代码随想录算法训练营第8天|右旋转字符串、28. 实现 strStr()、459.重复的子字符串
右旋转字符串
2025-01-29 11:04:35 星期三
题目描述:右旋转字符串
文档讲解:代码随想录(programmercarl)右旋转字符串
这个题的思路,和昨天的151.反转字符串里的单词是一个思路,都是先全部反转字符,之后对每个部分再单独进行一下反转
梳理
-
写一个void函数,对指定区间的元素进行交换。这里写的函数也是左闭右闭的
-
对全部字符串进行反转
-
对到
[0,k - 1]的元素进行交换,和[k, s.size() - 1]的元素进行交换
卡码网测试
整体代码比较简单,就是如果想用库函数reverse(),在卡码网上需要手动# include<algorithm>
点击查看代码
# include<iostream>
using namespace std;
void reverse(string& s, int start, int end) {
int i = start, j = end;
for (; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
int main() {
int k;
string s;
cin >> k;
cin >> s;
reverse(s, 0, s.size() - 1);
reverse(s, 0, k - 1);
reverse(s, k, s.size() - 1);
cout << s;
}
LeetCode28
题目描述:力扣28
文档讲解:代码随想录(programmercarl)28. 实现 strStr()
视频讲解:《代码随想录》算法视频公开课:帮你把KMP算法学个通透!B站(理论篇);《代码随想录》算法视频公开课:帮你把KMP算法学个通透!(求next数组代码篇
代码随想录视频内容简记
KMP算法的目的其实就是为了减小字符串匹配过程中的时间复杂度,提高匹配的效率,用前缀表,求最长相等前后缀长度就是这一目的具体实现方式。
求next数组梳理
核心分为四步
-
初始化
-
前后缀不相等的情况
-
前后缀相等的情况
-
更新
next数组
大致代码内容
我们首先定义一个文本串和一个模式串
文本串:aabaabaaf
模式串:aabaaf
-
首先定义
i,j,分别指向后缀的末尾和前缀的末尾,同时,j的值代表了最长相等前后缀的长度。初始getNext(int* next, string& s),s表示模式串 -
next数组的第0位默认数值为0,j指向第0位,让i指向第1位。我们的
for (int i = 1; i < s.size(); i++),如果s[j] != s[i],则让j进行回退,回退到前一个字符的next数组对应的下标位置,注意这里的回退是连续回退,所以用的是while,同时要保证j > 0,while (j > 0 && s[j] != s[i]),j = next[j - 1] -
如果前缀和后缀相等,
if (s[j] == s[i]),则需要对j进行++操作,让next数组中的j对应的值+1。 -
因为无论前后缀相不相等,j指针都需要向后移动,并给
next[i]进行赋值,所以进行next[i] = j
使用next数组做匹配梳理
核心也是四步
-
对一个文本串和一个模式串做匹配,检查模式串是否在文本串中并返回第一次匹配的下标
-
文本串的i指针不回退,若发生失配,则模式串的指针j回退,并继续匹配
-
若两个指针所指的元素相等,则共同向下移动
-
一旦发生第一次全匹配的情况,就
return
大致代码内容
-
用s表示文本串,用t表示模式串,则用i指针指向文本串,j指针指向模式串。
-
也是一个for循环,
for (; i < s.size(); i++),while (j > 0 && s[i] != t[j]) j = next[j - 1] -
if (s[i] == s[j]) j++ -
最后就是为了实现找出文本串中第一个匹配项的下标,我们需要设置一个if判断,一旦模式串的指针j自增超过了t.size(),那么立即
return i - t.size() + 1。这种情况是为了应对这种用例,文本串"sadbutsad"和模式串"sad"
刚开始的代码是这样的
for (; i < haystack.size(); i++) {
while (j > 0 && needle[j] != haystack[i]) {
j = next[j - 1];
}
if (needle[j] == haystack[i]) j++;
}
if (j == needle.size()) return i - needle.size();

这样写有个问题,就会是等i遍历完之后,返回的i值是不及时的,并不是一旦匹配好之后立即返回,会有滞后。同时,因为没有合适的循环出口,每次匹配好"sad"之后,就会进行j++操作发生失配,所以稍微变动一下用例就会出现这种情况
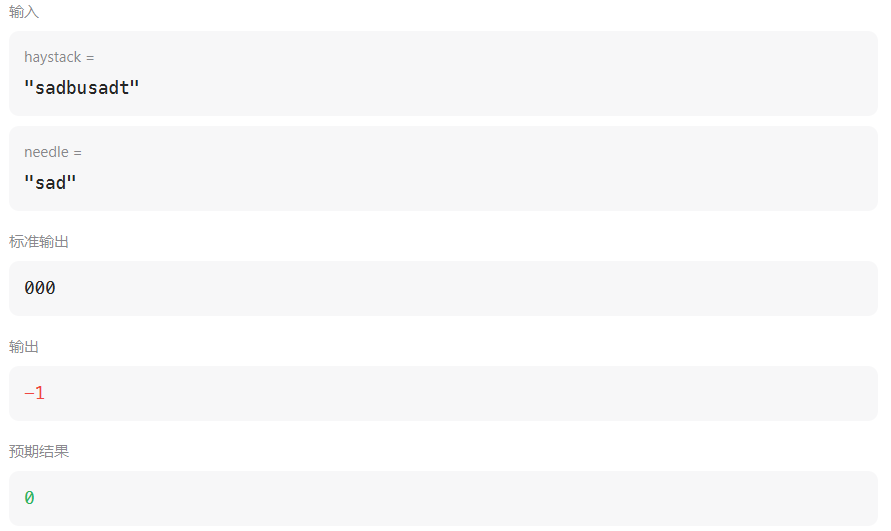
所以正确的代码应该是这样的
for (; i < haystack.size(); i++) {
while (j > 0 && needle[j] != haystack[i]) {
j = next[j - 1];
}
if (needle[j] == haystack[i]) j++;
if (j == needle.size()) return i - needle.size() + 1;
}
LeetCode测试
这个比较不好写,我写的next数组是没有进行-1和右移一位的操作的,还需要注意一点的是在调用getNext()函数时,需要注意写法getNext(&next[0], needle);
完整代码如下:
点击查看代码
class Solution {
public:
void getNext(int* next, string& s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[j] != s[i]) j = next[j - 1];
if (s[j] == s[i]) j++;
next[i] = j;
}
}
int strStr(string haystack, string needle) {
int j = 0, i = 0;
vector<int> next(needle.size());
getNext(&next[0], needle);
for (int k = 0; k < next.size(); k++) cout << next[k];
for (; i < haystack.size(); i++) {
while (j > 0 && needle[j] != haystack[i]) {
j = next[j - 1];
}
if (needle[j] == haystack[i]) j++;
if (j == needle.size()) return i - needle.size() + 1;
}
return -1;
}
};
LeetCode459
题目描述:力扣459
文档讲解:代码随想录(programmercarl)459.重复的子字符串
视频讲解:《代码随想录》算法视频公开课:字符串这么玩,可有点难度! | LeetCode:459.重复的子字符串
代码随想录视频内容简记
移除匹配
这种方法的想法就是:任何一个字符串s如果是由他的子串重复而构成的,那么他一定可以拆成前后相等的两部分。举个例子,比如"ababab",可以看成"abab"和"abab"相加得到(中间有重叠没有关系)。[代码随想录有配图详细描述]
由此,将s自己相加得到ss,去除首尾元素,如果s并出现在相加后的字符串ss的中间,那么s就是由重复的字串构成的。比如,字符串"abcabc"是由"abc"构成的,那么他自己相加得到"abcabcabcabc",去除首尾的"a"和"c",得到"bcabcabcab",仍可以搜索到s,那么就可以判断是true
因为题目并不需要返回最小的重复字串,所以按照上面的想法是可行的,只需要返回true或false即可,对最小的重复字串"abc"并不关心
梳理
-
将两个字符串进行相加
-
使用
erase()函数去除首元素和尾元素 -
使用
find()函数查找一个中间的s
大致代码内容
-
ss = s + s; -
ss.erase(ss.begin()); ss.erase(ss.end() - 1);,注意这里有-1的操作 -
if (ss.find(s) != std::string::npos) return true;,注意这里的写法,之前在349.两个数组的交集中,用set实现在哈希表中进行查询使用find()写法是这样的num_set.find(nums2[i]) != num_set.end()注意区分
KMP算法
首先回顾一下KMP算法就是为了去判断一个字符串是否出现在另一个字符串中。而在这道题目中使用KMP算法有一个结论,就是如果一个字符串是由他的子字符串重复构成的,那么这个字符串减去他的最长相等前缀就是最小的重复字串(或者减去他的最长相等后缀)。具体的推导过程请移步[代码随想录重复的子字符串推导部分]
梳理
-
首先计算next数组
-
做一个判断
大致代码内容
-
做一个判断
if (next[s.size() - 1] != 0 && len(s) % len(s) - next(s.size() - 1) == 0),则返回true即可。因为next(s.size() - 1计算得到的就是字符串长度减去他的最长前后缀的长度,如果他是由重复的子字符串构成的,那么此时就得到了他的最小重复子串,也就是取模一定是0。 -
注意,这里
next[s.size() - 1] != 0主要针对一些用例比如"abcd",最后一位的next数组值一旦为0就一定不可能是重复字串构成的,所以这里要注意判断条件
LeetCode测试
移除匹配
点击查看代码
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string ss;
ss = s + s;
ss.erase(ss.begin()); ss.erase(ss.end() - 1);
if (ss.find(s) != std::string::npos) return true;
else return false;
}
};
KMP算法
点击查看代码
class Solution {
public:
void getNext(int* next, string& s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[j] != s[i]) j = next[j - 1];
if (s[j] == s[i]) j++;
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
vector<int> next(s.size(), 0);
getNext(&next[0], s);
if (next[s.size() - 1] && s.size() % (s.size() - next[s.size() - 1]) == 0) return true;
else return false;
}
};


 浙公网安备 33010602011771号
浙公网安备 33010602011771号