

Towards Accurate Multi-person Pose Estimation in the Wild 论文阅读
论文概况
论文名:Towards Accurate Multi-person Pose Estimation in the Wild
作者(第一作者)及单位:George Papandreou, 谷歌
发表期刊/会议:CVPR2016
被引次数(截止到发博日期,以谷歌学术为数据来源):52
主要方法
论文实现的是多人的姿态估计,使用的是自顶向下(top-down)的方法,即:先由目标检测方法把人检测出来,然后再进行单人的姿态估计。这篇论文的总体流程是:第一步,使用Faster-RCNN进行人的检测。第二步,进行姿态估计。
第一步、使用Faster-RCNN进行人的提取
这部分看起来没什么好说的,但是,读论文就要事无巨细,所以来看一下详细实现。
文章中使用了基于ResNet101的Faster-RCNN,但是做了一些更改,就是把卷积操作用atrous convolution给修改了,具体修改可以看一下原文的参考文献,我们这里看一下atrous convolution是什么,atrous convolution频繁的在deeplab的论文里出现,这里特意找了一下,如下图:
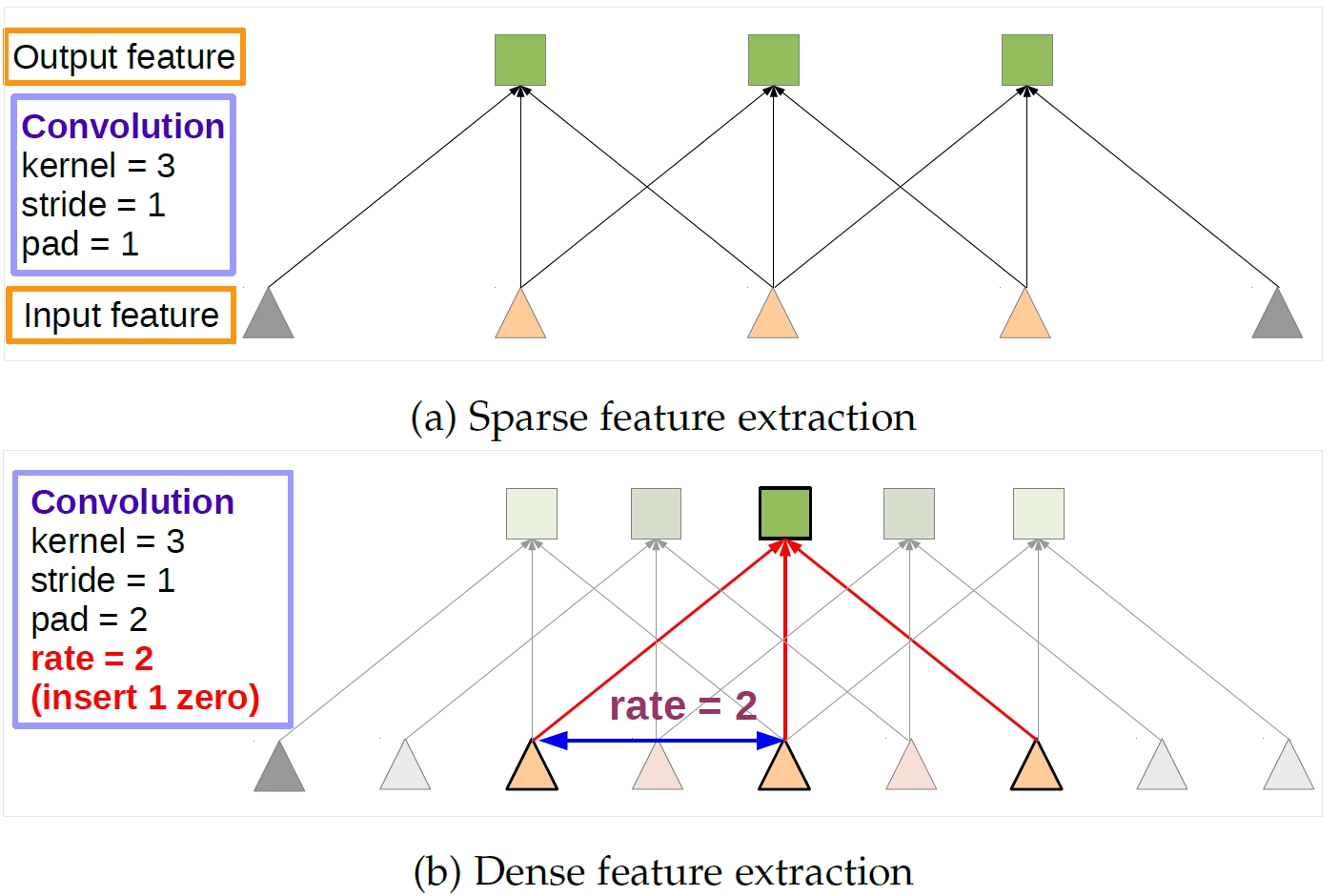
图(b)就是atrous convolution,接下来我们看一个二维的卷积,如图:
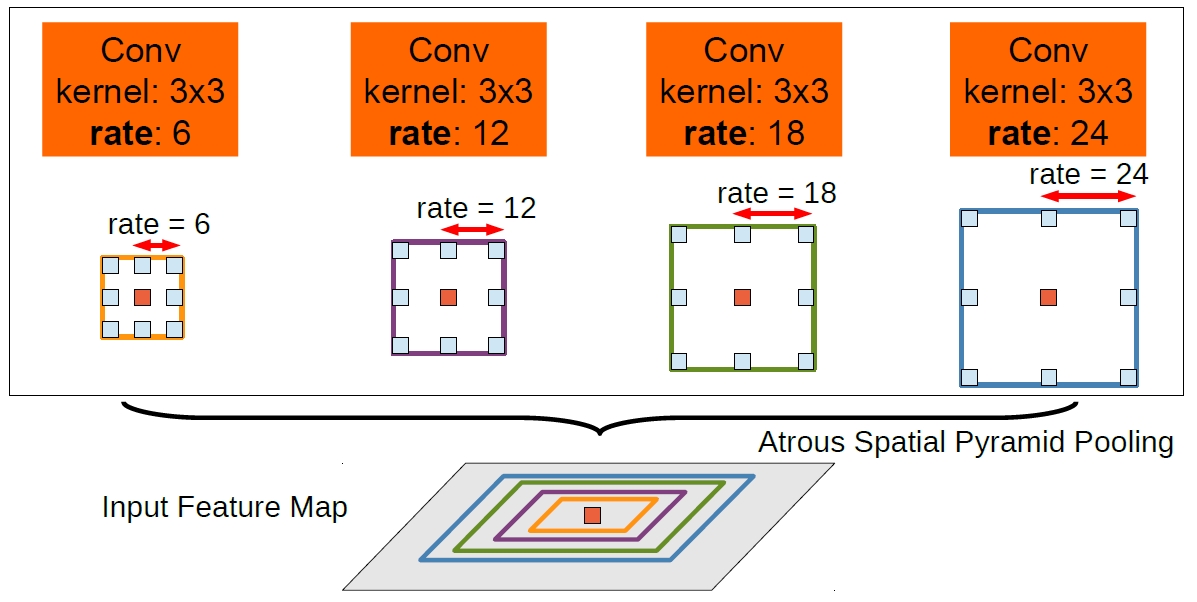
这幅图虽然是讲的时空金字塔池化,但是上面的卷积核我们可以直观的看到,可以说就是带孔的卷积,这样可以用相对更少的参数得到更大感受野的feature map(这样说也不知道对不对),论文中这么做的目的是为了让ResNet的输出由原来的stride=32变成stride=8,这样子就可以产生更“稠密”的feature map,我的理解是具有更大的感受野和更多的信息。另外,这里用的Faster-RCNN是重新训练过的,并且训练的时候只保留“人”这一个类别。
第二步、姿态估计
这部分是本文的重头戏,其骨干就是用ResNet来同时做了分类和回归。
1.图片分割
之前说过,我们首先要通过一个Faster-RCNN来检测人,但是我们知道检测框的大小不一样,那么应该如何处理呢。让我来做的话,二话不说,直接resize成我的网络输入大小,但实际上这样子会使我的人的图像长宽比失真,最终导致我的模型训练效果不佳。本文使用了一个比较好的方法,我觉得以后做类似任务的时候都可以这么处理。
- 将检测出来的框的长或宽扩展,使检测框符合一个长宽比x。
- 然后将整个框保持长宽比不变进行扩大,论文里说训练的时候按照1.0-1.5的比例随机扩大,也算是数据集增强的一部分,然后测试的时候就按1.25的比例扩大。
- 将上面的框框出来的区域裁剪,然后resize成257*353的大小,注意,之前的长宽比x=353/257=1.37,这样,即使经过resize,图片也不会失真。
2.分类和回归问题
前面说过,这部分主要是做了分类和回归。对于分类问题,论文中将以关节点为中心,以R为半径的区域归为1,其余位置为0。对于回归问题,回归了一个向量,也就是偏移量,定义为:
其中l_k为关节点坐标。为什么要这样呢?直接回归出关节点不好吗,实际上直接回归是很难的,谷歌的deeppose论文就是直接回归的,但是也是用了很多了阶段不停地修正才能得到真正的坐标,我曾经试过只用一个阶段单纯的回归坐标,但是结果是所有的预测结果都是一样的,必须经过修正才可以让网络学到真正能识别关节的特征,所以这就是本文的两步走策略,我先找到一个大概区域,然后根据我预测的偏移量投票出我真正的关节点坐标,那么怎么得到呢,公式如下:
其中G()是 bilinear interpolation kernel,恕我才疏学浅,这个函数找了很久都不知道是什么,看字面是双线性内插算法,但是双线性内插公式要有四个已知点,这部分等以后搞懂了再说吧。但是论文中提到,如果heatmap(也就是那个圆)和offset(偏移向量)都是完美的话,那么f应该是冲击响应函数,我们看一下论文里的图片,直觉上理解一下。


后面就是实验结果,其中还提到了基于OKS的非最大值抑制,但是可惜没有说具体怎么做,关于非最大值抑制的相关问题,由于这个也很重要,以后单写一篇随笔吧。
