无符号、零填充
unsigned
id int unsigned
zerofill
id int(5) zerofill
非空
create table t1(
id int,
name varchar(16)
);
insert into t1(id) values(1);
insert into t1(name) values('jason');
insert into t1(name,id) values('kevin',2);
ps:所有字段类型不加约束条件的情况下默认都可以为空
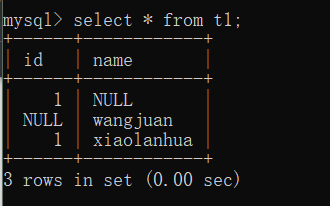
create create table t2(
id int,
name varchar(16) not null
);
insert into t2(id) values(1);
insert into t2(name) values('jason');
insert into t2 values(1,'');
insert into t2 values(2,null);
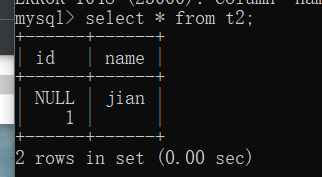
默认值
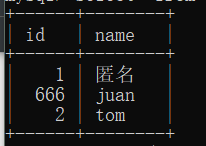
create table t3(
id int default 666,
name varchar(16) default '匿名'
);
insert into t3(id) values(1);
insert into t3(name) values('jason');
insert into t3 values(2,'kevin');
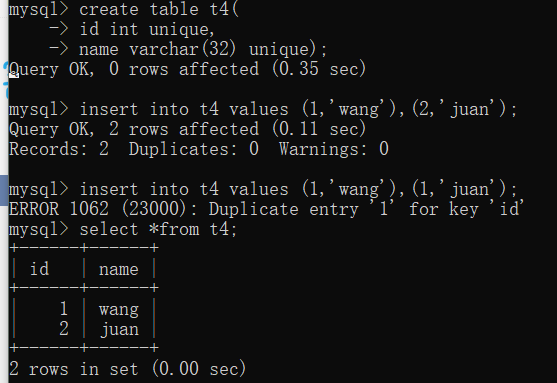
唯一值
'''单列唯一'''
create table t4(
id int unique,
name varchar(32) unique
);
insert into t4 values(1,'jason'),(2,'jason');
'''联合唯一'''
create table t5(
id int,
ip varchar(32),
port int,
unique(ip,port)
);
insert into t5 values(1,'127.0.0.1',8080),(2,'127.0.0.1',8081),(3,'127.0.0.2',8080);
insert into t5 values(4,'127.0.0.1',8080);
主键
1.单从约束层面上而言主键相当于not null + unique(非空且唯一)
create table t6(
id int primary key,
name varchar(32)
);
insert into t6(name) values('jason');
insert into t6 values(1,'kevin');
insert into t6 values(1,'jerry');
2.InnoDB存储引擎规定了所有的表都必须有且只有一个主键(主键是组织数据的重要条件并且主键可以加快数据的查询速度)
1.当表中没有主键也没有其他非空切唯一的字段的情况下
InnoDB会采用一个隐藏的字段作为表的主键 隐藏意味着无法使用 基于该表的数据查询只能一行行查找 速度很慢
2.当表中没有主键但是有其他非空且唯一的字段 那么会从上往下将第一个该字段自动升级为主键
create table t7(
id int,
age int not null unique,
phone bigint not null unique,
birth int not null unique,
height int not null unique
);
"""
我们在创建表的时候应该有一个字段用来标识数据的唯一性 并且该字段通常情况下就是'id'(编号)字段
id nid sid pid gid uid
create table userinfo(
uid int primary key,
);
"""
自增
该约束条件不能单独出现 并且一张表中只能出现一次 主要就是配合主键一起用
create table t8(
id int primary key,
name varchar(32)
);
create table t9(
id int primary key auto_increment,
name varchar(32)
);
"""
自增特性
自增不会因为数据的删除而回退 永远自增往前
如果自己设置了更大的数 则之后按照更大的往前自增
如果想重置某张表的主键值 可以使用
truncate t9; 清空表数据并重置主键
"""
外键前戏
我们需要一张员工表
id name age dep_name dep_desc
1.表语义不明确(到底是员工还是部门) 无所谓
2.存取数据过于冗余(浪费存储空间) 无所谓
3.数据的扩展性极差 不能忽略
将上述表一分为二
id name age
id dep_name dep_desc
上述的三个问题全部解决 但是员工跟部门之间没有了关系
外键字段:用于标识数据与数据之间关系的字段
关系的判断
表关系、数据关系其实意思是一样的 知识说法上有区分
关系总共有四种
一对多
多对多
一对一
没有关系
关系的判断可以采用'换位思考'原则
一对多关系
以员工表和部门表为例
1.先站在员工表的角度
问:一名员工能否对应多个部门
答:不可以
2.再站在部门表的角度
问:一个部门能否对应多名员工
答:可以
结论:一个可以一个不可以 那么关系就是'一对多'
针对'一对多'关系 外键字段建在'多'的一方
外键字段的建立
小技巧:先定义出含有普通字段的表 之后再考虑外键字段的添加
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id)
);
create table dep(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64)
);
1.创建表的时候一定要先创建被关联表
2.录入表数据的时候一定要先录入被关联表
3.修改数据的时候外键字段无法修改和删除
针对3有简化措施>>>:级联更新级联删除
create table emp1(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep1(id)
on update cascade
on delete cascade
);
create table dep1(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64)
);
"""
外键其实是强耦合 不符合解耦合的特性
所以很多时候 实际项目中当表较多的情况 我们可能不会使用外键 而是使用代码建立逻辑层面的关系
"""
多对多关系
以书籍表与作者表为例
1.先站在书籍表的角度
问:一本书能否对应多个作者
答:可以
2.再站在作者表的角度
问:一个作者能否对应多本书
答:可以
结论:两个都可以 关系就是'多对多'
针对'多对多'不能在表中直接创建 需要新建第三张关系表
create table book(
id int primary key auto_increment,
title varchar(32),
price float(5,2)
);
create table author(
id int primary key auto_increment,
name varchar(32),
phone bigint
);
create table book2author(
id int primary key auto_increment,
author_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade,
book_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
一对一关系
以用户表与用户详情表为例
1.先站在用户表的角度
问:一个用户能否对应多个用户详情
答:不可以
2.再站在用户详情表的角度
问:一个用户详情能否对应多个用户
答:不可以
结论:两个都可以 关系就是'一对一'或者没有关系
针对'一对一'外键字段建在任何一方都可以 但是推荐建在查询频率较高的表中
create table user(
id int primary key auto_increment,
name varchar(32),
detail_id int unique,
foreign key(detail_id) references userdetail(id)
on update cascade
on delete cascade
);
create table userdetail(
id int primary key auto_increment,
phone bigint
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号