基本结构
Server > Database> Table> Row >Colum
数据库服务器 数据库 数据表 行 列
使用客户端服务器:
mysql.exe -hIP地址/localhost -P端口 -uroot -p -h host 域名/IP地址 127.0.1.1/localhost -P(大写P) port 端口 -u user 用户名 root 管理员 -p(小写p) password 密码 xampp下root的密码为空 直接回车 (结束时不加分号)
可简写: mysql -uroot
常见管理命令:
1 exit;/quit; //退出服务器的连接 2 show databases; //显示数据库服务器下所有的数据库 3 use 数据库名称; //进入指定的数据库 4 show tables; //显示当前数据库下所有的数据表 5 desc 数据表名称; //描述数据表中都有哪些列(查看表头) 6 (以英文分号结束)
SQL命令:
结构化查询语言:用于操作关系型数据库服务器,主要是对数据进行增删改查
执行方式:
交互模式:哭护短输入一行,点击回车,服务器就会执行一行,适用于临时性的查看数据。
脚本模式:客户端把所有要执行的命令写在一个脚本文件中,一次性提交给服务器执行,适用于批量的操作数据。
注意:不能提前连接
执行文件的命令: mysql -uroot<(拖拽脚本文件进入窗口)
单行注释 # ; 多行注释 /* */
语法规范:
1.一条SQL命令可以跨越多行,以英文分号作为结束;
2.假设某一条SQL命令出现语法错误,则此条命令后所有的代码不被服务器执行;
3.SQL命令不区分大小写,习惯上关键字大写,非关键字小写;
4.分为单行注释(#...)和多行注释(/* */),注释的代码不被服务器执行。
常用的SQL命令
1.删除数据库(如果存在jd数据库的话): drop database if exists id; 2.创建新的数据库: creat database jd; 3.进入创建的数据库: use jd; 4.创建数据库的表(student): creat table student( 列名称 类型 ); 5.插入数据: insert into student(表名称) value('值1','值2',..); //单引号、双引号都可 6.查询数据: select * from student; 7.修改数据: (1)update 表名称 set 列='名称',列='名称' ...where 条件; (2)delete from 表名称 where 条件; //常用这个
标准的SQL命令
定义数据(DDL):create(创建)/drop(删除)/alter(修改)
操作数据(DML):insert(插入)/delete(删除)/update(修改)
查询数据(DQL):select(查询)
控制用户权限(DCL):grant(授权)revoke(收权)
计算机如何存储字符
(1)如何存储英文字符
ASCII:总共有128个,对英文字符进行了编码
Latin-1:总共有256个,对欧洲字符进行了编码,兼容ASCII,MySQL默认这个编码
(2)如何存储中文
GB2312:对常用的6千多汉字进行了编码,兼容ASCII
GBK:对2万多汉字进行编码,兼容GB2312
BIG5:台湾繁体字编码
Unicode:对世界上主流国家常用的语言进行了编码,具体使用分为三中存储方案utf-8,utf-16,utf-32
(3)MySQL中文乱码产生的原因
默认使用Latin-1
(4)解决方法(一起使用)
脚本文件另存为的编码为utf-8(代码里写utf8)
客户端连接服务器端的编码为utf-8(在第一行写 :set names utf8;)
客户端创建数据库,存储字符使用的编码为utf-8(在创建数据库的时候使用 charset=utf8

常用的列类型
列类型:指定的列所要存储的数据类型
create table news(
nid 列类型
);
数值型
tinyint 微整型,占一个字节,范围:-128~127
Smallint 小整型,占2个字节,范围:-32768~32767
int 整型,占4个字节,范围:-2147483648~2147483647
bigint 大整型,占8个字节,范围很大
浮点型
float 单精度浮点型,占4个字节
double 双精度浮点型,占8个字节
float和double存储的值比int和bigint大的多,以牺牲小数点后的值为代价,数字越大,精度越低
decimal(M,D) 定点小数,小数点不会发生变化
M 代表小数点前后总的有效位数
D 代表小数点的位数
boolean 布尔型
只有两个值true和false,代表真和假,用于存储只有两个值的数据
true和false是关键字,使用的时候不能加引号
日期时间型
date 日期 “2021-10-20”
time 时间型 “16:53:20”
datetime 日期时间型 “2021-10-20 16:53:20”
字符串型
varchar(M) 变长字符串 (几乎不会产生空间浪费,错做速度相对慢,最大值是65535,常用于存储变化长度的数据,例如:文章的标题,详情...)
char(M) 定长字符串 (使用效率较快,可能产生空间浪费,最大值是255,常用于存储固定长度的数据,例如:手机号码,身份证号码)
text(M) 大型边长字符串,M最大值为2G
引号的使用:
数值型的引号可以省略
字符串和日期时间必须加引号
列约束
MySQL可以对要插入的值进行验证,只有符合条件才允许插入,例如:编号不允许重复,性别只能男女....
(1)主键约束 -----primary key
声明了主键约束的列上不允许插入重复的值;一个表中只能有一个主键约束,通常是加在编号列上,会加快数据的查询速度
null : 空;表示一个暂时无法确定的值,例如:暂时无法确定商品的上架时间、价格。。。
null 是关键字,不能加引号
主键约束的列上不允许插入null
(2)非空约束 ---- not null
声明了非空约束的列上不允许插入null
(3)唯一约束 ---- unique
声明了唯一约束的列上不允许出现重复的值,允许插入多个null
(4)默认值约束 ---- default 默认值(若没有设置默认值,就默认null)
可以使用default关键字给列设置默认值,具体应用默认值有两种方式:
insert into 表名称 values(1,default...); #会自动调用列的默认值
insert into 表名称(列1,列2....)values(值1,值2...); #给指定的列提供值,没有出现的列自动应用默认值
(5)检查约束 check(条件)
也称为自定义约束,可以自己指定约束条件
```javascript
create table 表名称(
score tinyint check(score>=0 and score<=100); //挑选0~100之间的分数
)
```
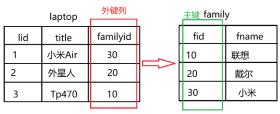
(6)外键约束 foreign key(外键列) reference 另一个表名称(主键列)
声明了外键约束的列,要插入的值必须在另一个表的主键中出现过,目的是为了建立两个表之间的关联关系
外键列的列类型要和另一个主键列的列类型要保持一致
自增列
Auto_increment:自动增长,如果设置了自增列,在插入数据的时候,只需要赋值为null,就会获取最大值,然后加1插入
注:自增列必须添加整数形式的主键列上,也就是只有一个
自增列允许手动赋值
源代码:
#设置客户端连接服务器的编码 set names utf8; #丢弃数据库,如果存在 drop database if exists tedu; #创建新的数据库,设置编码utf8 create database tedu charset=utf8; #进入数据库 use tedu; #创建部门表dept create table dept( did int primary key auto_increment, dname varchar(8) unique ); #插入部门数据 insert into dept values(10,'研发部'); insert into dept values(20,'运营部'); insert into dept values(30,'市场部'); insert into dept values(40,'测试部'); #创建员工表emp create table emp( eid int primary key auto_increment, ename varchar(5) not null, sex boolean default 0, #1-男 ,0-女 brithday date, salary decimal(7,2), #99999.99 detpId int, foreign key(detpId) references dept(did) ); #插入数据 insert into emp values(null,'tao',default,'2021-10-05',555.55,40); insert into emp values(null,'tao',default,'1973-7-15',50000,20); INSERT INTO emp VALUES(NULL,'Tom',1,'1990-5-5',6000,20); INSERT INTO emp VALUES(NULL,'Jerry',0,'1991-8-20',7000,10); INSERT INTO emp VALUES(NULL,'David',1,'1995-10-20',3000,30); INSERT INTO emp VALUES(NULL,'Maria',0,'1992-3-20',5000,10); INSERT INTO emp VALUES(NULL,'Leo',1,'1993-12-3',8000,20); INSERT INTO emp VALUES(NULL,'Black',1,'1991-1-3',4000,10); INSERT INTO emp VALUES(NULL,'Peter',1,'1990-12-3',10000,10); INSERT INTO emp VALUES(NULL,'Franc',1,'1994-12-3',6000,30); INSERT INTO emp VALUES(NULL,'Tacy',1,'1991-12-3',9000,10); INSERT INTO emp VALUES(NULL,'Lucy',0,'1995-12-3',10000,20); INSERT INTO emp VALUES(NULL,'Jone',1,'1993-12-3',8000,30); INSERT INTO emp VALUES(NULL,'Lily',0,'1992-12-3',12000,10); INSERT INTO emp VALUES(NULL,'Lisa',0,'1989-12-3',8000,10); INSERT INTO emp VALUES(NULL,'King',1,'1988-12-3',10000,10); INSERT INTO emp VALUES(NULL,'Brown',1,'1993-12-3',22000,NULL);
简单查询
(1)查询特定的列
示例:查询所有员工的编号和姓名
select 列名,列名 from 表名称
(2)查询所有的列
方法一:select * from 表名称;
方法二:select 把所有列写出来 from 表名称
(3)给列起别名
示例:查询出所有员工的编号和姓名,使用一个字母作为别名
select eid as a,ename as b from emp;
简写:列名(空格/as)别名
(4)显示不同的记录
示例:查询出都有哪些性别的员工
seleect distinct sex from emp;
(5)查询时执行计算
示例:计算1+2+3+4*5
select 1+2+3+4**5;
(6)查询出所有的部门,结果按照编号升序排序
示例:查询出所有的部门,结果按照编号升序排列
select * from dept order by did asc;
#ascendant 升序的
示例:查询出所有的部门,结果按照编号降序排列
select * from dept order by did desc;
#desc 描述 describe
#desc 降序 descendant
若按照字符串排列,最终是按照首个字符的Unicode码排列
不加排序规则,默认是按照升序排列
示例:查询所有的员工,结果按照工资的降序排列,如果工资相同按照姓名排列
select * from emp order by salary desc,ename;
(7)条件查询
示例:查询编号为8号的员工
select * from emp where eid=8;
!= 不等于;
找null的数据
select * from emp where detpid is null;
找不是null的数据
select * from emp where detpid is not null;
如:查询工资8000以上的女员工有哪些
select * from emp where salary>8000 and sex=0;
and/&& 并且
or/|| 或者
如:查询部门在20或者30的员工
select * from emp where detpid in(20,30);
(8)模糊条件查询(搜索) like
% 匹配任意个字符 >=0
_ 匹配任意1个字符 =1
示例:查询出姓名含有字母e的员工有哪些
select * from emp where ename like "%e%";
(9)分页查询 limit
查询的结果中有大多的数据一次显示不完可以做成分页
需要有两个已知的条件:当前的页码是多少、页面的数据量
开始查询的值=(当前的页码-1)*每页的数据量
select * from emp limit 开始查询的值,每页的数据量;
limit 后的两个值(开始查询的值和每页的数据量)必须是数值型,不能加引号
复杂查询
(1)聚合查询/分组查询
聚合查询: count() 数量/sum() 总和/avg() 平均/max() 最大/min() 最小
示例:查询出所有员工的数量
select coutn(*) from emp; #推荐使用主键列
分组查询通常用于查询聚合函数和分组条件
分组:group by
示例:查询出男女员工的数量,工资总和,平均工资
select count(eid), sum(salary),avg(salary),sex from emp group by sex;
(2)子查询
子查询是多个SQL命令的组合,将一个SQL命令的结果作为另一个的条件使用
year() 获取日期中的年份
month() 获取日其中的月份
示例:查询出工资最高的员工
步骤一: select max(salary) from emp; 得出50000
步骤二: select * from emp where salary=50000;
综合写法:
select * from emp where salary=(select max(salary) from emp);
(3)多表查询
查询的列分布在多个表中,前提是多个表之间建立关联
示例:查询出所有的员工姓名及其部门名称
select ename,dname from emp,dept where detpid=did; select emp,ename,dept.dname from emp,dept where emp,detpid=dept.did;
语法新增
1. 内连接(结果和上面一致,语法新增)
inner join.... on
select ename,dname from emp inner join dept on detpid=did;
2.左外连接(新增语法,左边的表中所有的员工都查询出来,包括null,先写的是左)
left outer join (outer 可省略)
select ename,dname from emp(#这个就是左) left outer join dept on detpid=did;
3.右外连接(新增语法,将右侧表所有员工都查询出来,不管其有没有数据)
right outer join(outer 可省略)
select dname,ename from emp right outer join dept on detpid=did;
4.全连接
full join .. on
同时显示左侧和右侧所有的记录,MySQL不支持全连接
(虽然MySQL不支持,但总有牛人想出办法)
union 联合后,合并相同的记录
union all 联合后,不合并相同的记录
方法:将左外连接和右外连接联合,合并相同的记录
(select ename,dname from emp left join dept on detpid=did) union all(select ename,dname from emp right join dept on detpid=did);
```


 浙公网安备 33010602011771号
浙公网安备 33010602011771号