

微信公众号 文章的爬虫系统
差不多俩个星期了吧,一直在调试关于微信公众号的文章爬虫系统,终于一切都好了,但是在这期间碰到了很多问题,今天就来回顾一下,总结一下,希望有用到的小伙伴可以学习学习。
1、做了俩次爬虫了,第一次怕的凤凰网,那个没有限制,随便爬,所以也就对自动化执行代码模块放松了警惕,觉得挺简单的,但是其实不是这样的,我被这个问题困扰了好几天,差不多4天的一个样子,因为搜狗做的限制,同一个ip获取的次数多了,首先是出现验证码,其次是就是访问限制了,直接就是不能访问,利用 request得到的就是访问次数过于频繁,这样子的提示,所以说开发过程中最头疼的不是代码的编写,而是测试,写完代码不能立马测试,这种感觉相信大多数的程序员是不能喜欢的,我现在写的程序是每天执行三次,这样的一个频率还行,而且因为是多公众号采集嘛,每个公众号之间的间隔时间也的有,要不然同时访问十几个公众号的上百篇文章也是不现实的,说到这里插一句,怎么让每个公众号怕去玩之后,等一段具体的时间,在执行下一个,最后用的setInterval函数解决的,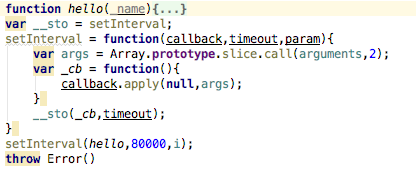
每过80秒执行一个公众号,把每次的执行代码写到hello中,泡的有点远了,收一收哈,说说cron这个包,自动化执行,npm官网上只给了一个例子,但是我这个指桑拿可能是有点压制的厉害,不能够玩却理解他的用法,然后我说理解不了怎么办啊,上网搜呗,百度,cron包的具体用法,一看,嚯,还挺多,于是就看啊看啊,但是仔细以分析就不是那么回事儿了,都是废话,没什么用,网上一般的用法中都带有一个问号,但是我加上问号的时候,就报错了,所以说都是扯淡,最后在同学组的一个前端技术讨论群中说了一声,还真有热心的群友,给我找了一个链接,我进去一看,试了一下,还行,所以呢,非常感谢这个帮助我解惑的同学,再次我把qq群号,和链接附上,方便正在看这篇文章的你学习,QQ群号:435012561,链接:http://www.tuicool.com/articles/yy2Ivmj,这个链接里面说的还行,至少能用,这里我还行到一个问题,就是timezone,我们之前用过一次,用的是洛杉矶时间,但是这次明显不行啊,要用咱们中国的时间啊,但是我试了几次北京的不行,重庆的可以,所以我就用了重庆的。
2、这里要说的是,从地址栏获取参数的问题,我上一个做的没问题,但是这个不知道怎么就不行了,上一个从地址栏得到的是数字,但是这个得到的是字符串,再加上mongodb中的对字段的要求还是挺严格的,所以一个分页功能也困扰了我几个小时吧,最后是怎么解决的呢,是通过我加的一个mongodb的讨论群,在里面问了一句这是怎么了,发了个截图,里面就有一个热心的网友说你这明显是传入的数据格式不对啊,一语惊醒梦中人,我说是啊,然后就把得到的参数,我用Number()函数处理了一下,让string类型的数字,变成了number类型的数字,就好了,所以说大家在用mongodb的时候一定要注意存储数据的格式,
3、mongodb查询数据语句组织方式:

其实说白了就是limit和skip俩个函数的使用,但是具体的格式可的看好了,还有我这个是接受的参数,不过mongo的参数接受也好弄直接写就好了,不用像sql那样搞什么${""}这种类型的,后面的sort函数说明了排序的方式,这里是设置的以ctime字段为标准,-1表示倒序,1表示正序,
4、在本次代码编写中,我首次使用了try catch 这个补错的方式,事实证明,还行,可以把偶尔的错误正常的打印出来,但是不影响代码的整体执行,或者是说下一次执行,整体感觉非常好,
具体的使用方法,在try中放入你要执行的代码,在最后加上一行,throw Error();
然后给catch传入一个参数e,在catch中可以打印很多个信息,我只打印了其中的一个,e.message,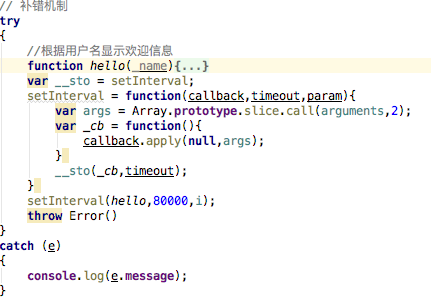
5、这次编码过程中主要用到了anync包,其中的ansyc.each循环,ansyc.waterfall执行完上面的才可以执行下面的,而且撒谎给你下之间还可以从上至下传递参数,这个很重要,因为在本次编程中,每次获取的内容不同,每次代码执行的条件不同,即需要的参数也不同,即有可能下一次代码的执行就需要用到上一次代码执行得到的结果,所以说这个anync包,真的是值得研究,他的每个方法都不同,有时候可以得到意想不到的效果。
6、在mysql中如果想要达到这样一个效果,就是说,如果数据库中已经存在了,那就不予理会,或者说不重复存储,如果数据库中不存在,那么就存储进来,很简单,直接把插入数据的insert 换成 replace 。但是在mongodb中,应该是没有,或者说是我还没有发现,我是这么解决的,定义了一个开关,令这个开关为真,每次存储之前,先把所有的数据循环一遍,看看有没有这条数据,如果有,让开关变为假,如果没有,继续执行,即判断此时开关的真假,如果是真的,那就执行插入操作,如果是假的,就不予理会,这就达到了类似的效果,否则每次都会存储大量的重复数据,
7、本次采集的核心,就是我文件中的common.js了,首先因为要采集,所以需要用到request包,采集到之后,要处理html格式的数据,使之可以使用类jquery的操作,那么久用到了cheerio这个包,然后在循环采集的时候,会用到anync.each这个方法,所以会用到async这个包,
7-1、
通过搜狗微信采集,就要分析搜狗微信的路径,每个公众号的页面的路径是这样的
http://weixin.sogou.com/weixin?type=1&s_from=input&query=%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie=utf8&_sug_=n&_sug_type_=
这个是“这才是日本”的页面的链接,经过分析,所有的公众号的链接只有query后面的参数不同,但是query后面的参数是什么呢,其实就是通过encodeURIComponent()这个函数转化之后的“这才是日本”,所以说都一样,获取那个公众号,就将那个公众号的名字编码之后,动态的组合成一个链接,访问就可以进入到每个链接里面了,但是这个链接只是请求到了这个页面,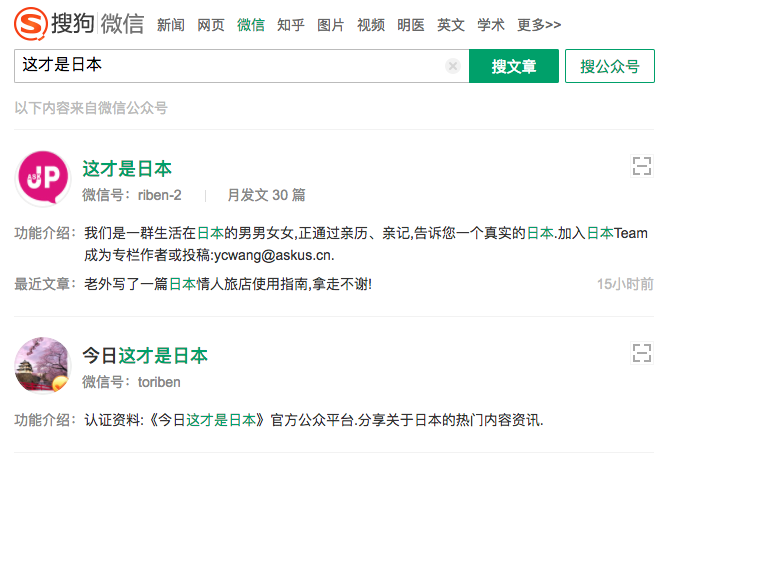
并不是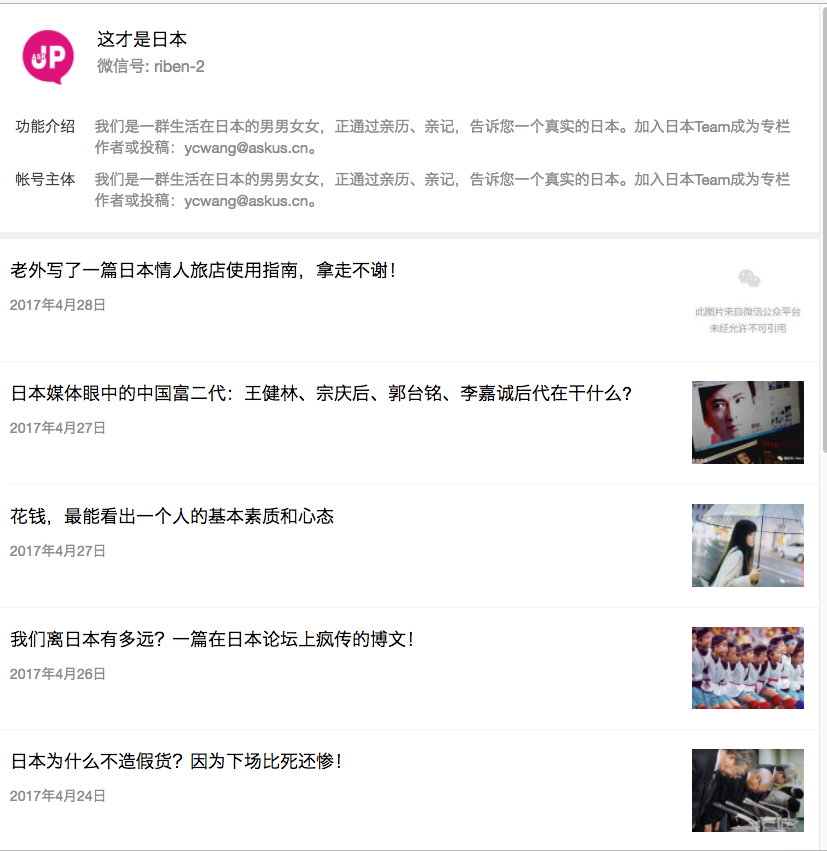
这个页面,所以还的进一步处理,就是得到当前页面的第一个内容的链接,即href
当得到了这个链接,就会发现他有他的加密方式,其实很简单的,就是在链接里面的加了三个amp;把链接里面的这三个amp;替换为空,就好了,这也就是第一步,得到每一个公众号的页面链接,
7-2
得到链接之后,就要进行访问了,即请求,请求每个地址,得到每个地址的内容,但是每个页面显示的内容都不在页面中,即html结构中,在js中藏着,所以要通过正则匹配,得到每篇文章的对象,然后就循环每个公众号的这个对象,得到这个对象中的每篇文章的一些信息,包括title,thumb,abstract,URL,time,五个字段,但是我使用的代码烂透了,尽然当时使用了
对象.属性.foreach(function(item,index){
})
这种烂透了的方式,弄的最后好的在写一次循环才可以完全的得到每一个对象,否则只可以得到第一个,在这里应该用async.each,或者async.foreach这俩中方式每种都可以啊,而且都是非常好用的方式。这样的话买就得到了每篇文章的以上基本消息,
7-3、
第三个阶段,就是进入到每篇文章的详情页,获得每篇文章的内容,点赞数,作者,公众号,阅读量等数据,在这里碰到的主要问题是,人家的content直接在在js中,所有的img标签都有问题,他是以<image-src = "...>这种形式存在雨content中,但是这样的话,这样的图片在我们的网页中不能被显示,因为标签存在问题啊,html文档不认识这样的img标签啊,所以这里要进行一些处理,把所有的<image-src = "...>用replace替换为<img src = "...>这样的话就OK了,但是我在编程的时候进行到这儿碰到了一个傻逼问题,我将这样的得到的content,放到html中可以,但是存到mongodb中,每个引号的前面莫名其妙的多了一条杠,每个img标签多了三条杠,这样的话就又不可以显示了,我就一直纠结啊,怎么能存储的时候不要这三条杠呢,经过了一番艰苦卓绝的斗争,最后还是没能解决了,最后加了一个mongodb 的讨论群,我进去问了一下,有一个大神立马说,你知道什么是转义字符吗?我当时很懵逼啊,我自认为我知道啊,人家说,你的群备注还是前端,你做前端的不明白这是转义字符吗?我就更加懵逼了,然后过了一会儿我才明白过来,这个是存储的时候被转义了,但是当从数据库读的时候,就自动有没有了,所以说只有存在数据库中的数据有三条杠,原始数据和读取出来的数据都没有,真是完美啊!
8、最后想说一点,这次是我第一次接触有验证码的网页请求,这里用到了阿里一个服务,识别验证码,
END!

