
Python字符编码与转换
需知: 1.在python2默认编码是ASCII, python3里默认是unicode 2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间 3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
Python数据类型:
数字Number()
二进制都是bytes类型(音频文件,视频文件)
string---encode----->bytes
bytes---decode----->string
文本是string类型
print (varname.encode(encoding='utf-8').decode(encoding="utf-8"))
编码占位
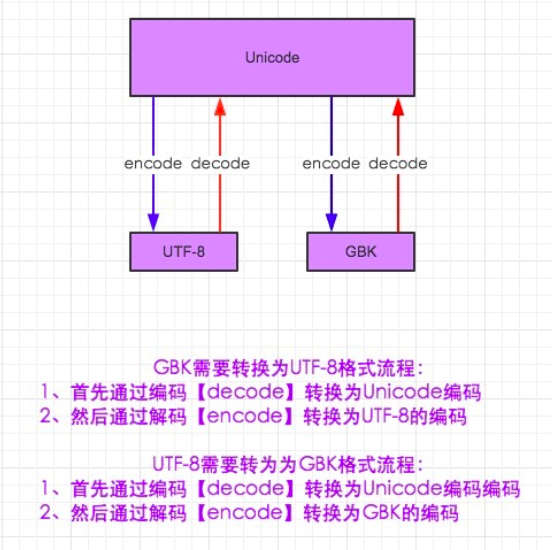
- Unicode:英文和中文字符存储都占两个字节空间(16位)
- GBK中文编码
- utf-8 :中文字符3个字节,英文字符按照ASCII码存储,占1个字节,8位。
- ASCII码只存英文和特殊字符
Python2中的编码转换:
问:
为什么Python3里面没有decode的方法?
Python默认数据编码是unicode,改了编码方式,程序内字符仍旧是unicode。只是文件的编码变成其他。
sys.getdefault()得到的是文件的编码方式。
Unicode---encode---->gbk/utf-8
1 #python2 2 import sys 3 print(sys.getdefaultencoding()) 4 5 6 msg = "我爱北京天安门" 7 msg_gb2312 = msg.decode("utf-8").encode("gb2312") 8 gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") 9 10 print(msg) 11 print(msg_gb2312) 12 print(gb2312_to_gbk)
1 #-*-coding:gb2312 -*- 2 import sys 3 print(sys.getdefaultencoding()) 4 5 6 msg = "我爱北京天安门" 7 #msg_gb2312 = msg.decode("utf-8").encode("gb2312") 8 msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 9 gb2312_to_unicode = msg_gb2312.decode("gb2312") 10 gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") 11 12 print(msg) 13 print(msg_gb2312) 14 print(gb2312_to_unicode) 15 print(gb2312_to_utf8)
关于字符编码的程序报错:
错误:can't assign to operator
翻译:binary mode doesn't take an encoding argument 遇到这种错误,表明二进制模式不接受编码参数,应该去掉encoding

 浙公网安备 33010602011771号
浙公网安备 33010602011771号