mysql如何执行关联查询与优化
mysql如何执行关联查询与优化
一、前言
在数据库中执行查询(select)在我们工作中是非常常见的,工作中离不开CRUD,在执行查询(select)时,多表关联也非常常见,我们用的也比较多,那么mysql内部是如何执行关联查询的呢?它又做了哪些优化呢?今天我们就来揭开mysql关联查询的神秘面纱。
二、mysql如何执行关联查询
mysql关联执行的策略很简单:mysql对任何关联都执行嵌套循环关联操作。即:mysql先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。如果mysql在最后一个关联表无法找到更多的行,它将返回上一层关联表,看看能否找到更多的匹配记录,以此类推迭代执行。
按照这种方式,mysql查找第一个表的记录,再嵌套查询下一个关联表,然后回溯到上一个表,这正如其名——“嵌套循环关联”。看一下下面的例子:
SELECT
t1.column1,
t2.column2
FROM
tb1 t1
INNER JOIN tb2 t2 ON t1.column3 = t2.column3
WHERE
t1.column1 IN (4, 6)
假设mysql按照查询中的表顺序进行关联操作,我们可以用伪代码表示其过程:
outer_iter = iterator over t1 WHERE column3 IN (4, 6)
outer_row = outer_iter.next
WHILE outer_row
inner_iter = iterator over t2 WHERE column3 = outer_row.column3
inner_row = inner_iter.next
WHILE inner_row
output [ outer_row.column1,inner_row.column2 ]
inner_row = inner_iter.next
END
outer_row = outer_iter.next
END
上面的执行过程对于单表查询和多表关联查询都适用,如果只是单表查询,那么只需要完成最外层的循环操作即可。如果关联中存在外连接,上面的过程仍然适用,我们只需略作修改。查询sql如下:
SELECT
t1.column1,
t2.column2
FROM
tb1 t1
LEFT OUTER JOIN tb2 t2 ON t1.column3 = t2.column3
WHERE
t1.column1 IN (4, 6)
对应的伪代码修改如下:
outer_iter = iterator over t1 WHERE column3 IN (4, 6)
outer_row = outer_iter.next
WHILE outer_row
inner_iter = iterator over t2 WHERE column3 = outer_row.column3
inner_row = inner_iter.next
IF inner_row
WHILE inner_row
output [ outer_row.column1,inner_row.column2 ]
inner_row = inner_iter.next
END
ELSE
output [ outer_row.column1,NULL ]
END
outer_row = outer_iter.next
END
如果用图表示关联查询的过程,图示如下,请从左至右,从上至下看这幅图:
| t1 | t2 | 结果行 |
| column1=4,column3=1 | column3=1,column2=1 | column1=4,column3=1 |
| column3=1,column2=2 | column1=4,column3=2 | |
| column3=1,column2=3 | column1=4,column3=3 | |
| column1=6,column3=2 | column3=2,column2=1 | column1=6,column3=1 |
| column3=2,column2=2 | column1=6,column3=2 | |
| column3=2,column2=3 | column1=6,column3=3 |
mysql的关联方式也可以由一棵树表示,它是一个左侧深度优先树:
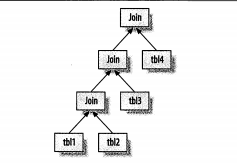
三、关联查询优化器
mysql优化器最重要的一部分就是关联查询优化,它决定了多个表关联时的顺序。通常多表关联的时候,可以有多种不同的关联顺序来获得相同的结果。关联查询优化器则通过评估不同顺序时的成本来选择一个代价最小的关联顺序。
大家看一下下面的查询,它可以通过不同的关联顺序得到相同的结果:
SELECT
u.realname,
u.mobile,
c.`name`
FROM
USER u
INNER JOIN user_company uc ON u.id = uc.user_id
INNER JOIN company c ON uc.company_id = c.id
按照上面的关联执行规则,我们可以给出执行计划,mysql可以从user表开始,通过user_company表的user_id列找到对应的company_id,然后再通过company表的主键找到对应的记录。我们执行了mysql的explain,得出的结果如下:

这和我们给出的执行顺序不一致,这样的效率是否更高呢?我们使用STRAIGHT_JOIN关键字得出的分析结果如下:

我们分析一下mysql为什么会改变关联的顺序,我们可以看到改变顺序后,第一个关联表只需要扫描很少的行数,第二个、第三个关联表的扫描项也是不同的。uc表只有480条记录,而u表有2300条记录。如果先扫描uc表,只返回480条记录,然后进行嵌套循环查询,如果先扫描u表,则返回2300条记录。换句话说,更改顺序后,查询可以进行更少的嵌套循环和回溯操作。
通过这个例子,我们可以看到mysql是如何选择合适的顺序让查询执行的成本更低的。重新定义关联顺序是优化器的一个重要的功能,它尝试在所有关联顺序中选择一个成本最小的来生成执行计划树。
至此,mysql是如何进行关联查询的,以及优化,已经介绍完了,欢迎大家多多交流。
*如果您觉得对您有帮助,请关注+推荐
*您的支持就是我继续下去的动力
*承接项目+V:ronaldoliubo
***************************************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号