

统计学习方法c++实现之三 朴素贝叶斯法
朴素贝叶斯法
前言
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,这与我们生活中判断一件事情的逻辑有点类似,朴素贝叶斯法的核心是参数的估计,在这之前,先来看一下如何用朴素贝叶斯法分类。
代码地址https://github.com/bBobxx/statistical-learning,欢迎提问。
基本方法
朴素贝叶斯法必须满足特征条件独立假设,分类时,对给定的输入\(x\),通过学习到的模型计算后验概率分布\(P(Y=c_i|X=x)\),将后验概率最大的类作为输出,后验概率的计算由贝叶斯定理:
再根据特征条件独立假设,
由于分母都一样,所以我们只比较分子就可以确定类别。
参数估计
对于上面的公式来说,我们需要知道两个概率,即:
先验概率:\(P(Y=c_k)=\frac{\sum^{N}_{i=1}I(y_i=c_k)}{N}\)
通俗来说就是数个数然后除以总数。
还有一个条件概率:\(P(X^{(j)}=a_{jl}|Y=c_k)=\frac{\sum^{N}_{i=1}I(x_{i}^{(j)}=a_{jl},y_i=c_k)}{\sum^{N}_{i=1}I(y_i=c_k)}\)
不要被公式唬住了,看含义就容易懂,其实还是数个数,只不过现在要同时满足x y的限制,即第i个样本的第j维特征\(x_{i}^{(j)}\)取\(a_{jl}\)这个值,并且所属类别为\(c_k\)的概率。
上面的就是经典的最大似然估计,就是数个数嘛,于此相对的还有贝叶斯学派的参数估计贝叶斯估计,这里直接给出公式:
先验概率:\(P(Y=c_k)=\frac{\sum^{N}_{i=1}I(y_i=c_k)+\lambda}{N+K\lambda}\)
条件概率:\(P(X^{(j)}=a_{jl}|Y=c_k)=\frac{\sum^{N}_{i=1}I(x_{i}^{(j)}=a_{jl},y_i=c_k)+\lambda}{\sum^{N}_{i=1}I(y_i=c_k)+S_j\lambda}\)
通常取\(\lambda=1\),此时叫做拉普拉斯平滑。\(K\)是Y取值的个数,\(S_j\)是某个特征的可能的取值个数。
代码结构
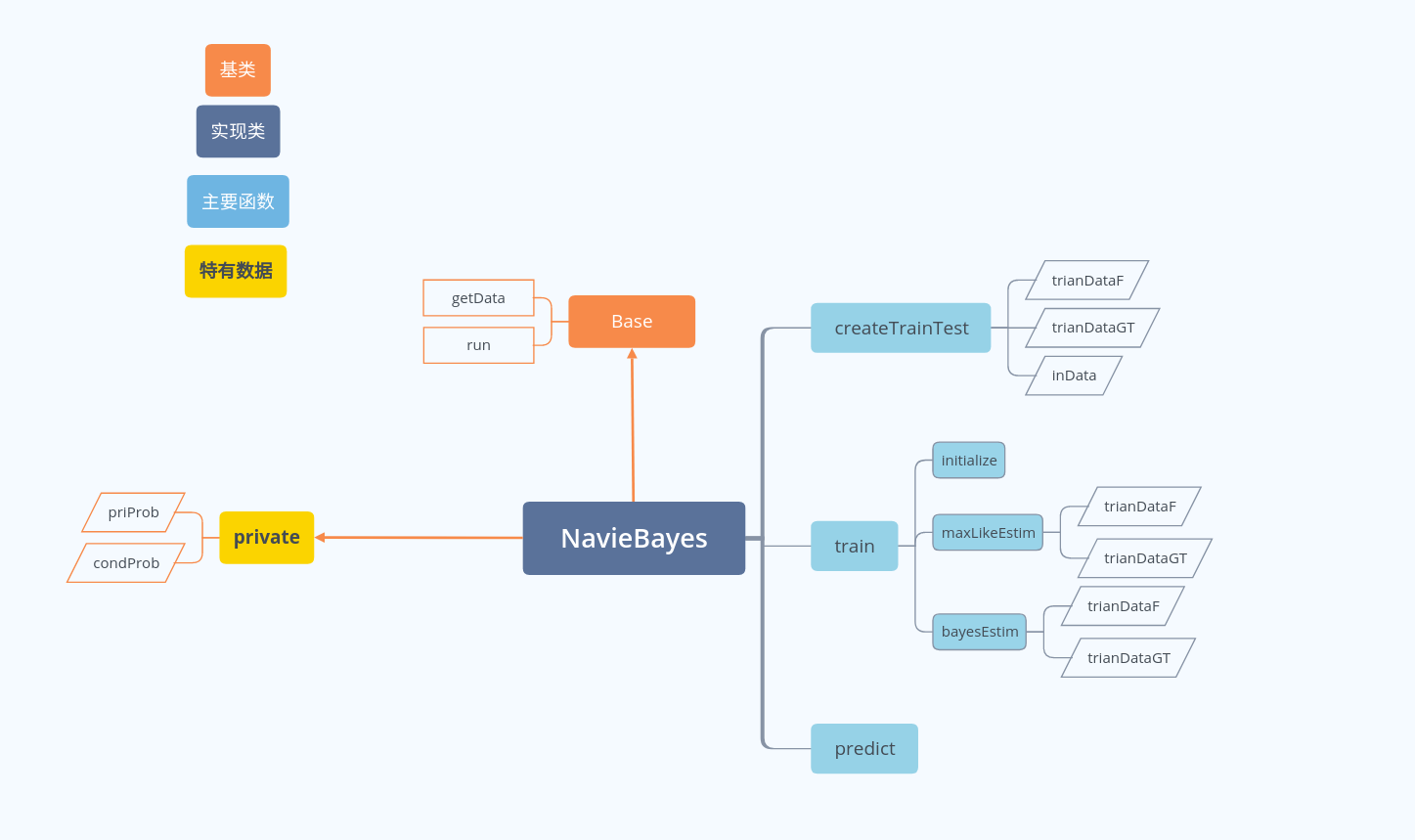
在train里面分别调用了两种参数估计的方法。
实现细节
对于贝叶斯法,终点在于参数估计,这里其实就是计数(个人看法,希望得到指导,想破脑袋也没想起来如何不用遍历的方法计算概率)。
首先,我选用了map结构来存储条件概率和先验概率:
vector<map<pair<string,string>, double>> condProb;
map<string, double> priProb;
map是基于红黑树的一种数据结构,所以查找很快,这样计算后验概率的时候就能很快查找到相应的概率。
其他的应该都好理解,无非是循环计数,不过在贝叶斯估计这里我耍了个花招,就是将公式拆成两部分:\(P(X^{(j)}=a_{jl}|Y=c_k)=\frac{\sum^{N}_{i=1}I(x_{i}^{(j)}=a_{jl},y_i=c_k)}{\sum^{N}_{i=1}I(y_i=c_k)+S_j\lambda}+\frac{\lambda}{\sum^{N}_{i=1}I(y_i=c_k)+S_j\lambda}\)
void NavieBayes::bayesEstim(const double& lmbda = 1.0){
for(const auto& gt: trainDataGT){
priProb[std::to_string(gt)] += 1.0;
}
for(unsigned long i=0;i<indim;++i){
for(unsigned long j=0;j<trainDataF.size();++j)
{
auto cond = std::make_pair(std::to_string(trainDataF[j][i]), std::to_string(trainDataGT[j]));
condProb[i][cond] += 1.0/(priProb[std::to_string(trainDataGT[j])]+lmbda*xVal[i].size());
}//先跟最大似然估计一样,由于采用了连加,如果把lambda那部分也包含,需要计算一个每个特征取某个值时的个数
//于是将公式拆成两个分母相同的式子相加的形式,这部分计算分子中除去lambda那部分
}
for(unsigned long i=0;i<indim;++i){
for(auto& d:condProb[i]){
d.second += lmbda/(priProb[d.first.second]+lmbda*xVal[i].size());
}
}//这里计算另一部分
for(auto& iter:priProb)
iter.second = (iter.second+lmbda)/(double(trainDataF.size()+yVal.size()));
}
至于预测就是取\(P(Y=c_k)\prod_{j}{P(X=x^{(j)}|Y=c_k)}\)最大的那一部分
void NavieBayes::predict() {
...
for(const auto& y: yVal){
auto pr = priProb[std::to_string(y)];
for(unsigned long i=0;i<indim;++i)
pr *= condProb[i][std::make_pair(std::to_string(testDataF[j][i]), std::to_string(y))];
...
}
}
总结
这部分概念很好懂,但是如何计数确实废了一番脑筋,以后看看在优化吧,这个时间复杂度实在太高了。
