pandas
pandas
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
pandas.Series( data, index, dtype, name, copy)
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
import pandas as pd
a=[1,2,3]
myvar=pd.Series(a)
print(myvar)

a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)

sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)

sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构
pandas.DataFrame( data, index, columns, dtype, copy)
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)

import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)

import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)

import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])

import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])

import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)

import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc["day2"])

Pandas CSV 文件
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)

import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')

数据处理
head()
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())

tail()
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())

info()
info() 方法返回表格的一些基本信息:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())

Pandas JSON
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
import pandas as pd
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)

import pandas as pd
# 字典格式的 JSON
s = {
"col1":{"row1":1,"row2":2,"row3":3},
"col2":{"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)

import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)

import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path =['students'])
print(df_nested_list)

import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)

import pandas as pd
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
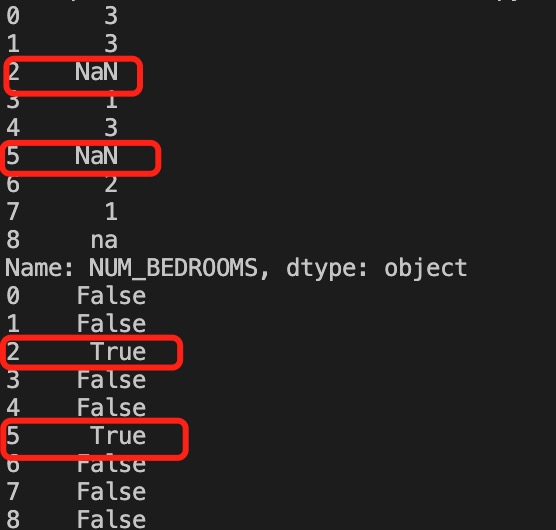
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())

import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
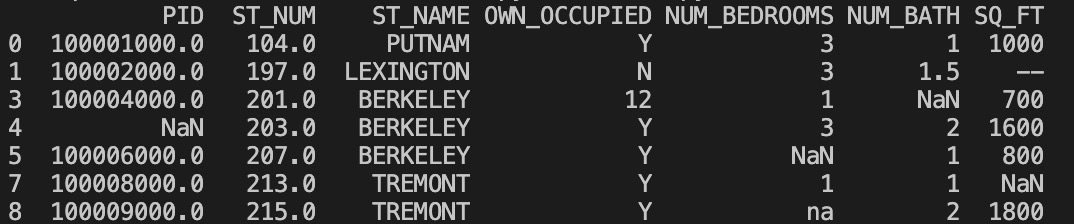
import pandas as pd
df = pd.read_csv('property-data.csv')
df.fillna(12345, inplace = True)
print(df.to_string())
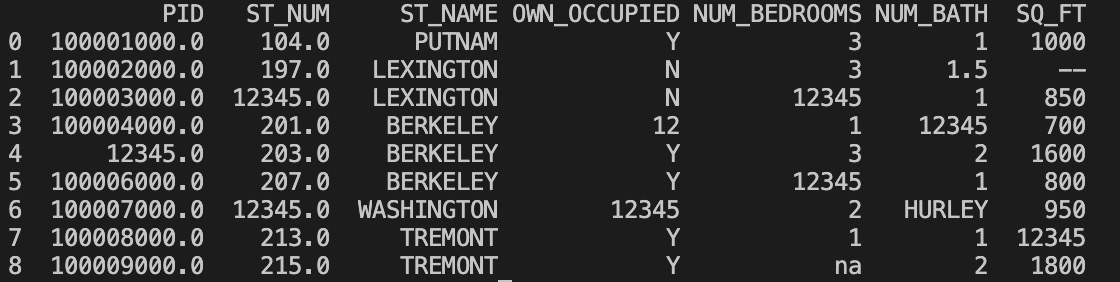
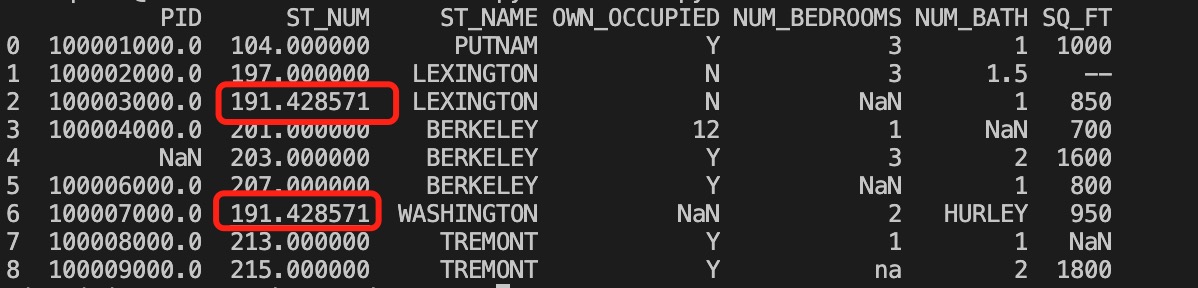
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号