Introducing the kafka producer
Introduction
As we saw in the previous sections, I think we have some basic information about the kafka producers, today, let me dig in this concept.
Kafka producers are going to write data to topics are made of partitions, now the producers in kafka will automatically know to which broker and partition to write on your message and in case there is a kafka broker failure in your cluster the producers will automatically recover from it which makes kafka resilient and which makes kafka so good and used today, So if we look at a diagram to have the data in our topic partitions we are going have a producer on the left-hand side sending data into each of partitions of our topics.

So, how dose a producer know how to send the data to a topic partition, by default, producers will evenly balance messages to all of the partitions of our topic, in some cases, producers can direct messages to specific partitions, and you need to generate and control the message key , it is a hash key and can map it to specific partition, because this ensures that all messages produced with a given key will get written to the same partition. so , let me start to how to constructing a kafka producer.
Constructing a kafka producer
The first step in writing messages to kafka is to create a producer object with the properties you want to pass to the producer. A kafka producer has three mandatory properties.
bootstrap.servers : List of host:port pairs of brokers that the producer will use to establish inital connection to the kafka cluster, this list does not need to include all brokers, since the producer will get more information after the initial connection. But it is recommended to include at least two, so in case one broker goes down, the producer will be able to connect to the cluster, on the other hand, we need to take care with the order of the lists, usually, the producers will use the first pair of those brokers, if we have many producers, we need to balance the load.
key.serializer: name of a class that will be used to serialize the keys of the records we will produce to kafka ,kafka brokers expect byte arrays as keys and values of messages, however, the producer interface allows, using parameterized types , any Java object to be sent as a key and value. This make for very readable code, but it also means that the producer has to know how to convert these objects to byte arrays.key.serializer should be set to a name of a class that implements the org.apache.kafka.common.serialization.Serializer interface, the producer will use this class to serialize the key object to a byte array. the kafka client package includes other different Serializers interface , and much more , so if you use common types, there is no need to implement your own serializers, setting key.serializer is required even if you intend to send only values.
value.serializer: name of a class that will be used to serialize the values of the records we will produce to kafka, the name way you set key.serializer to a name of a class that will serialize the message key object to a byte array, you set value.serializer to a class that will serialize the message value object.
the following code snippet shows how to create a new producer by setting just the mandatory parameters and using defaults for everything else:
1 private Properties producerTest(){ 2 Properties kafkaPro = new Properties(); 3 kafkaPro.put("bootstrap.servers","broker1:9092,broker2:9092"); 4 kafkaPro.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 5 kafkaPro.put("valuse.serializer","org.apache.kafka.common.serialization.StringSerializer"); 6 return kafkaPro; 7 } 8 public void sendMes(){ 9 KafkaProducer producer = new KafkaProducer<String,String>(producerTest()); 10 ProducerRecord<String,String> record= 11 new ProducerRecord<String,String>("topic","test1"); 12 producer.send(record); 13 }
- The second line, we actually start with a Properties object.
- The fourth line ,Since we plan on using strings for message key and value, we use the built-in StringSerializer.
- The ninth line, here we create a new producer by setting the appropriate key and value types and passing the Properties object.
with such a simple interface, it is clear that most of control over producer behavior is done by setting the correct configuration properties, apache kafka documentation covers all the configuration options, and we will go over the important ones later in this blog.
Once we instantiate a producer, it is time to start sending messages, There are three primary methods of sendings of messages.
fire-and-forget: we send a message to the server and do not really care if it arrives sucessfully or not, Most of the time, it will arrive sucessfully, since kafka is highly available and the producer will retry sending messages automatically . however, in case of nonretriable errors or timeout, messages will get lost and the application will not get any information or exceptions about this.
synchronous send: Technically, kafka producer is always asynchronous--we send a message and the send() method returns a Future object, However , we use get() to wait on the Future and see if the send() was sucessful or not before sending the next record.
asynchronous send: we call the send() method with a callback function, which gets triggered when it receives a response from the kafka broker.
In the examples that follows, we will see how to send messages using these methods and how to handle the different types of errors that might occur.
Sending a message to kafka
The simplest way to send a message is as follows:
1 public void sendMes(){ 2 KafkaProducer producer = new KafkaProducer<String,String>(producerTest()); 3 ProducerRecord<String,String> record= 4 new ProducerRecord<String,String>("topic","test1"); 5 try { 6 producer.send(record); 7 } catch (Exception e){ 8 e.printStackTrace(); 9 } 10 }
- The first line means the producer accepts ProducerRecord objects, so we start by creating one, ProducerRecord has multiple constructors, which we will discuss later, here we use one that requirs the name of the topic we are sending data to, which is always a string, and the key and value we are sending to kafka , which in this case are also strings. The types of key and value must match our key serializer and value serializer objects.
- The six line,We use the producer object send() method to send the ProducerRecord. as we've been in the producer architecture diagram, the message will be placed in a buffer and will be sent to the broker in a separate thread, The send() method returns a Java Future object with RecordMetadata, but since we simply ignore returned value, we have no way of knowing whether the messages was send sucessfully or not, this method of sending messages can be used when dropping a message silently is acceptable, this is not typically the case in production applications.
- The eight line, while we ignore errors that may occur while sending messages to kafka brokers or in the brokers themselves, we may still get an exception if the producer encounter errors befor sending the message to kafka, those can be , for example, a SerializationException when it fails to serialize the message, a bufferExhaustedException or TimeoutException if the buffer is full, or an InterruptException if the sending thread was interrupted.
So ,how to send a mesage synchronously, sending a message synchronously is simple but still allows the producer to catch exceptions when kafka responds to the produce request with an error, or when send retries were exhausted, The main trade-off involved is performance, Depending how busy the kafka cluster is, brokers can take anywhere from 2 ms to a few seconds to respond to produce requests, if you send messages synchronously, the sending thread will spend this time waiting and doing nothing else, not even sending additional messages, this leads to very poor performance, and as a result, synchronous sends are usually not used in production applications (but are very common in code example).
The simplest way to send a message synchronously is as follows:
1 public void sendMes(){ 2 KafkaProducer producer = new KafkaProducer<String,String>(producerTest()); 3 ProducerRecord<String,String> record= 4 new ProducerRecord<String,String>("topic","test1"); 5 try { 6 producer.send(record).get(); 7 } catch (Exception e){ 8 e.printStackTrace(); 9 } 10 }
- Please see the line six,here, we are using Future.get() to wait for a replay from kafka, this method will throw an exception if the record is not sent sucessfully to kafka, if there were no errors , we will get a RecordMatedata object that we can use to retrieve the offset the message was written to and other metadata.
- The line 8, if we were any errors before or while sending the record to kafka , we will encounter an exception , In this case, we just print any exception we ran into.
kafkaProducer has two types of errors , Retriable errors are those that can be resolved by sending the message again . for example ,a connection error can be resolved because the connection may get reestablished, a "not leader for partition" error can be resolved when a new leader is elected for the partition and the client metadata is refreshed, kafkaProducer can be configured to retry those errors automatically , so the application code will get retriable exceptions only when the numebr of retries was exhausted and the error was not resolved, some errors will not be resolved by retrying, for example, "message size too large", in those cases, kafkaProducer will not attempt a retry and will return the exception immediately.
And, how to send message asynchronously, suppose the network round-trip time between our application and the kafka cluster is 10ms, if we wait for a reply after sending each message, sending 100 messages will take around 1 second, on the other hand, if we just send all our messages and not wait for any replies, then sending 100 messages will barely any time at all, In most cases, we really don't need a reply, kafka send back the topic ,partition, and offset of record after it was written, which is usually not required by sending app, on the other hand, we do need to know when we failed to send a message completely so we can throw an exception , log an error, or perhaps write the message to an errors file for later analysis.
To send messages asynchronously and still handle error scenarios, the producer supports adding a callback when sending a record, here is an example of how we use a callback:
1 public void sendMes(){ 2 KafkaProducer producer = new KafkaProducer<String,String>(producerTest()); 3 ProducerRecord<String,String> record= 4 new ProducerRecord<String,String>("topic","test1"); 5 try { 6 producer.send(record,new DemoProducerCallback()); 7 } catch (Exception e){ 8 e.printStackTrace(); 9 } 10 } 11 private class DemoProducerCallback implements Callback{ 12 @Override 13 public void onCompletion(RecordMetadata recordMetadata,Exception e){ 14 if(e != null){ 15 e.printStackTrace(); 16 } 17 } 18 }
- please see line 11,to use callbacks, you need a class that implements the Callback interface. which has a single function--On Completion().
- The line 15, if the kafka returned an error, onCompletion() will have a nonull exception, which means it won't get any feedback until an error is happening, here we "handle" it by printing, but production code will probably have more robust error handling functions.
- The line 6 means we pass a callback object along when the record.
The callbacks execute in the producer's main thread, This guarantees that when we send two messages to the same partition one after another, their callbacks will be executed in the same order that we sent them, But it also means that the callback should be reasonably fast to avoid delaying the producer and preventing other messages from being sent, it is not recommended to perform a blocking operation within the callback, instand, you should use another thread to perform any blocking operation concurrently.
Configuring ClientId and acks
So far we've seen very few configuration parameters for the producers , just the mandatory bootstrap.servers, URI, and serializers.
The producer has a large number of configuration parameters that are documented in apache kafka documentation, and many have resonable defaults, so there is no reason to tinker with every single parameter, however, some of parameters have a significant impact on memory use, performance, and reliability of the producers, we will review those here.
client.id: client.id is a logical identifier for the client and the application it is used in, This can be any string and will be used by the brokers to identify messages sent from the client, It is used in logging and metrics and for quotas, Choosing a good client name will make troubleshooting much easier, it is the difference between "we are seeing a high rate of authentication failures from IP 104.6.2.2" and "look like the Order Validation service is failing to authenticate, can you ask laura to take a look?"
acks : acknowledgement, the acks parameter controls how many partition replicas must receive the record before the producer can consider the write sucessful, by default, kafka will respond that the record was written sucessfully after the leader received the record , this option has a significant impact on the durability of written messages, and depending on your use case, the default may not be the best choice, now let us look at the three allowed values for the acks paramter:
ack=0: the producer will not wait for a reply from the broker before assuming the messages was sent sucessfully , this means that if something goes wrong and the broker dose not receive the message, the producer will not know about it, and the message will be lost, however , because the producer is not waiting for any response from the server, it can send messages as fast as the network will support, so this setting can be used to achieve very high throughput.
ack=1: the producer will receive a success response from the broker the moment the leader replica receives the message. if the message can't be written to the leader(if the leader crashed and a new leader was not elected yet), the producer will receive an error response and can retry sending the message, avoiding potential loss of data, the message can still get lost if the leader crashed and the latest messages were not yet replicated to the new leader.
ack=all: the producer will receive a success response from the broker once all in sync replicas receive the message , this is the safest mode since you can make sure more than one broker has the message and that the message will survive even in case of a crash. however , the latency we discussed in the ack=1 case will be even higher, since we will be waiting for more than one broker to receive the message.
you will see that with lower and less reliable acks configuration, the producer will be able to send records faster, this means that you trade off reliability for producer latency, however, end-to-end latency is measured from the time a record was producerd until it is available for consumers to read and is identical for all three options, the reason is that, in order to maintain consistency, kafka will not allow consumers to read records until they are written to all in sync replicas. Therefor , if you care about end-to-end latency, rather than just the producer latency, there is no trade off to make, you will get the same end-to-end latency if you choose the most reliable option.
Configuring Message Delivery Time
The producer has multiple configuration parameters that interact to contrl one of the behaviors that are of most interest to developers:how long will it take until a call to send() will succeed or fail, this is the time we are willing to spend until kafka responds successfully, or until we are willing to give up and admit defeat.
The configurations and their behaviors were modified serveral times over the years, we will describe here the latest implementation , introduced in Apache Kafka 2.1.
since apache kafka 2.1, we divide the time spent sending a ProduceRecord into two time intervals that are handled separately:
- Time until an async call to send() returns, During this interval, the thread that called send() will be blocked.
- From the time an async call to send() returned successfully until the callback is triggered(with success or failure), this is the same as from the point a ProduceRecord was placed in a batch for sending until kafka responds with success, nonretriable, or we run out of time allocated for sending.
the flow of data within the producer and how the different configuration parameters affect each other can be summarized in the figure below .
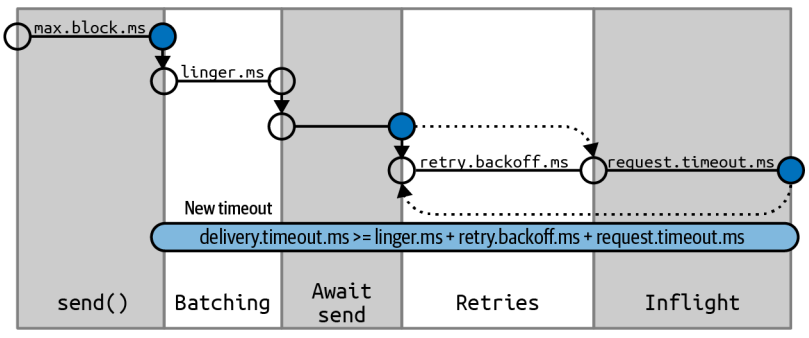
we'll go through the different configuration parameters used to control the time spent waiting in these two intervals and how they interact.
max.block.ms: this parameter controls how long the producer may block when calling send() and when explicitly metadata via partitionFor(), those methods may be block when the producer's send buffer is full or when metadata is not available, when max.block.ms is reached, a timeout exception is thrown.
delivery.timeout.ms : this configuration will limit the amount of time spent from the point a record is ready for sending(send() returned successfully and the record is placed in a batch) until either the broker responds or the client gives up, including time spent on retries, as you can see in the figure above, this time should be greater than linger.ms and request.timeout.ms , if you try to create a producer with an inconsistent timeout configuration, you will get an exception, messages can be successfully sent much faster than delivery.timeout.ms, and typically will.
If the producer exceeds delivery.timeout.ms while retrying, the callback will be called with the exception that corresponds to the error that the broker returned before retrying, if delivery.ms is exceeded while the record batch was still waiting to be sent , the callback will be called with a timeout exception.
you can configure the delivery timeout to the maximum time you will want to wait for a message to be sent. typically a few minutes, and then leave the default number of retries, with this configuration , the producer will keep retrying for as long as it has time to keep trying (or until it successed), this is a much more reasonable way to think about retries,our normal process for tuning retries is: " in case of a broker crash, it typically takes leader election 30 seconds to complete, so let's keep retrying for 120 seconds just to be on the safe side." Instead of converting this mental dialog to number of retries and time between retries, you just configure delivery.timeout.ms to 120.
request.timeout.ms : this parameter controls how long the producer will wait for a reply from the server when sending data, note that this is the time spend waiting on each producer request before giving up; it dose not include retries, time spend before sending, and so on,if the timeout is reached without reply, the producer will either retry sending or complete the callback with a TimeoutException.
retries and retry.backoff.ms : when the producer receives an error message from the server, the error could be transient(e.g. , a lack of leader for a partition), in this case , the value of the retries parameter will control how many times the producer will retry sending the message before giving up and notifying the client of an issue, By default, the producer will wait 100 ms between retries, but you can control this using the retry.backoff.ms parameter.
we recommend against using these paramters in the current version of kafka. instead, test how long it takes to recover from a crashed broker(i.e., how long until all partitions get new leaders), and set delivery.timeout.ms such that the total amount of time spent retrying will be longer than the time it takes the kafka cluster to recover from the crash---otherwise, the producer will give up too soon.
Not all errors will be retried by the producer, some errors are not transient and will not cause retries(e.g. , "message too large" error), In general, because the producer handles retries for you, there is no point in handling retries within your own application logic, you will want to focus your effort on handling nonretriable errors or case where retry attempts were exhausted.
linger.ms: linger.ms controls the amount of time to wait for additional messages before sending the current bath, kafkaProducer sends a batch of messages either when the current batch is full or when the linger.ms limit is reached. By default, ther producer will send messages as soon as there is a sender available to send them. even if there's just one message in the batch, By setting linger.ms higher than 0, we instruct the producer to wait a few milliseconds to add additional messages to the batch before sending it to the brokers . this increase latency a little and significantly increase throughput---the overhead per message is much lower, and compression, if enable, is much better.
Conclusion
I think we know many configuration parameters about the kafka's producers, and we know how to construct a simple kafka producer, how to send messages synchronously and asynchronously, and which configuration paramter is mandatory and necessary, and how to handle the message delivery time is that developer are most interested in. I hope you learnt something, see you!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号