

Percona xtrabackup
关于percona xtrabackup
percona xtrabackup是世界上唯一开源的、免费的MySQL热备份软件,可以为InnoDB存储引擎和XtraDB存储引擎进行不间断的备份,使用percona xtrabackup,可以做到以下几点:
- 快速、可靠的备份
- 在备份过程中,不中断正在处理的事物操作
- 节省磁盘空间和网络带宽
- 自动备份确认
- 恢复时间短
percona xtrabackup可以为Percona Server ,MySQL和MariaDB的所有版本进行热备份,甚至可以做基于流的、可压缩的、增量备份。
percona xtrabackup在为Percona Server ,MySQL和MariaDB备份过程中,对InnoDB、XtraDB和HailDB存储引擎,可以做到无中断的备份。在备份MyISAM、Merge和Archive存储引擎时,在备份结束的时候,会短暂的中断写操作。
Percona Server ,MySQL和MariaDB的特点:
- 为InnoDB创建热备份
- 为MySQL做增量备份
- 基于流的压缩,将MySQL备份传输到其他服务器上
- 在MySQL服务器之间,实时在线的移动表格
- 更简单的建立MySQL的主从复制关系
- 备份时,不会给服务器造成压力。
Percona Xtrabackup是基于InnoDB的灾难恢复功能,将InnoDB的数据文件(里面是数据,内部不一致的)拷贝一份,然后执行灾难恢复操作,使得数据文件变成一致,可用的文件。
这个功能能执行的原因,是因为InnoDB维护了一个redo的日志文件,在这个日志文件中保留了每一个对InnoDB数据变更的操作记录,当启动了InnoDB数据库,redo日志文件就会监控数据库文件和事物日志,然后执行两步操作,将committed的事物日志记录,应用到数据文件;如果是那些没有进行committed的事物操作,会执行一个回滚的操作。
Percona Xtrabackup在启动时,会记录日志序列号,也就是LSN,然后将数据文件拷贝走,拷贝是需要花费一定时间,在拷贝的过程中,数据是在变化的,这就反映了数据库在不同时间点的状态。在拷贝的同时,Percona Xtrabackup会在后台运行一个进程,监控事物日志文件,然后拷贝这个事物日志文件,Percona Xtrabackup需要持续的去做这个操作,因为事物日志是以RR的方式写入的,日志空间写满之后,会直接覆盖之前的日志。所以Percona Xtrabackup需要在事物日志开始写的时候,之后的所有日志,这些日志是直接反映了对数据文件的更改操作。
Percona Xtrabackup使用备份锁,类似于flush tables with read lock功能的轻量锁,在Percona Xserver 5.6以后的版本中,都会支持这个功能。Percona Xtrabackup自动的使用这个功能,来拷贝非InnoDB的数据,避免那些请求修改InnoDB table的DML语句的中断。当在备份服务器上启用了备份锁的功能,Percona Xtrabackup会先拷贝InnoDB数据,然后执行lock tables for backup,来拷贝MyISAM表格和表frm文件,当这些操作都我那成之后,数据文件的备份才会开始。Percona Xtrabackup会对.frm, .MRG, .MYD, .MYI,.TRG, .TRN, .ARM, .ARZ, .CSM, .CSV, .par, 和opt文件进行备份。
只有在MyISAM引擎和非InnoDB表上,才会执行锁操作。而且是在Percona Xtrabackup已经完成了所有的InnoDB/XtraDB表的备份之后才会执行。
在这个操作之后,Percona Xtrabackup会执行lock binlog for backup操作,会中断所有的操作,可能会对binlog的position或者是GTID会产生变化,通过show master/slave status可以查看。Percona Xtrabackup会完成对REDO日志的拷贝,然后会获得合适的binlog。当 这些操作都完成之后,Percona Xtrabackup就会释放这个锁。
最后,binlog的位置,会被打印到标准错误输出,然后Percona Xtrabackup会退出运行,如果一切都OK。
标准错误输出,不会写入到任何文件中,可以将这个重定向到某个文件中。
在准备阶段,Percona Xtrabackup不仅仅执行数据拷贝,还会使用拷贝的事物日志,执行灾难恢复操作,当这些操作都已经完成后,数据库就可以恢复和重新使用了。
备份出来的MyISAM和InnoDB表格会和之前的保持完整一致,因为在准备阶段之后,InnoDB数据文件会被回滚到备份完成的时间点,并不是回滚到备份开始的时间点。假如备份开始时间为T1,备份完成时间点为T2,则备份回滚回到的数据库,是T2时间点的数据库文件。这个时间点是和执行flush tables with read lock时间点相同,所以MyISAM和InnoDB数据是同步的。
备份恢复
使用Percona Xtrabackup进行备份恢复,可以使用命令xtrabackup –copy-back 或者是xtrabackup –move-back。执行这个命令的时候Percona Xtrabackup会去读取配置文件my.cnf,来确定该有的变量目录是否存在。
备份恢复会先拷贝MyISAM表、索引等文件,然后会拷贝InnoDB的表,最后才会拷贝日志文件。在拷贝的过程中,会保持原有文件的属性,拷贝完成后,需要更改这些文件的属主为mysql,在启动数据库之前。默认情况下属主是创建这个备份的用户。
Move和copy功能相同,唯一的区别是copy是复制一份备份,而move直接将备份文件移动到目标目录,当磁盘空间不足时,可以使用。
Percona Xtrabackup的安装
Percona Xtrabackup的安装方式有三种:使用仓库源安装(有网)、使用下载的rpm或apt进行安装、使用源码进行编译安装。
Percona Xtrabackup提供了一个yum安装源,这是的安装变得很方便,下载安装的软件版本取决于操作系统的包管理工具,这是推荐的安装方式。
RPM安装包内容:
- percona-xtrabackup-24中包含了最新的percona-xtrabackup-24 GA二进制文件和相关文件
- percona-xtrabackup-24-debuginfo中包含了debug工具
- percona-xtrabackup中包含了最新的percona-xtrabackup版本软件
1、使用源码编译安装的先决条件:
yum install cmake gcc gcc-c++ libaio libaio-devel automake autoconf \
bison libtool ncurses-devel libgcrypt-devel libev-devel libcurl-devel \
vim-common
2、下载安装包percona-xtrabackup-2.4.12.tar.gz,上传至服务器中,解压。
3、开始进行编译安装
默认安装目录是/usr/local/xtrabackup目录下,建议可以不用更改。如果要更改,可以在cmake阶段修改或者make install的时候指定目录。
cmake -DBUILD_CONFIG=xtrabackup_release -DWITH_MAN_PAGES=OFF -DWITH_BOOST=/usr/local/boost
和源码编译安装mysql一样,需要指定boost目录
编译报错:Could not find libev on your system
下载libev文件,然后正常解压安装即可。http://dist.schmorp.de/libev/国外的网站,打开很慢。
如果下载不下来,可以直接用二进制进行安装。
yum localinstall percona-xtrabackup-24-2.4.12-1.el6.x86_64.rpm
安装完成后,通过xtrabackup –help,如果能出现帮助,证明安装成功。
连接数据库
Percona XtraBackup需要能够连接到数据库服务器上,然后又能够操作服务器的权限。这就涉及到权限的问题。专门指定一个系统用户,然后使用该用户来连接数据库。
Xtrabackup可以用来远程连接,主要参数有—user –password –port –host –socket,--socket是用来连接本地数据库。
用户要求的数据库权限,RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT。需要这些权限。
在数据库中创建用户,赋予这些权限:
GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'backupuser'on'%' identified by '123456';
备份参数
所有的xtrabackup的配置,都是通过参数选项来控制的,和标准的MySQL程序一样,可以通过数据库的配置文件来控制,也可以在执行的时候通过命令执行。
Xtrabackup从配置文件的[mysqld]和[xtrabackup]部分读取,可以从已经存在的安装文件中获取,读取数据库的datadir和一些InnoDB选项。如果想改写这部分,可以在[xtrabackup]中重新定义,因为是有先后的读顺序,所以是后生效。
如果不想在my.cnf中进行配置,可以在执行备份的时候通过命令行进行输入。通常情况下,有一件事情,是需要写入到配置文件中的,也就是备份文件存放的目录target_dir。
全备份脚本
创建备份,通过xtrabackup –backup选项,来进行备份操作,必须要制定备份的目标路径,用来存放备份文件。如果不想把InnoDB数据文件或者是日志文件存放在相同的目录,可以指定这些属性。如果目标路径不存在,xtrabackup会自动创建该目录;如果目录存在且为空,则备份会成功,如果目录存在,但不为空,则会报错,error 17
比如在生产的某一个库上进行备份,具体的命令如下:
xtrabackup --defaults-file=/usr/local/mysql/mysqldata/data2/my.cnf --backup --user=root --password=***** --socket=/usr/local/mysql/mysqldata/data2/mysql.sock --target-dir=/usr/local/mysql/mysqldata/databak/`date +%F`/data2 1>/tmp/xtrabackup-log2 2>&1
在正常情况下,defaults-file参数必须要放在第一个,指定数据库的配置文件,登录信息和正常登录mysql的是一样的,后面指定备份出来的目录即可。整个备份会打出一个详细的日志信息,备份过程中,日志拷贝线程,每秒钟会检查一次事物日志文件,查看是否有新的日志写入,需要拷贝。但是在这个地方会有一个问题,日志的复制线程,可能无法和事物日志的写入保持同步,这就会出现一个错误,当事物日志已经被修改了,则日志拷贝线程就无法完成复制了。
打印输出时,能看到日志拷贝线程的情况。
备份时间的长短,取决于数据库的大小,在备份过程中,可以随时的取消,不会对数据库产生任何影响。
基于现有的备份,进行恢复,备份准备prepare
通过xtrabackup –backup备份出来的备份文件,可以用来恢复数据库。数据在没有准备好之前,是不一致的,因为拷贝是在不同时间点进行的,在拷贝完成后,数据有可能发生了变化。如果使用这些数据文件启动了数据库,数据库会检测到中断,然后自己停止,不允许在有错误的数据上进行启动。Xtrabackup –prepare就是用来将数据文件恢复到一致性上,然后就可以利用这些数据文件,启动数据可怜。
准备操作,可以在任何机器上运行,并不一定是备份的机器上,可以将备份拷贝到其他机器上,然后在其他机器上进行还原恢复操作。
使用Percona XtraBackup旧版本备份出来的数据,可以用新版本进行准备,但如果是用新版本备份的,用旧版本就无法保证了。但是新版本要支持旧数据库的版本。需要根据Percona XtraBackup的版本支持来选择。
在数据准备的过程中,Percona XtraBackup会启动一种内置的、优化的InnoDB引擎,这种修改之后的InnoDB引擎会禁止标准引擎的安全检查,比如日志文件大小是否对应等。
在准备阶段使用这种内置的集成InnoDB 引擎,会通过拷贝的日志文件,在这些拷贝的数据文件上执行一次灾难恢复的操作。准备操作很简单,直接xtrabackup –prepare就可以,然后后面要接上备份生产的目录,对那个目录的备份进行准备。
xtrabackup --prepare --target-dir=/data/backups/
准备工作完成后,会看到一个停止InnoDB引擎的日志。
在准备过程中,不建议停止该操作,应该在准备过程中,数据是在不断变化的。如果中断,该备份会变得不可用。
如果打算将备份作为以后增量备份的基础,在备份准备阶段,需要执行—apply-log-only,如果没有改参数,则不能那个在该本分上面进行增量。
备份恢复
直接使用xtrabackup –copy-back –target-dir 会从备份目录中,将数据库拷贝到配置文件中定义的datadir下,然后开始进行恢复。如果不想保留该备份,可以使用move-back。如果不想使用以上两个参数,可以通过rsync或者是cp进行拷贝。
恢复时,目标datadir必须是一个空的,在恢复前,数据库服务器必须关停。
备份恢复回来的文件,必须要保证用户属主和属组的正确,mysql
所有文件属性都必须要保留,在开启数据库之前,需要修改文件属主和数组信息。
增量备份incremental backup
Xtrabackup和innobackupex都支持增量备份,增量备份意味着可以基于前一次的备份,只拷贝有变化的数据部分。
在每一个全备份之后,可以做多次增量备份,比如每周做一次全量备份,然后每天在每周的基础上做一次增量备份。或者是每天全量备份一次,每小时增量备份一次。
增量备份之所以能够执行是因为InnoDB的页面中,包含了一个日志序列号,也就是LSN,LSN就是整个数据库的系统版本号,每一个页面的LSN就反应了数据库的变化。
每一个增量备份,都拷贝了基于前一次备份(全量备份或者是增量备份),更新的LSN页面。在查找这些更新的页面上,有两种算法,第一种,在所有的服务器版本和类型中都可用的,就是直接读取所有的数据页面,然后检查所有的页面LSN;第二种只适用于percona server,在服务器上启用变更页面跟踪技术,会直接将变更过的页面标注出来,这些信息稍后会被写入到一个单独的位图文件中,xtrabackup会使用该位图文件,来读取那些需要用与增量备份的数据页,减少了很多读请求。如果xtrabackup能找到这个位图文件,会自动启用第二中算法,可以通过命令xtrabackup –incremental-force-scan来读取所有的数据页,不论位图数据是否存在。
增量备份,并不会真的去拿现有数据和之前备份数据对比,实际上,可以通过xtrabackup –incremental-lsn命令,在知道备份的LSN的情况下,直接进行增量备份,即使没有之前的备份。增量备份会直接拿数据页的LSN和最后一次备份的LSN进行对比,如果是要恢复这些增量备份,还是需要一个全量的备份,如果没有一个全量备份作为基础,这些增量备份也就是没有任何作用。
创建一个增量备份
增量备份,通常是基于全量备份开始的,xtrabackup会在备份目标目录中,写一个名为xtrabckup_checkpoints的文件,在这个文件中会有一行为to_LSN,该LSN为备份结束时的数据库LSN。
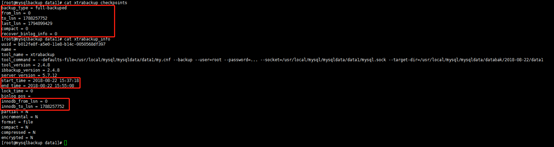
在xtrabackup生成的checkpoints和info文件中,能表明起始LSN和结束LSN。
如果已经有了一个完整备份,可以在这个完整备份的基础上,做一个增量备份,需要添加一个参数为increamental-basedir,完整备份,就是该basedir。具体命令为:xtrabackup –backup –target-dir=D1--incremental-basedir=D2
当执行完该命令之后,在D1中会生成再续文件,比如ibdata1.delta,delta就是再续文件。这些再续文件,体现了基于上次LSN之后的数据变化,可以通过增量备份的checkpoints文件,来查看from_lsn和to_lsn,from_lsn是增量备份开始的起始,应该和上一个备份的to_lsn相同。
基于这个增量备份,还可以做增量备份,只要在incremental-basedir参数后面指定该增量备份的目录即可。下一个增量备份的from_lsn就是该增量的to_lsn。
如果在checkpoints中last_lsn和to_lsn不同,这就意味着在备份过程中,数据库发生过变更,在恢复时需要做prepare工作。
增量备份的prepare
增量备份的prepare和普通全量备份的prepare是不同的,在全量备份的prepare中,有两种方法,都是用来使得数据库变得一致,通过对比日志文件和数据文件,将提交了的事物在重演,将未提交的事物回滚。而在增量备份恢复prepare中,不能执行未提交的事物回滚操作,因为在备份时间点未提交的事物可能是在途,有可能在下一次增量备份的时候提交,所以在增量备份的prepare的时候,必须使用命令来阻止回滚阶段xtrabackup –apply-log-only。
如果不是用该参数,增量备份的恢复将不可用。当事物都被回滚之后,之后的增量备份都无法提交。
如果是使用全量备份作为恢复,可以先prepare之后,然后将增量备份也附加在上面,需要调用全量备份的目录和增量备份的目录。
但是在做prepare的时候,对于全量备份的prepare,也要指定参数apply-log-only,对于增量备份的恢复,要制定incremental-dir和target-dir,其中所有的target-dir都是全量备份的目录,incremental-dir是增量备份的目录。备份prepare完成之后,会出现一个LSN,这个LSN和备份结束时出现的LSN是相同的。
如果在全量备份恢复的时候,使用了该apply-log-only,然后启动了数据库,这个时候数据库会检测到回滚阶段没有执行,然后数据库会在后台执行这个操作,就好比数据库是意外宕机一样进行恢复,同时还会给出一个提示,数据库没有正常关闭。
通过增量备份进行恢复的时候,是将 增量备份中的再续文件,应用到之前的备份上,之前的备份可以回滚到增量备份完成的时候。同时对重演日志进行操作,最后在target目录下的文件就会变更,并不是在增量备份的目录下变更。相同的,LSN应该和前一次增量备份的结果相同。然后整个数据库就会恢复到增量备份的时候。
当在进行最后一次增量数据备份恢复时,不应该再使用apply-log-only参数,最后一次备份恢复,就是恢复到最后一次备份时间点,应该回滚的事物要执行回滚操作。如果在最后一次增量备份恢复的时候,使用了该参数,数据库文件还是一致的,只不过在启动之后,会执行数据回滚操作。
在对数据库执行的第一次增量备份操作,和全量备份操作一样,备份恢复也是一样的。
压缩备份
Percona xtrabackup支持压缩备份,可以通过xbstream进行本地或者基于流的备份压缩和解压。
使用参数—compress创建压缩备份。如果想提高压缩速度,可以启用并行的压缩方式,通过使用参数—compress-threads指定压缩线程数量,来进行压缩。
在备份准备阶段,需要对压缩文件进行解压操作,解压操作的参数是—decompress。在处理之前,需要保证,系统已经安装了qpress软件,可以通过仓库来获得。
使用参数—parallel可以同时解压不同的文件,并行。
Percona xtrabackup不会自动的删除压缩文件,如果想在解压缩完成后删除该文件,可以使用参数—remove-original。即使这些压缩文件不删除,在恢复的时候,也不会移动或者拷贝到target-dir下。
Xtrabackup –decompress –target-dir=
对target下的压缩文件进行解压缩
当完成解压缩之后,就可以进行prepare了。这个操作和全备份的prepared是一样的。准备完成之后的数据,就可以直接用了。
备份恢复
通过参数—copy-back,将备份还原得到目标数据的datadir下,需要指定备份的目录,也就是target-dir。执行这个操作,会根据配置文件my.cnf,将相关文件,拷贝至datadir目录下,当恢复完成后,会提示成功。对拷贝回来到datadir目录下的文件,需要修改文件的权限,然后才能进行启动。
Xtrabackup –copy-back –target-dir=*******
关于加密的部门,可以参考使用手册。
Innobackupex备份工具
Innobackupex备份工具是xtrabackup备份工具的符号链接,可以通过该工具,配合备份方案,对InnoDB/xtraDB、MyISAM表或其他服务器进行实时的备份。早期的innobackupex是用perl脚本编写的。
官方手册不建议使用innobackupex。

完整备份full backup
Innobackupex可以为对整个MySQL数据库进行备份,功能和xtrabckup结合xbstream/xbcrypt相同。
通过innobackupex创建完整备份,只需要在连接数据库的基础上,增加一个参数,也就是备份存放的目录即可。命令格式如下:innobackupex –user= --password= **** /tmp/backup/。
在备份输出信息中最后会显示完成。备份会生成一个目录,该目录的名字会以时间戳的形式命名。
Innobackup会调用xtrabackup对所有的InnoDB表格进行备份,然后将建表语句.frm文件、和MyISAM相关的数据和文件等等一系列文件,拷贝到以时间戳命名的目录下。可以通过参数—no-timestamp,不在备份目录下生成时间戳命名的目录,如果在备份目录下指定了一个不存在的目录,innobackupex会自动创建该目录,如果该目录存在,备份会失败。
在xtrabackup和innobackupex中,都可以指定配置文件的目录位置,但是必须要把该参数放在第一位。
准备完整备份
在创建了完整备份之后,这些备份数据实际上是不能立即被恢复使用的,因为日志中可能会存在一些未提交的事物,需要回滚,同时有些已经提交的事物需要重演。这个操作过程是为了保持数据的一致性,也就是准备阶段,当完成了数据准备阶段之后,这个数据就可以用来恢复了。
在innobackupex中准备阶段,命令格式和xtrabackup不同,innobackupex –apply-log ****,在参数后面,直接写上备份的全路径。在准备完成后,也会打印LSN。
整个准备阶段,innobackupex会读取备份目录下的backup-my.cnf文件,然后会根据日志文件,对指定的事物进行重演或者回滚,当这些操作都完成后,表空间中的所有数据和日志文件都将会被重建。实际上就是调用了xtrabackup –prepare两次。
这个准备操作,对增量备份来说,是不适用的。如果是对增量备份恢复的基础备份进行操作,不能增加增量部分。
使用参数—use-memory,在提高准备阶段的效率,这个参数取决于机器的内存,默认是100MB,通常情况下,内存越多,处理越快。例如—use-memory=4G.
完整备份恢复
Innobackupex也有一个参数,--copy-back,用来将备份恢复到数据库的datadir目录下。Innobackupex –copy-back ********后面直接跟上备份的路径即可。这个操作,会将相关文件拷贝到datadir下,也是根据服务器的配置文件来进行拷贝操作。
默认情况下,datadir目录必须是空的,除非制定了—force-non-empty-directories属性。在恢复之前,需要关闭数据库。
同理,在恢复的时候,需要修改数据库文件的属主和属组信息。
使用innobackupex进行增量备份。
如果在每个备份之间,数据变化不大,可以通过增量备份策略,来减少磁盘空间占用和备份时间。这个增量备份的原理和xtrabackup是一样的。使用innobackupex做增量备份,前提也是得有一个完整备份。做增量备份时,要制定该完整备份。命令格式为:innobackupex –incremental ****D1 --incremental-basedir=****D2。完整备份存放在D2目录下,然后会在D1目录下自动生成一个以时间戳命名的目录,存放增量备份文件。
在增量的基础上,继续做增量,和这个方法类似。
这种增量,只会对InnoDB/xtraDB生效,对于其他存储引擎,还是会执行全量拷贝。
增量恢复prepare
增量备份的prepare,和全量备份的prepare有很大的不同。和xtrabackup类似,有一个参数—redo-only。具体命令为innobackupex –apply-log –redo-only BASE-DIR –incremental-dir=****。这个操作之后,BASEDIR目录下的数据,就是第一次增量完成社会的数据库状态,
Redo-only在增量恢复中,除了最后一次不需要,其他社会都需要,和xtrabackup中的apply-log-only相同。如果最后一次也使用了该参数,数据库起来之后要执行一次回滚操作。
可以同时在一个全量上,增加多个增量,这些增量目录的顺序,取决于备份时候的顺序。如果增量恢复的顺序不对,这些数据都将不可用。可以通过每次备份的checkpoints来判断备份的顺序。
在innobackupex中,不会自动产生iblog文件,只有在xtrabackup中使用—prepare才会产生。
增量恢复
对增量备份进行prepare之后,base目录中的数据就是一个可以用的数据库文件,可以通过命令innobackupex –copy-back BASE,将base目录下的文件拷贝纸datadir目录下进行恢复使用。
部分备份
Percona xtrabackup支持部分备份功能,也就是对指定的表或者是数据库进行备份。需要备份的表,必须要有独立的表空间,也就是说必须要在配置文件中设定一个参数innodb_file_per_table,每一个表一个单独的数据文件。
使用部分备份,有一个唯一的警告,就是不要直接将prepared的部分备份直接copy-back,这部分备份只能通过表的导入import,虽然有些场景是可以直接copy-back,但是会造成数据库的不一致,所以不推荐。
有三种方式来做部分备份:1、常规的—include参数;2、在一个文件中将所有需要备份的表枚举出来,使用—tables-file参数;3、使用—databases参数,列出所有要备份的数据库名称。
使用—include参数,会在数据库中进行全名称比对,格式为库名.表名,例如—include='mydatabase[.]mytable',就是包含mydatabse库中的mytable表。在做部分备份的时候,跟普通备份一样,会创建一个以时间戳命名的目录,但是只会将相关的表拷贝过去。实际上,这个命令会传递到xtrabackup –tables进行执行,会将表格和每一个数据库里面进行比对,每一个数据库目录都会被创建,及时不复制里面的表。
使用—tables-file参数,将多个表的名字,放在一个text文件中,每一行显示一个表,以库名.表名的方式。然后在备份的时候,指定该text文件。这个功能和xtrabckup –tables-file相同,只会创建那些匹配上的表的数据库目录。
使用—databases参数,这个参数支持用空格分隔的表名输入,或者是一个表名文件,也就是同时可以支持—include和—tables-file。
Prepare部分备份
Prepare部分备份,就好比是重新恢复单独的表,通过—export参数,将日志应用到备份上。在操作的过程中,可能会看到很多错误输出,显示表格不存在,这是因为基于InnoDB的存储引擎是将数据字典存放在frm文件中,innobackupex会调用xtrabackup在数据字典中去删除这些不存在的表,也就是备份时没有选择的表,避免此错误信息的再次出现。
命令格式为:innobackupex –apply-log –export ****后面是部分备份的路径
恢复部分备份
恢复过程,和在一个数据库中恢复单个表的过程相同,直接将数据文件,拷贝至服务器的datadir目录下。
压缩备份
在备份InnoDB表时,可以忽略二级索引文件,这样备份出来数据,会占用较少的磁盘空间,缺点是在prepare阶段,需要花费的时间更长,因为需要重建二级索引文件。备份压缩的大小取决于二级索引文件的大小。
使用—compact参数,就是去忽略二级索引,但是必须是每个表一个单独的表空间,也就是一个独立文件。
使用了compact参数之后,会在checkpoint文件中有显示compact=1,默认不使用为0,通过这个参数,可以判断备份中是否包含二级索引。
压缩备份prepare
在prepare压缩备份的时候,需要重建索引,所以需要搭配参数使用,具体命令格式为innobackupex –apply-log –rebuild-indexes ***。在输出方面,出了有标准的innobackupex数据,应该也会包含索引重建的信息。
在恢复全量备份的基础上,增加恢复增量备份,索引信息也需要重建,当全量备份和所有的增量备份都已经准备恢复时,这个时候才去重建这些索引信息,因为重建索引需要很长时间。
压缩备份恢复,也是通过copy-back参数来实现。
在主从复制环境中的备份
在主从复制环境中,使用percona进行备份,有几个特殊的参数。
--slave-info参数,当在slave上进行备份时,这个参数很有用,这个参数会打印master服务器的名称和日志位置,然后会将这些信息写入到一个名为xtrabackup_slave_info的文件中,是一个change master的语句。这种方式,能够快速的根据文件中的信息和备份文件,创建一个新的slave。
--safe-slave-backup属性,为保证一个一致性的复制状态,这个参数会停止slave上面的SQL线程,直到show status中的slave-open-temp-tables值为0时,才会启动备份操作。当数据库没有打开临时表时,开会开始备份工作,也就是说SQL线程只有在没有打开任何临时表的时候,才会打开或者关闭。当使用了该属性,如果在--safe-slave-backup-timeout默认为300秒后,临时表打开数量依然不为0 ,则备份会失败。SQL线程在备份结束后,会重启。
在通过slave主机进行备份时,通常建议使用该参数。
加快备份速度
通过并行拷贝和压缩线程数量
当进行本地备份或者是通过xbstream参数执行流备份时,可以通过—parallel并行参数,同时拷贝多个文件,这个参数可以用来设定xtrabackup用于拷贝的线程数量。
这个特性是基于文件级别的,在高碎片数据文件的数据库上做备份时,并行文件传输会增加IO读写,因为重叠了大量的随机读请求。如果数据文件只存储在一个文件中,这个参数就无效了。
使用这个参数的命令格式为:innobackup –parallel=4 ***启用4个线程进行备份工作。
在基于流的备份中,可以使用压缩线程参数,来提高压缩的速度,默认压缩线程数为1.
命令格式为:innobackupex –stream=xbstream –compress –compress-thread=4 ***。使用4个线程来做并行压缩。
