
SVM(一)-线性支持向量机详解(附代码)
线性支持向量机
SVM(Support Vector Machine)是数据挖掘中常用的分类算法。事实上,在2012年深度学*算法提出之前,SVM一直被认为是机器学*领域*几十年来最成功的算法。SVM的难度相较于其他分类算法要高一些儿,特别是涉及到的数学知识比较多,不过不要害怕,本文尽量把每个知识点讲清楚,力求更多的人能看懂SVM分类算法。现在,请深呼吸几次,给大脑充足的氧气,我们即将一起去探究SVM的点点滴滴。
我们根据数据集的分布情况,可将数据集分成两种:线性可分与线性不可分。所谓的线性可分,是指我们可以找到一个线性方程(2维情况下是一条直线,3维情况下是一个平面),将数据分隔开来。下图展示了2维数据集线性可分与线性不可分的情况。
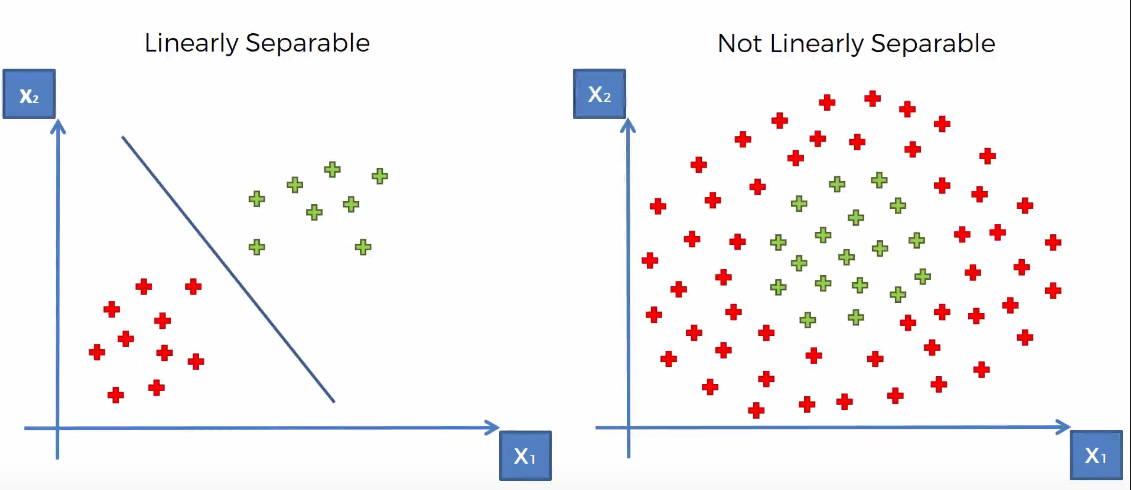 如图所示,在左图中可以找到一条直线,将两类数据分隔开,而右图则找不到这样一条直线,因此我们称其是线性不可分的。
如图所示,在左图中可以找到一条直线,将两类数据分隔开,而右图则找不到这样一条直线,因此我们称其是线性不可分的。
本文将着重讨论SVM在线性可分数据集上的应用,对于线性不可分的数据集,留待在后续的文章中详细讨论。
SVM的模型
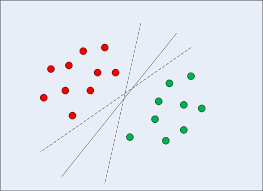
对于给定的训练数据集,我们可能有多条不同的线性方程可以将数据分隔开,如上图所示。SVM分类算法的目标,就是找到最优划分的那条线性方程。因此,线性方程的数学模型,即是SVM的分类模型,其可以表示为:
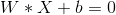
其中,X是数据集的特征向量,W是权重向量,b是偏置项。
我们说到,要寻找最优划分的线性方程,那么,该如何度量线性方程划分结果的优劣呢?这里我们引入一个概念:边缘(Margin)
有时候,我们也会称线性方程为超平面(hyperplane,因为3维空间里的线性方程就是指一个平面,而对于高维空间,则是超平面)。对于一个超平面,我们做一个这样的操作:将超平面向上平移,直到蓝色类的第一个点落在超平面上时停止(上方虚线);将超平面向下平移,直到红色类的第一个点落在超平面上时停止(下方虚线)。两条虚线间的距离即为该超平面的边缘。
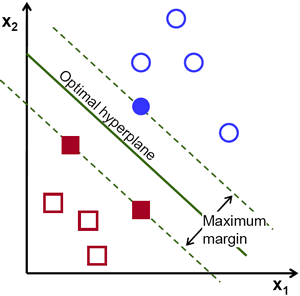
那么这个距离得怎么算呢?我们知道,将超平面平移时,权重向量W是不会改变的,仅仅是改变偏置项b。(平移时直线的斜率不会变),因此,两条虚线的方程可以这样表示:(我们把偏置项的变化量移到了方程右边)
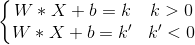
我们不妨用(X,y)表示一条数据记录,其中X是记录的特征向量,y是记录的类标号,我们把蓝色类的类标号记为1,把红色类的类标号记为-1,则有:
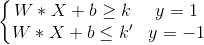
为了之后计算方便,我们可以调整W和b的取值,对方程做缩放变换,使得k=1,k'=-1,则上式可改写为:
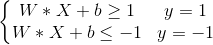
我们可以将上面两个不等式概括为更加简洁的形式:
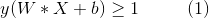
假设超平面 W * X + b = 0上有p1,p2两点,则有 W * Xp1 + bp1 = 0,W * Xp2 + bp2 = 0,两式相减有 W * ( Xp1 - Xp2 ) = 0。其中 Xp1 - Xp2 是该超平面上的向量,说明权重向量W和该超平面垂直。
假设上下虚线上分别有p3,p4两点,则对于p3点,有 W * Xp3 + bp3 = 1;对于p4点,有 W * Xp4 + bp4 = -1,两式相减有 W * ( Xp3 - Xp4 ) = 2。Xp3 - Xp4 是p3,p4两点间的向量,其在W方向上的投影长度即是两条虚线间的距离d,所以有:
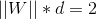
即:
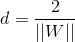
其中,||W||是向量W的模长。至此,我们已经知道了如何计算一个超平面边缘的大小,SVM的目标,就是找到边缘最大的那个超平面,我们称之为最大边缘超平面(Maximum Margin Hyperplane)。也就是说,我们要优化距离函数d,使得取得最大值,此时对应的W0,就是MMH的权重向量。
为什么要寻找边缘最大的超平面呢?因为具有较大边缘的超平面具有更小的泛化误差(也就是将应用在其它样本上的误差),边缘较小的超平面,对训练数据的过分拟合程度会更高,从而在未知样本上的泛化能力较差。
目标函数
通过上面的讨论,我们知道了需要最大化边缘,最大化边缘等价于最小化下面的函数:
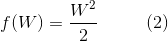
像 f(W) 这样我们要优化的目标,在机器学*领域,有一个专门的术语:目标函数
同时,不要忘了还有式1的不等式约束。总结来说,SVM的学*任务为以下被约束的优化问题:
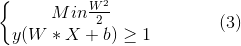
可以看到,目标函数 f(W) 是二次的,而不等式约束在参数W和b上面是线性的,这在数学上属于一个凸优化问题,对于凸优化问题,我们可以通过标准的拉格朗日乘子(Lagrange Multiplier)方法求解。下面简要介绍一下求解这个优化问题的主要思想。
首先,必须改写目标函数,将施加在解上的约束包括进来,新目标函数称为该优化问题的拉格朗日函数:
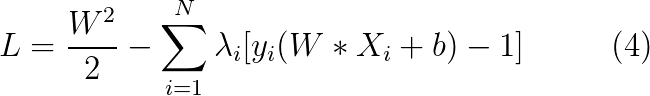
其中,N为训练数据集的大小,λi称为拉格朗日乘子。拉格朗日函数的第一项为原函数,第二项则捕获了不等式约束。为了理解改写原目标函数的必要性,考虑式2,容易证明当 W=0(零向量)时函数取得最小值,然而,这样的解违背了约束条件,因为b此时没有解。事实上,如果 W,b 的解违反了约束,即 yi ( W Xi + b ) - 1 < 0 ,假定λi≥ 0,则任何不可行的解仅仅是增加了拉格朗日函数的值,当我们求得函数的最小值时,即可保证此时的解W0,b0是满足约束条件的。
为了最小化拉格朗日函数,需要对L求关于W和b的偏导,并令它们等于0:
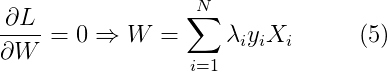
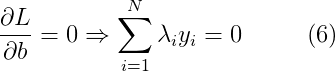
因为拉格朗日乘子λi是未知的,所以现在我们仍然求解不了W和b的值。
如果我们能将式1中的不等式约束转换为等式约束,则我们可以从该等式约束得到的N的方程,加上式5,6(共N+2个方程),从而求得W,b,λi(共N+2个参数)的可行解。幸运的是,这种转换在数学上是可行的,称为Karuch-Kuhn-Tucher(KKT)转换。式1的不等式约束等价于以下的等式约束:
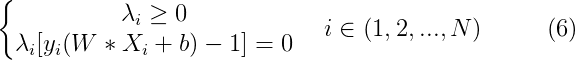
乍一看,拉格朗日乘子的数量好像和训练数据集的规模一样大。不过我们冷静想一下,绝大部分的点,满足 y ( W * X + b ) - 1 > 0,因为它们都在虚线的一侧,并没有落在虚线上,因此,为了满足式6的等式约束,这些点对应的拉格朗日乘子必须等于0,我们所需要求的,只是那些落在虚线上的点对应的λ。这些点被称为支持向量,因为式5中W的取值只受那些λ≠0的点的影响,这也是这个算法被称为支持向量机的原因。
现在,我们已经过滤掉了大量为0的参数,但是对于式4的优化问题求解仍然是一项十分棘手的任务,因为方程中同时涉及了W,b,λ三类参数。我们可以将拉格朗日函数转化成对应的对偶函数(duel function)来进一步简化该问题。在对偶函数中,参数只有拉格朗日乘子λ。
对偶定理陈述如下:
如果原问题有最优解,则其对偶问题也有最优解,并且相应的最优解是相同的。
我们可以将式5,6代入到式4中求得原拉格朗日函数的对偶拉格朗日函数。
首先,将式4展开:
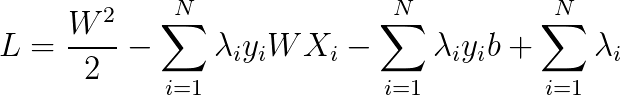
代入式5,6:
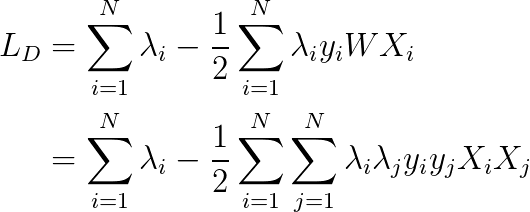
因为,λi=0时,对结果没有影响,所以我们可以把数据的范围从整个训练数据集缩小到支持向量的集合,用S表示支持向量的集合。
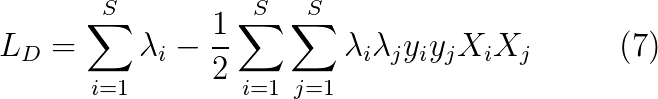
此时有约束条件如下:
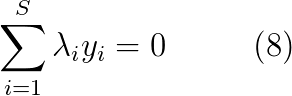
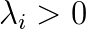
至此,通过层层的转化,我们已经找到了最终的目标函数:对偶拉格朗日函数LD。可以看到,LD仅涉及到拉格朗日乘子和支持向量,而原拉格朗日函数L除了拉格朗日乘子外还涉及超平面的参数W,b。奇妙的是,这两个优化问题的解是等价的。同时,需要注意的是,LD中的二次项前面的符号是负的,这说明原来涉及L的最小化问题已经变成了涉及LD的最大化问题。
SMO算法
首次,对坚持到这里的同学们点个赞,经过各种数学公式的层层洗礼之后还未放弃实属不易。告诉大家一个好消息,SMO算法是求解SVM分类器的最后一步了,现在,大家可以站起来活动活动筋骨,再次深吸几口气,让大脑休息一会儿再一鼓作气攻克最后一步吧!
那么,如何求解式7呢?这在数学上属于二次规划问题,可以使用通用的二次规划算法来求解,然而,该问题的复杂程度正比于训练数据集的规模,这会在实际的任务中造成很大的开销,为了避开这个障碍,人们通过利用问题本身的特性,提出了很多高效的算法,SMO(Sequential Minimal Optimization)就是其中一个著名的代表。
SMO的基本思想是选取一对变量λi,λj,并固定其他参数,由于存在式8的约束,所以λi可以用λj和其他固定的拉格朗日乘子导出。这样LD就变成了一个只关于单变量λi的二次规划问题,仅有的约束是λi > 0。我们可以将参数全都初始化为0,然后不断执行如下步骤直至收敛。
1.选取一对需要更新的变量λi,λj
2.固定除λi,λj外的参数,通过式7更新λi,λj
我们假定更新前的λ记为λold,更新后的λ记为λnew 。则式8的约束可以改写为:(因为得保证式8一直成立)
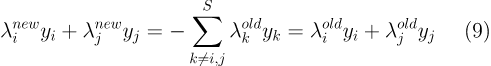
为了求式7的导数时容易理解,我们让 i=1,j=2,则有:(其中Constant是和λ1,λ2无关的常数项,并不影响后面导数的计算)
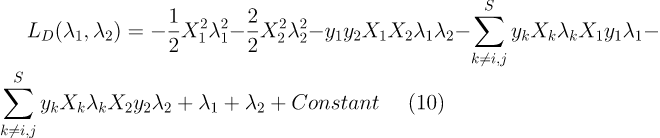
将式9代入式10并令其关于λ1的导数为0可以得到未截断(unclipped)的最优解:(其中E是误差项,E = W * X + b - y)
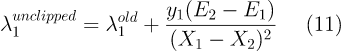
对于未截断的最优解λ1unclipped,通过二次规划的约束λ1≥0,λ2≥0便可截断λ1unclipped,得到λ1new的值。然后通过式9计算出λ2new,至此,我们便完成了一组拉格朗日乘子的更新。重复以上计算过程,直到各拉格朗日乘子不再变化。
当计算出支持向量对应的拉格朗日乘子后,我们就可以通过式5计算出权重向量W的值了。
说了这么多,一直在说W如何计算,那么偏置项b呢?我们可以通过两条虚线的方程:W*X+b=±1 来计算b的值,可以知道,两条虚线的偏置项b计算出来的结果是不一样的,我们不妨记为b1,b2。常用的做法是,取它们的平均值作为b的最终取值,也即是:b=(b1+b2)/2。
到这里,线性SVM算是基本讲完了,只剩下一个小问题:模型训练误差为0,也即是说模型对训练数据是完全拟合的。但有时候,可能有一定训练误差的模型效果要更好一些。在接下来的文章中,我们将一起讨论如何训练允许一定训练误差的SVM。好了,今天就先到这吧,快去让大脑放松一下。
代码(Python3.7):
线性SVM的实现类代码:
1 import numpy as np 2 3 4 class LinearSVM(object): 5 """ 6 线性SVM的实现类 7 """ 8 def __init__(self, dataset_size, vector_size): 9 """ 10 初始化函数 11 :param dataset_size:数据集规模,用于初始化 ‘拉格朗日乘子’ 的数量 12 :param vector_size:特征向量的维度,用于初始化 ‘权重向量’ 的维度 13 """ 14 self.__multipliers = np.zeros(dataset_size, np.float_) 15 self.weight_vec = np.zeros(vector_size, np.float_) 16 self.bias = 0 17 18 def train(self, dataset, iteration_num): 19 """ 20 训练函数 21 :param dataset:数据集,每条数据的形式为(X,y),其中X是特征向量,y是类标号 22 :param iteration_num: 23 """ 24 dataset = np.array(dataset) 25 for k in range(iteration_num): 26 self.__update(dataset, k) 27 28 def __update(self, dataset, k): 29 """ 30 更新函数 31 :param dataset: 32 :param k: 33 """ 34 for i in range(dataset.__len__() // 2): 35 j = (dataset.__len__() // 2 + i + k) % dataset.__len__() 36 record_i = dataset[i] 37 record_j = dataset[j] 38 self.__sequential_minimal_optimization(dataset, record_i, record_j, i, j) 39 self.__update_weight_vec(dataset) 40 self.__update_bias(dataset) 41 42 def __sequential_minimal_optimization(self, dataset, record_i, record_j, i, j): 43 """ 44 SMO函数,每次选取两条记录,更新对应的‘拉格朗日乘子’ 45 :param dataset: 46 :param record_i:记录i 47 :param record_j:记录j 48 :param i: 49 :param j: 50 """ 51 label_i = record_i[-1] 52 vector_i = np.array(record_i[0]) 53 label_j = record_j[-1] 54 vector_j = np.array(record_j[0]) 55 56 # 计算出截断前的记录i的‘拉格朗日乘子’unclipped_i 57 error_i = np.dot(self.weight_vec, vector_i) + self.bias - label_i 58 error_j = np.dot(self.weight_vec, vector_j) + self.bias - label_j 59 eta = np.dot(vector_i - vector_j, vector_i - vector_j) 60 unclipped_i = self.__multipliers[i] + label_i * (error_j - error_i) / eta 61 62 # 截断记录i的`拉格朗日乘子`并计算记录j的`拉格朗日乘子` 63 constant = -self.__calculate_constant(dataset, i, j) 64 multiplier = self.__quadratic_programming(unclipped_i, label_i, label_j, i, j) 65 if multiplier >= 0: 66 self.__multipliers[i] = multiplier 67 self.__multipliers[j] = (constant - multiplier * label_i) * label_j 68 69 def __update_bias(self, dataset): 70 """ 71 计算偏置项bias,使用平均值作为最终结果 72 :param dataset: 73 """ 74 sum_bias = 0 75 count = 0 76 for k in range(self.__multipliers.__len__()): 77 if self.__multipliers[k] != 0: 78 label = dataset[k][-1] 79 vector = np.array(dataset[k][0]) 80 sum_bias += 1 / label - np.dot(self.weight_vec, vector) 81 count += 1 82 if count == 0: 83 self.bias = 0 84 else: 85 self.bias = sum_bias / count 86 87 def __update_weight_vec(self, dataset): 88 """ 89 计算权重向量 90 :param dataset: 91 """ 92 weight_vector = np.zeros(dataset[0][0].__len__()) 93 for k in range(dataset.__len__()): 94 label = dataset[k][-1] 95 vector = np.array(dataset[k][0]) 96 weight_vector += self.__multipliers[k] * label * vector 97 self.weight_vec = weight_vector 98 99 def __calculate_constant(self, dataset, i, j): 100 label_i = dataset[i][-1] 101 label_j = dataset[j][-1] 102 dataset[i][-1] = 0 103 dataset[j][-1] = 0 104 sum_constant = 0 105 for k in range(dataset.__len__()): 106 label = dataset[k][-1] 107 sum_constant += self.__multipliers[k] * label 108 dataset[i][-1] = label_i 109 dataset[j][-1] = label_j 110 return sum_constant 111 112 def __quadratic_programming(self, unclipped_i, label_i, label_j, i, j): 113 """ 114 二次规划,截断`拉格朗日乘子` 115 :param unclipped_i: 116 :param label_i: 117 :param label_j: 118 :return: 119 """ 120 multiplier = -1 121 if label_i * label_j == 1: 122 boundary = self.__multipliers[i] + self.__multipliers[j] 123 if boundary >= 0: 124 if unclipped_i <= 0: 125 multiplier = 0 126 elif unclipped_i < boundary: 127 multiplier = unclipped_i 128 else: 129 multiplier = boundary 130 else: 131 boundary = max(0, self.__multipliers[i] - self.__multipliers[j]) 132 if unclipped_i <= boundary: 133 multiplier = boundary 134 else: 135 multiplier = unclipped_i 136 return multiplier 137 138 def predict(self, vector): 139 result = np.dot(self.weight_vec, np.array(vector)) + self.bias 140 if result >= 0: 141 return 1 142 else: 143 return -1 144 145 def __str__(self): 146 return "multipliers:" + self.__multipliers.__str__() + '\n' + \ 147 "weight_vector:" + self.weight_vec.__str__() + '\n' + \ 148 "bias:" + self.bias.__str__()
数据集和测试代码:
1 from SVM import LinearSVM 2 import numpy as np 3 from matplotlib import pyplot as plt 4 5 dataset = [ 6 [[0.3858, 0.4687], 1], 7 [[0.4871, 0.611], -1], 8 [[0.9218, 0.4103], -1], 9 [[0.7382, 0.8936], -1], 10 [[0.1763, 0.0579], 1], 11 [[0.4057, 0.3529], 1], 12 [[0.9355, 0.8132], -1], 13 [[0.2146, 0.0099], 1] 14 ] 15 16 linearSVM = LinearSVM.LinearSVM(dataset.__len__(), dataset[0][0].__len__()) 17 linearSVM.train(dataset, 100) 18 print(linearSVM) 19 20 for record in dataset: 21 vector = record[0] 22 label = record[-1] 23 if label == 1: 24 plt.plot(vector[0], vector[1], 'r-o') 25 else: 26 plt.plot(vector[0], vector[1], 'g-o') 27 28 predict = linearSVM.predict(vector) 29 print(record.__str__() + predict.__str__() + '\n') 30 31 x1 = np.linspace(0, 1, 50) 32 x2 = (-linearSVM.bias - linearSVM.weight_vec[0] * x1) / linearSVM.weight_vec[1] 33 plt.plot(x1, x2) 34 plt.show()

