Memcached介绍
Memcached介绍
Memcached是一种免费的、开源的、高性能的、分布式对象缓存系统,通过缓解数据库压力,来提高动态web页面的速度。
Memcached是一种内存级别的键值对存储,用来存放数据库调用、API调用或者是页面反馈的任意类型的数据,可以是字符串、对象等。
Memcached的功能很强大,设计是用来促进快速部署、简单开发,解决大数据缓存的问题,在大多数语言中都有memcached的调用API。
Memcached是一种开发工具,不是代码编译器,也不是数据库中间件。
Memcached的组成:
- Client软件,用来显示memcached服务器的列表
- 基于client的hash算法,基于key来选择server
- Server端,在内部hash表中存放了key和对应的value
- LRU,决定了什么时候将old数据释放,重新分配内存
简单的key/value存储模型
服务器端不会关心数据,在服务器端存放的数据字段通常有4种:key键、超时时间、可选标志位和原始数据raw data。服务器不理解数据结构,所以在使用中必须提前将数据序列化,然后上传至服务器中。可能有些命令会作用在底层的数据上,但是并不是一种管理端。
在逻辑上一半在client,一半在server
Memcached的实施,一半在client,一半在server上,client会知道如何选择一个server去读写数据,也知道当client自己连接不到server时,会怎么处理。
Server知道如何存储数据和取数据,也知道如何管理和调度内存。
Server之间是相互独立,不用互联
在部署了memcached的server上,是相互独立的,不需要交互和同步,也不需要广播和复制。增加server就是增加了可用的内存,如果client在直接本地拥有的server上删除和重新写数据,缓存就会失效。
在memcached上,所有的命令都会被快速的执行,在慢设备上,1MS就会有响应,如果是高端的server,每秒会有几十万的输入。
默认情况下,memcached是基于LRU,也就是least recently used,最小化重用缓存,在缓存中的内容,超过一定时间之后,就会超时 ,超时的数据会限制重新返回内存的时间,或者是将这些无用的数据删除。为了保证低延时,在资源回收过程中,是没有等待状态的,资源的回收也是懒惰式的。
硬件限制
Memecached服务和硬件的耦合关系没有那么强,对CPU的占用比较低,内存的占用是分配多少内存,就占用多少内存,网络带宽的占用,取决于数据的平均大小。
CPU需求
Memcached对CPU的需求很低,主要是因为他的主要功能是为快速响应,memcached是一种多线程的服务,默认有4个工作线程,这并不意味着需要使用100C来满足memcached的使用需求。在一般的部署场景中,CPU都是充足的,大多数的安装,只会使用1个memcached的线程。
内存需求
Memcached服务的最主要的一个点就是将多个主机的内存组合在一起,让应用看起来是访问的一个大内存,内存越多越好,但是不要占用服务的内存,如果这些服务要访问memcached。
最好是让每个memcached服务器使用的存储相同,集群均衡就是意味着在集群中动态的增加或删除主机,不用考虑主机的权重,当失去了该主机,也不会对服务产生影响。
避免使用swap
在memcached主机上,指定物理内存和一小部分的一处,不能超额分配内存,也不要寄希望与swap交换内存能够充当内存使用。如果使用交换内存,性能会很差。如果使用了swap交换内存,要时时做到监控。
Numa
在numa系统中,memcached会正常工作,如果memcached运行在多个numa节点上,会有一个明显的性能下降。如果对性能很关心,而且有多个NUMA系统,最好的方法是在每一个numa节点上运行一个memcached实例,通过numactl将势力绑定在节点上。
在web服务器上运行memcached
通常是在web服务器上使用单独的内存空间,或者是使用单独的服务器来做为memcached节点,如果web服务器有4G内存,系统和应用最多占用了2G内存,那么就可以分配1.5G给memcached,或者更多。
瘦置备分配内存是一种减小内存开销的好办法,当失去任何一个web应用服务,都不会造成大的损失。
在额外的维护过程中,如果应用超额使用内存,需要关注memcached是否会被终止访问。如果超额使用内存、使用交换内存空间或者因为应用内存短缺而停止了memcached,会造成应用风险。最好的建议是使用一点点交换内存或者不使用。或者是让应用停止,而不是放任内存竞争。
在数据库上运行memcached
在数据库服务器上运行memcached服务,并不是一个好的方式。对于数据库服务器来说,给服务器分配的内存越多越好,如果出现内存未命中,也可以保证数据库的索引和数据都在内存中。
使用独立的主机
如果在单独的物理主机上部署memcached服务,这就意味着不需要担心其他服务会和memcached产生冲突,可以分配该主机上尽可能多的内存给memcached服务。这种方式还有一种好处,就是能很方便的扩展内存容量。
这种部署同样也有问题,当在memcached集群中,每个服务器的压力越大,当某个服务器故障后,所需要承受的风险就越大。
假如现在的内存命中率达到90%,现在有10台memcached服务器构成一个集群,如果1个服务器故障,则命中率会降低到82%或者更多。假如那些剩下的10%请求直接访问,这个时候的直接访问数据量就会上升到18%或者20%,这就意味着后端服务器会比以前承受更多的请求。如果数据库在响应成倍的请求时依然保持正常,那这个影响可能会很小,内存未命中的部分,数据库查询就会多出来一倍。
所以说,当单台memcached服务器的性能越好,丢失一台服务器,产生的影响,也就越大。
容量规划
在做memcached容量规划的时候,要重点关注当内存,当服务器故障,能承受的最大损失是多少。
网络需求
Memcached的网络需求,取决于缓存的数据的平均大小。尽量通过应用来控制到小。在内网千兆传输来说,会很快。在很多部署环境中都很低的网络要求,如果网络带宽越大,数据传输的效果就越好。
Memcached的安装
可以通过系统自带的镜像yum或rpm形式安装,也可以通过在官网下载源码文件tar.gz,通过编译的形式安装,编译的方法是最标准最普通的安装形式。在编译安装之前,需要安装libevent-devel组件,可以直接通过挂载镜像安装,如果不清楚依赖关系,可以直接通过镜像yum源来安装。

直接到源码解压目录下,进行configure ,make && make install
其实memcached安装完成之后,启动服务只是开启了一个键值对的存储空间,并不会计算或缓存任何数据,应用侧需要通过编程来调用该服务,而应用就需要安装client了。
安装完成后,会自动生成三个目录,bin、include和share,需要将bin目录添加到系统的环境变量path中,然后就可以直接执行memcached命令了。在memcached安装过程中,自带了基础文档和命令介绍,通过memcached -h或者是man命令可以查看帮助信息。
当第一次安装完成后启动memcached,需要关注-m、-d和-v参数。
-m:用来设置memcached用来存储数据使用的内存大小,这个大小不受到当前主机的设置的最大内存的限制,所以memcached可能会超额使用一些内存,所以需要设置到一个安全范围,如果设置的值小于64M,则memcached最少使用的大小也是64M。
-d:用来设置memcached以守护进程的形式运行,如果是通过初始化的脚本来运行memcached可能不需要该参数,如果是第一次运行memcached,可以不带该参数,用来观察启动的现象。
-v:用来观察标准输出和标准错误,在大多数情况下,-v都是代表verbose详细信息,如果没有-v只会单纯显示服务启动的信息,如果有-v,则会显示memcached启动请求的详细信息。如果想观察脚本是否按照设定的方案去执行时,可以在前台启动memcached,然后打印出一些信息,来观察。
很多memcached的默认配置都是直接可以使用的,新功能通常是通过非默认属性来设置的。
初始化脚本
如果是通过系统自带的包管理工具安装的memcached,可能已经自带了初始化的脚本,同过可选化的配置启动选项,初始化脚本可以是/etc/sysconfig/memcached文件。在启动之前,需要检查一下初始化脚本,或者写一个自己的初始化脚本。
如果是通过源码编译安装的memcached,那么在解压目录的scripts下,有一些初始化脚本的例子,可以用来参考。

多实例
Memcached的多实例,实际上就是启用不同的监听端口即可。通过-p来指定。
网络
默认情况下,memcached监听的TCP和UDP端口都是11211,-l可以用来绑定指定的端口和地址,memcached并不会有很大的开销,但是如果是用来抵御随机的互联网连接,开销可能会很大,所以不能直接将memcached放在公网上,或者是开放给其他不安全的用户,可以通过SASL认证,但也不是完全可信的。
TCP端口,通过-p可以更改和设置memcached监听的TCP端口,当通过-p设置时,是同时设置了TCP和UDP端口。
-U是用来设置UDP端口的,UDP在用于获取和设置小数据时比较高效,当数据比较大时反而不适合,如果是设置为0,表示不启用UDP端口,这个没有什么影响。
如果只是想通过本地来访问该守护进程,就需要使用-s来制定socket来进行连接,如果启用了该socket属性,TCP/UDP端口将失效。
连接限制
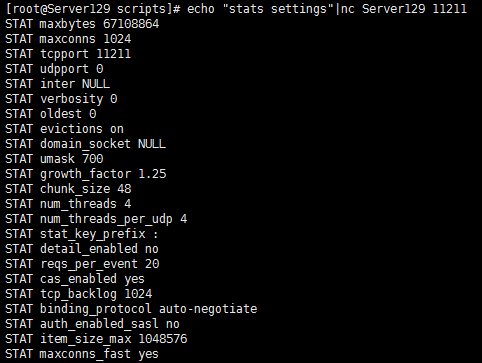
默认情况下,最大连接数为1024,设置正确的最大连接数是很有必要的,超出最大连接数的连接可能需要挂起来等待连接数释放之后才能响应。可以通过status状态命令来查看当前运行的memcached实例是否超出了最大的连接数,如果超出了,会有一个状态位listen_disabled_num,该值应该为0,或者近似于0,如果该值很大,表示最大连接数已经超出,设置可能不合理,需要重新配置。
Memcached的线性扩展连接数很方便,每个连接数消耗的内存容量是很小的(即使该链接是空闲状态),所以不要吝啬设置最大连接数。
假如说现在有5台web应用服务器,每一个上面都运行着一个apache应用,每个apache设置的最大连接数是12,这就意味着整个apache服务的最大连接数为5×12,如果可以,可以设置一个超过60的最大连接数,预留一部分用于管理,或者是添加新的web服务器。
线程
Memcached跨CPU的服务是通过线程来执行的,成为worker 线程,每一个线程都运行着一个一致性的连接,使用libevent使得有良好的扩展能力,每一个线程可以支持多个client。
这个和其他服务器还是有很大不同点的,比如apache服务,apache对于每一个client来说都是一个进程或者一个线程。正因为如此,memcached是非常高效的,设置低线程数也是没有关系的。如果在web服务器领域类比,就好比是nginx和apache相比。
默认值用4线程,除非是想将memcached的性能发挥到极致,才会去将线程设置为高,如果超过80,则会运行缓慢。
当启动了memcached之后,可以通过命令来查看当前memcached的运行设置参数。
memcached -u root -p 11211 -m 64m -d

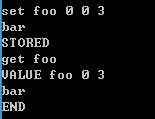
简单使用memcached
启动服务之后,可以通过本地来进行连接了,直接telnet端口。Memcached是一个空的,可以通过先设置键值对,然后再来查看。设置的关键字为set 后面是键,然后输入值。就会存储进memcached中。查询的关键字是get,后面跟键,就能得到值。