
Paper Reading: A Brief Introduction to Weakly Supervised Learning
incomplete, 想利用未标注数据帮助训练
inexact, 笼统的数据标注,如垃圾邮件分类
inaccurate supervision, 带噪声的数据,如众包
Incomplete supervision
training data set \(D=\{(x_1,y_1),\cdots,(x_l,y_l),x_{l+1},\cdots,x_m\}\)
active learning (with human intervention)
the labeling cost only depends on the number of queries
-
informativeness: an unlabeled instance helps reduce the uncertainty of a statistical model.
1.1 Uncertainty sampling a single learner, with the least confidence
1.2 query-by-committee multiple learners, disagree to most
-
representativeness : an instance helps represent the structure of input patterns
2.1 aim to exploit the cluster structure of unlabeled data
semi-supervised learning (no human intervention is assumed)
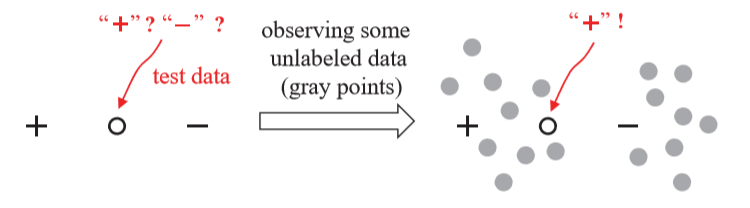
Here, although the unlabeled data points are not explicitly with label information, they implicitly convey some information about data distribution which can be helpful for predictive modelling.
two basic assumptions: the cluster assumption (data have inherent cluster structure) and the manifold assumption (data lie on a manifold).
-
generative methods
labels of unlabeled instances can be treated as missing values of model parameters, and estimated by approaches such as the EM .
To get good performance, one usually needs domain knowledge to determine adequate generative model.
-
graph based methods
the performance will heavily depends on how the graphis constructed.
-
low-density seperation methods
It is evident that S3VMs try to identify a classification boundary which goes across the less dense region while keeping the labeled data correctly classified.
-
disagreement-based methods
generate multiple learners and let them collaborate to exploit unlabeled data.
Inexact Supervision
Multi-instance learning: predict the labels for unseen bags(\(X_i\) is a positive bag, if there exists \(x_{ip}\) which is positive, while p is unknown).
Inaccurate Supervision
For machine learning, crowdsourcing is commonly used as a cost-saving way to collect labels for training data.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号