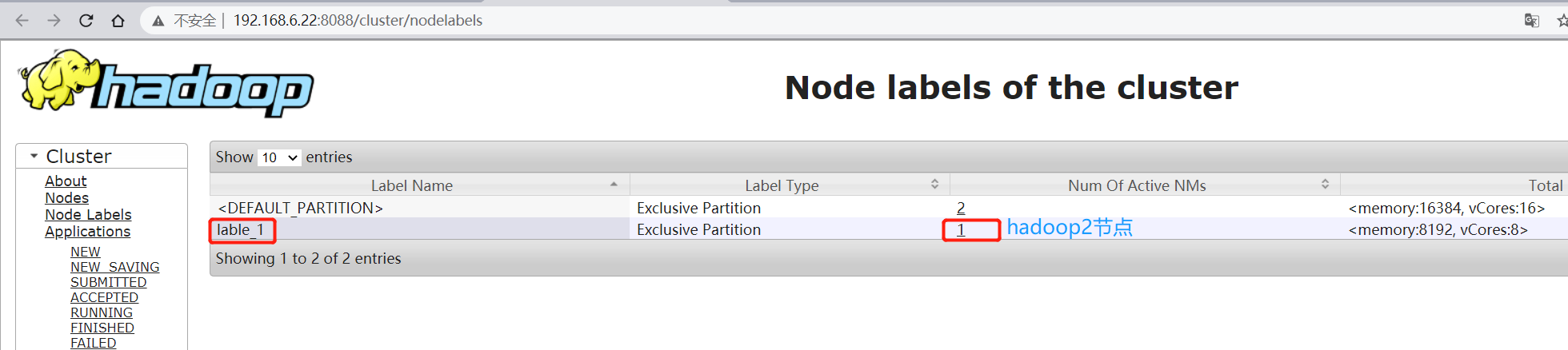
此时,标签已经绑定至队列,所以标签是不能删除的
下面是我自己测试的集群的配置和效果供参考


<property> <name>yarn.scheduler.capacity.root.small.accessible-node-labels</name> <value>lable_1</value> </property> <property> <name>yarn.scheduler.capacity.root.big.accessible-node-labels</name> <value>lable_1</value> </property> <property> <name>yarn.scheduler.capacity.root.small.accessible-node-labels.lable_1.capacity</name> <value>50</value> </property> <property> <name>yarn.scheduler.capacity.root.big.accessible-node-labels.lable_1.capacity</name> <value>50</value> </property> <property> <name>yarn.scheduler.capacity.root.big.default-node-label-expression</name> <value>lable_1</value> </property>
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> <property> <name>yarn.node-labels.enabled</name> <value>true</value> </property> <property> <name>yarn.node-labels.fs-store.root-dir</name> <value>hdfs://zhangwentao/lable</value> </property> <property> <name>yarn.node-labels.configuration-type</name> <value>centralized</value> </property> </configuration>
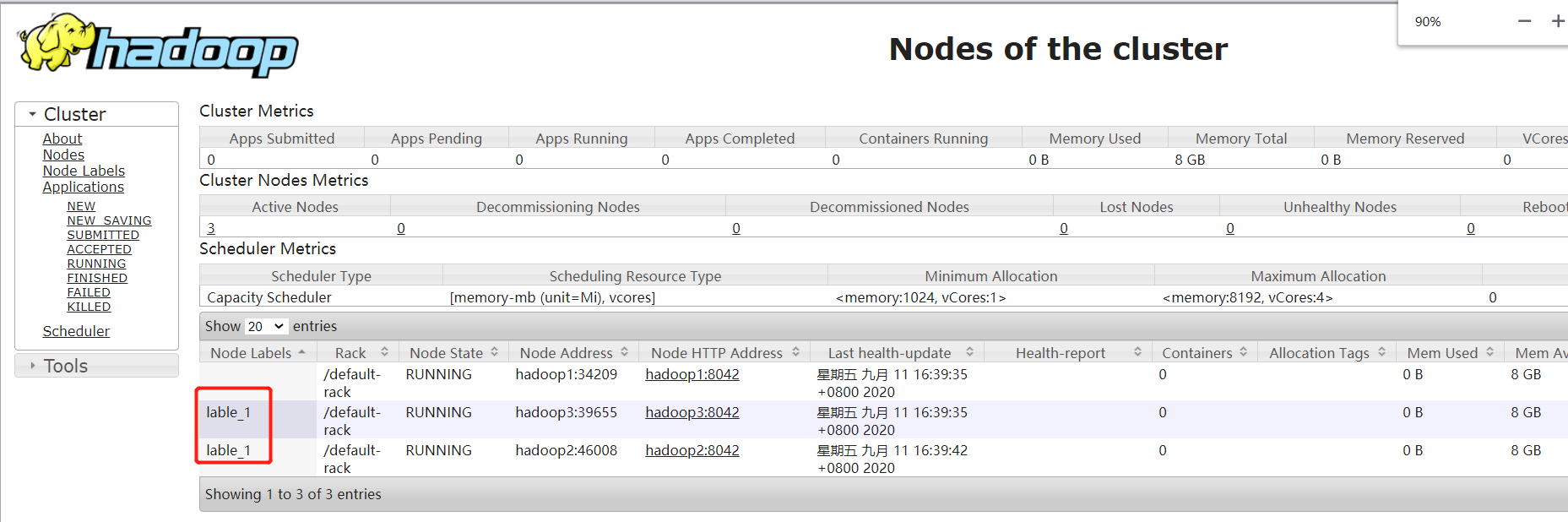
节点效果
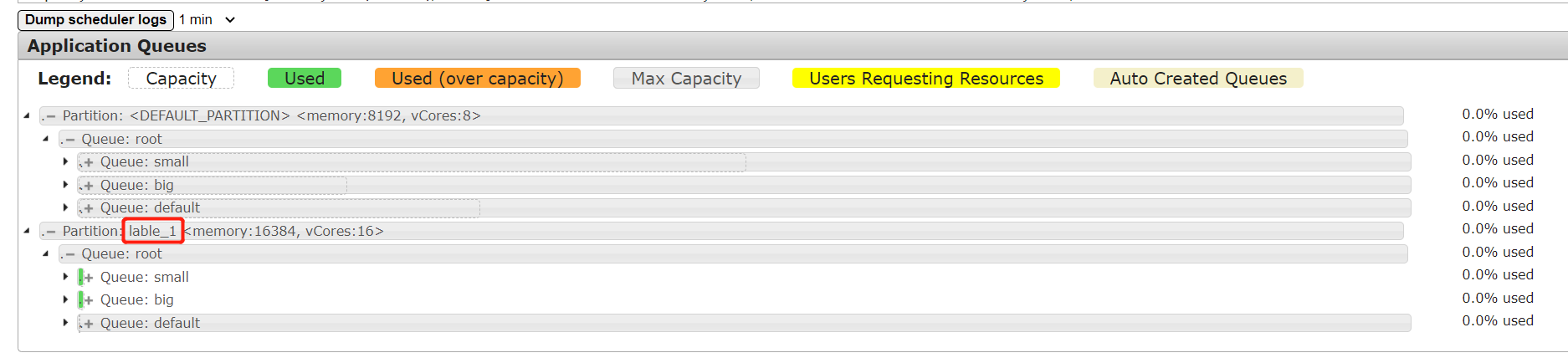
队列效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号