hadoop vs spark
http://www.zhihu.com/question/26568496#answer-12035815
Hadoop
首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
- HDFS,在由普通PC组成的集群上提供高可靠的文件存储,通过将块保存多个副本的办法解决服务器或硬盘坏掉的问题。
- MapReduce,通过简单的Mapper和Reducer的抽象,将并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来,并在一个由几十台上百太的PC组成的不可靠集群上,提供可靠的数据处理。而Mapper和Reducer的抽象,又是各种各样的复杂数据处理都可以分解为的基本元素。这样,复杂的数据处理可以分解为由多个Mapper和Reducer组成的有向无环图(DAG),然后每个Mapper和Reducer放到Hadoop集群上执行,就可以得出结果。
在MapReduce中,Shuffle是一个非常重要的过程,有了看不见的Shuffle过程,才可以使在MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。
(图片来源: Hadoop Definitive Guide By Tom White)
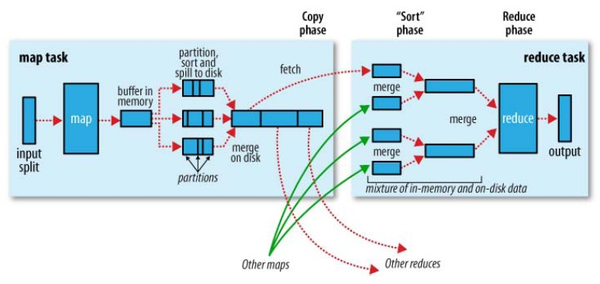
但是MapRecue存在以下局限,使用起来比较困难
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- 一个Job只有Map和Reduce两个阶段,复杂的计算需要大量的Job完成。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- 中间结果也放在文件系统中
- ReduceTask需要等待所有MapTask都完成后才可以开始
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- 对于迭代式数据处理性能比较差
Apache Pig
Apache Pig也是Hadoop框架中的一部分,Pig提供类SQL语言(Pig Latin)通过MapReduce来处理大规模半结构化数据。而Pig Latin是更高级的过程语言,通过将MapReduce中的设计模式抽象为操作,如Filter,GroupBy,Join,OrderBy,由这些操作组成数据处理流程。例如如下程序:
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
而Pig Latin又是通过编译为MapReduce,在Hadoop集群上执行的。上述程序被编译成MapReduce时,会产生如下图所示的Map和Reduce:
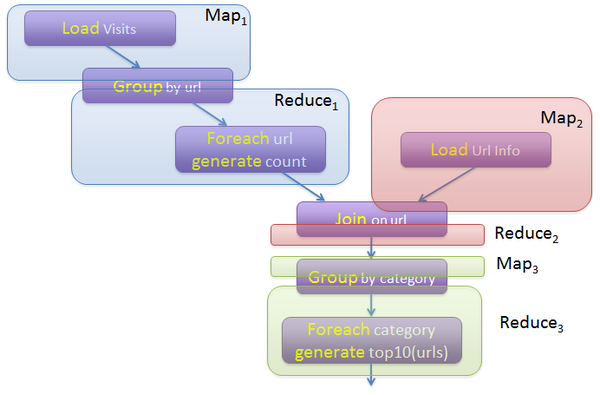
(图片来源:http://cs.nyu.edu/courses/Fall12/CSCI-GA.2434-001/sigmod08-pig-latin.ppt)
Apache Pig解决了MapReduce存在的大量手写代码,语义隐藏,提供操作种类少的问题。类似的项目还有Cascading,JAQL等。
Apache Tez
Apache Tez,Tez是HortonWorks的Stinger Initiative的的一部分。作为执行引擎,Tez也提供了有向无环图(DAG),DAG由顶点(Vertex)和边(Edge)组成,Edge是对数据的移动的抽象,提供了One-To-One,BroadCast,和Scatter-Gather三种类型,只有Scatter-Gather才需要进行Shuffle。
Tez的优化主要体现在:
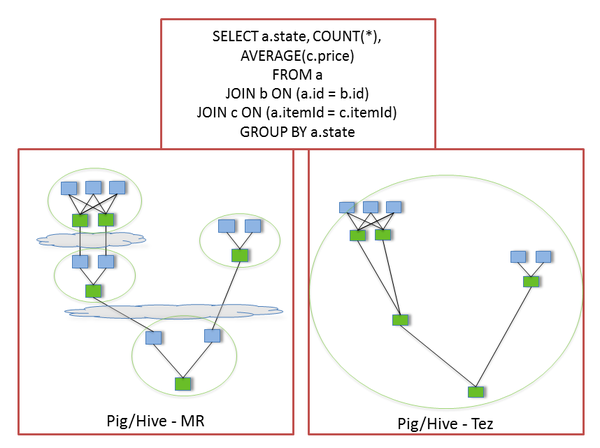
(图片来源:http://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing)
- 去除了连续两个任务之间的写操作
- 去除了每个工作流中多余的Map阶段
Apache Spark
Apache Spark也是一个大数据处理的引擎,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。
这个抽象就是RDD(Resilient Distributed Dataset),RDD就是一个不可变的带分区的记录集合。Spark提供了RDD上的两类操作,转换和动作。转换是用来定义一个新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等,动作是返回一个结果,包括collect, reduce, count, save, lookupKey。
Spark支持故障恢复的方式也不同,提供两种方式,Linage,通过数据的血缘关系,再执行一遍前面的处理,Checkpoint,将数据集存储到持久存储中。
Spark的API非常简单易用,使用Spark,WordCount的示例如下所示:
val spark = new SparkContext(master, appName, [sparkHome], [jars])
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Spark对于有向无环图对任务进行调度,确定阶段,分区,流水线,任务和缓存,进行优化,并在Spark集群上运行任务。RDD之间的依赖分为宽依赖(依赖多个分区)和窄依赖(只依赖一个分区),在确定阶段时,需要根据宽依赖划分阶段。根据分区划分任务。
(图片来源:https://databricks-training.s3.amazonaws.com/slides/advanced-spark-training.pdf)
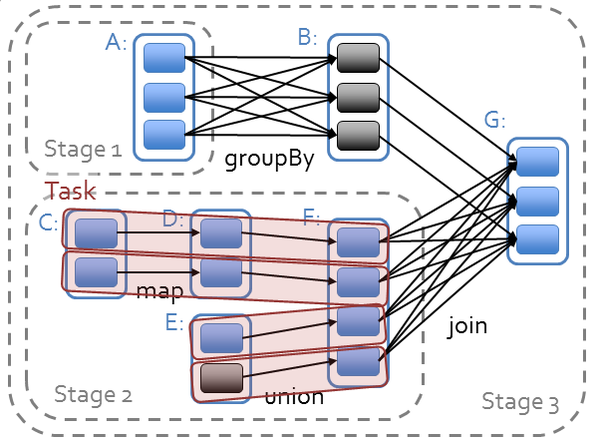
Spark为迭代式数据处理提供更好的支持。每次迭代的数据可以保存在内存中,而不是写入文件。
Spark的性能相比Hadoop有很大提升,2014年1月,Spark完成了一个Daytona Gray类别的Sort Benchmark测试,排序完全是在磁盘上进行的,与Hadoop之前的测试的对比结果如表格所示:
(表格来源: Spark officially sets a new record in large-scale sorting)
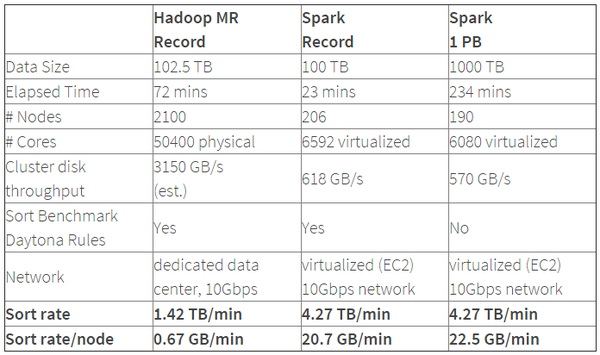
从表格中可以看出排序100TB的数据(1万亿条数据),Spark只用了Hadoop所用1/10的计算资源,耗时只有Hadoop的1/3。
Spakr的优势不仅体现在性能提升上的,Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供一个统一的平台,这相对于使用Hadoop有很大优势。
(图片来源:https://gigaom.com/2014/06/28/4-reasons-why-spark-could-jolt-hadoop-into-hyperdrive/)
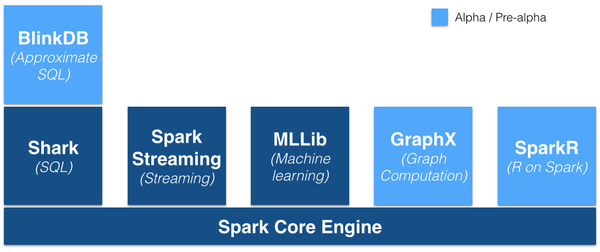
那么Spark解决了Hadoop的哪些问题呢?
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- =>基于RDD的抽象,很多代码已经在RDD转换和动作中实现。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- =>提供很多转换和动作,如Join,GroupBy这种常用的操作
- 一个Job只有Map和Reduce两个阶段,复杂的计算需要大量的Job完成。
- =>逻辑上的多个RDD的转换,在调度式可以生成多个阶段。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- =>在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。
- 中间结果也放在文件系统中
- =>中间结果放在内存中。
- ReduceTask需要等待所有MapTask都完成后才可以开始
- =>待定
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- =>通过将流拆成小的batch提供Discretized Stream处理流数据。
- 对于迭代式数据处理性能比较差
- =>通过在内存中缓存数据,提高迭代式计算的性能。
+++++++++++++++++++++++++++++++++++++++++++
如本文存在任何侵权部分,请及时告知,我会第一时间删除!
转载本博客原创文章,请附上原文@cnblogs的网址!
QQ: 5854165 我的开源项目 欢迎大家一起交流编程架构技术&大数据技术! +++++++++++++++++++++++++++++++++++++++++++
如本文存在任何侵权部分,请及时告知,我会第一时间删除!
转载本博客原创文章,请附上原文@cnblogs的网址!
QQ: 5854165 我的开源项目 欢迎大家一起交流编程架构技术&大数据技术! +++++++++++++++++++++++++++++++++++++++++++

 浙公网安备 33010602011771号
浙公网安备 33010602011771号