

本帖提供两种做法,可避免在 SQL Server 事务锁定时产生的不正常或长时间阻塞,让用户和程序也无限期等待,甚至引起 connection pooling 连接数超过容量。
所谓的「阻塞」,是指当一个数据库会话中的事务,正在锁定其他会话事务想要读取或修改的资源,造成这些会话发出的请求进入等待的状态。SQL Server 默认会让被阻塞的请求无限期地一直等待,直到原来的事务释放相关的锁,或直到它超时 (根据 SET LOCK_TIMEOUT,本文后续会提到)、服务器关闭、进程被杀死。一般的系统中,偶尔有短时间的阻塞是正常且合理的;但若设计不良的程序,就可能导致长时间的阻塞,这样就不必要地锁定了资源,而且阻塞了其他会话欲读取或更新的需求。遇到这种情况,可能就需要手工排除阻塞的状态,而本文接下来要介绍两种排除阻塞的做法。
日前公司 server-side 有组件,疑似因撰写时 exception-handling 做得不周全,导致罕见的特殊例外发生时,让 SQL Server 的事务未执行到 cmmmit 或 rollback,造成某些表或记录被「锁定 (lock)」。后来又有大量的 request,要透过代码访问这些被锁定的记录,结果造成了严重的长时间「阻塞」,最后有大量 process (进程) 在 SQL Server 呈现「等待中 (WAIT)」的状态。
由于 SQL Server 的「事务隔离级别」默认是 READ COMMITTED (事务期间别人无法读取),加上 SQL Server 的锁定造成阻塞时,默认是别的进程必须无限期等待 (LOCK_TIMEOUT = -1)。结果这些大量的客户端 request 无限期等待永远不会提交或回滚的事务,并一直占用着 connection pool 中的资源,最后造成 connection pooling 连接数目超载。
查了一些书,若我们要查询 SQL Server 目前会话中的 lock 超时时间,可用以下的命令:
SELECT @@LOCK_TIMEOUT
执行结果默认为 -1,意即欲访问的对象或记录被锁定时,会无限期等待。若欲更改当前会话的此值,可用下列命令:
SET LOCK_TIMEOUT 3000
后面的 3000,其单位为毫秒,亦即会先等待被锁定的对象 3 秒钟。若事务仍未释放锁,则会抛回如下代号为 1222 的错误信息,可供程序员编程时做相关的逾时处理:
消息 1222,级别 16,状态 51,第 3 行
已超过了锁请求超时时段。
若将 LOCK_TIMEOUT 设置为 0,亦即当欲访问对象被锁定时,完全不等待就抛回代号 1222 的错误信息。此外,此一 SET LOCK_TIMEOUT 命令,影响范例只限当前会话 (进程),而非对某个表做永久的设置。
-------------------------------------------------------------------------------------------
接下来我们在 SSMS 中,开两个会话 (查询窗口) 做测试,会话 A 创建会造成阻塞的事务进程,会话 B 去访问被锁定的记录。
BEGIN TRAN;
UPDATE Orders SET EmployeeID=7 WHERE OrderID=10248
--rollback; --故意不提交或回滚
SELECT * FROM Orders WHERE OrderID=10248
分别执行后,因为欲访问的记录是同一条,按照 SQL Server 「事务隔离级别」和「锁」的默认值,会话 B 将无法读取该条数据,而且会永远一直等下去 (若在现实项目里写出这种代码,就准备被客户和老板臭骂)。
-------------------------------------------------------------------------------------------
若将会话 B 先加上 SET LOCK_TIMEOUT 3000 的设置,如下,则会话 B 会先等待 3 秒钟,才抛出代号 1222 的「锁请求已超时」错误信息:
SET LOCK_TIMEOUT 3000
SELECT * FROM Orders WHERE OrderID=10248
--SET LOCK_TIMEOUT -1
执行结果:
消息 1222,级别 16,状态 51,第 3 行
已超过了锁请求超时时段。
语句已终止。
-------------------------------------------------------------------------------------------
另根据我之前写的文章「30 分钟快快乐乐学 SQL Performance Tuning」所述:
http://www.cnblogs.com/WizardWu/archive/2008/10/27/1320055.html
撰写不当的 SQL 语句,会让数据库的索引无法使用,造成全表扫描或全聚集索引扫描。例如不当的:NOT、OR 算符使用,或是直接用 + 号做来串接两个字段当作 WHERE 条件,都可能造成索引失效,变成全表扫描,除了性能变差之外,此时若这句不良的 SQL 语句,是本帖前述会话 B 的语句,由于会造成全表扫描或聚集索引扫描,因此就一定会被会话 A 的事务阻塞 (因为扫描全表时,一定也会读到 OrderID=10248 这一条会话 A 正在锁定的记录)。
下方的 SQL 语句,由于 OrderID 字段有设索引,因此下图 1 的「执行计划」,会以算法中的「二分查找法」在索引中快速查找 OrderID=10250 的记录。
SELECT * FROM Orders WHERE OrderID=10250
SELECT * FROM Orders WHERE OrderID=10250 AND ShipCountry='Brazil'
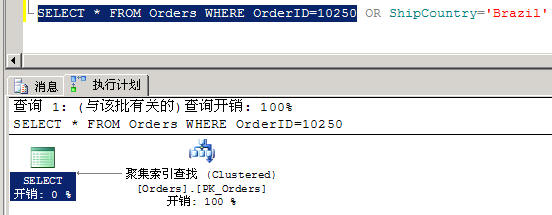
图 1 有正确使用到索引的 SQL 语句,以垂直的方向使用索引。用 AND 算符时,只要有任一个字段有加上索引,就能受惠于索引的好处,并避免全表扫描
此时若我们将这句 SQL 语句,当作前述会话 B 的语句,由于它和会话 A 所 UPDATE 的 OrderID=10248 不是同一条记录,因此不会受会话 A 事务未回滚的影响,会话 B 能正常执行 SELECT 语句。
但若我们将会话 B 的 SQL 语句,改用如下的 OR 算符,由于 ShipCountry 字段没有加上索引,此时会造成聚集索引扫描 (和全表扫描一样,会对整个表做逐条记录的 scan)。如此一来,除了性能低落以外,还会因为在逐条扫描时,读到会话 A 中锁定的 OrderID=10248 那一条记录,造成阻塞,让会话 B 永远呈现「等待中」的状态。
SELECT * FROM Orders WHERE OrderID=10250 OR ShipCountry='Brazil'

图 2 未正确使用索引的 SQL 语句,以水平的方向使用索引。用 OR 算符时,必须「所有」用到的字段都有加上索引,才能有效使用索引、避免全表扫描
-------------------------------------------------------------------------------------------
发生阻塞时,透过以下命令,可看出是哪个进程 session id,阻塞了哪几个进程 session id,且期间经过了多少「毫秒 (ms)」。如下图 3 里 session id = 53 阻塞了 session id = 52 的进程。另透过 SQL Server Profiler 工具,也能看到相同的内容。
SELECT blocking_session_id, wait_duration_ms, session_id FROM sys.dm_os_waiting_tasks

图 3 本帖前述会话 A 的 UPDATE 语句 (53),阻塞了会话 B 的 SELECT 语句 (52)
透过以下两个命令,我们还能看到整个数据库的锁定和阻塞详细信息:
SELECT * FROM sys.dm_tran_locks
EXEC sp_lock
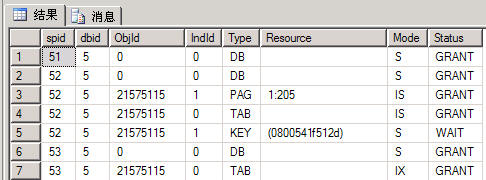
图 4 session id = 52 的 process 因阻塞而一直处于等待中 (WAIT)
另透过 KILL 命令,可直接杀掉造成阻塞的 process,如下:
KILL 53
-------------------------------------------------------------------------------------------
欲解决无限期等待的问题,除了前述的 SET LOCK_TIMEOUT 命令外,还有更省事的做法,如下,在会话 B 的 SQL 语句中,在表名称后面加上 WITH (NOLOCK) 关键字,表示要求 SQL Server,不必去考虑这个表的锁定状态为何,因此也可减少「死锁 (dead lock)」发生的机率。但 WITH (NOLOCK) 不适用 INSERT、UPDATE、DELETE。
SELECT * FROM Orders WITH (NOLOCK) WHERE OrderID=10248
类似的功能,也可如下,在 SQL 语句前,先设置「事务隔离级别」为可「脏读 (dirty read)」。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT * FROM Orders WHERE OrderID=10248
两种做法的效果类似,让会话 B 即使读到被锁阻塞的记录,也永远不必等待,但可能读到别人未提交的数据。虽然说这种做法让会话 B 不用请求共享锁,亦即永远不会和其他事务发生冲突,但应考虑项目开发实际的需求,若会话 B 要查询的是原物料的库存量,或银行系统的关键数据,就不适合用这种做法,而应改用第一种做法的 SET LOCK_TIMEOUT 命令,明确让数据库抛回等候逾时的错误代号 1222,再自己写代码做处理。
-------------------------------------------------------------------------------------------
归根究柢,我们在编程时,就应该避免写出会造成长时间阻塞的 SQL 语句,亦即应最小化锁定争用的可能性,以下为一些建议:
- 尽可能让事务轻薄短小、让锁定的时间尽量短,例如把不必要的命令移出事务外,或把一个大量更新的事务,切成多个更新较少的事务,以改善并发性。
- 将组成事务的 SQL 语句,摆到一个「批 (batch) 处理」,以避免不必要的延迟。这些延迟常由 BEGIN TRAN ... COMMIT TRAN 命令之间的网络 I/O 所引起。
- 考虑将事务的 SQL 语句写在一个存储过程内。一般来说,存储过程的执行速度会比批处理的 SQL 语句快,且存储过程可降低网络的流量和 I/O,让事务可更快完成。
- 尽可能频繁地认可 Cursor 中的更新,因为 Cursor 的处理速度较慢,会让锁定的时间较长。
- 若无必要,使用较宽松的事务隔离级别,如前述的 WITH (NOLOCK) 和 READ UNCOMMITTED。而非为了项目开发方便,全部使用默认的 READ COMMITTED 级别。
- 避免在事务执行期间,还要等待用户的反馈或交互,这样可能会造成无限期的持有锁定,如同本帖一开始提到的状况,最后造成大量的阻塞和数据库 connection 被占用。
- 避免事务 BEGIN TRAN 后查询的数据,可能在事务开始之前先被引用。
- 避免在查询时 JOIN 过多的表 (此指非必要的 JOIN),否则除了性能较差外,也很容易读到正被锁定或阻塞中的表和字段。
- 应注意在一个没有索引的表上,过量的「行锁」,或一些锁定使用了过多的内存和系统资源时,SQL Server 为了有效地管理这些锁定,会尝试将锁定扩展为整个表的「表锁」,此时会很容易造成其他 process 在访问时的阻塞和等待。
-------------------------------------------------------------------------------------------
本帖尚未提到死锁和其他更进阶的议题,等下次有空再继续泡茶聊天。

