

机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
2018-01-06 16:16 bluemapleman 阅读(1760) 评论(0) 编辑 收藏 举报声明:本文翻译自Vishal Maini在Medium*台上发布的《Machine Learning for Humans》的教程的《Part 5: Reinforcement Learning》的英文原文(原文链接)。该翻译都是本人(tomqianmaple@outlook.com)本着分享知识的目的自愿进行的,欢迎大家交流!
关键词:探索和利用、马尔科夫决策过程、Q-Learning、策略学习、深度增强学习。
[Update 9/2/17] 现在本系列教程已经出了电子书了,可以在这里下载!
有问题请咨询ml4humans@gmail.com。
“我刚因为完成上个部分的任务而吃了些巧克力。”
在监督学习中,训练数据伴随着来自像神一般的“监督者”给定的相应答案,如果生活也能像这样一切有确定的答案就好了!
在强化学习(Reinforcement Learning)中,却没有答案这一说,但是你的强化学习agent仍然不得不决定如何行动以完成指定任务。在没有训练数据存在的情况下,agent从经验当中学习。 它会在尝试完成任务的过程中通过是错收集训练样例(“这个行为是好的,那个行为很糟糕”),而其目标则始终是最大化长期回报。
在《Machine Learning for Humans》系列的这最后一部分,我们将探索:
- 探索/利用之间的权衡
- 马尔科夫决策过程(MDPs),强化学习任务的经典设定
- Q-Learning,策略学习,深度学习
- 还有最后的价值学习问题
最后,我们也如往常一样提供一些好的继续可供深入探索的相关学习资源。
我们首先来把一个机器人老鼠放在迷宫里
最简单的理解强化学习的环境,就是一个有清晰目标和记分系统的游戏。
假设我们在玩一个游戏,我们的老鼠��正在寻找位于迷宫出口、作为终极回报的奶酪(��+1000分),也包括奖励稍少一点路上的水源(��+10分)。同时,机器老鼠也想避免会给它造成电击的位置。(⚡️-100分)

The reward is cheese.
在探索了一会儿后,老鼠可能就发现出口附*的、同时存在三个水滴的“小天堂”,并且它会花大量的时间充分利用这个发现,即不断地奔着这个“小天堂”而去,并且不再探索迷宫更深层的地方,以追求更高的奖励。
但是如你所见,老鼠会错失更好的东西,因为迷宫更深处有最好的奶酪!
这就带来了探索/利用(exploration/exploitation)权衡问题。一个简单的探索策略是大部分时间都采取已知最优的行动(比如80%的时候),但是偶尔进行新的探索,即随机选择前行方向,即使可能会远离已知的奖励。
这种策略叫做
需要着重记住的是,回报不总是即时的:在机器老鼠的例子里,可能在找到奶酪前,需要走过很长一段迷宫,这一段路上还有好几个需要做决策的地方。
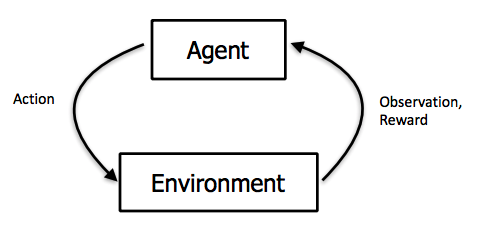
观察环境,采取行动以应对环境,并接收正或负的回报。图像来自Berkeley的CS 294:Deep Reinforcement Learning by John Schulman & Pieter Abbeel
马尔科夫决策过程(Markov Decision Processes, MDPs)
老师游荡着穿过迷宫的过程可以被规范化地描述为一个马尔科夫决策过程,这是一个由具体的状态间的转移概率的过程。我们将通过机器老鼠的例子来具体解释。MDPs包括:
- 一个有限状态的集合:这些是老师可能在迷宫中所处的位置。
- 一个在每种状态下可采取的行动的集合:在走廊里,可能是{前,后},而在交叉路口则是{前,后,左,右}。
- 状态间的迁移:比如说,如果你在一个交叉路口往左走,并以到达一个新的状态结束。这可以是一个概率的集合,这些不同的概率对应着使你到达不同状态的可能性(比如在游戏精灵宝可梦里面,如果你发动一次攻击,你有可能未击中(miss)也有可能造成一些损伤,也有可能直接将对手击出场外)。
- 和每个迁移相关联的回报:在机器老鼠例子里,大多数的回报都是0,但是当你到达有水滴或者奶酪的地方的时候是正的,而遭遇电击的时候就是负的。
- 一个[0,1]区间内的折现因子y:这量化了即使回报与未来回报之间重要性的差别。比如说,如果y=0.9,有个3步后的reward=5,那么它的现值就是
0.93∗5 。 - 无记忆性:一旦当前状态已知,老鼠就会在记忆中擦除曾经走过的迷宫路程相关的记忆,因为当前的马尔科夫状态已经包含了从历史中获得的所有有用信息。换言之,“当考虑现状时,未来和过去是独立的”。
既然我们知道了MDP是什么,我们也能规范化老鼠的目标。我们将努力最大化长期的回报总和(the sum of rewards in the long term)。
让我们来逐项看一下这个加总式。首先,我们是在每一次走新的一步时都进行加总。假设y当前值为1,那么在式子中就可以暂时忽略它。r(x,a)是回报函数。对于状态x和行动a(比如说,在一个交叉路口往左走),它将给出在状态x采取行动a的回报。回到我们的等式,我们在每个状态采取最优行动,以努力最大化未来回报的加总。
现在,我们已经建立起了一个强化学习问题,并规范化了我们的目标,接下来,让我们来探索一下可能地解决方案。
Q-learning: 学习动作-价值函数(Q-learning: learning the action-value function)
Q-learning是一种基于行动-价值函数(action-value function)来评估采取哪种行动的技术,而行动-价值函数决定了在某个状态下采取某个行动的价值。
我们有一个函数Q,它以一个状态和一个行动作为输入,并返回该状态下,采取该行动(以及后续所有行动)的期望回报。在我们探索环境之前,Q会随机给每定一些固定值。但之后,随着我们探索环境加深,Q会给我们一个越来越好地对于任一状态s下采取行动a的价值估计。我们在过程中不断对Q进行更新。
这个等式来自Wikipedia的Q-learning页面,它很好地解释了一切。它展示了如何基于从环境中获得的回报来更新Q的值:

我们再次先把折现因子y设为1以暂时忽略它。首先,记住Q应当返回当你采取行动a,并在后续状态下都采取最优行动的情况下,未来所有回报的加总。
现在,我们从左到右来看一下这个等式。当我们在状态st采取行动,我们通过给Q(st,at)原本的项加上一个新的项,这个项包含:
学习率alpha:这代表我们有多么迫切地进行更新。当alpha接*0时,我们并不急切地进行更新。当alpha接*1时,我们就是在用更新的值来替换旧值。
回报:这里的回报是我们在状态st下采取行动at的回报,所以我们要将这个回报加到我们的旧估计值上。
我们也将估计的未来回报加上了,这也是在状态xt+1对所有可采取行动的最大可实现回报的值。
最后,我们减去Q的旧值以保证我们只是在加上或减去估计值的差值(并乘上alpha)
现在我们有了一个对每个状态-行动对的估计价值,我们可以根据我们的行动-选择策略来确定采取那个行动(我们不一定每次都采取有最大期望回报的,比在
在机器老鼠的例子中,我们可以用Q-learning来求解在迷宫中每个位置对应的价值,以及在每个位置采取行动{前,后,左,右}分别的价值。然后,我们可以用我们的行动-选择策略来确定老鼠实际应该在每一步选择怎么做。
策略学习:一个状态到行动的映射(Policy learning: a map from state to action)
在Q-learning方法里,我们学习到了一个价值函数,它可以估计每个状态-行动对的价值。
策略学习是一个更加直接地迷宫问题解决方案,在这个方案下,我们学到一个策略函数(policy function),
A policy is a map from state to action.
所以我们在学习一个能最大化期望回报的函数。我们所知道的能够学习到复杂函数的工具是什么呢?深度神经网络!
Andrej Karpathy的Pong from Pixels提供了一个优秀的用深度增强学习来学习策略,玩Atari游戏Pong的流程:将游戏画面的原始像素作为输入(状态),并输出一个手柄上移或下移的概率(行动)。
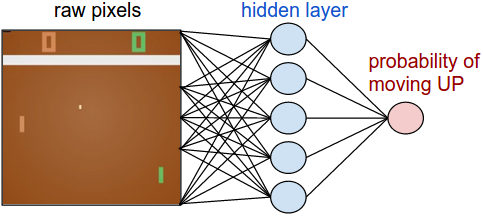
在一个策略梯度网络中,agent通过基于来自环境的回报信号的梯度下降来调整权重,以学习到最优策略。图像来自 http://karpathy.github.io/2016/05/31/rl/。
如果你想直接上手深度增强学习,看一下Andrej的博客。你将可以用130行代码实现一个2层的策略网络,并学习到如何将它嵌入到一个OpenAI的[Gym]https://gym.openai.com/()中,Gym环境下,你将可以快速地上手并运行你的第一个增强学习算法,并在一系列游戏上进行测试,并看它的表现和其它人提交的算法表现相比起来如何。
DQNs,A3C以及深度增强学习的进步(DQNs, A3C, and advancements in deep RL)
在2015年,DeepMind使用了一个称之为深度Q网络 (deep Q-networks,DQN)的方法,它可以用深度神经网络估计Q函数,并且在很多Atari游戏中超越人类玩家的表现:
我们展现了深度Q网络agent,在使用相同的算法、网络结构和超参数,并只接收像素和游戏得分作为输入的情况下,可以在49个游戏中超越所有以前算法,并且达到和职业人类游戏玩家相*的水*。这项成果消除了高维传感器输入和对应行动之间的隔阂,使得首次智能agent可以通过学习在一系列复杂任务上表现出色。(Silver et al., 2015)
这里是一个截图,它展示了DQN相比线性学习器以及人类在多个领域游戏中的表现:
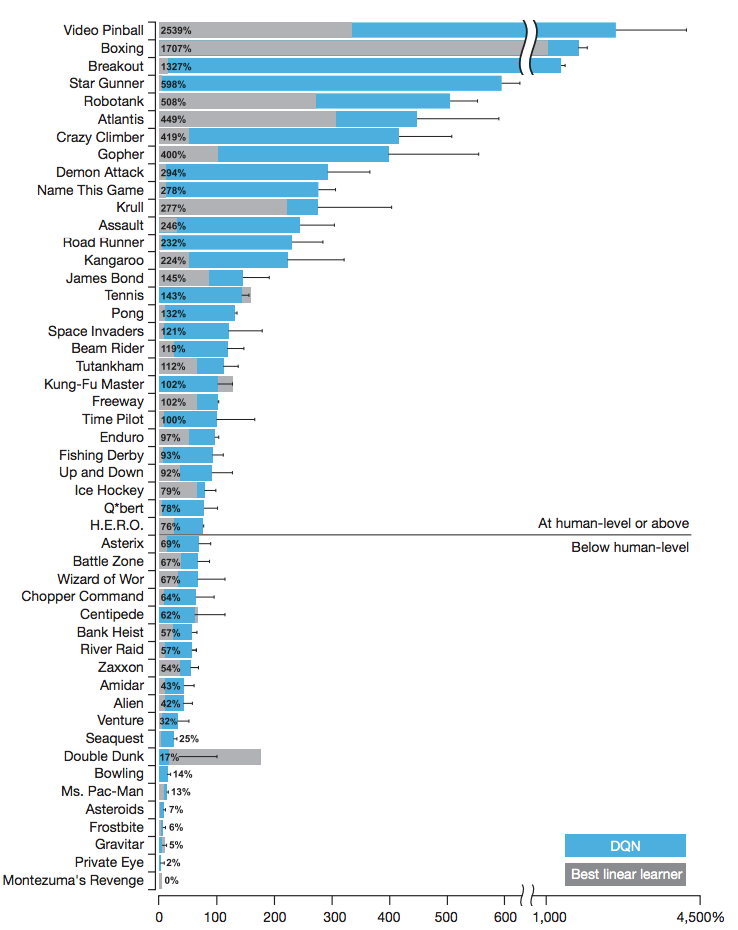
这些是以职业人类玩家的游戏表现作了规范化的:0%相当于瞎玩,100%是人类的表现。来源:DeepMind’s DQN paper, Human-level control through deep reinforcement learning。
为了帮助你更好地从直觉上理解强化学习领域正在做的研究动态,以下是一些尝试改进非线性Q函数估计器的性能以及稳定性的例子:
- 经验回放,这种方法通过随机化一个之前的观察与相应的回报更长的序列(randomizing over a longer sequence of previous observations and corresponding reward)来避免过拟合了最*的经验。这个想法是从生物大脑得到的启发:比如说,老鼠穿越迷宫时,会“回放”睡觉时的神经活动模式以最优化在迷宫中的未来行为。
- 循环神经网络增强的DQNs。当一个agent只能看到它即时的周遭环境时(比如说机器老鼠只能看到迷宫的一部分,而从鸟瞰的角度来说,可以看到整个迷宫),agent需要去记住更大的图像,如此它才能记住各个物件都在什么位置。这个很类似于人类婴孩对物体存在的认知发展,这种发展使得他们可以知道即使那个东西不在视线中了,可它依然存在。RNNs是“循环的”,也就说,它们使得信息能够更长时间的在系统中维持。这里有一个令人印象深刻的视频,关于用深度循环Q网络(deep recurrent Q-network,DQRN)来玩Doom。
Paper: https://arxiv.org/abs/1609.05521. Source: Arthur Juliani’s Simple Reinforcement Learning with Tensorflow series
(视频来自Youtube,所以需要科学上网才能观看,原视频链接)
2016年,就在DQN论文发布的一年后,DeepMind公开了另一个算法,称为异步优势Actor-Critic(Asynchronous Advantage Actor-Critic,A3C),它到目前已经超越了一半的之前在Atari游戏中最顶级的游戏表现(Mnih et al., 2016)](https://arxiv.org/pdf/1602.01783.pdf)。A3C是一种actor-critic算法,它结合了我们之前已经探索过的两种最好的算法:它使用一个actor(一个策略网络来决定如何行动)和一个critic(一个Q网络决定对象的价值)。Arthur Juliani写了一个很棒的关于A3C具体原理的文章。A3C现在也是OpenAI的统一起始agent(Universe Starter Agent)。
自那以后,就是数不清的接踵而来的令人惊叹的突破-从AI发明自己的语言来教会自己在各种地形上行走。而本系列也只是介绍了一点强化学习前沿水*的皮毛,但是希望本系列能作为一个你进行深入探索的良好起点。
在这里,我们想分享一下这个关于DeepMind的agent如何学习走路的视频……附带着一些声效。抓好爆米花,调高音量,看好了人工智能的强大能力!
������
(视频来自Youtube,所以需要科学上网才能观看,原视频链接
实用材料和扩展阅读(Practice materials & further reading)
代码(Code)
Andrej Karpathy的Pong from Pixels将带你快速入门并运行你的第一个强化学习agent。如文章所描述的,“我们将学习如何用PG玩一个Atari游戏(Pong!),利用scratch(不确定如何翻译),利用像素,还有一个深度神经网络,所有这一切只需要130行的Python代码,用到的库只有numpy。(Gist link)”
接下来,我们非常推荐Arthur Juliani的Simple Reinforcement Learning with Tensorflow(即我正在着手翻译的强化学习系列)教程。它会带你学习DQNs,策略学习,actor-critic方法,还有探索策略的TensorFlow实现。自己试着理解并重新实现这些方法。
阅读+课程(Reading + lectures)
- Richard Sutton的书Reinforcement Learning: An Introduction,非常棒的一本书,很值得一读。
- John Schulman的CS 294: Deep Reinforcement Learning (Berkeley)
- David Silver的强化学习课程(UCL)

