异常、生成器
异常常见类型
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 SyntaxError
NameError
IndexError
KeyError
IndentationError
异常处理语法结构
1.基本句法
try:
待监测的代码(可能会出错的代码)
except 错误类型:
针对上述错误类型制定的方案
eg:
try:
print(x)
except NameError:
print("Variable x is not defined")
except:
print("Something else went wrong")
2.查看错误的信息
try:
待监测的代码(可能会出错的代码)
except 错误类型 as e: # e就是系统提示的错误信息
针对上述错误类型制定的方案
3.针对不同的错误类型制定不同的解决方案
try:
待监测的代码(可能会出错的代码)
except 错误类型1 as e: # e就是系统提示的错误信息
针对上述错误类型1制定的方案
except 错误类型2 as e: # e就是系统提示的错误信息
针对上述错误类型2制定的方案
except 错误类型3 as e: # e就是系统提示的错误信息
针对上述错误类型3制定的方案
待监测的代码(可能会出错的代码)
4.万能异常 Exception/BaseException
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
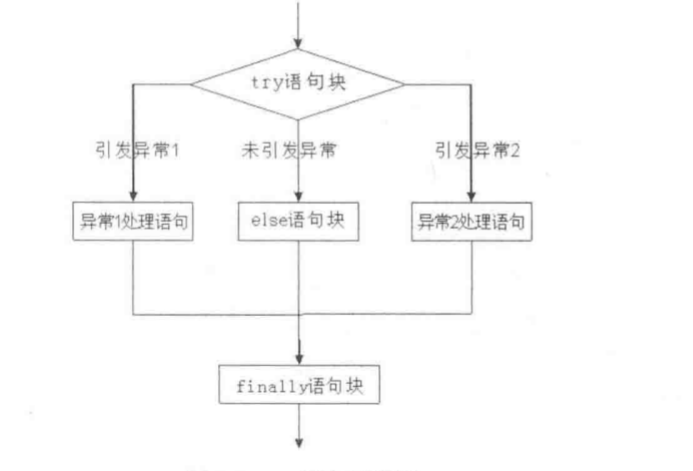
5.结合else使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
try的子代码正常运行结束没有任何的报错后 再执行else子代码
6.结合finally使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
try的子代码正常运行结束没有任何的报错后 再执行else子代码
finally:
无论try的子代码是否报错 最后都要执行finally子代码
1.基本语法结构
try:
待监测的代码(可能会出错的代码)
except 错误类型:
针对上述错误类型制定的方案
2.查看错误的信息
try:
待监测的代码(可能会出错的代码)
except 错误类型 as e: # e就是系统提示的错误信息
针对上述错误类型制定的方案
3.针对不同的错误类型制定不同的解决方案
try:
待监测的代码(可能会出错的代码)
except 错误类型1 as e: # e就是系统提示的错误信息
针对上述错误类型1制定的方案
except 错误类型2 as e: # e就是系统提示的错误信息
针对上述错误类型2制定的方案
except 错误类型3 as e: # e就是系统提示的错误信息
针对上述错误类型3制定的方案
...
4.万能异常 Exception/BaseException
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
5.结合else使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
try的子代码正常运行结束没有任何的报错后 再执行else子代码
6.结合finally使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
try的子代码正常运行结束没有任何的报错后 再执行else子代码
finally:
无论try的子代码是否报错 最后都要执行finally子代码
异常处理补充
1.断言
assert <条件测式> ,<异常附加数据>
assert后面条件为假时就会报异常
name = 'jason'
# assert isinstance(name, int)
assert isinstance(name, str)
print('哈哈哈 我就说吧 肯定是字符串')
name.strip()
2.主动抛异常
raise 异常名
raise 异常名,附加数据
raise 类名
eg:
name = 'jason'
if name == 'jason':
raise Exception('老子不干了')
else:
print('正常走')
异常处理实战应用
1.异常处理能尽量少用就少用
2.被try监测的代码能尽量少就尽量少
3.当代码中可能会出现一些无法控制的情况报错才应该考虑使用
eg: 使用手机访问网络软件 断网
编写网络爬虫程序请求数据 断网
课堂练习
使用while循环+异常处理+迭代器对象 完成for循环迭代取值的功能
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# 1.先将列表调用__iter__转变成迭代器对象
iter_l1 = l1.__iter__()
# 2.while循环让迭代器对象反复执行__next__
while True:
try:
print(iter_l1.__next__())
except StopIteration as e:
break
生成器对象
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
1.本质
还是内置有__iter__和__next__的迭代器对象
2.区别
迭代器对象是解释器自动提供的
数据类型\文件对象>>>:迭代器对象
生成器对象是程序员编写出来的
代码、关键字>>>:迭代器对象(生成器)
3.创建生成器的基本语法
函数体代码中填写yield关键字
# def my_iter():
# print('哈哈哈 椰子汁很好喝')
# yield
'''1.函数体代码中如果有yield关键字
那么函数名加括号并不会执行函数体代码
会生成一个生成器对象(迭代器对象)
'''
# res = my_iter()
'''2.使用加括号之后的结果调用__next__才会执行函数体代码'''
# res.__next__()
'''3.每次执行完__next__代码都会停在yield位置 下次基于该位置继续往下找第二个yield'''
def my_iter():
print('哈哈哈 椰子汁很好喝')
yield 111, 222, 333
print('呵呵呵 从小喝到大')
yield 111, 222, 333
print('嘿嘿嘿 特种兵牌还可以')
yield 111, 222, 333
print('哼哼哼 千万别整多了 倒沫子 头发掉光光')
yield 111, 222, 333
res = my_iter()
r1 = res.__next__()
print(r1)
r2 = res.__next__()
print(r2)
r3 = res.__next__()
print(r3)
r4 = res.__next__()
print(r4)
'''4.yield还有点类似于return 可以返回返回值'''
课堂练习
自定义生成器对标range功能(一个参数 两个参数 三个参数 迭代器对象)
for i in range(1, 10):
print(i)
1.先写两个参数的
2.再写一个参数的
3.最后写三个参数
# 1.生成器
# 两个参数
def my_range(start_num,end_num=None,step=1):
# 判断end_num是否有值 没有值说明用户只给了一个值 起始数字应该是0 终止位置应该是传的值
if not end_num:
end_num=start_num
start_num=0
if start_num>end_num:
start_num,end_num=end_num,start_num
while start_num<end_num:
if step > 0:
yield start_num
start_num+=step
elif step<0:
yield end_num
end_num+=step
for i in my_range(100,50,-1):
print(i)
yield冷门用法
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
def eat(name, food=None):
print(f'{name}准备用餐')
while True:
food = yield
print(f'{name}正在吃{food}')
res = eat('jason')
res.__next__()
# res.send('汉堡') # 1.将括号内的数据传给yield前面的变量名 2.再自动调用__next__
# res.send('包子')
# res.send('面条')
生成器表达式
说白了就是生成器的简化写法
l1 = [i ** 2 for i in range(100)]
print(l1)
l1 = (i ** 2 for i in range(100)) # 生成器对象
print(l1) # <generator object <genexpr> at 0x000001DFC07F7E40>
for i in l1:
print(i)
"""
面试题(有难度)
大致知道流程即可
"""
def add(n, i): # 普通函数 返回两个数的和 求和函数
return n + i
def test(): # 生成器
for i in range(4):
yield i
g = test() # 激活生成器
for n in [1, 10]:
g = (add(n, i) for i in g)
"""
第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g)
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23] (对)
#D. res=[21,22,23,24]
模块
索引取值与迭代器的差异
模块取值可以有索引取值的迭代取值。
l1 = [11, 22, 33, 44, 55]
1.索引取值
可以任意位置任意次数取值
不支持无序类型的数据取值
2.迭代取值
只能从前往后依次取值无法后退
支持所有类型的数据取值(无序有序)
ps:两者的使用需要结合实际应用场景
模块简介
1.模块的本质
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
2.python模块的历史
python刚开始的时候最早起源于linux运维、胶水语言,所有搞其他编程语言的程序员都看不起 甚至给python起了个外号>>>:调包侠(贬义词)
随着时间的发展项目的复杂度越来越高 上面那帮人也不得不用一下python 然后发现真香定律>>>:调包侠(褒义词)
3.python模块的表现形式
1.py文件(py文件也可以称之为是模块文件)
2.含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
3.已被编译为共享库或DLL的c或C++扩展(了解)
4.使用C编写并链接到python解释器的内置模块(了解)
模块的分类
1.自定义模块
我们自己写的模块文件
2.内置模块
python解释器提供的模块
3.第三方模块
别人写的模块文件(python背后真正的大佬)
导入模块的两种句式
"""
导入模块的两种句式:
1.一定要搞清楚谁是执行文件 谁是被导入文件
2.以后开发项目的时候py文件的名称一般是纯英文,不会含有中文甚至空格.
3.导入模块文件不需要填写后缀名
"""
1.import 语句
以import a为例研究底层原理
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中产生一个模块的名字
4.在执行文件中使用该模块名点的方式使用模块名称空间中所有的名字
"""
2.from...import...句式
以from a import name,func1为例研究底层原理
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中产生对应的名字绑定模块名称空间中对应的名字
4.在执行文件中直接使用名字就可以访问名称空间中对应的名字
"""
导入模块补充说明
1.import与from...import...两者优缺点
import句式
由于使用模块名称空间中的名字都需要模块名点的方式才可以用
所以不会轻易的被执行文件中的名字替换掉
但是每次使用模块名称空间中的名字都必须使用模块名点才可以
from...import...句式
指名道姓的导入模块名称空间中需要使用的名字 不需要模块名点
但是容易跟执行文件中名字冲突
2.重复导入模块
解释器只会导入一次 后续重复的导入语句并不会执行
3.起别名
import 语句 as 新名字
import wuyongerciyuan as wy
from wuyongerciyuan import zhangzehonglovezhanghong as zz
from a import name as n,func1 as f1
4.涉及到多个模块导入
import a
import wuyongerciyuan
如果模块功能相似度不高 推荐使用第一种 相似度高可以使用第二种
import a, wuyongerciyuan
循环导入问题
1.循环导入
两个文件之间彼此导入彼此并且相互使用各自名称空间中的名字 极容易报错
2.如何解决循环导入问题
1.确保名字在使用之前就已经准备完毕
2.我们以后在编写代码的过程中应该尽可能避免出现循环导入
判断文件类型
所有的py文件都可以直接打印__name__对应的值
当py文件是执行文件的时候__name__对应的值是__main__
当py文件是被导入文件的时候__name__对应的值是模块名
if __name__ == '__main__':
print('哈哈哈 我是执行文件 我可以运行这里的子代码')
上述脚本可以用来区分所在py文件内python代码的执行
使用场景
1.模块开发阶段
2.项目启动文件
"""
from a import * *默认是将模块名称空间中所有的名字导入
__all__ = ['名字1', '名字2'] 针对*可以限制拿的名字
"""
模块的查找顺序
1.内存
import aaa
import time
time.sleep(15)
print(aaa.name)
aaa.func1()
2.内置
import time
print(time)
print(time.name)
"""
以后在自定义模块的时候尽量不要与内置模块名冲突
"""
3.执行文件所在的sys.path(系统环境环境)
一定要以执行文件为准!!!
我们可以将模块所在的路径也添加到执行文件的sys.path中即可
import sys
print(sys.path) # 列表
sys.path.append(r'D:\pythonProject03\day17\mymd')
import ccc
print(ccc.name)
绝对导入与相对导入
"""
再次强调:一定要分清楚谁是执行文件!!!
模块的导入全部以执行文件为准
"""
绝对导入
from mymd.aaa.bbb.ccc.ddd import name # 可以精确到变量名
from mymd.aaa.bbb.ccc import ddd # 也可以精确到模块名
ps:套路就是按照项目根目录一层层往下查找
相对导入
.在路径中表示当前目录
..在路径中表示上一层目录
..\..在路径中表示上上一层目录
不在依据执行文件所在的sys.path 而是以模块自身路径为准
from . import b
相对导入只能用于模块文件中 不能在执行文件中使用
'''
相对导入使用频率较低 一般用绝对导入即可 结构更加清晰
'''
包
大白话:多个py文件的集合>>>:文件夹
专业:内部含有__init__.py文件的文件夹(python2必须要求 python3无所谓)
包的具体使用
虽然python3对包的要求降低了 不需要__init__.py也可以识别 但是为了兼容性考虑最好还是加上__init__.py
1.如果只想用包中某几个模块 那么还是按照之前的导入方式即可
from aaa import md1, md2
2.如果直接导入包名
import aaa
导入包名其实就是导包下面的__init__.py文件,该文件内有什么名字就可以通过包名点什么名字
编程思想的转变
1.面条版阶段
所有的代码全部堆叠在一起
2.函数版阶段
根据功能的不同封装不同的函数
3.模块版阶段
根据功能的不同拆分成不同的py文件
"""
第一个阶段可以看成是直接将所有的数据放在C盘(开始学习时期)
视频 音频 文本 图片
第二个阶段可以看成是将C盘下的数据分类管理
视频文件夹 音频文件夹 文本文件夹 图片文件夹
第三个阶段可以看成是将C盘下的数据根据功能的不同划分到更合适的位置
系统文件夹 C盘
视频文件夹 D盘
图片文件夹 E盘
ps:类似于开公司(小作坊 小公司 上市公司)
为了资源的高效管理
"""
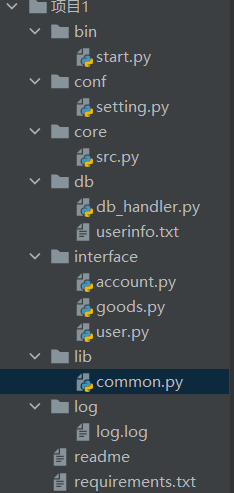
软件开发目录规范
1.文件及目录的名字可以变换 但是思想是不变的 分类管理
2.目录规范主要规定开发程序的过程中针对不同的文件功能需要做不同的分类
myproject项目文件夹
1.bin文件夹 主要存放项目启动文件
start.py 启动文件可以放在bin目录下 也可以直接在项目根目录
2.conf文件夹 主要存放项目配置文件
settings.py 里面存放项目的默认配置 一般都是全大写
3.core文件夹 主要存放项目核心文件
src.py 里面存放项目核心功能
4.interface文件夹 主要存放项目接口文件
goods.py 根据具体业务逻辑划分对应的文件
user.py
account.py
5.db文件夹 主要存放项目相关数据
userinfo.txt
db_handler.py 存放数据库操作相关的代码
6.log文件夹 主要存放项目日志文件
log.log
7.lib文件夹 主要存放项目公共功能
common.py
8.readme文件 主要存放项目相关说明
9.requirements.txt文件 主要存放项目所需模块及版本
常用内置模块之collections模块
1具名元组:namedtuple
from collections import namedtuple #导入 collections包的namedtuple方法
point = namedtuple('点',['x','y'])
p=point(1,2)
print(p) #点(x=1, y=2)
print(p.x) #1
print(p.y) #2
card=namedtuple('扑克牌',['num','cplor'])
c1=card('A','黑桃')
c2=card('B','红桃')
print(c1,c1.num,c1.cplor) #扑克牌(num='A', cplor='黑桃') A 黑桃
print(c2,c2.num,c2.cplor) #扑克牌(num='B', cplor='红桃') B 红桃
#deque
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import *
point=namedtuple('point',['x','y','r'])
print(point(1, 2,3))
q=deque(['a','b','c'])
q.append('x')
q.appendleft('y')
print(q)
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用
d=dict([('a', 1), ('b', 2), ('c', 3)])
print(d)#{'a': 1, 'b': 2, 'c': 3}
od=OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od)#OrderedDict([('a', 1), ('b', 2), ('c', 3)])
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
原生字典解决方法
for value in values:
if value>66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
print(my_dict)#defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value
from collections import *
c=Counter('asassdasdas')
print(c) #Counter({'s': 5, 'a': 4, 'd': 2})
2.队列
队列与堆栈
队列:先进先出
堆栈:先进后出
对插入和删除操作的限定不同
1. 队列:只能在表的一端进行插入,并在表的另一端进行删除;
2. 栈:只能在表的一端插入和删除
队列和堆栈都是一边只能进一边只能出
常用内置模块之时间模块
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。
"""
三种时间表现形式
1.时间戳
秒数
2.结构化时间
主要是给计算机看的 人看不适应
3.格式化时间
主要是给人看的
"""
import time
print(time.time()) #1666164179.9794426
print(time.time_ns())#1666164179979442700
print(time.localtime()) #time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=15, tm_min=20, tm_sec=59, tm_wday=2, tm_yday=292, tm_isdst=0)
print(time.strftime('%Y-%m-%d')) #2022-10-19
print(time.strftime('%Y/%m/%d')) #2022/10/19
print(time.strftime('%Y-%m-%d %H-%M-%S')) #2022-10-19 15-25-56
print(time.strftime('%Y-%3m-%d %X'))#2022-10-19 15:27:40
time.sleep(10)#暂停10秒
print(time.asctime())#Wed Oct 19 16:03:59 2022

python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
#时间戳-->结构化时间
#time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致
#time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
>>>time.gmtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
>>>time.localtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
#结构化时间-->时间戳
#time.mktime(结构化时间)
>>>time_tuple = time.localtime(1500000000)
>>>time.mktime(time_tuple)
1500000000.0
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)

#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
import time
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S'))
dif_time=time_now-true_time
struct_time=time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,
struct_time.tm_mday-1,struct_time.tm_hour,
struct_time.tm_min,struct_time.tm_sec))
计算时间差
datetime模块
import datetime
print(datetime.datetime.now()) # 2022-10-19 17:17:00.951505
print(datetime.datetime.today()) # 2022-10-19 17:17:00.951505
print(datetime.date.today()) # 2022-10-19
a=datetime.datetime.utcnow()
print(a) #2022-10-19 09:22:51.151990
c=datetime.datetime(2017, 5, 23, 12, 20)
print('指定日期:',c) #指定日期: 2017-05-23 12:20:00
from datetime import *
from datetime import datetime
d=datetime.strptime('2017/9/30','%Y/%m/%d')
print(d)
e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六')
print(e)
f=datetime.strptime('2017年9月30日星期六8时42分24秒','%Y年%m月%d日星期六%H时%M分%S秒')
print(f)
g=datetime.strptime('9/30/2017','%m/%d/%Y')
print(g)
h=datetime.strptime('9/30/2017 8:42:50 ','%m/%d/%Y %H:%M:%S ')
print(h)
from datetime import datetime
i=datetime(2017,9,28,10,3,43)
print(i.strftime('%Y年%m月%d日%A,%H时%M分%S秒'))
j=datetime(2017,9,30,10,3,43)
print(j.strftime('%A,%B %d,%Y'))
k=datetime(2017,9,30,9,22,17)
print(k.strftime('%m/%d/%Y %I:%M:%S%p'))
l=datetime(2017,9,30)
print(l.strftime('%B %d,%Y'))
常用内置模块之随机数模块
import random
print(random.random()) # 随机产生0到1之间的小数
print(random.randint(1, 6)) # 随机产生1到6之间的整数
print(random.randrange(1, 100, 2)) # 随机产生指定的整数
print(random.choice(['一等奖', '二等奖', '三等奖', '谢谢惠顾'])) # 随机抽取一个样本 '二等奖'
print(random.choices(['一等奖', '二等奖', '三等奖', '谢谢惠顾'])) # 随机抽取一个样本 ['二等奖']
print(random.sample(['jason', 'kevin', 'tony', 'oscar', 'jerry', 'tom'], 2)) # 随机抽指定样本数 ['tom', 'jerry']
l1 = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
random.shuffle(l1) # 随机打乱数据集
print(l1)
'''产生图片验证码: 每一位都可以是大写字母 小写字母 数字 4位'''
def get_code(n):
code = ''
for i in range(n):
# 1.先产生随机的大写字母 小写字母 数字
random_upper = chr(random.randint(65, 90))
random_lower = chr(random.randint(97, 122))
random_int = str(random.randint(0, 9))
# 2.随机三选一
temp = random.choice([random_upper, random_lower, random_int])
code += temp
return code
res = get_code(10)
print(res)
res = get_code(4)
print(res)
Python3 OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
import os
# 1创建目录
# os.mkdir(r'd1')# 相对路径 在执行文件所在的路径下创建目录 可以创建单级目录
# os.mkdir(r'd2\d22\d22')#不可以创建多级目录
# os.makedirs(r'd2\d22\d22')#可以创建多级目录
# os.makedirs(r'd3')#也可以创建单级目录
# 2删除目录(文件夹)
# os.rmdir(r'd1')#删除单级目录
# os.rmdir(r'd2\d22\d22')#不可以删除多级目录
# os.removedirs(r'd2\d22')#可以删除多级目录
# os.removedirs(r'd3')#可以删除空的多级目录
# 3列举指定路径下内容名称
# print(os.listdir())#默认执行文件同级目录
# print(os.listdir(r'D:\\'))#可以添加路径
# 4删除\重命名文件
# os.remove(r'4.py')#删除文件
# os.rename(r'0403.py',r'aa.py')#重命名文件
# 5获取、切换当前工作目录
# print(os.getcwd())#current working directory #G:\pythonxiangmu
# os.chdir('..')#G:\
# print(os.getcwd())
# 6动态获取项目根路径
# print(os.path.abspath(__file__))#获取执行文件的绝对路径 G:\pythonxiangmu\管理系统.py
# print(os.path.dirname(__file__))#获取执行文件所在的目录路径 #G:/pythonxiangmu
# 7判断路径是否存在
# print(os.path.exists(r'管理系统.py'))#判断文件路径是否存在 存在为True 否者为False
# print(os.path.exists(r'G:\pythonxiangmu\管理系统.py'))#判断路径是否存在 存在为True 否者为False
# print(os.path.isfile(r'管理系统.py'))#判断路径是否是文件 True
# print(os.path.isfile(r'G:\pythonxiangmu\管理系统.py'))#True
# 8路径拼接
# s1=r'G:\pythonxiangmu'
# s2=r'管理系统.py'
# print(os.path.join(s1,s2))
# 9获取文件大小
# print(os.path.getsize(r'管理系统.py'))
sys模块
import sys
# print(sys.path)#获取执行文件的sys.path
# print(sys.getrecursionlimit())
# sys.setrecursionlimit(2000)
# print(sys.version)#3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
# print(sys.getrecursionlimit())
# print(sys.platform)#win32
res=sys.argv
if len(res)!=3:
print('执行命令缺少了用户名或密码')
else:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('jason您好 文件正常执行')
else:
print('您不是jason无权执行该文件')
json模块
json模块也称为序列化模块 序列化可以打破语言限制实现不同编程语言之间数据交互
json格式数据的作用
json格式数据的形式
字符串类型并且引号都是双引号
json相关操作
针对数据
json.dumps()
json.loads()
针对文件
json.dump()
json.load()
json实战
用户登录注册功能
import os
import json
# 注册功能
# 1.获取执行文件所在的目录路径
base_dir = os.path.dirname(__file__) # D:/pythonProject03/day19
# 2.拼接出db目录的路径
db_dir = os.path.join(base_dir, 'db') # D:/pythonProject03/day19/db
# 3.创建db目录
if not os.path.isdir(db_dir):
os.mkdir(db_dir)
# 4.获取用户数据
# username = input('username>>>:').strip()
# password = input('password>>>:').strip()
# 4.1.判断用户名是否已存在
# print(os.listdir(db_dir)) # ['jason.json', 'kevin.json', 'tony.json'] 方式1
# user_file_path = os.path.join(db_dir, f'{username}.json') 方式2
# 5.构造用户字典
# user_dict = {
# 'username': username,
# 'password': password,
# 'account': 15000, # 账户余额
# 'shop_car': [] # 购物车
# }
# 6.拼接存储用户数据的文件路径
# user_file_path = os.path.join(db_dir, f'{username}.json') # D:/pythonProject03/day19/db/jason.json
# 7.写入文件数据
# with open(user_file_path,'w',encoding='utf8') as f:
# json.dump(user_dict, f)
username = input('username>>>:').strip()
# 1.拼接上述用户名组成的文件路径
target_user_file_path = os.path.join(db_dir, f'{username}.json')
if not os.path.isfile(target_user_file_path):
print('你赶紧滚蛋 用户名都不对 搞什么飞机')
else:
password = input('password>>>:').strip()
# 2.获取用户真实数据字典
with open(target_user_file_path,'r',encoding='utf8') as f:
real_user_dict = json.load(f)
if password == real_user_dict.get('password'):
print('登录成功')
else:
print('密码错误')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号