【转载】Spark SQL 1.3.0 DataFrame介绍、使用
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1
1.DataFrame是什么?
2.如何创建DataFrame?
3.如何将普通RDD转变为DataFrame?
4.如何使用DataFrame?
5.在1.3.0中,提供了哪些完整的数据写入支持API?![]()
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件。除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外,它还为Spark带来了通用、高效、多元一体的结构化数据处理能力。在刚刚发布的1.3.0版中,Spark SQL的两大升级被诠释得淋漓尽致。
DataFrame
就易用性而言,对比传统的MapReduce API,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame API不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
DataFrame是什么?
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。

创建DataFrame
在Spark SQL中,开发者可以非常便捷地将各种内、外部的单机、分布式数据转换为DataFrame。以下Python示例代码充分体现了Spark SQL 1.3.0中DataFrame数据源的丰富多样和简单易用:
可见,从Hive表,到外部数据源API支持的各种数据源(JSON、Parquet、JDBC),再到RDD乃至各种本地数据集,都可以被方便快捷地加载、转换为DataFrame。这些功能也同样存在于Spark SQL的Scala API和Java API中。
使用DataFrame
和R、Pandas类似,Spark DataFrame也提供了一整套用于操纵数据的DSL。这些DSL在语义上与SQL关系查询非常相近(这也是Spark SQL能够为DataFrame提供无缝支持的重要原因之一)。以下是一组用户数据分析示例:
除DSL以外,我们当然也可以像以往一样,用SQL来处理DataFrame:
最后,当数据分析逻辑编写完毕后,我们便可以将最终结果保存下来或展现出来:
幕后英雄:Spark SQL查询优化器与代码生成
正如RDD的各种变换实际上只是在构造RDD DAG,DataFrame的各种变换同样也是lazy的。它们并不直接求出计算结果,而是将各种变换组装成与RDD DAG类似的逻辑查询计划。如前所述,由于DataFrame带有schema元信息,Spark SQL的查询优化器得以洞察数据和计算的精细结构,从而施行具有很强针对性的优化。随后,经过优化的逻辑执行计划被翻译为物理执行计划,并最终落实为RDD DAG。
这样做的好处体现在几个方面:
1. 用户可以用更少的申明式代码阐明计算逻辑,物理执行路径则交由Spark SQL自行挑选。一方面降低了开发成本,一方面也降低了使用门槛——很多情况下,即便新手写出了较为低效的查询,Spark SQL也可以通过过滤条件下推、列剪枝等策略予以有效优化。这是RDD API所不具备的。
2. Spark SQL可以动态地为物理执行计划中的表达式生成JVM字节码,进一步实现归避虚函数调用开销、削减对象分配次数等底层优化,使得最终的查询执行性能可以与手写代码的性能相媲美。
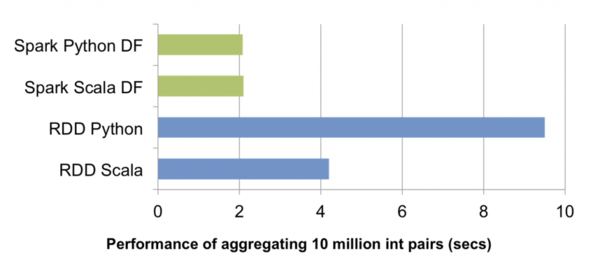
3. 对于PySpark而言,采用DataFrame编程时只需要构造体积小巧的逻辑执行计划,物理执行全部由JVM端负责,Python解释器和JVM间大量不必要的跨进程通讯得以免除。如上图所示,一组简单的对一千万整数对做聚合的测试中,PySpark中DataFrame API的性能轻松胜出RDD API近五倍。此外,今后Spark SQL在Scala端对查询优化器的所有性能改进,PySpark都可以免费获益。
外部数据源API增强

从前文中我们已经看到,Spark 1.3.0为DataFrame提供了丰富多样的数据源支持。其中的重头戏,便是自Spark 1.2.0引入的外部数据源API。在1.3.0中,我们对这套API做了进一步的增强。
数据写入支持
在Spark 1.2.0中,外部数据源API只能将外部数据源中的数据读入Spark,而无法将计算结果写回数据源;同时,通过数据源引入并注册的表只能是临时表,相关元信息无法持久化。在1.3.0中,我们提供了完整的数据写入支持,从而补全了多数据源互操作的最后一块重要拼图。前文示例中Hive、Parquet、JSON、Pandas等多种数据源间的任意转换,正是这一增强的直接成果。
站在Spark SQL外部数据源开发者的角度,数据写入支持的API主要包括:
1. 数据源表元数据持久化
1.3.0引入了新的外部数据源DDL语法(SQL代码片段)
由此,注册自外部数据的SQL表既可以是临时表,也可以被持久化至Hive metastore。需要持久化支持的外部数据源,除了需要继承原有的RelationProvider以外,还需继承CreatableRelationProvider。
2. InsertableRelation
支持数据写入的外部数据源的relation类,还需继承trait InsertableRelation,并在insert方法中实现数据插入逻辑。
Spark 1.3.0中内置的JSON和Parquet数据源都已实现上述API,可以作为开发外部数据源的参考示例。
统一的load/save API
在Spark 1.2.0中,要想将SchemaRDD中的结果保存下来,便捷的选择并不多。常用的一些包括:
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
- ....
可见,不同的数据输出方式,采用的API也不尽相同。更令人头疼的是,我们缺乏一个灵活扩展新的数据写入格式的方式。
针对这一问题,1.3.0统一了load/save API,让用户按需自由选择外部数据源。这套API包括:
1.SQLContext.table
从SQL表中加载DataFrame。
2.SQLContext.load
从指定的外部数据源加载DataFrame。
3.SQLContext.createExternalTable
将指定位置的数据保存为外部SQL表,元信息存入Hive metastore,并返回包含相应数据的DataFrame。
4.DataFrame.save
将DataFrame写入指定的外部数据源。
5.DataFrame.saveAsTable
将DataFrame保存为SQL表,元信息存入Hive metastore,同时将数据写入指定位置。
Parquet数据源增强
Spark SQL从一开始便内置支持Parquet这一高效的列式存储格式。在开放外部数据源API之后,原有的Parquet支持也正在逐渐转向外部数据源。1.3.0中,Parquet外部数据源的能力得到了显著增强。主要包括schema合并和自动分区处理。
1.Schema合并
与ProtocolBuffer和Thrift类似,Parquet也允许用户在定义好schema之后随时间推移逐渐添加新的列,只要不修改原有列的元信息,新旧schema仍然可以兼容。这一特性使得用户可以随时按需添加新的数据列,而无需操心数据迁移。
2.分区信息发现
按目录对同一张表中的数据分区存储,是Hive等系统采用的一种常见的数据存储方式。新的Parquet数据源可以自动根据目录结构发现和推演分区信息。
3.分区剪枝
分区实际上提供了一种粗粒度的索引。当查询条件中仅涉及部分分区时,通过分区剪枝跳过不必要扫描的分区目录,可以大幅提升查询性能。
以下Scala代码示例统一展示了1.3.0中Parquet数据源的这几个能力(Scala代码片段):
这段代码的执行结果为:
可见,Parquet数据源自动从文件路径中发现了key这个分区列,并且正确合并了两个不相同但相容的schema。值得注意的是,在最后的查询中查询条件跳过了key=1这个分区。Spark SQL的查询优化器会根据这个查询条件将该分区目录剪掉,完全不扫描该目录中的数据,从而提升查询性能。
小结
DataFrame API的引入一改RDD API高冷的FP姿态,令Spark变得更加平易近人,使大数据分析的开发体验与传统单机数据分析的开发体验越来越接近。外部数据源API体现出的则是兼容并蓄。目前,除了内置的JSON、Parquet、JDBC以外,社区中已经涌现出了CSV、Avro、HBase等多种数据源,Spark SQL多元一体的结构化数据处理能力正在逐渐释放。
为开发者提供更多的扩展点,是Spark贯穿整个2015年的主题之一。我们希望通过这些扩展API,切实地引爆社区的能量,令Spark的生态更加丰满和多样。
+++++++++++++++++++++++++++++++++++++++++++
如本文存在任何侵权部分,请及时告知,我会第一时间删除!
转载本博客原创文章,请附上原文@cnblogs的网址!
QQ: 5854165 我的开源项目 欢迎大家一起交流编程架构技术&大数据技术! +++++++++++++++++++++++++++++++++++++++++++
如本文存在任何侵权部分,请及时告知,我会第一时间删除!
转载本博客原创文章,请附上原文@cnblogs的网址!
QQ: 5854165 我的开源项目 欢迎大家一起交流编程架构技术&大数据技术! +++++++++++++++++++++++++++++++++++++++++++

 浙公网安备 33010602011771号
浙公网安备 33010602011771号