图解“管道过滤器模式”应用实例:SOD框架的命令执行管道
管道和过滤器
管道和过滤器是八种体系结构模式之一,这八种体系结构模式是:层、管道和过滤器、黑板、代理者、模型-视图-控制器(MVC) 表示-抽象-控制(PAC)、微核、映像。
管道和过滤器适用于需要渐增式处理数据流的领域,而常见的“层”模式它 能够被分解成子任务组,其中每个子任务组处于一个特定的抽象层次上。
按照《POSA(面向模式的软件架构)》里的说法,管道过滤器(Pipe-And-Filter)应该属于架构模式,因为它通常决定了一个系统的基本架构。管道过滤器和生产流水线类似,在生产流水线上,原材料在流水线上经一道一道的工序,最后形成某种有用的产品。在管道过滤器中,数据经过一个一个的过滤器,最后得到需要的数据。

管道&过滤器模型的基本部件都有一套输入输出接口。每个部件从输入接口中读取数据,经过处理,将结果数据置于输出接口中,这样的部件称为“过滤器”。这种模型的连接者将一个过滤器的输出传送到另一个过滤器的输入,
我们把这种连接者称为“管道”。在这种模型中,过滤器必须是独立的实体,每一个过滤器的状态不受其它过滤器的影响,并且,虽然人们对过滤器的输入输出有一定的规定,但过滤器并不需要知道向它提供数据流的过滤器和
它要提供数据流的过滤器的内部细节。任何两个过滤器,只要它们之间传送的数据遵守共同的规约就可以相连接。
每个过滤器都有自己独立的输入输出接口,如果过滤器间传输的数据遵守其规约,只要用管道将它们连接就可以正常工作。
查询的关注点
基于以上管道和过滤器特点,它为处理数据流的系统提供了一种良好的结构,每一个处理步骤封装在一个过滤器组件中,数据通过相邻的过滤器之间的管道传输。在程序处理中,也有类似的这种数据流,最常见的就是命令处理的数据流,它从最开始的查询命令,到最后的结果输出,会经过多个步骤,以ADO.NET来说,执行一个查询会经过以下过程:
查询命令:
- 获取数据集:
- 打开数据库连接 IDbConnection
- 创建命令对象 IDbCommand
- 创建数据适配器 IDataAdapter
- 填充数据集 IDataAdapter.Fill(DataSet)
- 关闭数据库连接
- 返回数据集 DataSet
- 获取数据阅读器
- 打开数据库连接 IDbConnection
- 创建命令对象 IDbCommand
- 执行数据阅读器查询 IDbCommand.ExecuteReader
- 返回数据阅读器 IDataReader
- 关闭数据库连接
非查询命令:
- 打开数据库连接 IDbConnection
- 创建命令对象 IDbCommand
- 执行查询 IDbCommand.ExecuteNonQuery()
- 关闭数据库连接
- 查询前
- 查询中
- 查询后
- 查询异常
SOD框架的命令处理管道
命令处理接口
/// <summary> /// 查询命令处理器接口 /// </summary> public interface ICommandHandle { /// <summary> /// 获取当前适用的数据库类型,如果通用,请设置为 UNKNOWN /// </summary> DBMSType ApplayDBMSType { get; } /// <summary> /// 执行前处理,比如预处理SQL,补充设定参数类型,返回是否继续进行查询执行 /// </summary> /// <param name="db">数据库访问对象</param> /// <param name="SQL"></param> /// <param name="commandType"></param> /// <param name="parameters"></param> /// <returns>返回真,以便最终执行查询,否则将终止查询</returns> bool OnExecuting(CommonDB db, ref string SQL, CommandType commandType, IDataParameter[] parameters); /// <summary> /// 执行过程中出错情况处理 /// </summary> /// <param name="cmd"></param> /// <param name="errorMessage"></param> void OnExecuteError(IDbCommand cmd, string errorMessage); /// <summary> /// 查询执行完成后的处理,不管是否执行出错都会进行的处理 /// </summary> /// <param name="cmd"></param> /// <param name="recordAffected">命令执行的受影响记录行数</param> long OnExecuted(IDbCommand cmd, int recordAffected); }
一图胜千言,先看下面的“SOD框架命令处理管道”图:
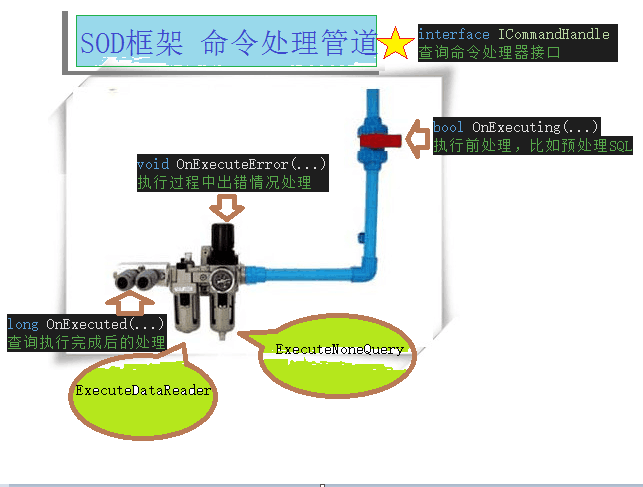
由前面接口的定义并结合这个图,可以看到查询命令在“数据访问”这个管道里面流动过程:
- 首先,它在 OnExecuting 这个过滤插口位置改变命令的行为特征,比如SQL预处理,终止查询等,发起异步操作等;
- 接着,查询命令由Ado.Net进行处理,而此时是很有可能发生查询错误的情况的,那么提供一个OnExecuteError 过滤插口,让错误信息可以被一些过滤器使用,比如查询操作日志组件;
- 最后,不论前面命令执行是否成功,命令执行完了还需要进行一些其它的处理,那么提供一个OnExecuteError 过滤插口,比如观察命令执行的结果行/影响行,命令的执行时间,返回异步通知等。
根据这里定义的命令执行管道接口,最典型的实现就是可以用来记录查询日志,比如下面的 CommandExecuteLogHandle 类:
/// <summary> /// 命令执行日志处理器,可以记录SQL和参数,执行时间等信息 /// </summary> public class CommandExecuteLogHandle :ICommandHandle { /// <summary> /// 初始化一个命令执行日志处理器 /// </summary> public CommandExecuteLogHandle() { this.CurrCommandLog = new CommandLog(true); //这里需要进行一些初始化检查,设置日志路径等 if (CommandLog.DataLogFile == null) CommandLog.DataLogFile = "~/sql.log"; CommandLog.SaveCommandLog = true; } public CommandLog CurrCommandLog { get; private set; } public bool OnExecuting(CommonDB db, ref string SQL, CommandType commandType, IDataParameter[] parameters) { this.CurrCommandLog.ReSet(); return true; } public void OnExecuteError(IDbCommand cmd, string errorMessage) { CurrCommandLog.WriteErrLog(cmd, "AdoHelper:" + errorMessage); } public long OnExecuted(IDbCommand cmd, int recordAffected) { long elapsedMilliseconds; CurrCommandLog.WriteLog(cmd, "AdoHelper", out elapsedMilliseconds); CurrCommandLog.WriteLog("RecordAffected:"+recordAffected , "AdoHelper"); return elapsedMilliseconds; } public DBMSType ApplayDBMSType { get { return DBMSType.UNKNOWN; }
} }
注意,这里 ApplayDBMSType 返回 UNKNOW,表示当前接口实现类性适合于任意数据库查询的情况。
另外,日志过滤器内部使用了框架内置的 CommandLog 类,它可以异步的记录SQL执行情况,并能记录查询时间大于某个值的查询,详细请看《PDF.NET的SQL日志》。
再看下面,我们实现一个用于处理Oracle查询的“过滤器”组件,它会在查询开始前,对SQL进行一些预处理,比如将本来使用于SQLSERVER的SQL语句格式,处理成Oracle特有的格式:
/// <summary> /// 自定义的Oracle命令处理器,用于处理特殊的字段名大写问题 /// </summary> public class OracleCommandHandle : ICommandHandle { public bool OnExecuting(CommonDB db, ref string sql, System.Data.CommandType commandType, System.Data.IDataParameter[] parameters) { sql= sql.Replace("[", "").Replace("]", "").Replace("@", ":").ToUpper(); //设置SQLSERVER兼容性为假,避免命令对象真正执行的时候再进行Oracle的查询语句的预处理。 db.SqlServerCompatible = false; //返回真,以便最终执行查询,否则将终止查询 return true; } public void OnExecuteError(System.Data.IDbCommand cmd, string errorMessage) { } public long OnExecuted(System.Data.IDbCommand cmd, int recordAffected) { return 1; } public PWMIS.Common.DBMSType ApplayDBMSType { get { return PWMIS.Common.DBMSType.Oracle; } } }
注意:上面这个实现类,指明了当前命令执行过滤器组件,仅使用于Oracle数据库,当前如果是其它数据库类型,会忽略该过滤器组件。
除此之外,是不是还可以写一个过滤器组件,监视下当前查询是否执行成功,如果成功,将查询的SQL和参数发送到消息队列,进行异步更新其它数据库?
开闭原则
所以,SOD框架的“命令执行管道”给予了最终用户在不改变原有数据访问组件的内部实现的情况下,一个监视和处理命令执行过程的“窗口”,一个或者多个对查询命令的“过滤器”组件,这正是面向对象原则之一的开闭原则。
我们来看下百度百科对开闭原则的解释:
开闭原则(OCP)是面向对象设计中“可复用设计”的基石,是面向对象设计中最重要的原则之一,其它很多的设计原则都是实现开闭原则的一种手段。 遵循开闭原则设计出的模块具有两个主要特征: (1)对于扩展是开放的(Open for extension)。这意味着模块的行为是可以扩展的。当应用的需求改变时,我们可以对模块进行扩展,使其具有满足那些改变的新行为。也就是说,我们可以改变模块的功能。 (2)对于修改是关闭的(Closed for modification)。对模块行为进行扩展时,不必改动模块的源代码或者二进制代码。模块的二进制可执行版本,无论是可链接的库、DLL或者.EXE文件,都无需改动。
既然命令执行管道如此有用,我们该如何使用呢?还是直接看示例代码比较简单:
/// <summary> /// 用来测试的本地 数据库上下文类 /// </summary> public class MyOracleDbContext : DbContext { public MyOracleDbContext() : base("local") { //local 是连接字符串名字 //注册日志处理器和Oracle命令处理器 base.CurrentDataBase.RegisterCommandHandle(new CommandExecuteLogHandle()); base.CurrentDataBase.RegisterCommandHandle(new OracleCommandHandle()); } #region 父类抽象方法的实现 protected override bool CheckAllTableExists() { //创建用户表 CheckTableExists<User>(); return true; } #endregion }
在这个 MyOracleDbContext 类中,我们注册了2个过滤器组件:日志过滤器和Oracle命令过滤器。
如果当前连接配置名 local 对应的数据库访问提供程序不是Oracle了怎么办?
不用担心,前面说过, Oracle命令过滤器仅对Oracle数据访问有效,其它数据库访问会忽略,而日志过滤器组件它是适用于任何数据库访问的。
上面的示例代码中,CurrentDataBase 对象其实就是 SOD框架的 AdoHelper对象,所以,只要你使用SOD框架,那么不管你使用的是框架的ORM,SQL-MAP,Data Controls功能,甚至是最简单的“SqlHelper”类应用,你都可以享受到SOD框架的“命令执行管道”带给你d便利!
与“观察者模式”的区别

.NET框架中,对观察者模式最常见的实现就是“事件”,事件可以实现监视某个对象的改变情况然后发起事件通知,最后由事件处理程序完成处理。在本文描述的查询处理场景中,也可以在查询处理前,处理后,发生异常这3个“观察点”发起事件,并且,事件也可以实现“多播”,一个事件可以由多个事件处理程序来处理。所以,从这个意义上来说,“管道-过滤器”模式跟“观察者”模式功能上很相似的,但为何SOD框架不选择后者来实现呢?
我认为,主要区别有以下几个方面:
在架构层面上,
“管道-过滤器”模式通常用于架构设计层面,是一种“架构模式”,比如分层架构;而观察者模式一种面向对象编程的模式,运用的领域不一样。
“管道-过滤器”模式让架构实现松耦合;而观察者模式的观察者和被观察者之间,往往是紧密耦合的关系。
在具体使用形式上,
“架构模式”可以通过配置文件来提供附件的一种功能实现,比如ASP.NET的HttpHandle,ASP.NET MVC的Controller上的Filter等,所以它的实现是松耦合的;
而观察者模式往往体现在编写的代码中,用事件来处理代码来实现,所以它往往是紧耦合的。
在业务语义上,
“管道-过滤器”是用于处理流动的载体的,比如数据,信息或其它具有流动特性的物体,方便进行多环节,多层次的拦截或者加工处理,并且每个处理环节都有序的,流动和有序,这是这类业务最重要的特征;
“事件”处理的客体范围更广,事件的客体没有固定的形态,事件的发生和处理可能都是无序的。
其它方面的考虑,事件使用前总是需要声明事件挂钩,会多增加一些代码量,并且使用完成之后,往往还需要解除挂钩,否则可能发生内存泄漏,请参见 我另外一篇文章《Release编译模式下,事件是否会引起内存泄漏问题初步研究》。
总结
所以,在当前这个数据查询的场景中,对于查询命令的处理,采用“管道-过滤器”模式来实现一个命令执行管道,是最合适的,它让人在业务语义上更加明确,并且使用上更加灵活,代码实现量也最小,而且不需要修改原有的代码实现,符合开闭原则。
到目前为止,我还没有看到其它 数据处理框架/ORM框架 比较明确的提供了关注和干预组件内部查询执行过程的功能,都只能进行外部的拦截,如果你有这样的需求,来试试SOD框架带给你的灵活和自由吧!
附注:
SOD不仅仅是一个ORM,它还有SQL-MAP和DataControl,具体可以看框架官网 http://www.pwmis.com/sqlmap ,9年历史铸就的成果,坚固可靠。
非常感谢你看到这里,相信你初步了解了SOD框架的基本功能,如果您还有其它问题,欢迎你在项目的开源网站 http://pwmis.codeplex.com的讨论区发帖,或者去官方博客相关文章回帖也可。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号