网络协议学习笔记(九)CDN和数据中心
概述
上一篇给大家介绍了DNS协议和HttpDns协议,现在给大家介绍一下CDN和数据中心相关的知识。
CDN:你去小卖部取过快递么?
如果你去电商网站下单买个东西,这个东西一定要从电商总部的中心仓库送过来吗?原来基本是这样的,每一单都是单独配送,所以你可能要很久才能收到你的宝贝。但是后来电商网站的物流系统学聪明了,他们在全国各地建立了很多仓库,而不是只有总部的中心仓库才可以发货。电商网站根据统计大概知道,北京、上海、广州、深圳、杭州等地,每天能够卖出去多少书籍、卫生纸、包、电器等存放期比较长的物品。这些物品用不着从中心仓库发出,所以平时就可以将它们分布在各地仓库里,客户一下单,就近的仓库发出,第二天就可以收到了。这样,用户体验大大提高。当然,这里面也有个难点就是,生鲜这类东西保质期太短,如果提前都备好货,但是没有人下单,那肯定就坏了。这个问题,我后文再说。
我们先说,我们的网站访问可以借鉴“就近配送”这个思路。全球有这么多的数据中心,无论在哪里上网,临近不远的地方基本上都有数据中心。是不是可以在这些数据中心里部署几台机器,形成一个缓存的集群来缓存部分数据,那么用户访问数据的时候,就可以就近访问了呢?当然是可以的。这些分布在各个地方的各个数据中心的节点,就称为边缘节点。
由于边缘节点数目比较多,但是每个集群规模比较小,不可能缓存下来所有东西,因而可能无法命中,这样就会在边缘节点之上。有区域节点,规模就要更大,缓存的数据会更多,命中的概率也就更大。在区域节点之上是中心节点,规模更大,缓存数据更多。如果还不命中,就只好回源网站访问了。
这就是 CDN 分发系统的架构。CDN 系统的缓存,也是一层一层的,能不访问后端真正的源,就不打扰它。这也是电商网站物流系统的思路,北京局找不到,找华北局,华北局找不到,再找北方局。有了这个分发系统之后,接下来,客户端如何找到相应的边缘节点进行访问呢?
还记得我们讲过的基于 DNS 的全局负载均衡吗?这个负载均衡主要用来选择一个就近的同样运营商的服务器进行访问。你会发现,CDN 分发网络也是一个分布在多个区域、多个运营商的分布式系统,也可以用相同的思路选择最合适的边缘节点。
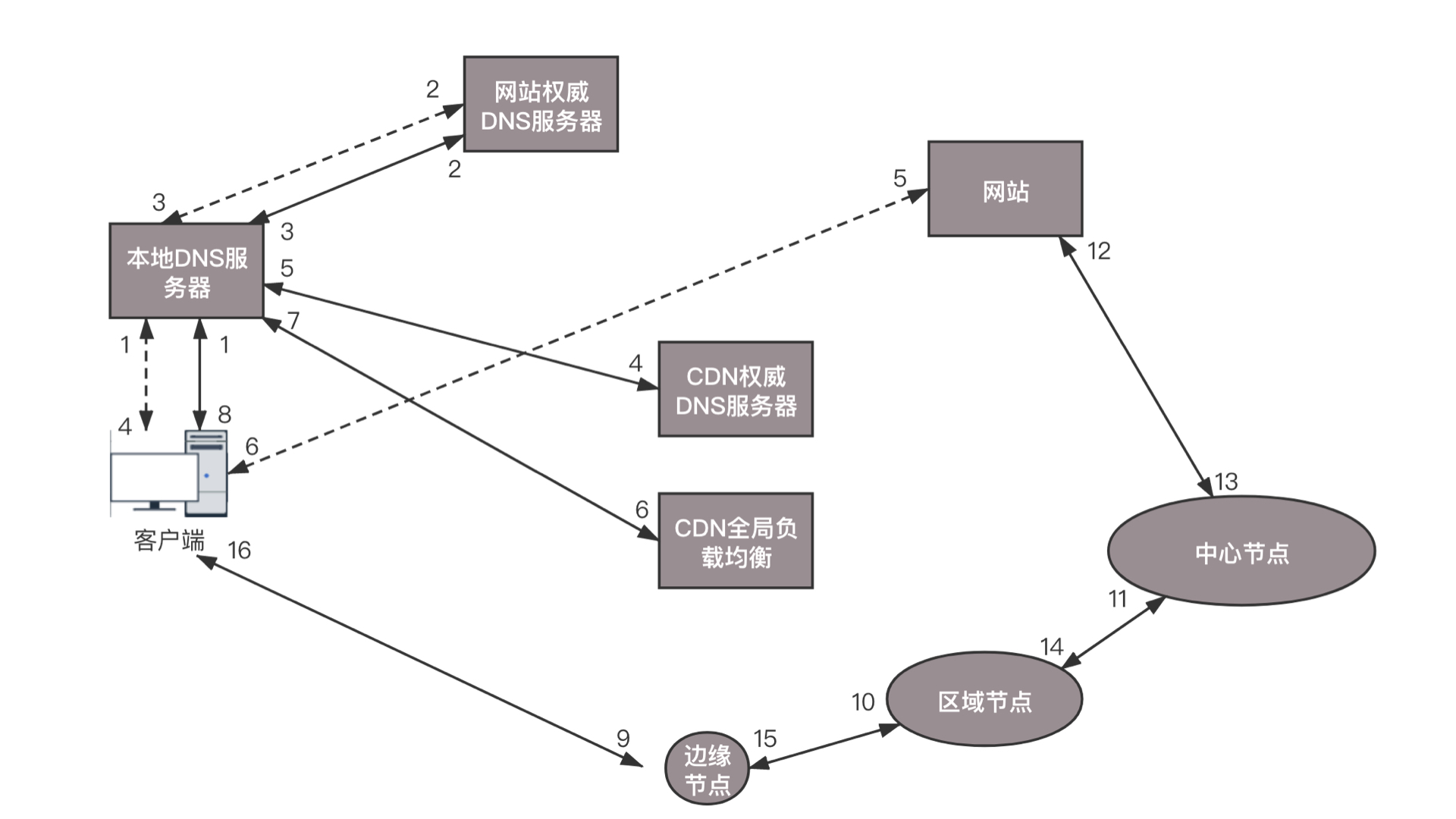
在没有 CDN 的情况下,用户向浏览器输入 www.web.com 这个域名,客户端访问本地 DNS 服务器的时候,如果本地 DNS 服务器有缓存,则返回网站的地址;如果没有,递归查询到网站的权威 DNS 服务器,这个权威 DNS 服务器是负责 web.com 的,它会返回网站的 IP 地址。本地 DNS 服务器缓存下 IP 地址,将 IP 地址返回,然后客户端直接访问这个 IP 地址,就访问到了这个网站。然而有了 CDN 之后,情况发生了变化。在 web.com 这个权威 DNS 服务器上,会设置一个 CNAME 别名,指向另外一个域名 www.web.cdn.com,返回给本地 DNS 服务器。
当本地 DNS 服务器拿到这个新的域名时,需要继续解析这个新的域名。这个时候,再访问的就不是 web.com 的权威 DNS 服务器了,而是 web.cdn.com 的权威 DNS 服务器,这是 CDN 自己的权威 DNS 服务器。在这个服务器上,还是会设置一个 CNAME,指向另外一个域名,也即 CDN 网络的全局负载均衡器。接下来,本地 DNS 服务器去请求 CDN 的全局负载均衡器解析域名,全局负载均衡器会为用户选择一台合适的缓存服务器提供服务,选择的依据包括:
根据用户 IP 地址,判断哪一台服务器距用户最近;
用户所处的运营商;
根据用户所请求的 URL 中携带的内容名称,判断哪一台服务器上有用户所需的内容;
查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力。
基于以上这些条件,进行综合分析之后,全局负载均衡器会返回一台缓存服务器的 IP 地址。本地 DNS 服务器缓存这个 IP 地址,然后将 IP 返回给客户端,客户端去访问这个边缘节点,下载资源。缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
CDN 可以进行缓存的内容有很多种
保质期长的日用品比较容易缓存,因为不容易过期,对应到就像电商仓库系统里,就是静态页面、图片等,因为这些东西也不怎么变,所以适合缓存。
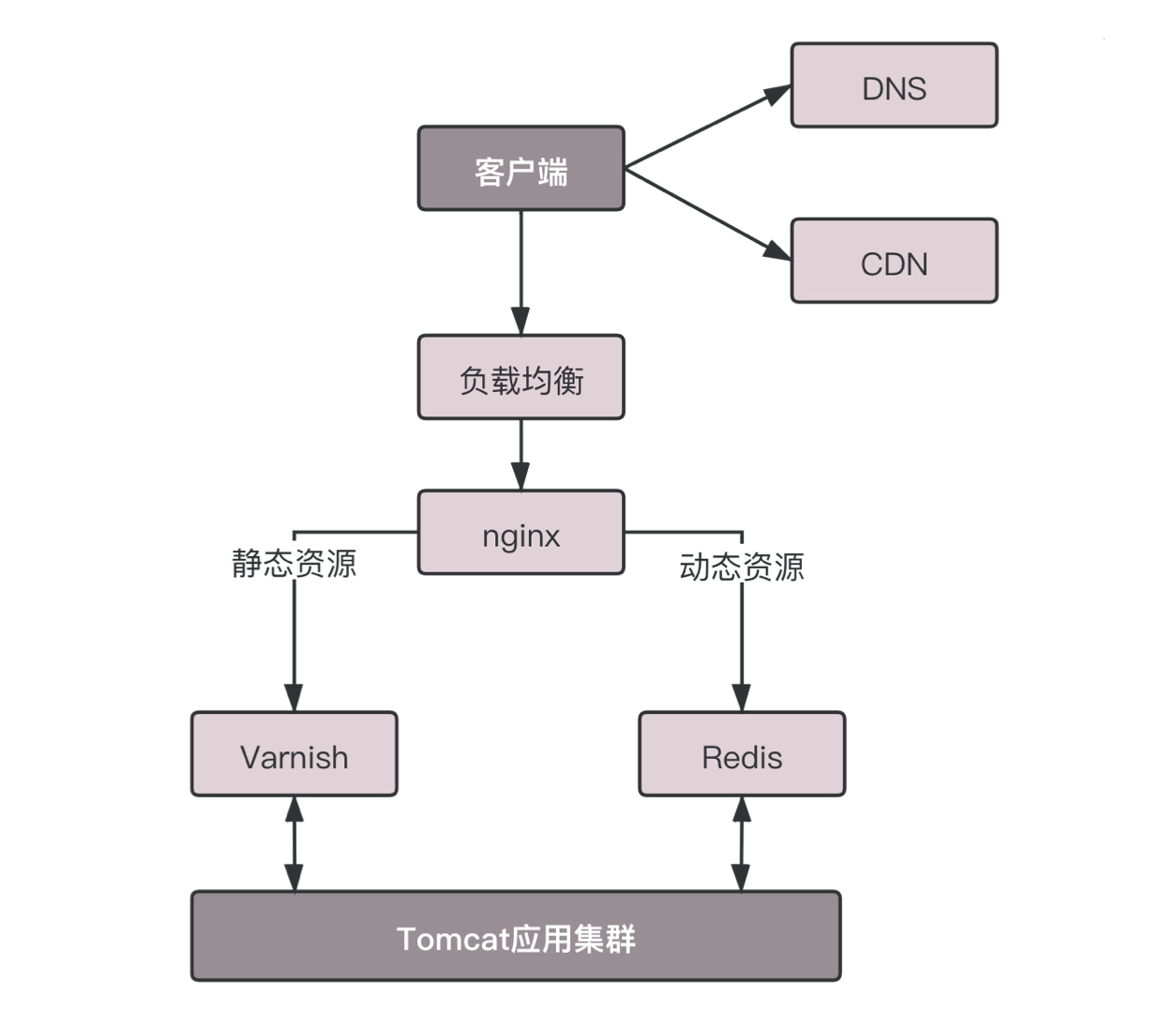
还记得这个接入层缓存的架构吗?在进入数据中心的时候,我们希望通过最外层接入层的缓存,将大部分静态资源的访问拦在边缘。而 CDN 则更进一步,将这些静态资源缓存到离用户更近的数据中心。越接近客户,访问性能越好,时延越低。但是静态内容中,有一种特殊的内容,也大量使用了 CDN,这个就是前面讲过的流媒体。CDN 支持流媒体协议,例如前面讲过的 RTMP 协议。在很多情况下,这相当于一个代理,从上一级缓存读取内容,转发给用户。由于流媒体往往是连续的,因而可以进行预先缓存的策略,也可以预先推送到用户的客户端。
对于静态页面来讲,内容的分发往往采取拉取的方式,也即当发现未命中的时候,再去上一级进行拉取。但是,流媒体数据量大,如果出现回源,压力会比较大,所以往往采取主动推送的模式,将热点数据主动推送到边缘节点。对于流媒体来讲,很多 CDN 还提供预处理服务,也即文件在分发之前,经过一定的处理。例如将视频转换为不同的码流,以适应不同的网络带宽的用户需求;再如对视频进行分片,降低存储压力,也使得客户端可以选择使用不同的码率加载不同的分片。这就是我们常见的,“我要看超清、标清、流畅等”。
对于流媒体 CDN 来讲,有个关键的问题是防盗链问题。因为视频是要花大价钱买版权的,为了挣点钱,收点广告费,如果流媒体被其他的网站盗走,在人家的网站播放,那损失可就大了。最常用也最简单的方法就是 HTTP 头的 referer 字段, 当浏览器发送请求的时候,一般会带上 referer,告诉服务器是从哪个页面链接过来的,服务器基于此可以获得一些信息用于处理。如果 refer 信息不是来自本站,就阻止访问或者跳到其它链接。
referer 的机制相对比较容易破解,所以还需要配合其他的机制。一种常用的机制是时间戳防盗链。使用 CDN 的管理员可以在配置界面上,和 CDN 厂商约定一个加密字符串。客户端取出当前的时间戳,要访问的资源及其路径,连同加密字符串进行签名算法得到一个字符串,然后生成一个下载链接,带上这个签名字符串和截止时间戳去访问 CDN。在 CDN 服务端,根据取出过期时间,和当前 CDN 节点时间进行比较,确认请求是否过期。然后 CDN 服务端有了资源及路径,时间戳,以及约定的加密字符串,根据相同的签名算法计算签名,如果匹配则一致,访问合法,才会将资源返回给客户。然而比如在电商仓库中,我在前面提过,有关生鲜的缓存就是非常麻烦的事情,这对应着就是动态的数据,比较难以缓存。怎么办呢?现在也有动态 CDN,主要有两种模式。
1,一种为生鲜超市模式,也即边缘计算的模式。既然数据是动态生成的,所以数据的逻辑计算和存储,也相应的放在边缘的节点。其中定时从源数据那里同步存储的数据,然后在边缘进行计算得到结果。就像对生鲜的烹饪是动态的,没办法事先做好缓存,因而将生鲜超市放在你家旁边,既能够送货上门,也能够现场烹饪,也是边缘计算的一种体现。
2,另一种是冷链运输模式,也即路径优化的模式。数据不是在边缘计算生成的,而是在源站生成的,但是数据的下发则可以通过 CDN 的网络,对路径进行优化。因为 CDN 节点较多,能够找到离源站很近的边缘节点,也能找到离用户很近的边缘节点。中间的链路完全由 CDN 来规划,选择一个更加可靠的路径,使用类似专线的方式进行访问。
对于常用的 TCP 连接,在公网上传输的时候经常会丢数据,导致 TCP 的窗口始终很小,发送速度上不去。根据前面的 TCP 流量控制和拥塞控制的原理,在 CDN 加速网络中可以调整 TCP 的参数,使得 TCP 可以更加激进地传输数据。可以通过多个请求复用一个连接,保证每次动态请求到达时。连接都已经建立了,不必临时三次握手或者建立过多的连接,增加服务器的压力。另外,可以通过对传输数据进行压缩,增加传输效率。所有这些手段就像冷链运输,整个物流优化了,全程冷冻高速运输。不管生鲜是从你旁边的超市送到你家的,还是从产地送的,保证到你家是新鲜的。
总而言之,CDN 和电商系统的分布式仓储系统一样,分为中心节点、区域节点、边缘节点,而数据缓存在离用户最近的位置。CDN 最擅长的是缓存静态数据,除此之外还可以缓存流媒体数据,这时候要注意使用防盗链。它也支持动态数据的缓存,一种是边缘计算的生鲜超市模式,另一种是链路优化的冷链运输模式。
数据中心:我是开发商,自己拿地盖别墅
无论你是看新闻、下订单、看视频、下载文件,最终访问的目的地都在数据中心里面。我们前面学了这么多的网络协议和网络相关的知识,你是不是很好奇,数据中心究竟长啥样呢?数据中心是一个大杂烩,几乎要用到前面学过的所有知识。前面讲办公室网络的时候,我们知道办公室里面有很多台电脑。如果要访问外网,需要经过一个叫网关的东西,而网关往往是一个路由器。数据中心里面也有一大堆的电脑,但是它和咱们办公室里面的笔记本或者台式机不一样。数据中心里面是服务器。服务器被放在一个个叫作机架(Rack)的架子上面。数据中心的入口和出口也是路由器,由于在数据中心的边界,就像在一个国家的边境,称为边界路由器(Border Router)。为了高可用,边界路由器会有多个。
一般家里只会连接一个运营商的网络,而为了高可用,为了当一个运营商出问题的时候,还可以通过另外一个运营商来提供服务,所以数据中心的边界路由器会连接多个运营商网络。既然是路由器,就需要跑路由协议,数据中心往往就是路由协议中的自治区域(AS)。数据中心里面的机器要想访问外面的网站,数据中心里面也是有对外提供服务的机器,都可以通过 BGP 协议,获取内外互通的路由信息。这就是我们常听到的多线 BGP 的概念。如果数据中心非常简单,没几台机器,那就像家里或者宿舍一样,所有的服务器都直接连到路由器上就可以了。但是数据中心里面往往有非常多的机器,当塞满一机架的时候,需要有交换机将这些服务器连接起来,可以互相通信。这些交换机往往是放在机架顶端的,所以经常称为 TOR(Top Of Rack)交换机。这一层的交换机常常称为接入层(Access Layer)。注意这个接入层和原来讲过的应用的接入层不是一个概念。
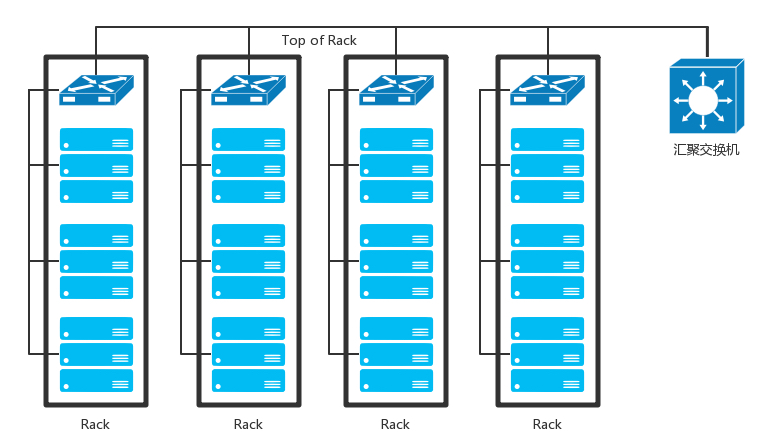
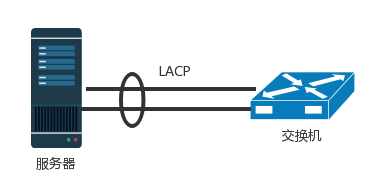
当一个机架放不下的时候,就需要多个机架,还需要有交换机将多个机架连接在一起。这些交换机对性能的要求更高,带宽也更大。这些交换机称为汇聚层交换机(Aggregation Layer)。数据中心里面的每一个连接都是需要考虑高可用的。这里首先要考虑的是,如果一台机器只有一个网卡,上面连着一个网线,接入到 TOR 交换机上。如果网卡坏了,或者不小心网线掉了,机器就上不去了。所以,需要至少两个网卡、两个网线插到 TOR 交换机上,但是两个网卡要工作得像一张网卡一样,这就是常说的网卡绑定(bond)。
这就需要服务器和交换机都支持一种协议 LACP(Link Aggregation Control Protocol)。它们互相通信,将多个网卡聚合称为一个网卡,多个网线聚合成一个网线,在网线之间可以进行负载均衡,也可以为了高可用作准备。
网卡有了高可用保证,但交换机还有问题。如果一个机架只有一个交换机,它挂了,那整个机架都不能上网了。因而 TOR 交换机也需要高可用,同理接入层和汇聚层的连接也需要高可用性,也不能单线连着。最传统的方法是,部署两个接入交换机、两个汇聚交换机。服务器和两个接入交换机都连接,接入交换机和两个汇聚都连接,当然这样会形成环,所以需要启用 STP 协议,去除环,但是这样两个汇聚就只能一主一备了。STP 协议里我们学过,只有一条路会起作用。
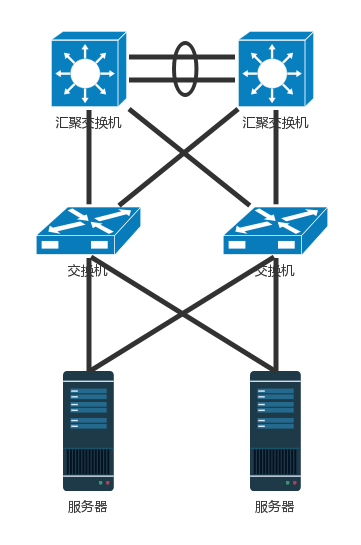
交换机有一种技术叫作堆叠,所以另一种方法是,将多个交换机形成一个逻辑的交换机,服务器通过多根线分配连到多个接入层交换机上,而接入层交换机多根线分别连接到多个交换机上,并且通过堆叠的私有协议,形成双活的连接方式。
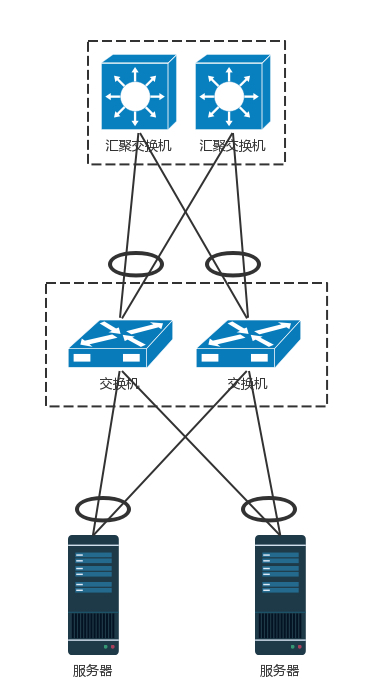
由于对带宽要求更大,而且挂了影响也更大,所以两个堆叠可能就不够了,可以就会有更多的,比如四个堆叠为一个逻辑的交换机。汇聚层将大量的计算节点相互连接在一起,形成一个集群。在这个集群里面,服务器之间通过二层互通,这个区域常称为一个 POD(Point Of Delivery),有时候也称为一个可用区(Available Zone)。当节点数目再多的时候,一个可用区放不下,需要将多个可用区连在一起,连接多个可用区的交换机称为核心交换机。
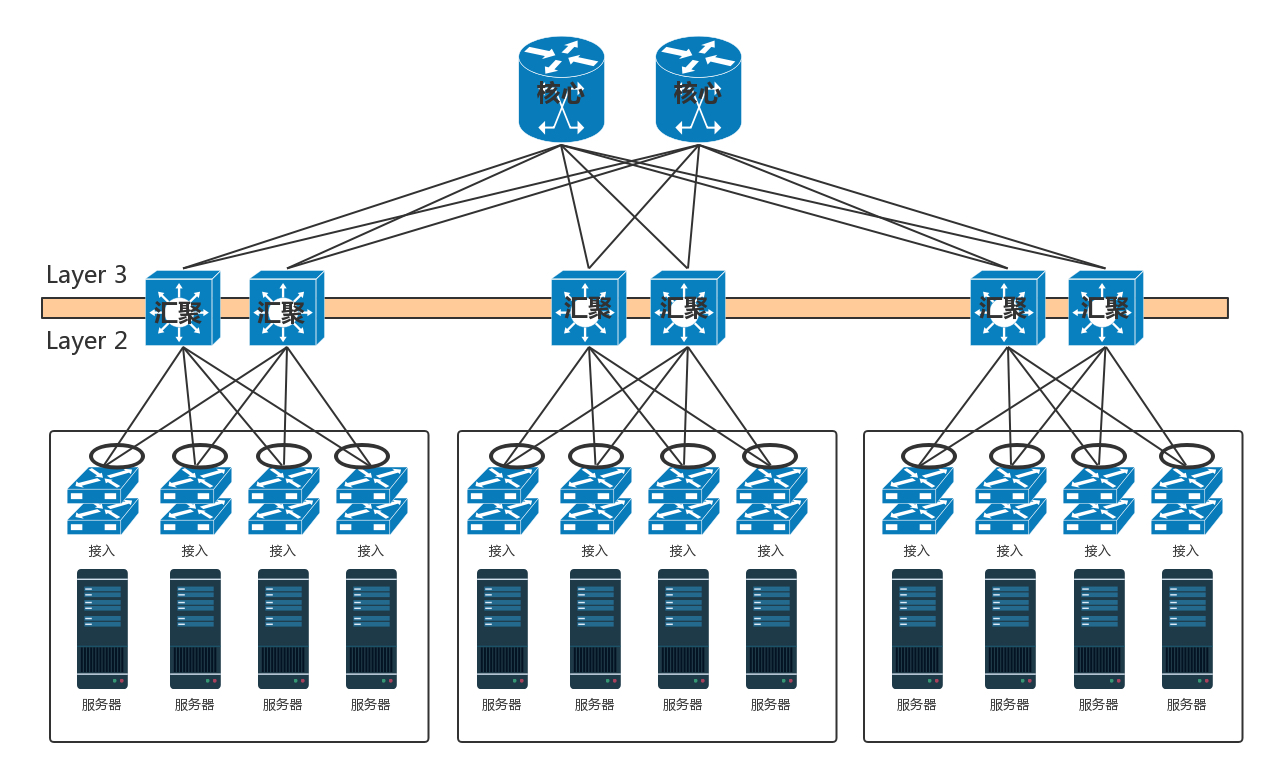
核心交换机吞吐量更大,高可用要求更高,肯定需要堆叠,但是往往仅仅堆叠,不足以满足吞吐量,因而还是需要部署多组核心交换机。核心和汇聚交换机之间为了高可用,也是全互连模式的。这个时候还存在一个问题,出现环路怎么办?一种方式是,不同的可用区在不同的二层网络,需要分配不同的网段。汇聚和核心之间通过三层网络互通的,二层都不在一个广播域里面,不会存在二层环路的问题。三层有环是没有问题的,只要通过路由协议选择最佳的路径就可以了。那为啥二层不能有环路,而三层可以呢?你可以回忆一下二层环路的情况。
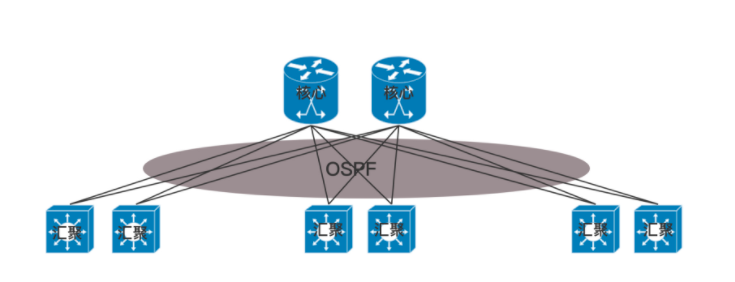
如图,核心层和汇聚层之间通过内部的路由协议 OSPF,找到最佳的路径进行访问,而且还可以通过 ECMP 等价路由,在多个路径之间进行负载均衡和高可用。但是随着数据中心里面的机器越来越多,尤其是有了云计算、大数据,集群规模非常大,而且都要求在一个二层网络里面。这就需要二层互连从汇聚层上升为核心层,也即在核心以下,全部是二层互连,全部在一个广播域里面,这就是常说的大二层。
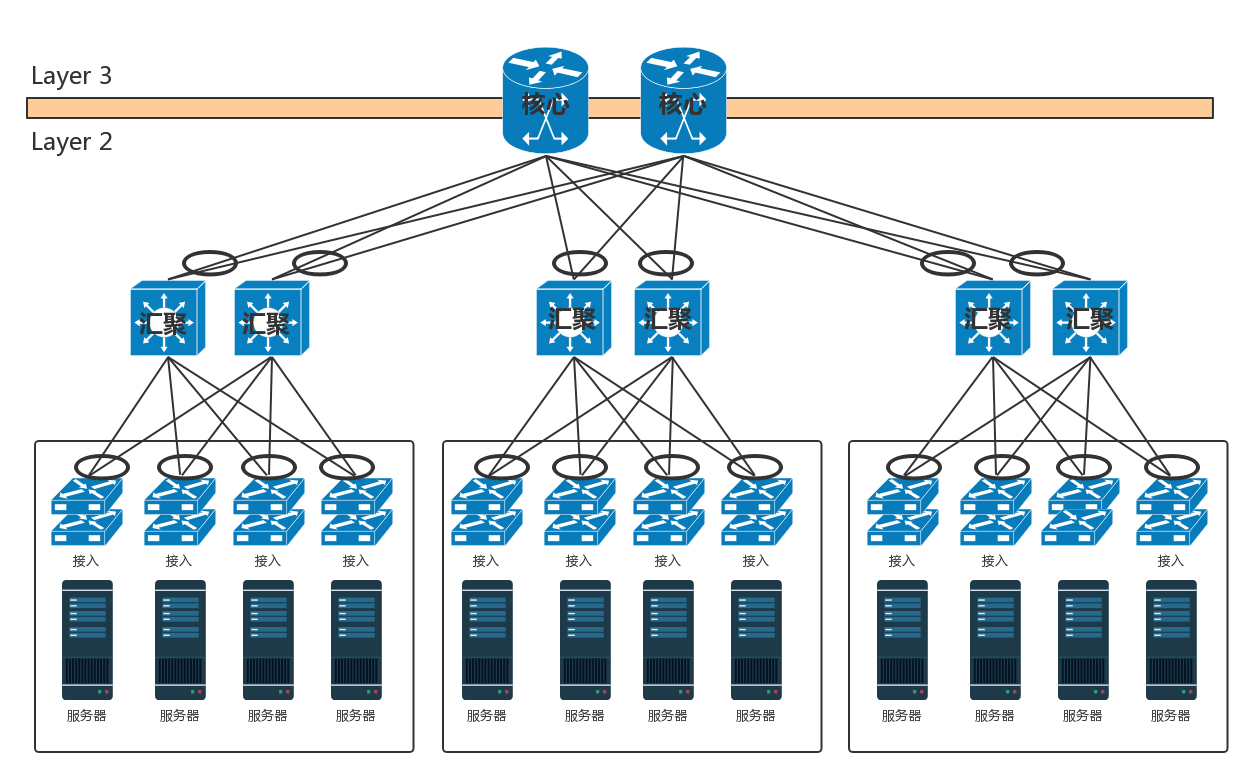
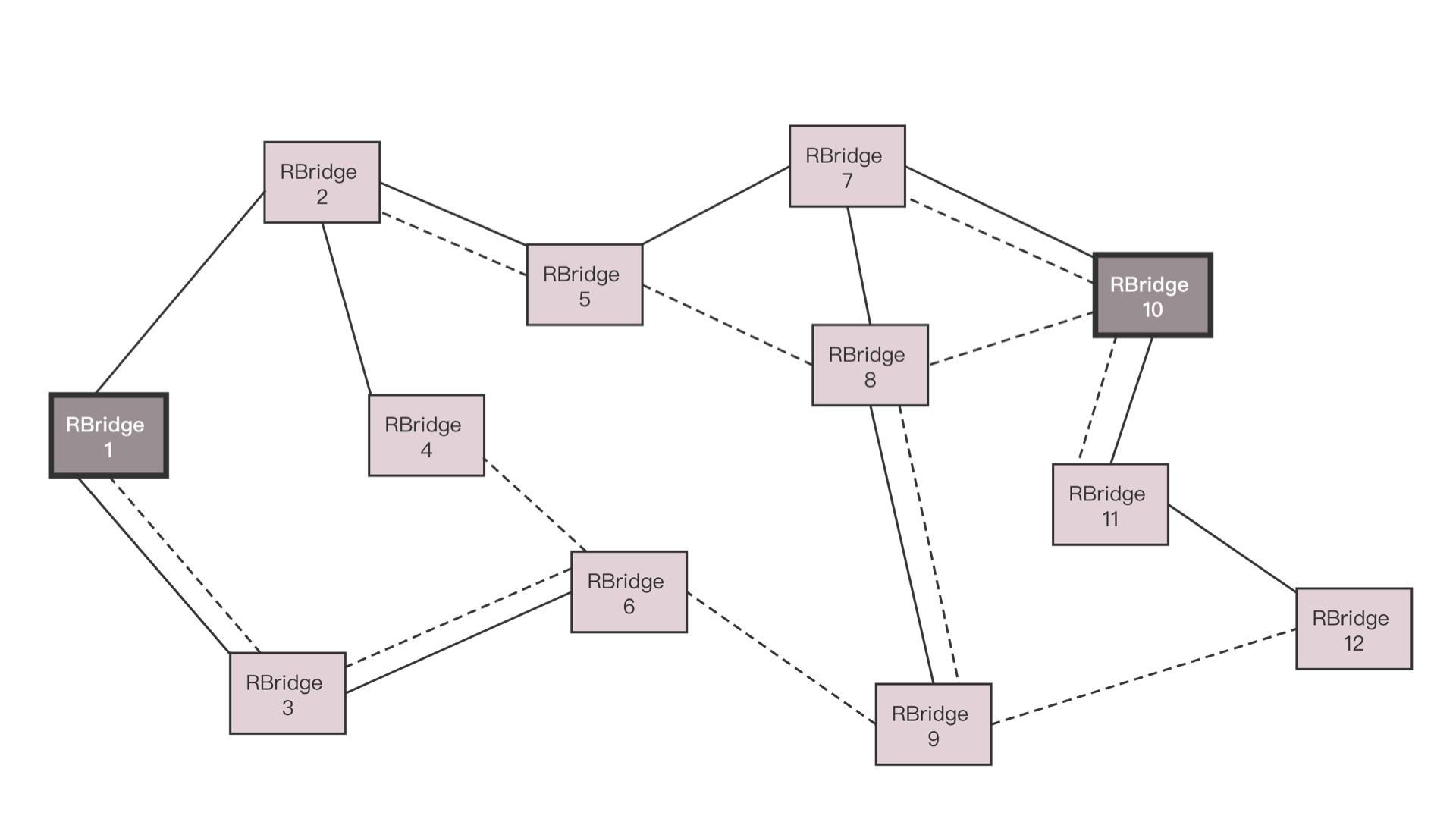
如果大二层横向流量不大,核心交换机数目不多,可以做堆叠,但是如果横向流量很大,仅仅堆叠满足不了,就需要部署多组核心交换机,而且要和汇聚层进行全互连。由于堆叠只解决一个核心交换机组内的无环问题,而组之间全互连,还需要其他机制进行解决。如果是 STP,那部署多组核心无法扩大横向流量的能力,因为还是只有一组起作用。于是大二层就引入了 TRILL(Transparent Interconnection of Lots of Link),即多链接透明互联协议。它的基本思想是,二层环有问题,三层环没有问题,那就把三层的路由能力模拟在二层实现。运行 TRILL 协议的交换机称为 RBridge,是具有路由转发特性的网桥设备,只不过这个路由是根据 MAC 地址来的,不是根据 IP 来的。Rbridage 之间通过链路状态协议运作。记得这个路由协议吗?通过它可以学习整个大二层的拓扑,知道访问哪个 MAC 应该从哪个网桥走;还可以计算最短的路径,也可以通过等价的路由进行负载均衡和高可用性。
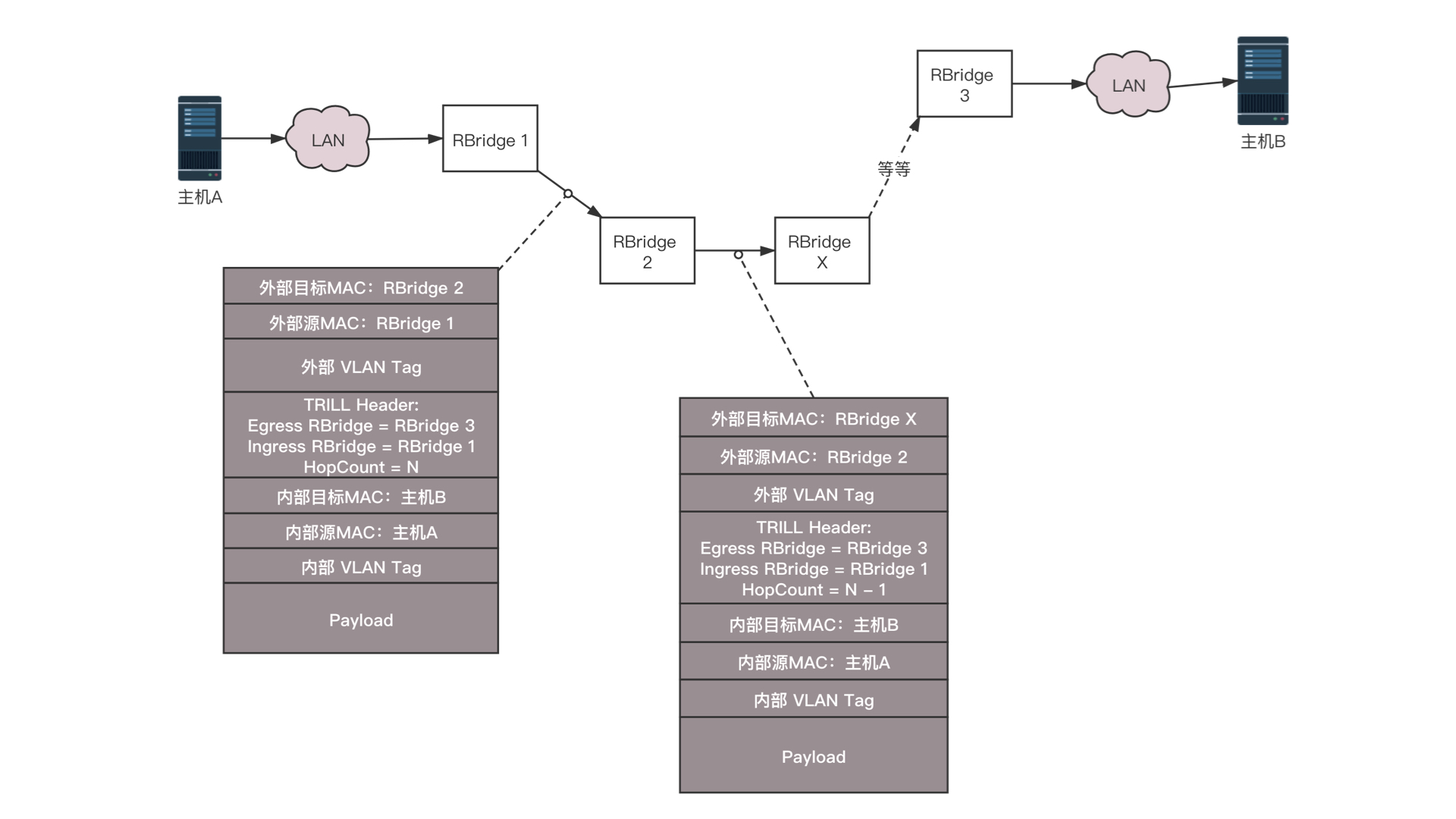
TRILL 协议在原来的 MAC 头外面加上自己的头,以及外层的 MAC 头。TRILL 头里面的 Ingress RBridge,有点像 IP 头里面的源 IP 地址,Egress RBridge 是目标 IP 地址,这两个地址是端到端的,在中间路由的时候,不会发生改变。而外层的 MAC,可以有下一跳的 Bridge,就像路由的下一跳,也是通过 MAC 地址来呈现的一样。如图中所示的过程,有一个包要从主机 A 发送到主机 B,中间要经过 RBridge 1、RBridge 2、RBridge X 等等,直到 RBridge 3。在 RBridge 2 收到的包里面,分内外两层,内层就是传统的主机 A 和主机 B 的 MAC 地址以及内层的 VLAN。在外层首先加上一个 TRILL 头,里面描述这个包从 RBridge 1 进来的,要从 RBridge 3 出去,并且像三层的 IP 地址一样有跳数。然后再外面,目的 MAC 是 RBridge 2,源 MAC 是 RBridge 1,以及外层的 VLAN。
当 RBridge 2 收到这个包之后,首先看 MAC 是否是自己的 MAC,如果是,要看自己是不是 Egress RBridge,也即是不是最后一跳;如果不是,查看跳数是不是大于 0,然后通过类似路由查找的方式找到下一跳 RBridge X,然后将包发出去。RBridge 2 发出去的包,内层的信息是不变的,外层的 TRILL 头里面。同样,描述这个包从 RBridge 1 进来的,要从 RBridge 3 出去,但是跳数要减 1。外层的目标 MAC 变成 RBridge X,源 MAC 变成 RBridge 2。如此一直转发,直到 RBridge 3,将外层解出来,发送内层的包给主机 B。这个过程是不是和 IP 路由很像?对于大二层的广播包,也需要通过分发树的技术来实现。我们知道 STP 是将一个有环的图,通过去掉边形成一棵树,而分发树是一个有环的图形成多棵树,不同的树有不同的 VLAN,有的广播包从 VLAN A 广播,有的从 VLAN B 广播,实现负载均衡和高可用。
核心交换机之外,就是边界路由器了。至此从服务器到数据中心边界的层次情况已经清楚了。在核心交换上面,往往会挂一些安全设备,例如入侵检测、DDoS 防护等等。这是整个数据中心的屏障,防止来自外来的攻击。核心交换机上往往还有负载均衡器,原理前面的章节已经说过了。在有的数据中心里面,对于存储设备,还会有一个存储网络,用来连接 SAN 和 NAS。但是对于新的云计算来讲,往往不使用传统的 SAN 和 NAS,而使用部署在 x86 机器上的软件定义存储,这样存储也是服务器了,而且可以和计算节点融合在一个机架上,从而更加有效率,也就没有了单独的存储网络了。于是整个数据中心的网络如下图所示。
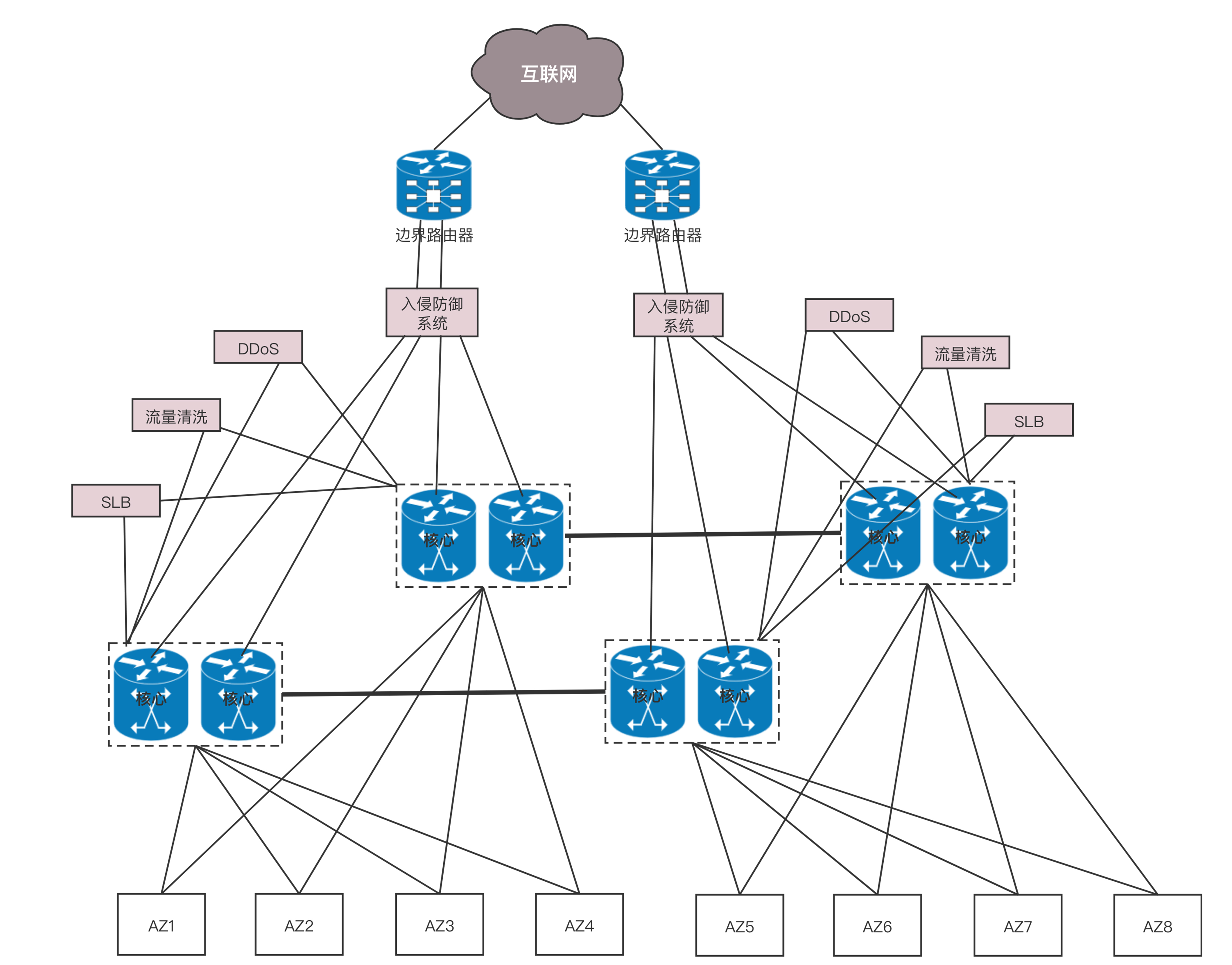
这是一个典型的三层网络结构。这里的三层不是指 IP 层,而是指接入层、汇聚层、核心层三层。这种模式非常有利于外部流量请求到内部应用。这个类型的流量,是从外到内或者从内到外,对应到上面那张图里,就是从上到下,从下到上,上北下南,所以称为南北流量。但是随着云计算和大数据的发展,节点之间的交互越来越多,例如大数据计算经常要在不同的节点将数据拷贝来拷贝去,这样需要经过交换机,使得数据从左到右,从右到左,左西右东,所以称为东西流量。为了解决东西流量的问题,演进出了叶脊网络(Spine/Leaf)。
叶子交换机(leaf),直接连接物理服务器。L2/L3 网络的分界点在叶子交换机上,叶子交换机之上是三层网络。
脊交换机(spine switch),相当于核心交换机。叶脊之间通过 ECMP 动态选择多条路径。脊交换机现在只是为叶子交换机提供一个弹性的 L3 路由网络。南北流量可以不用直接从脊交换机发出,而是通过与 leaf 交换机并行的交换机,再接到边界路由器出去。
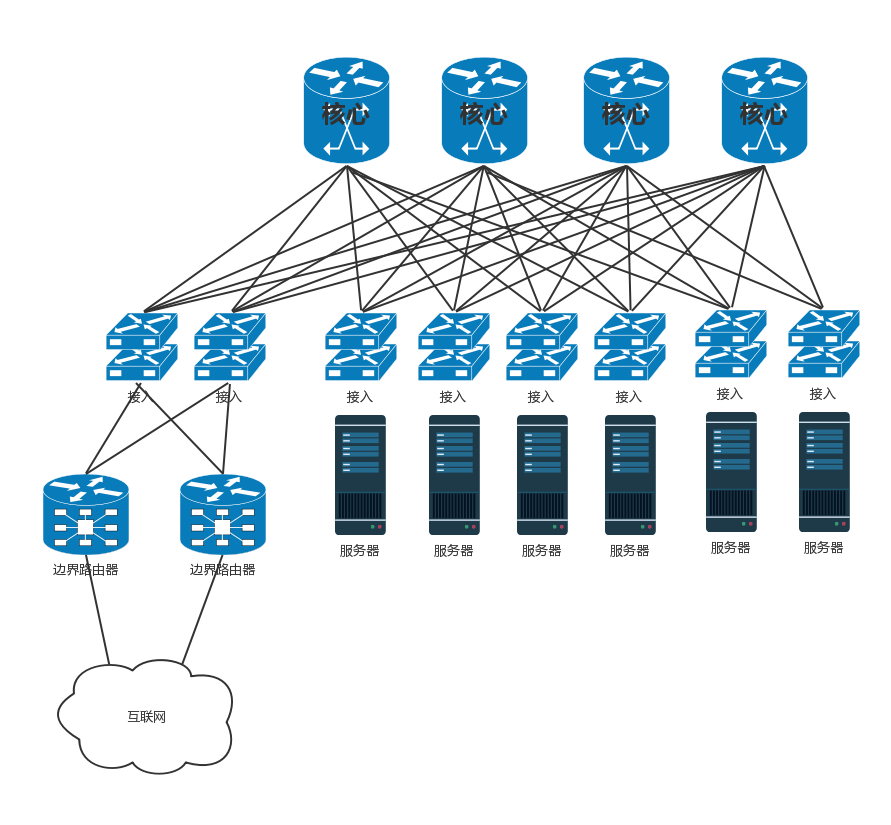
传统的三层网络架构是垂直的结构,而叶脊网络架构是扁平的结构,更易于水平扩展。
总而言之,数据中心分为三层。服务器连接到接入层,然后是汇聚层,再然后是核心层,最外面是边界路由器和安全设备。数据中心的所有链路都需要高可用性。服务器需要绑定网卡,交换机需要堆叠,三层设备可以通过等价路由,二层设备可以通过 TRILL 协议。随着云和大数据的发展,东西流量相对于南北流量越来越重要,因而演化为叶脊网络结构。
总结
以后关于数据中台系列的总结大部分来自Geek Time的课件,大家可以自行关键字搜索。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号