


深入理解C语言中的指针与数组之指针篇(转载)
前言
其实很早就想要写一篇关于指针和数组的文章,毕竟可以认为这是C语言的根本所在。相信,任意一家公司如果想要考察一个人对C语言的理解,指针和数组绝对是必考的一部分。
但是之前一方面之前一直在忙各种事情,一直没有时间静下心来写这些东西,毕竟这确实是一件非常耗费时间和精力的事情;一方面,个人对C语言的掌握和理解也还有限,怕写出来的东西会对大家造成误导。当然,今天写的这些东西也肯定存在各种问题,不严谨甚至错误的地方肯定有,也希望大家来共同探讨,相互改进。
我会慢慢的写完这几章,有想法的童鞋可以和我探讨。
指针
预备知识
在深入理解指针之前,我认为有必要先复习或者学习一下计算机原理的基础知识。
计算机是如何从内存中进行取指的?
计算机的总线可以分为3种:数据总线,地址总线和控制总线。这里不对控制总线进行描述。数据总线用于进行数据信息传送。数据总线的位数一般与CPU的字长一致。一般而言,数据总线的位数跟当前机器int值的长度相等。例如在16位机器上,int的长度是16bit,32位机器则是32bit。这个计算机一条指令最多能够读取或者存取的数据长度。大于这个值,计算机将进行多次访问。这也就是我们说的64位机器进行64位数据运算的效率比32位要高的原因,因为32位机要进行两次取指和运行,而64位机却只需要一次!
地址总线专门用于寻址,CPU通过该地址进行数据的访问,然后把处于该地址处的数据通过数据总线进行传送,传送的长度就是数据总线的位数。地址总线的位数决定了CPU可直接寻址的内存空间大小,比如CPU总线长32位,其最大的直接寻址空间长232KB,也就是4G。这也就是我们常说的32位CPU最大支持的内存上限为4G(当然,实际上支持不到这个值,因为一部分寻址空间会被映射到外部的一些IO设备和虚拟内存上。现在通过一些新的技术,可以使32位机支持4G以上内存,但这个不在这里的讨论范围内)。
一般而言,计算机的地址总线和数据总线的宽度是一样的,我们说32位的CPU,数据总线和地址总线的宽度都是32位。
计算机访问某个数据的时候,首先要通过地址总线传送数据存储或者读取的位置,然后在通过数据总线传送需要存储或者读取的数据。一般地,int整型的位数等于数据总线的宽度,指针的位数等于地址总线的宽度。
计算机的基本访问单元
学过C语言的人都知道,C语言的基本数据类型中,就属char的位数最小,是8位。我们可以认为计算机以8位,即1个字节为基本访问单元。小于一个字节的数据,必须通过位操作来进行访问。
内存访问方式
如图1所示,计算机在进行数据访问的时候,是以字节为基本单元进行访问的,所以可以认为,计算每次都是从第p个字节开始访问的。访问的长度将由编译器根据实际类型进行计算,这在后面将会进行讲述。

图1 内存访问方式
想要了解更多,就去翻阅计算机组成原理和编译原理吧。
sizeof关键字
sizeof关键字是编译器用来计算某些类型的数据的长度的,以字节为基本单位。例如:
sizeof(char)=1;
sizeof(int)=4;
sizeof(Type)的值是在编译的时候就计算出来了的,可以认为这是一个常量!
什么是指针
指针其实就是数据存放的地址,图1中的p就是一个指针。在图1中,n一般是CPU的位数,32位机上,n=32。因为指针需要能够指向内存中的任意一个位置,因此,指针的长度应该是n位的,32位机器上指针长度就是32位。这和整型的长度是相等的!
在我个人的理解中,可以将指针理解成int整型,只不过它存放的数据是内存地址,而不是普通数据,我们通过这个地址值进行数据的访问,假设它的是p,意思就是该数据存放位置为内存的第p个字节。
当然,我们不能像对int类型的数据那样进行各种加减乘除操作,这是编译器不允许的,因为这样错是非常危险的!
图2就是对指针的描述,指针的值是数据存放地址,因此,我们说,指针指向数据的存放位置。
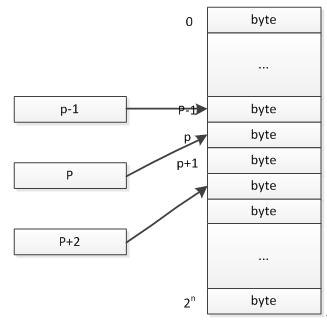
图2 指针
指针的长度
我们使用这样的方式来定义一个指针:
Type *p;
我们说p是指向type类型的指针,type可以是任意类型,除了可以是char,short, int, long等基本类型外,还可以是指针类型,例如int *, int **, 或者更多级的指针,也可是是结构体,类或者函数等。于是,我们说:
int * 是指向int类型的指针;
int **,也即(int *) *,是指向int *类型的指针,也就是指向指针的指针;
int ***,也即(int **) *,是指向int**类型的指针,也就是指向指针的指针的指针;
…我想你应该懂了
struct xxx *,是指向struct xxx类型的指针;
其实,说这么多,只是希望大家在看到指针的时候,不要被int ***这样的东西吓到,就像前面说的,指针就是指向某种类型的指针,我们只看最后一个*号,前面的只不过是type类型罢了。
细心一点的人应该发现了,在“什么是指针”这一小节当中,已经表明了:指针的长度跟CPU的位数相等,大部分的CPU是32位的,因此我们说,指针的长度是32bit,也就是4个字节!注意:任意指针的长度都是4个字节,不管是什么指针!(当然64位机自己去测一下,应该是8个字节吧。。。)
于是:
Type *p;
sizeof(p)的值是4,Type可以是任意类型,char,int, long, struct, class, int **…
以后大家看到什么sizeof(char*), sizeof(int *),sizeof(xxx *),不要理会,统统写4,只要是指针,长度就是4个字节,绝对不要被type类型迷惑!至于type是干什么用的,这个是给编译器用的,用于指针运算,这个在下面的章节中会有详细介绍。
取地址
我们说指针指向的是数据的存放地址,因此指针的值等于数据的存放地址。那么给指针赋值的时候就需要进行数据的取地址操作,这个我想不用我多说,各位也知道是&符号,没错,是&符号。
我们可以这样取地址:
Type v,*p=&v;
当然也可以:
Type v, *p;(或者Type v; Type *p)
p=&v;
这里的Type依然是任意的类型,可以是N级指针、结构体、类或者函数什么的。
指针运算
N多的面试会考这种东西了:
Type *p;
p++;
然后问你p的值变化了多少。
其实,也可以认为这是在考编译器的基本知识。因此p的值并不像表面看到的+1那么简单,编译器实际上对p进行的是加sizeof(Type)的操作。
看一个一段代码的测试结果:
- char cv='a',*pcv=&cv;
- short sv=1, *psv=&sv;
- int iv=1, *piv=&iv;
- long lv=1, *plv=&lv;
- long long llv=1, *pllv=&llv;
- float fv=1.0, *pfv=&fv;
- double dv=1.0, *pdv=&dv;
- long double ldv=1.0, *pldv=&ldv;
- //cout<<"pcv:"<<pcv<<" pcv+1: "<<pcv+1<<endl;
- cout<<"psv:"<<psv<<" psv+1: "<<psv+1<<endl;
- cout<<"piv:"<<piv<<" piv+1: "<<piv+1<<endl;
- cout<<"plv:"<<plv<<" plv+1: "<<plv+1<<endl;
- cout<<"pllv:"<<pllv<<" pllv+1: "<<pllv+1<<endl;
- cout<<"pfv:"<<pfv<<" pfv+1: "<<pfv+1<<endl;
- cout<<"pdv:"<<pdv<<" pdv+1: "<<pdv+1<<endl;
- cout<<"pldv:"<<pldv<<" pldv+1: "<<pldv+1<<endl;
- cout<<endl;
char cv='a',*pcv=&cv; short sv=1, *psv=&sv; int iv=1, *piv=&iv; long lv=1, *plv=&lv; long long llv=1, *pllv=&llv; float fv=1.0, *pfv=&fv; double dv=1.0, *pdv=&dv; long double ldv=1.0, *pldv=&ldv; //cout<<"pcv:"<<pcv<<" pcv+1: "<<pcv+1<<endl; cout<<"psv:"<<psv<<" psv+1: "<<psv+1<<endl; cout<<"piv:"<<piv<<" piv+1: "<<piv+1<<endl; cout<<"plv:"<<plv<<" plv+1: "<<plv+1<<endl; cout<<"pllv:"<<pllv<<" pllv+1: "<<pllv+1<<endl; cout<<"pfv:"<<pfv<<" pfv+1: "<<pfv+1<<endl; cout<<"pdv:"<<pdv<<" pdv+1: "<<pdv+1<<endl; cout<<"pldv:"<<pldv<<" pldv+1: "<<pldv+1<<endl; cout<<endl;
(这里注释掉char一行的原因是因为cout<<(char*)会被当成字符串输出,而不是char的地址)
执行结果:
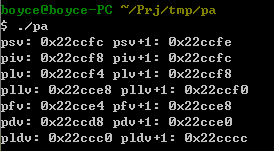
观察结果,可以看出,他们的增长结果分别是:
2(sizeof(short))
4(sizeof(int))
4(sizeof(long))
8(sizeof(long long))
4(sizeof(float))
8(sizeof(double))
12(sizeof(long double))
喏,增加的值是不是sizeof(Type)呢?别的什么struct,class之类的,就不验证你,有兴趣的自己去验证。
我们再对这样的一段代码进行汇编,查看编译器是如何进行指针的加法操作的:
- int iv=1,*piv=&iv;
- piv++;
- cout<<piv<<endl;
- piv=piv+4;
- cout<<piv<<endl;
- cout<<endl;
int iv=1,*piv=&iv; piv++; cout<<piv<<endl; piv=piv+4; cout<<piv<<endl; cout<<endl;
汇编结果:
- call ___main
- movl $1, -12(%ebp)
- leal -12(%ebp), %eax
- movl %eax, -8(%ebp)
- addl $4, -8(%ebp) /** 这里是piv++ **/
- movl -8(%ebp), %eax
- movl %eax, 4(%esp)
- movl $__ZSt4cout, (%esp)
- call __ZNSolsEPKv
- movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp)
- movl %eax, (%esp)
- call __ZNSolsEPFRSoS_E
- addl $16, -8(%ebp) /** 这里是piv+4 **/
- movl -8(%ebp), %eax
- movl %eax, 4(%esp)
- movl $__ZSt4cout, (%esp)
- call __ZNSolsEPKv
- movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp)
- movl %eax, (%esp)
- call __ZNSolsEPFRSoS_E
- movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp)
- movl $__ZSt4cout, (%esp)
- call __ZNSolsEPFRSoS_E
- movl $0, %eax
- addl $36, %esp
- popl %ecx
- popl %ebp
- leal -4(%ecx), %esp
- ret
call ___main movl $1, -12(%ebp) leal -12(%ebp), %eax movl %eax, -8(%ebp) addl $4, -8(%ebp) /** 这里是piv++ **/ movl -8(%ebp), %eax movl %eax, 4(%esp) movl $__ZSt4cout, (%esp) call __ZNSolsEPKv movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp) movl %eax, (%esp) call __ZNSolsEPFRSoS_E addl $16, -8(%ebp) /** 这里是piv+4 **/ movl -8(%ebp), %eax movl %eax, 4(%esp) movl $__ZSt4cout, (%esp) call __ZNSolsEPKv movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp) movl %eax, (%esp) call __ZNSolsEPFRSoS_E movl $__ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, 4(%esp) movl $__ZSt4cout, (%esp) call __ZNSolsEPFRSoS_E movl $0, %eax addl $36, %esp popl %ecx popl %ebp leal -4(%ecx), %esp ret
注意看注释部分的结果,我们看到,piv的值显示加了4(sizeof(int)),然后又加了16(4*sizeof(int))。
总结一点:
指针的实际运算,将会由编译器在编译的时候,根据指针指向数据类型的大小进行实际的翻译转换。指针类型的作用就在于此,让编译器能够正确的翻译这些指令的操作,另一方面,也让编译器检查程序员对指针的操作是否合法,保证程序的正确性和健壮性。
Type *p; p=p+i;
最终p的值实际上是(value of p) + i*sizeof(Type);
Type *p; p=p-i;
最终p的值实际上是(value of p) - i*sizeof(Type);
注意:指针只能进行加法和减法操作,不能进行乘除法!(指针毕竟不是普通的整数,乘除法的跨度太大了,出发还会搞出小数点神马的,这是我个人的理解。但是编译器不允许进行指针的乘除法。)
NULL指针
NULL是C语言标准定义的一个值,这个值其实就是0,只不过为了使得看起来更加具有意义,才定义了这样的一个宏,中文的意思是空,表明不指向任何东西。你懂得。不过这里不讨论空和零的区别,呵呵。
在C语言中,NULL其实就是0,就像前面说的指针可以理解成特殊的int,它总是有值的,p=NULL,其实就是p的值等于0。对于不多数机器而言,0地址是不能直接访问的,设置为0,就表示该指针哪里都没指向。
当然,就机器内部而言,NULL指针的实际值可能与此不同,这种情况下,编译器将负责零值和内部值之间的翻译转换。
NULL指针的概念非常有用,它给了你一种方法,表示某个特定的指针目前并未指向任何东西。例如,一个用于在某个数组中查找某个特定值的函数可能返回一个指向查找到的数组元素的指针。如果没找到,则返回一个NULL指针。
在内存的动态分配上,NULL的意义非同凡响,我们使用它来避免内存被多次释放,造成经常性的段错误(segmentation fault)。一般,在free或者delete掉动态分配的内存后,都应该立即把指针置空,避免出现所以的悬挂指针,致使出现各种内存错误!例如:
- int *p=(int*)malloc(sizeof(int));
- *p=23;
- free(p);
- p=NULL;
int *p=(int*)malloc(sizeof(int)); *p=23; free(p); p=NULL;
free函数是不会也不可能把p置空的。像下面这样的代码就会出现内存段错误:
- int *p=(int*)malloc(sizeof(int));
- *p=23;
- free(p);
- free(p);
int *p=(int*)malloc(sizeof(int)); *p=23; free(p); free(p);
因为,第一次free操作之后,p指向的内存已经释放了,但是p的值还没有变化,free函数改不了这个值,再free一次的时候,p指向的内存区域已经被释放了,这个地址已经变成了非法地址,这个操作将导致段错误的发生(此时,p指向的区域刚好又被分配出去了,但是这种概率非常低,而且对这样一块内存区域进行操作是非常危险的!)
但是下面这段代码就不会出现这样的问题:
- int *p=(int*)malloc(sizeof(int));
- *p=23;
- free(p);
- p=NULL;
- free(p);
int *p=(int*)malloc(sizeof(int)); *p=23; free(p); p=NULL; free(p);
因为p的值编程了NULL,free函数检测到p为NULL,会直接返回,而不会发生错误。
这里顺便告诉大家一个内存释放的小窍门,可以有效的避免因为忘记对指针进行置空而出现各种内存问题。这个方法就是自定义一个内存释放函数,但是传入的参数不知指针,而是指针的地址,在这个函数里面置空,如下:
- #include<iostream>
- #include<stdlib.h>
- using namespace std;
- void my_free(void *p){
- void **tp=(void **)p;
- if(NULL==*tp)
- return ;
- free(*tp);
- *tp=NULL;
- }
- int main(int argc, char **argv){
- int *p=new int;
- *p=1;
- cout<<p<<endl;
- my_free(&p);
- cout<<p<<endl;
- free(p);
- return 0;
- }
#include<iostream>
#include<stdlib.h>
using namespace std;
void my_free(void *p){
void **tp=(void **)p;
if(NULL==*tp)
return ;
free(*tp);
*tp=NULL;
}
int main(int argc, char **argv){
int *p=new int;
*p=1;
cout<<p<<endl;
my_free(&p);
cout<<p<<endl;
free(p);
return 0;
}
结果:

my_free调用了之后,p的值就变成了0(NULL),调用多少次free都不会报错了!
另外一个方式也非常有效,那就是定义FREE宏,在宏里面对他进行置空。例如
- #include<iostream>
- #include<stdlib.h>
- using namespacestd;
- #define FREE(x) if(x) free(x); x=NULL
- int main(intargc, char **argv){
- int *p=new int;
- *p=1;
- cout<<p<<endl;
- FREE(p);
- cout<<p<<endl;
- free(p);
- return 0;
- }
#include<iostream>
#include<stdlib.h>
using namespacestd;
#define FREE(x) if(x) free(x); x=NULL
int main(intargc, char **argv){
int *p=new int;
*p=1;
cout<<p<<endl;
FREE(p);
cout<<p<<endl;
free(p);
return 0;
}
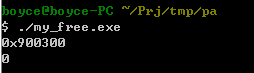
执行结果同上面一样,不会报段错误:
(关于内存的动态分配,这是个比较复杂的话题,有机会再专门开辟一章给各位讲述一下吧,写个帖子还是很花费时间和精力的,呵呵,写过的童鞋应该都很清楚,所以顺便插一句,转帖可以,请注明出处,毕竟,大家都是本着共享的精神来讨论问题的,写的好坏都没有向你所要什么,请尊重每个人的劳动成果。)
void指针
虽然从字面上看,void的意思是空,但是void指针的意思,可不是空指针的意思,空指针指的是上面所说的NULL指针。
void指针实际上的意思是指向任意类型的指针。任意类型的指针都可以直接赋给void指针,而不需要进行强制转换。
例如:
Type a, *p=&a;(Type等于char, int, struct, int *…)
void *pv;
pv=p;
就像前面说的,void指针的好处,就在于,任意的指针都可以直接赋值给它,这在某些场合非常有用,因此有些操作对于任意指针都是相同的。void指针最常用于内存管理。最典型的,也是大家最熟知的,就是标准库的free函数。它的原型如下:
void free(void*ptr);
free函数的参数可以是任意指针,没有谁见过free参数里面的指针需要强壮为void*的吧?
malloc, calloc,realloc这些函数的返回值也是void指针,因为内存分配,实际上只需要知道分配的大小,然后返回新分配内存的地址就可以了,指针的值就是地址,返回的不管是何种指针,其实结果都是一样的,因为所有的指针长度其实都是32位的(32位机器),它的值就是内存的地址,指针类型只是给编译器看的,目的是让编译器在编译的时候能够正确的设置指针的值(参见指针运算章节)。如果malloc函数设置成下面这样的原型,完全没有问题。
char*malloc(size_t sz);
实际上设置成
Type*malloc(size_t sz);
也是完全正确的,使用void指针的原因,实际上就像前面说的,void指针意思是任意指针,这样设计更加严谨一些,也更符合我们的直观理解。如果对前面我说的指针概念理解的童鞋,肯定明白这一点。
未初始化和非法指针
经常有面试,会考这样的代码校错:
int *a;
…
*a=12;
这段代码,在*a=12这里出了问题。这里的问题就在于,a究竟指向哪里?我们声明了这个变量,但是从未对它进行初始化,一般而言,没有初始化,a的值是任意的,随机的。如果a是全局变量或者static类型,它会被初始化为0(前面说过,其实指针可以理解成值是内存地址的int),但是不管哪种方式,这种方式的赋值都是非常危险的,如果你有着中体彩头号彩票的运气,a的值刚好等于某个变量或者分配内存的地址,那么这里的运行不会报错,但这时候的运气却不是什么好运,相反,是非常倒霉!因为这是对一块不属于你的内存进行操作,这实在是太危险了!如果a的初始值是个非法地址,这个赋值语句在执行的时候将会报错,从而终止程序吗,这个错误同样是段错误(segmentation fault),如果是这样,你是幸运的,因为你发现了它,这样就可以修正它。
关于这种问题,编译器可能会,也可能不会对它进行检测。GNU的编译器是会进行检测的,会对未初始化的指针或变量输出警告信息。
多级指针(也叫指针的指针)
其实如果对前面的指针概念完全理解了,这里都可以略过。指针的指针,无非就是指针指向的数据类型是指针罢了。
Type *p;
其中Type类型是指针,比如可以是int*,也可以是int **,这样p对应的就是二级指针和三级指针。一级指针的值存放的是数据的地址,二级指针的值存放的一级指针的地址,三级指针的值存放的是二级指针的地址,依此类推…
函数指针
跟普通的变量一样,每一个函数都是有其地址的,我们通过跳转到这个地址执行代码来进行函数调用,只是,跟取普通数据不同的在于,函数有参数和返回值,在进行函数调用的时候,首先需要将参数压入栈中,调用完成后又需要将参数压入栈中。既然函数也是通过地址来进行访问的,那它也可以使用指针来指向,事实上,每一个函数名都是一个指针,不过它是指针常量和指针常量,它的值是不能改的,指向的值也不能改。
(关于常量指针和指针常量什么的,有时间在专门开辟一章来说明const这个东东吧,也是很有讲头的一个东东。。。)
函数指针一般用来干什么呢?函数指针最常用的场合就是回调函数。回调函数,顾名思义,就是某个函数会在适当的时候被别人调用。当期望你调用的函数能够使用你的某些方式去操作的时候,回调函数就很有用,比如,你期望某个排序函数在比较的时候,能够使用你定义的比较方法去比较。
有过较深入的C编程经验的人应该都接触过。C的标准库中就有使用,例如在strlib.h头文件的qsort函数,它的原型为:
void qsort(void*__base, size_t __nmemb, size_t __size, int(*_compar)(const void *, const void*));
其中int(*_compar)(const void *, const void *)就是回调函数,这个函数用于qsort函数用于数据的比较。下面,我会举一个例子,来描述qsort函数的工作原理。
一般,我们使用下面这样的方式来定义函数指针:
typedef int(*compare)(const void *x, const void *y);
这个时候,compare就是参数为const void *, const void *类型,返回值是int类型的函数。例如:
- typedef int (*compare)(const void *x, const void *y);
- int my_compare(const void *x, const void *y){
- const int *a=(int *)x;
- const int *b=(int *)y;
- if(*a>*b)
- return 1;
- if(*a==*b)
- return 0;
- return -1;
- }
- void my_sort(void *data, int length, int size, compare){
- char *d1,*d2;
- //do something
- if(compare(d1,d2)<0){
- //do something
- }else if(compare(d1,d2)==0){
- //do something
- }
- else{
- //do something
- }
- //do something
- }
- int main(int argc, char **argv){
- int arr={2,4,3,656,23};
- my_sort(arr, 5, sizeof(int), my_compare);
- //do something
- return 0;
- }
typedef int (*compare)(const void *x, const void *y);
int my_compare(const void *x, const void *y){
const int *a=(int *)x;
const int *b=(int *)y;
if(*a>*b)
return 1;
if(*a==*b)
return 0;
return -1;
}
void my_sort(void *data, int length, int size, compare){
char *d1,*d2;
//do something
if(compare(d1,d2)<0){
//do something
}else if(compare(d1,d2)==0){
//do something
}
else{
//do something
}
//do something
}
int main(int argc, char **argv){
int arr={2,4,3,656,23};
my_sort(arr, 5, sizeof(int), my_compare);
//do something
return 0;
}
用typedef来定义的好处,就是可以使用一个简短的名称来表示一种类型,而不需要总是使用很长的代码来,这样不仅使得代码更加简洁易读,更是避免了代码敲写容易出错的问题。强烈推荐各位在定义结构体,指针(尤其是函数指针)等比较复杂的结构时,使用typedef来定义。
