XML
XML基本介绍
XML即可扩展标记语言(Extensible Markup Language)
特点
- 可扩展的, 标签都是自定义的
- 语法十分严格
XML的功能
- 存储数据,使数据的可移植性更强
- 配置文件,作为各种技术框架的配置文件使用(最多)
- 在网络中传输,客户端可以使用XML格式向服务器端发送数据,服务器接收到xml格式数据,进行解析
XML的语法
- 文档声明(必写在第一行)
<?xml version="1.0" encoding="UTF-8"?> - 元素的命名规则
- 不能使用空格,不能使用冒号
- xml 标签名称区分大小写
- XML 必须有且只有一个根元素
语法格式
<?xml version="1.0" encoding="utf-8" ?>
<users>//根元素
<hello> 大家好 </hello>//普通元素
</users>
- 属性
- 属性是元素的一部分,它必须出现在元素的开始标签中
- 属性的定义格式:属性名=属性值,其中属性值必须使用单引或双引
- 一个元素可以有0~N个属性,但一个元素中不能出现同名属性
- 属性名不能使用空格、冒号等特殊字符,且必须以字母开头
<bean id="" class=""> </bean>
用XML描述一张数据表

<?xml version="1.0" encoding="UTF-8" ?>
<bookstore>
<book id="book1">
<name>西游记</name>
<author>吴承恩</author>
<price>89</price>
</book>
<book id="book2">
<name>红楼梦</name>
<author>曹雪芹</author>
<price>109</price>
</book>
<book id="book3">
<name>Java编程思想</name>
<author>埃克尔</author>
<price>69</price>
</book>
</bookstore>
XML约束
编写一个文档来约束一个XML文档的书写规范
- 常见的XML约束:DTD,Schema
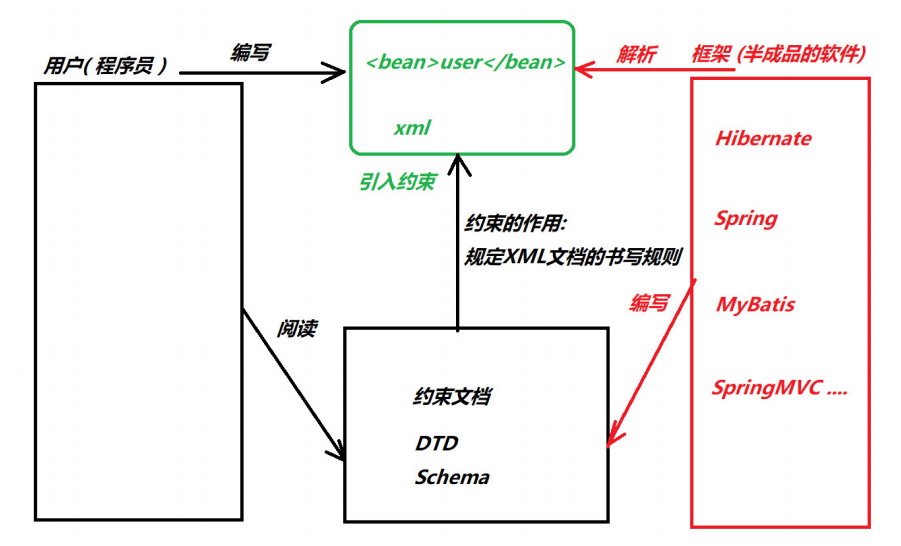
DTD约束
DTD(Document Type Definition),文档类型定义,用来约束XML文档。规定XML文档中元素的名
称,子元素的名称及顺序,元素的属性等。
Schema约束
- Schema是新的XML文档约束, 比DTD强大很多,是DTD 替代者;
- Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml。
- Schema 功能更强大,内置多种简单和复杂的数据类型
- Schema 支持命名空间 (一个XML中可以引入多个约束文档)
XML解析
为不同问题提供不同的解析方式,并提交对应的解析器,方便开发人员操作XML。
两种解析方式:
- DOM:解析器把整个XML文档装载到内存,解析成一个Document对象。
- 优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
- 缺点:XML文档过大,可能出现内存溢出显现。
- SAX:速度更快更有效,逐行扫描并解析,以事件驱动的方式进行,每执行一行,都将触发对应的事件。
- 优点:占用内存少 处理速度快,可以处理大文件
- 缺点:只能读,逐行后将释放资源。
XML解析器介绍
- DOM4J
使用核心类SaxReader加载xml文档获得Document,通过Document 对象获得文档的根元素
常用API如下:
SaxReader对象 ———— read(…) 加载执行xml文档
Document对象 ———— getRootElement() 获得根元素
Element对象 ———— elements(…) 获得指定名称的所有子元素。可以不指定名称
element(…) 获得指定名称的第一个子元素。可以不指定名称
getName() 获得当前元素的元素名
attributeValue(…) 获得指定属性名的属性值
elementText(…) 获得指定名称子元素的文本值
getText() 获得当前元素的文本内容
// 1.获取XML解析对象`
SAXReader reader = new SAXReader();
// 2.解析XML 获取 文档对象 document
Document document = reader.read("(文件位置)\user.xml");
XPath方式读取XML
XPath 是一门在 XML 文档中查找信息的语言。 可以是使用xpath查找xml中的内容。
DOM4J解析XML时只能一层一层解析,文件层数多时使用不便,结合XPath可以直接获取到某个元素
常用API方法:
selectSingleNode(query): 查找和 XPath 查询匹配的一个节点。—————— 参数是Xpath 查询串。
selectNodes(query): 得到的是xml根节点下的所有满足 xpath 的节点;————参数是Xpath 查询串。
Node: 节点对象
//3.调用 selectSingleNode() 方法,获取name节点对象
Node node1 = document.selectSingleNode("/bookstore/book/name")
JDBC自定义XML
- 创建自定义xml 文件, 保存 数据库连接信息
jdbc-config.xml
- 编写工具类 ,使用xpath 读取数据库信息
1.定义字符串变量, 记录获取连接所需要的信息
2.静态代码块 //使用 xpath读取 xml中的配置信息 //注册驱动
3.获取连接的静态方法 - 测试
1.获取连接
2.获取 statement ,执行SQL
3.处理结果集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号