【机器学习】莫烦
机器学习方法
1.1 机器学习(Machine Learning)
- 监督学习(supervised learning)
- 有标签的数据
- 非监督学习(unsupervised learning)
- 无标签的数据
- 半监督学习(semi-supersived learning)
- 少量有标签的样本
- 大量无标签的样本
- 强化学习(reinforcement learning)
- 只给机器人篮球和篮筐,让机器人自己尝试各种方法,投篮命中则进行奖励(Alpha Go)
- 遗传算法(genetic algorithm)
- 淘汰弱者,在强者的基础上再次进行学习(马里奥通关)
神经网络
2.1 人工神经网络 vs 生物神经网络
生物神经网络
- 人有900亿个神经元
- 通过刺激,产生新的联结,让信号能够通过新的联结传递而形成反馈
人工神经网络
- 通过正向和反向传播来更新神经元
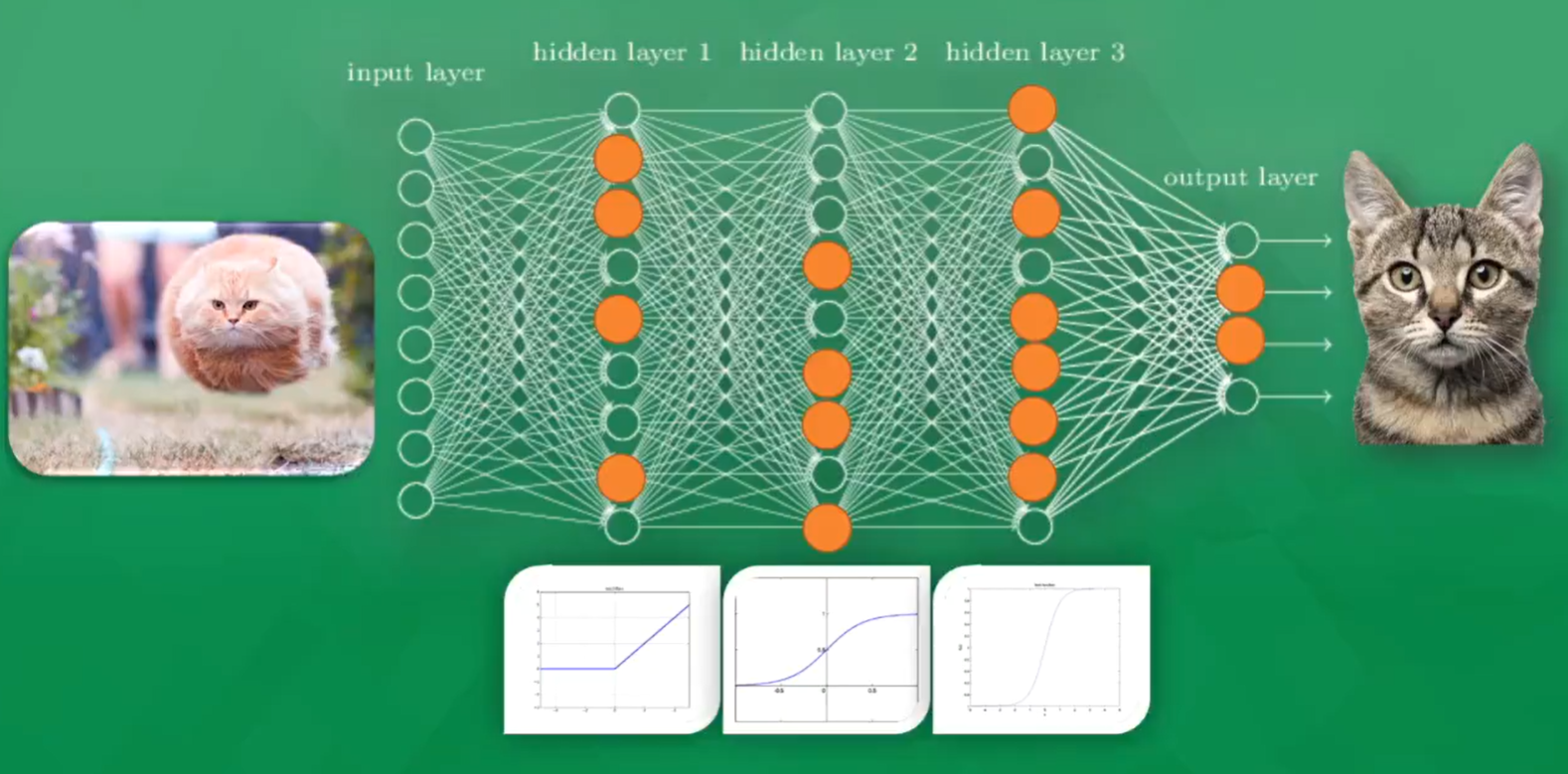
2.2 神经网络(Neural Network)
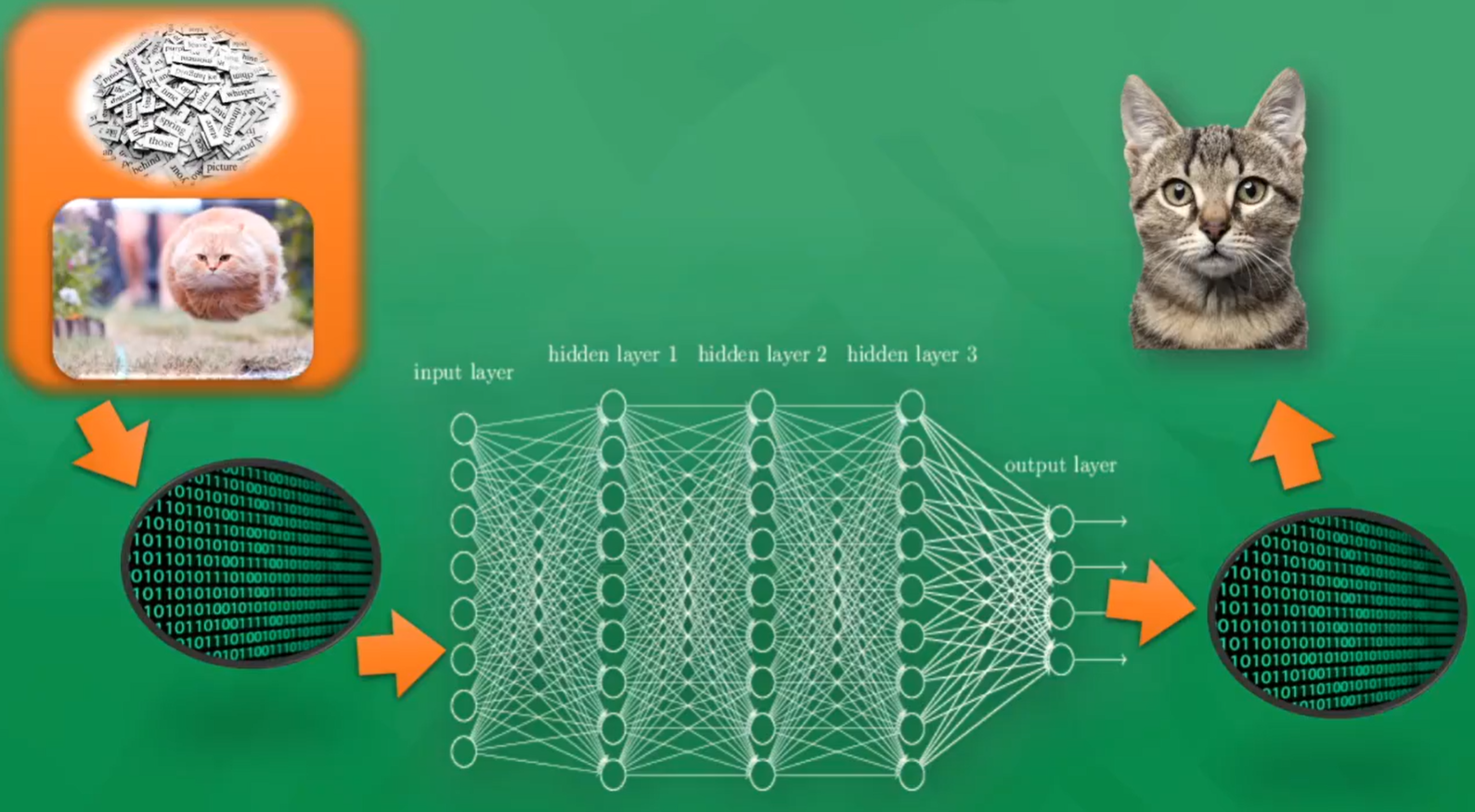
- 输入层
- 隐藏层(1~N层)
- 输出层
激活函数
TLDR(or the take-away)
- 优先使用 ReLU,但要注意初始化和Learning Rate的设置
- 遇到多个Dead ReLU,可以考虑使用Leaky ReLU(P-ReLU,R-ReLU),ELU或者Maxout
- 不建议使用tanh,尤其是sigmoid
- sigmoid
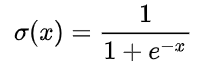
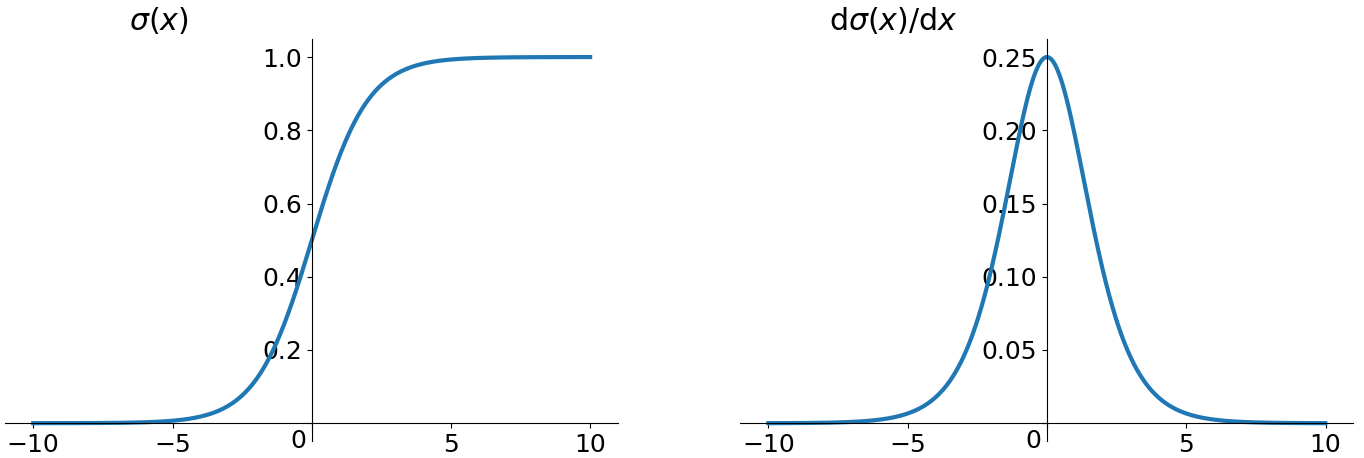
缺点1:在深度神经网络中梯度反向传递时导致梯度爆炸(小概率)和梯度消失(大概率)
缺点2:sigmoid的输出不是0均值,最终使得收敛缓慢。(按照batch训练,由于不同batch接收的信号不同,可以缓解这个问题)
缺点3:解析式中含有幂运算,计算耗时,增加训练时间
- tanh
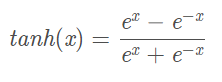
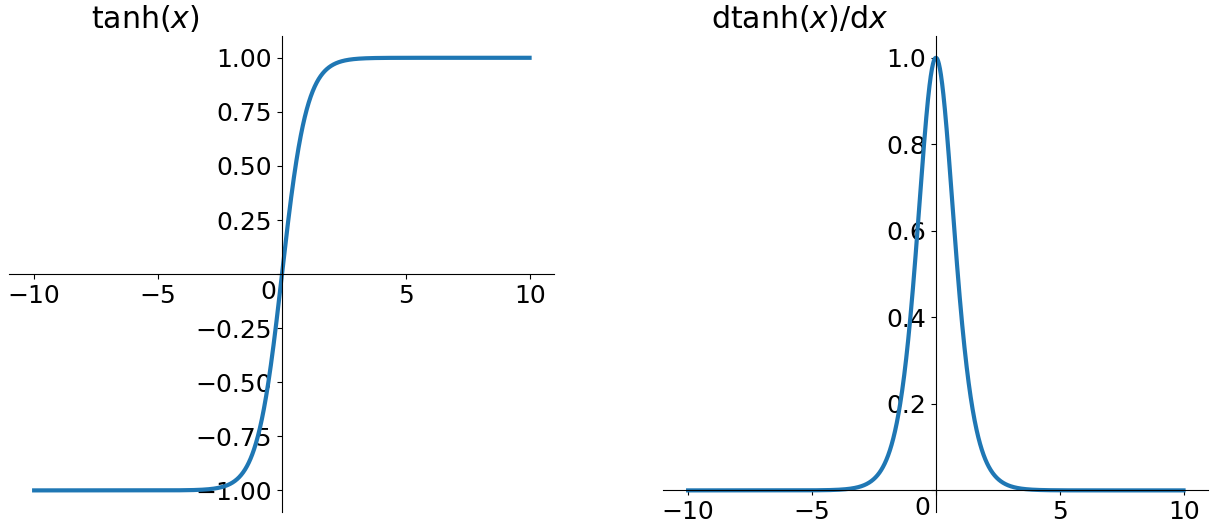
优点1:解决了sigmoid函数的非0均值问题
缺点1:梯度消失
缺点2:幂运算
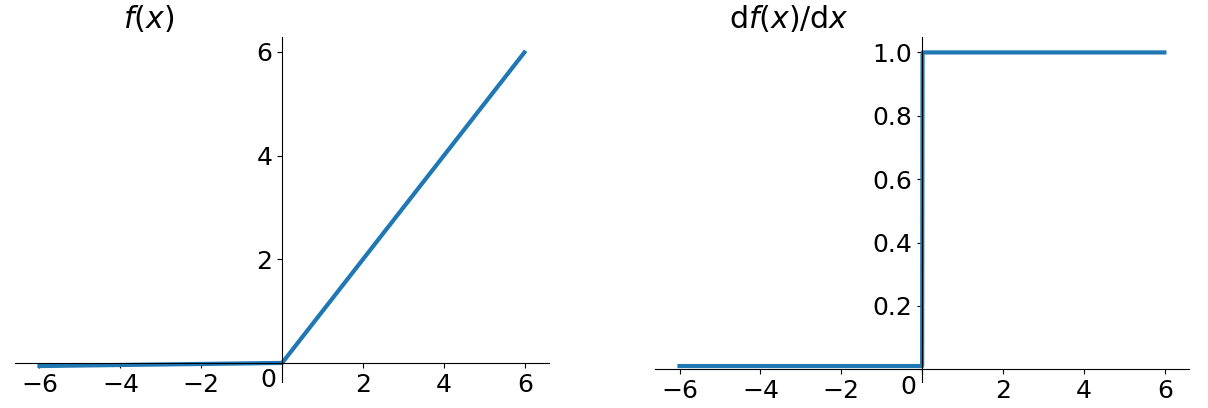
- ReLU(Rectified Linear Unit)
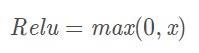
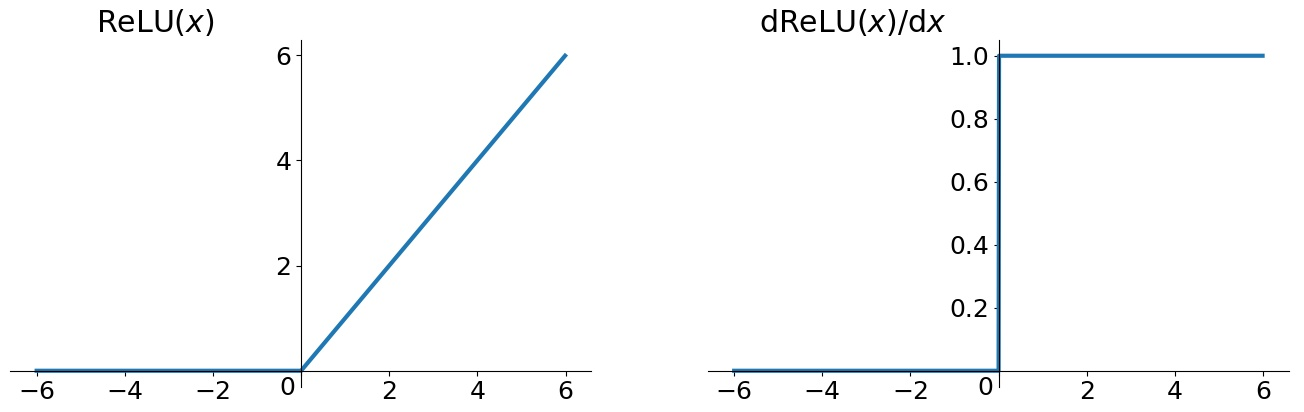
优点1:解决了gradient vanishing问题(正区间)
优点2:计算速度快(只需要判断是否大于0)
优点3:收敛速度远快于sigmoid 和tanh
缺点1:relu的输出不是0均值
缺点2:Dead ReLU Problem(某些神经元可能永远不会被激活,导致相应的参数永远不能被更新)
原因1:非常不幸的参数初始化(小概率)
原因2:Learning Rate 太高导致训练过程中参数更新太大
解决1:采用Xavier 初始化方法
解决2:避免将Learning Rate 设置太大
解决3:使用adagrad 等自动调节Learning Rate 的算法
- Leaky ReLU
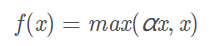
通常 α = 0.01
优点:解决了ReLU的Dead ReLU Problem,理论上好于ReLU,但实际中并没有好的证据表明Leaky ReLU总是优于ReLU
-
- P-ReLU(Parametric ReLU)
训练α:参考Kaiming He的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》
-
- R-ReLU(Randomized ReLU)
随机α:首次试在 kaggle 的NDSB 比赛中被提出的
- ELU(Exponential Linear Units)
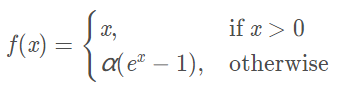
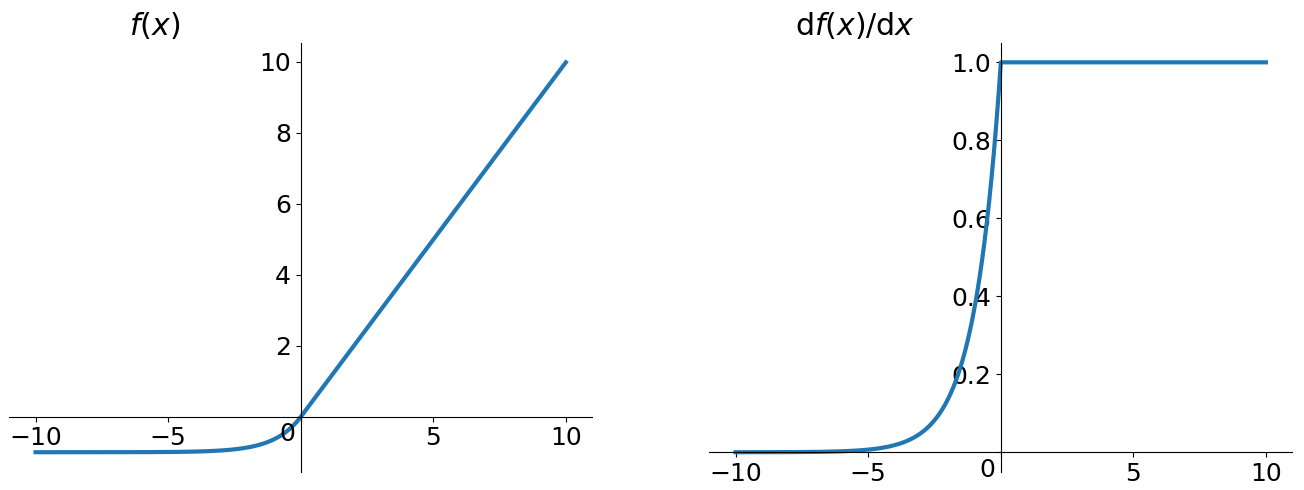
优点1:不会有Dead ReLU Problem,理论上好于ReLU,但实际中并没有好的证据表明ELU总是优于ReLU
优点2:输出的均值接近0(zero-centered)
缺点:计算量稍大
- MaxOut
参考Goodfellow的论文《maxout networks》(ICML2013)
参考资料
2.3 卷积神经网络 CNN(Convolutional Neural Network)
擅长领域:图片识别和语言识别
扩展领域:视频分析、自然语言处理、药物发现
具体应用:alpha go
卷积操作:通过批量过滤器,对一小块区域进行处理,形成边缘信息
神经网络的作用:从边缘信息里面总结出更高层的信息结构(眼睛,鼻子,嘴)
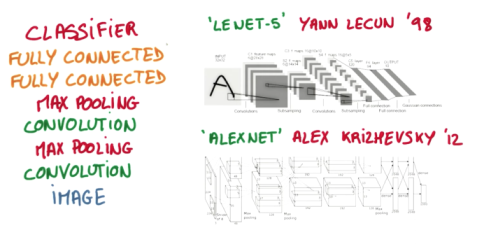
网络结构:LeNet-5,AlexNet
简单的CNN:image -> convolution -> max pooling -> convolution -> max pooling -> fully connected -> fully connected -> classifier
2.4 循环神经网络 RNN(Recurrent Neural Network)
擅长工作:处理序列数据
具体应用:描述照片,写论文,写脚本,作曲
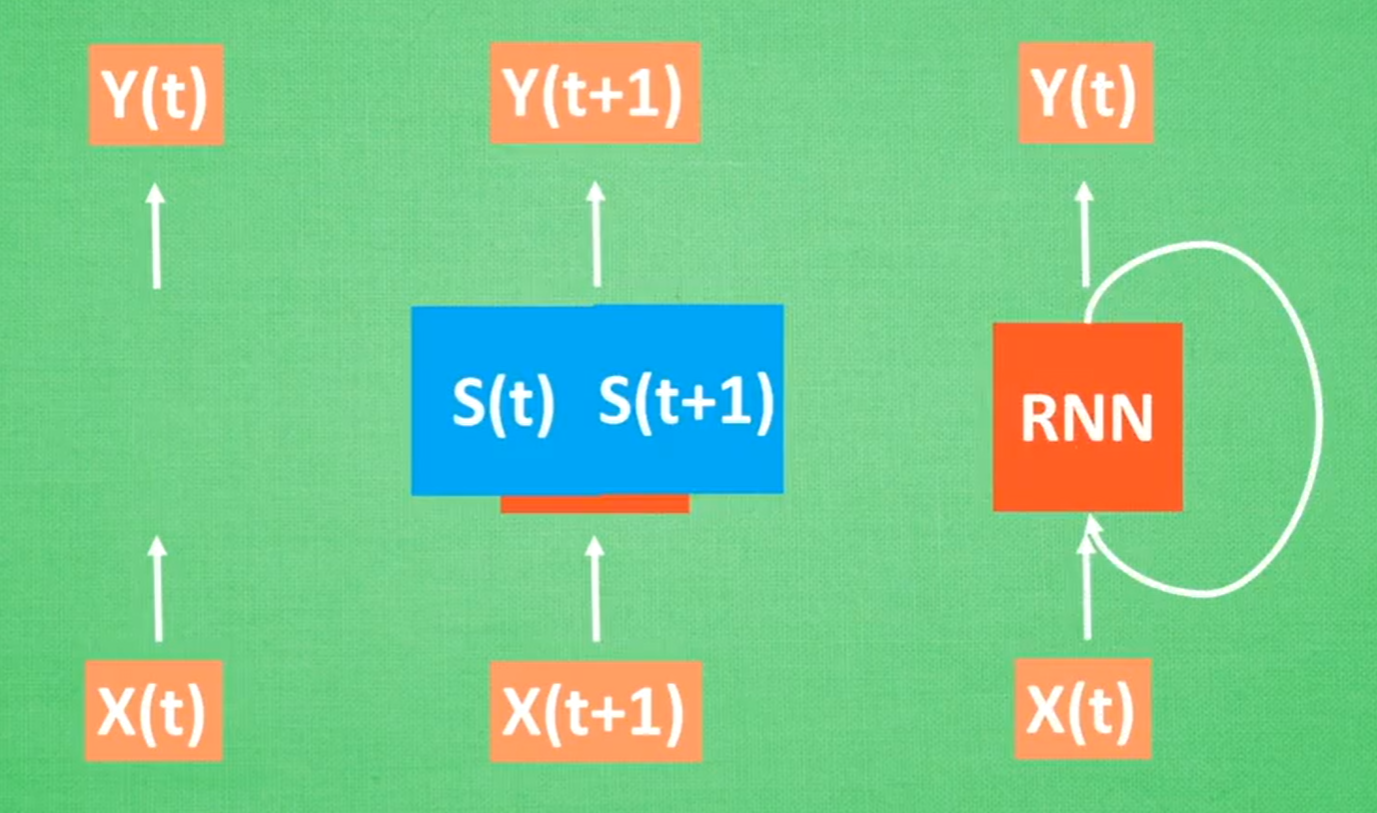
常规结构
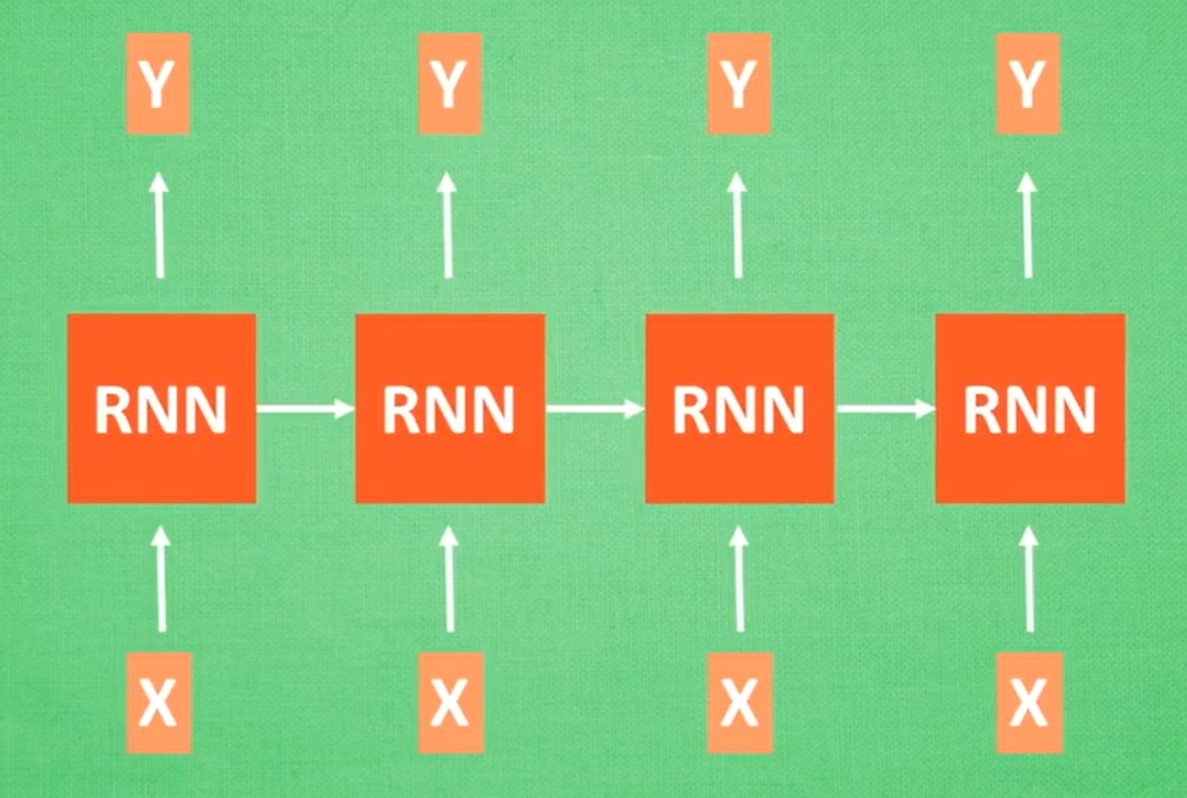
分类问题
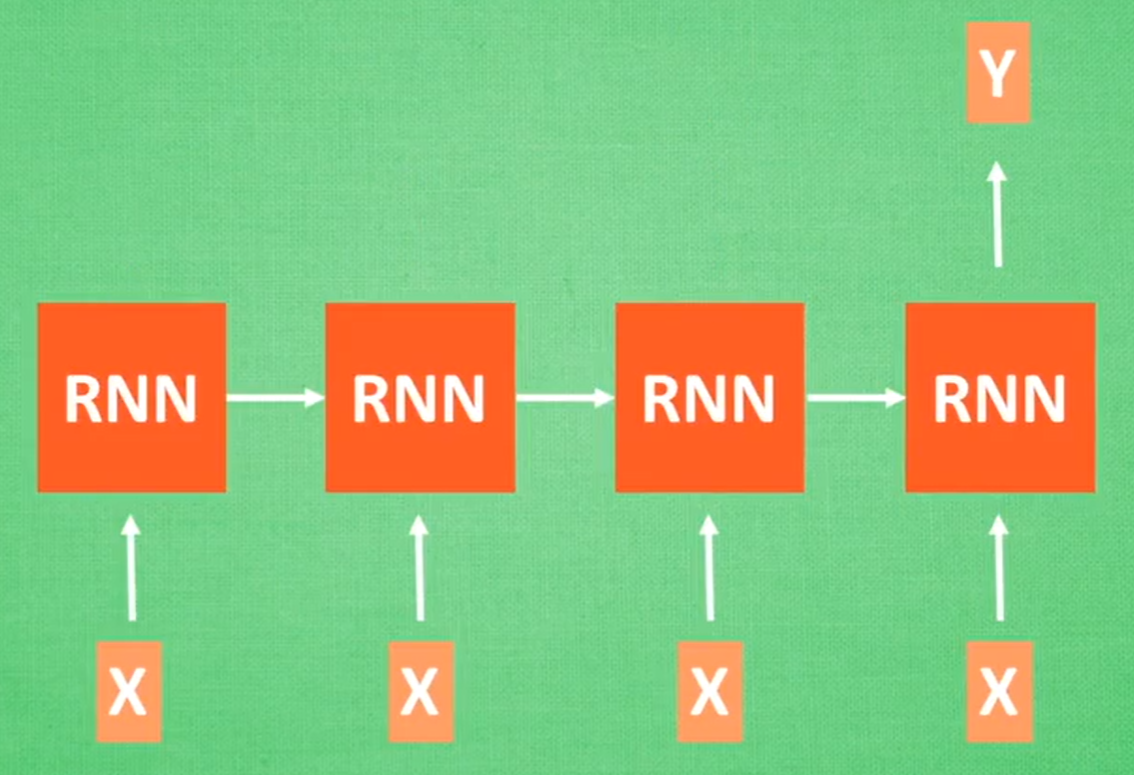
图片描述
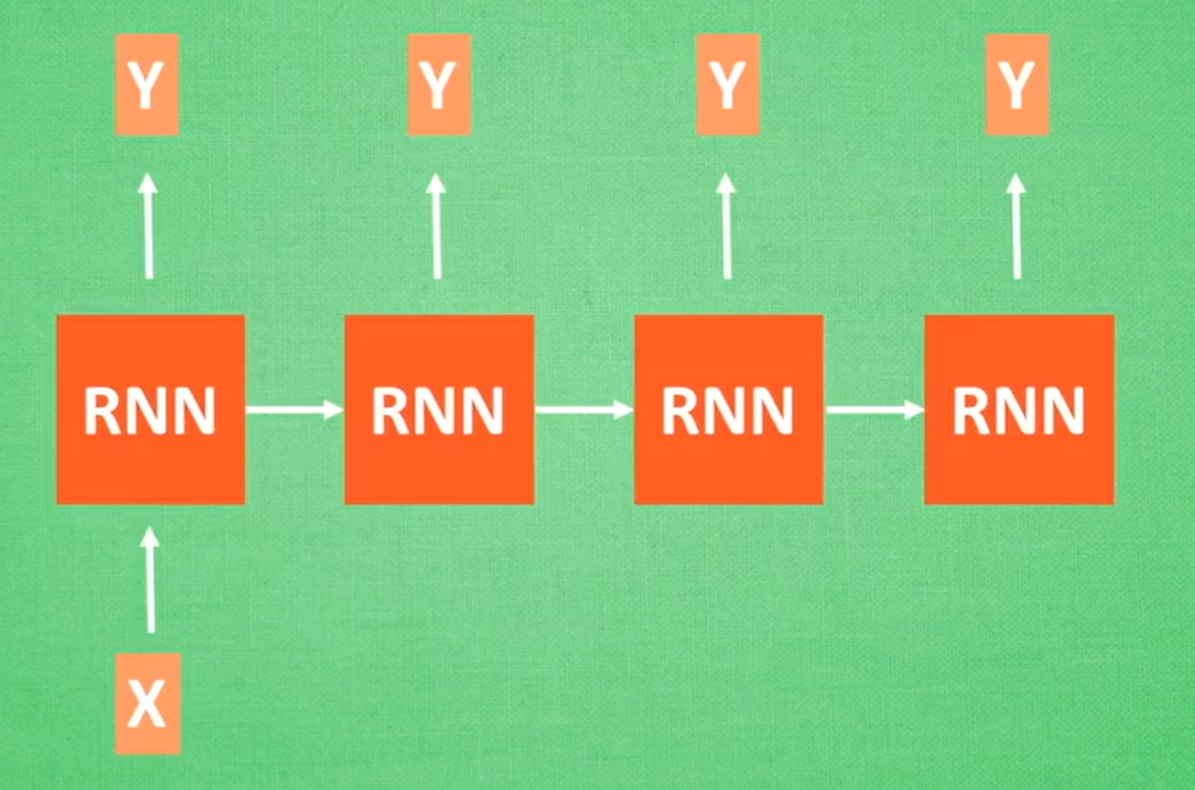
语言翻译

参考资料
2.5 LSTM RNN 循环神经网络(LSTM,Long Short-Term Memory)
RNN的问题:无法回忆起久远记忆(反向传播过程中出现误差的梯度消失/梯度爆炸问题)
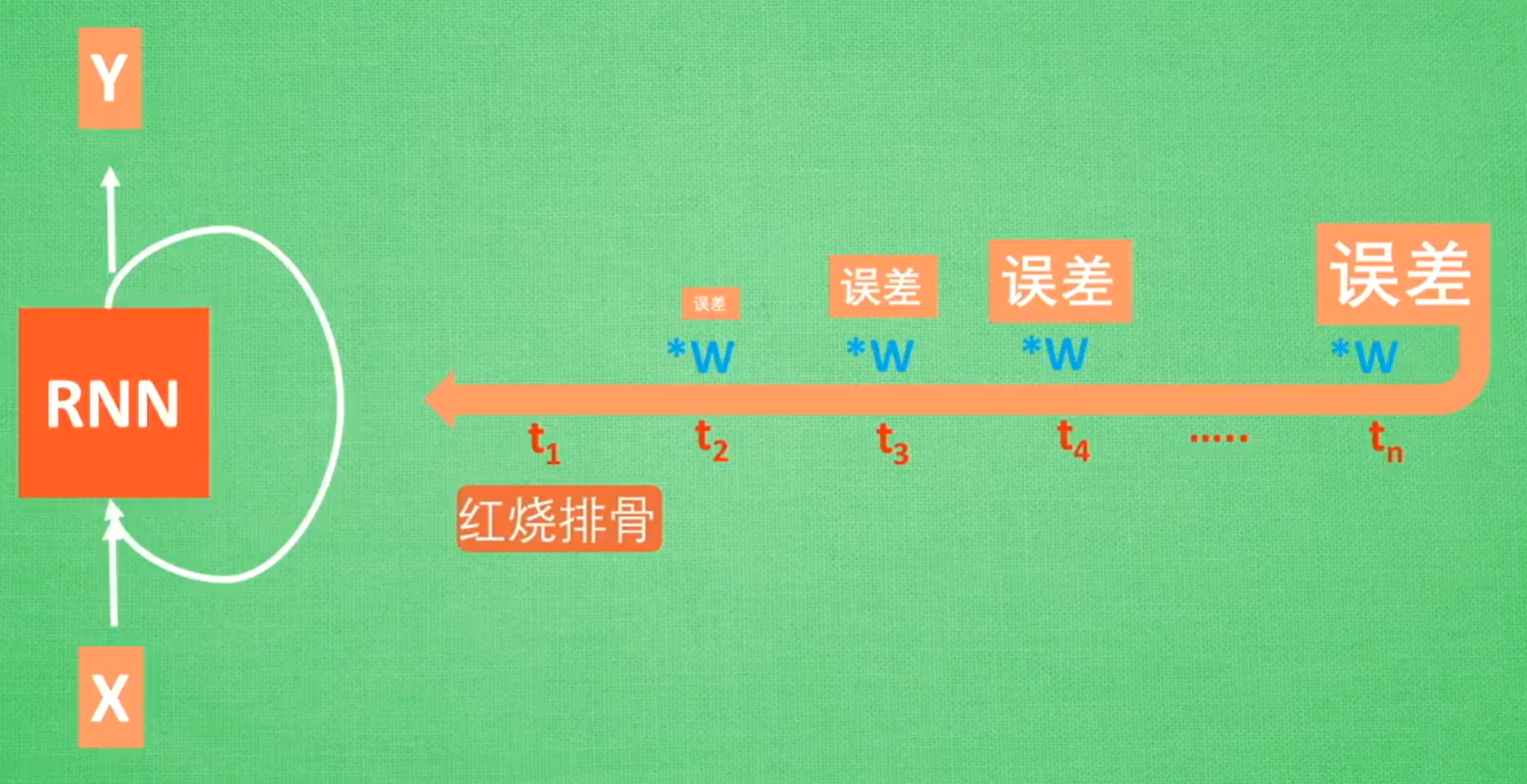
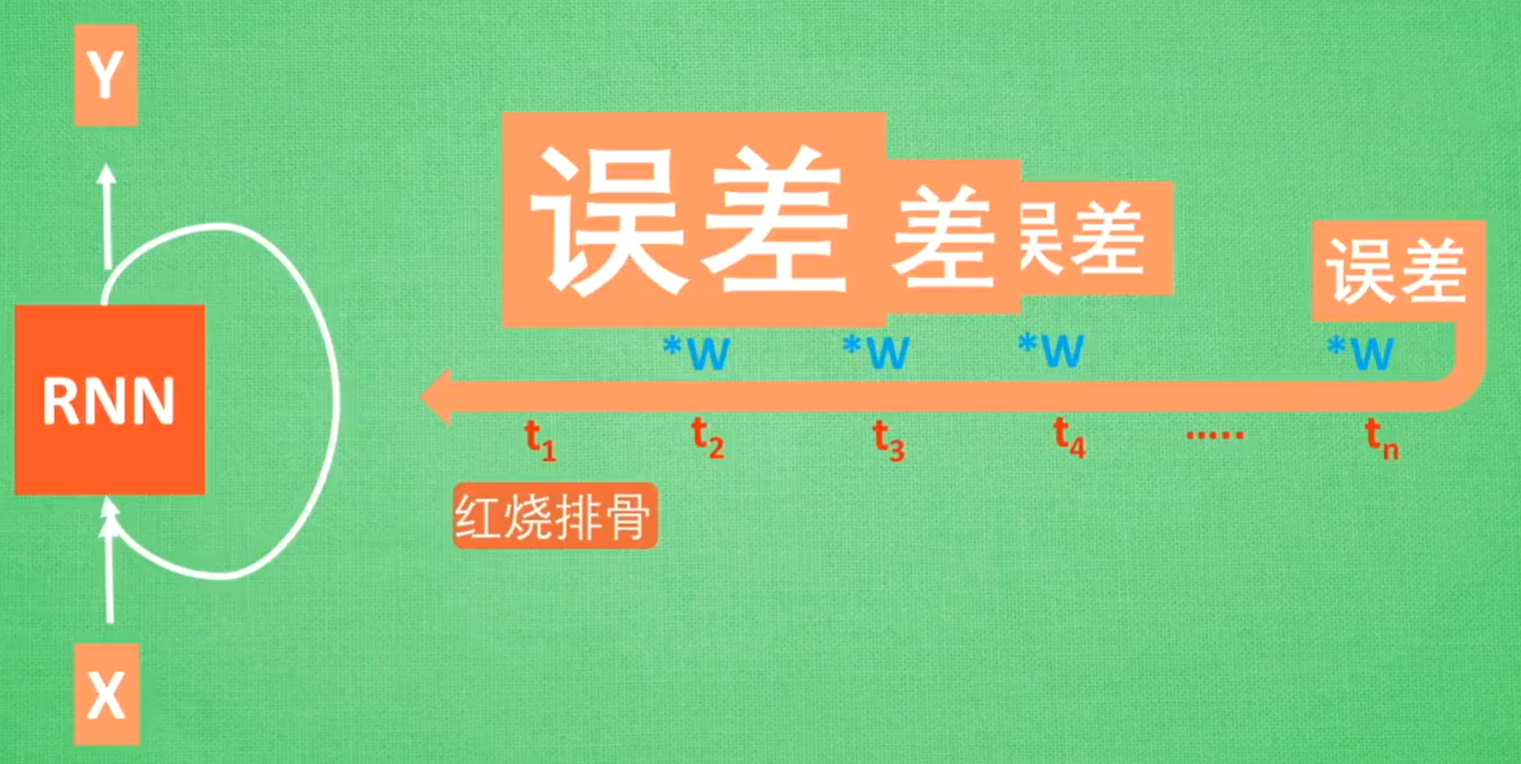
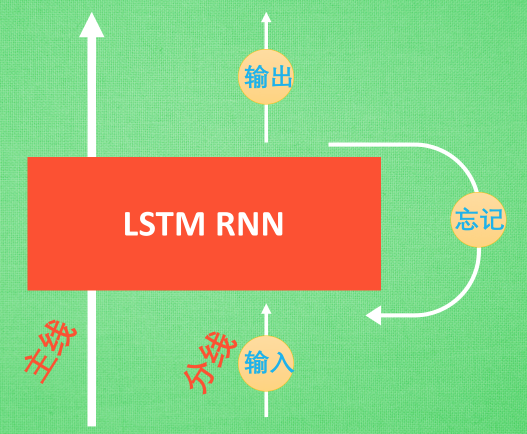
LSTM的结构:输入控制+忘记控制+输出控制
- 输入控制按照风险剧情的重要程度,写入主线剧情
- 忘记控制将之前不重要的主线剧情进行忘记,按比例替换成现在的新剧情
- 输出控制基于目前的主线剧情和分线剧情,判断输出的结果
2.6 自编码(Autoencoder)

学习过程(非监督学习):压缩 -> (特征)学习 -> 解压,对比黑白X,求出预测误差,反向传递,提升自编码的准确性
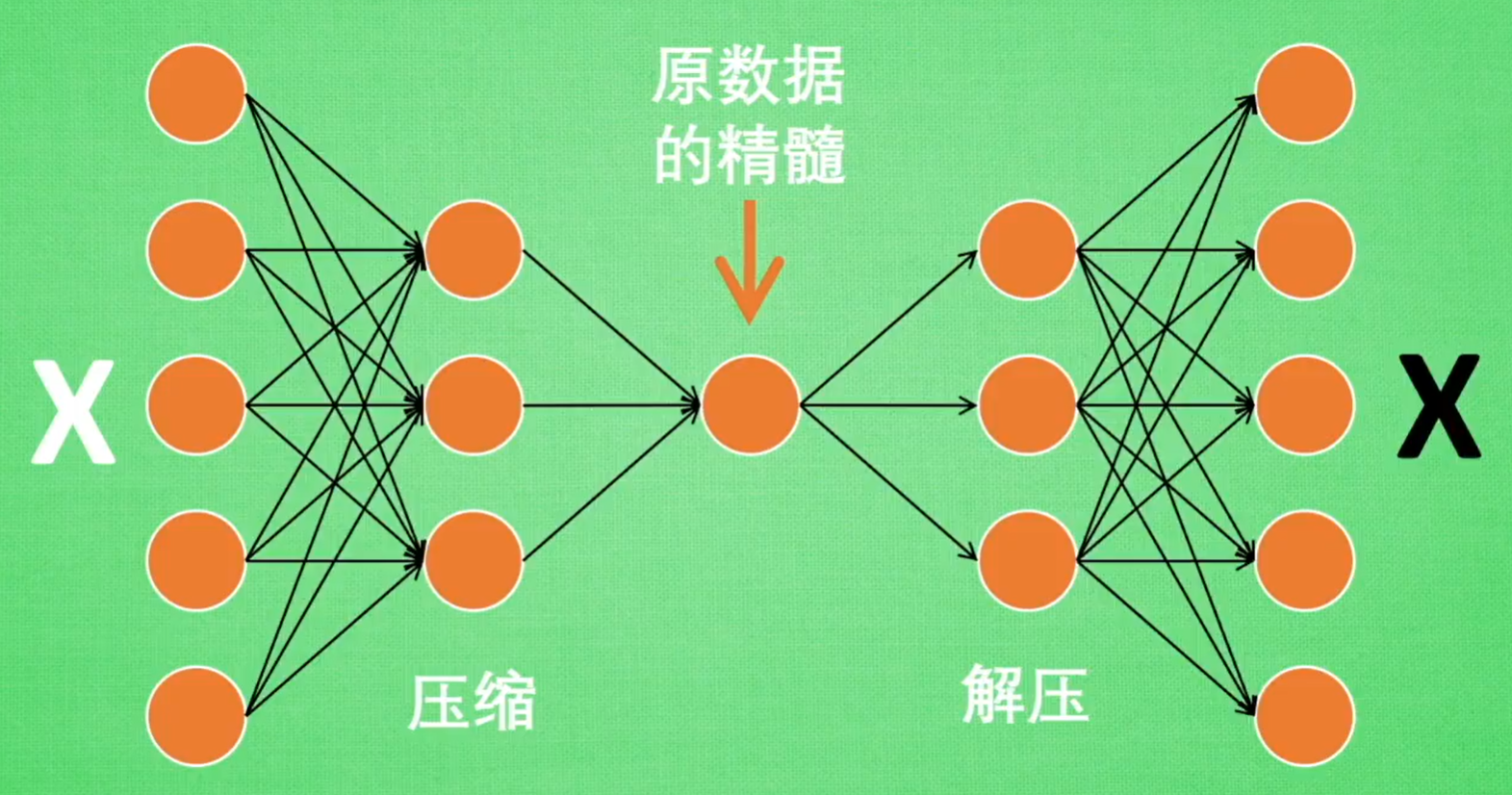
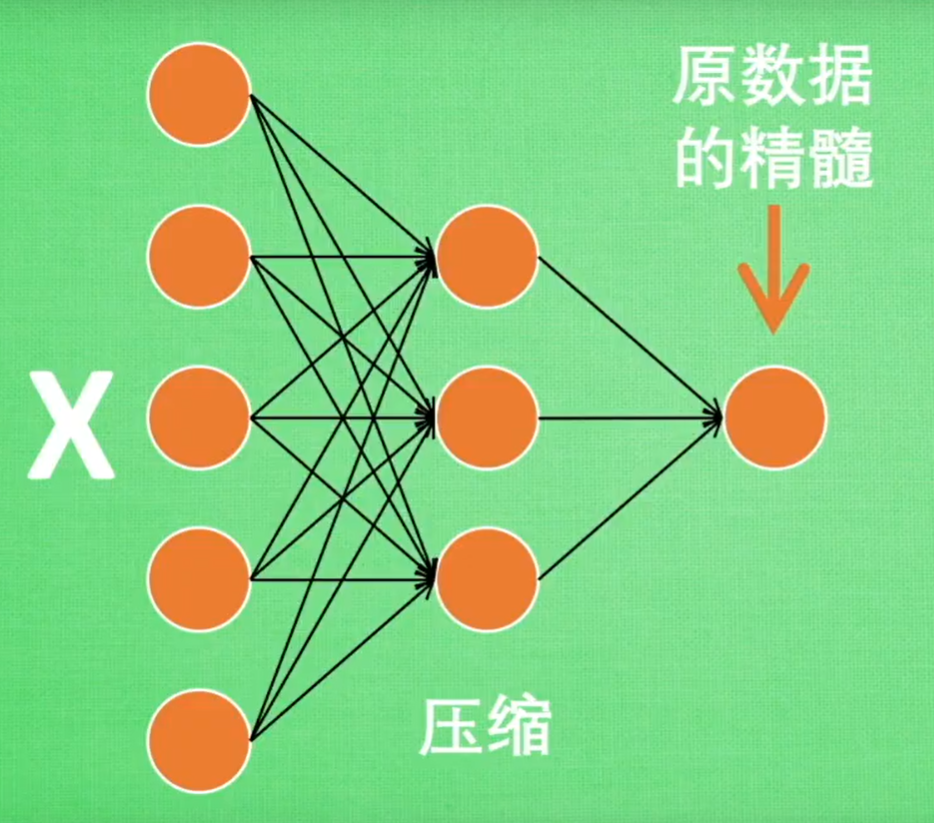
编码器:Encoder
用途:给特征属性降维(类似于PCA)
解码器:Decoder
用途:作为生成器(类似于GAN)
实例:variational autoencoders,模仿并生成手写数字

2.7 生成对抗网络(GAN)
神经网络(数据 -> 结果):前向传播神经网络,CNN,RNN
生成网络(随机数 -> 结果):GAN(凭空捏造)
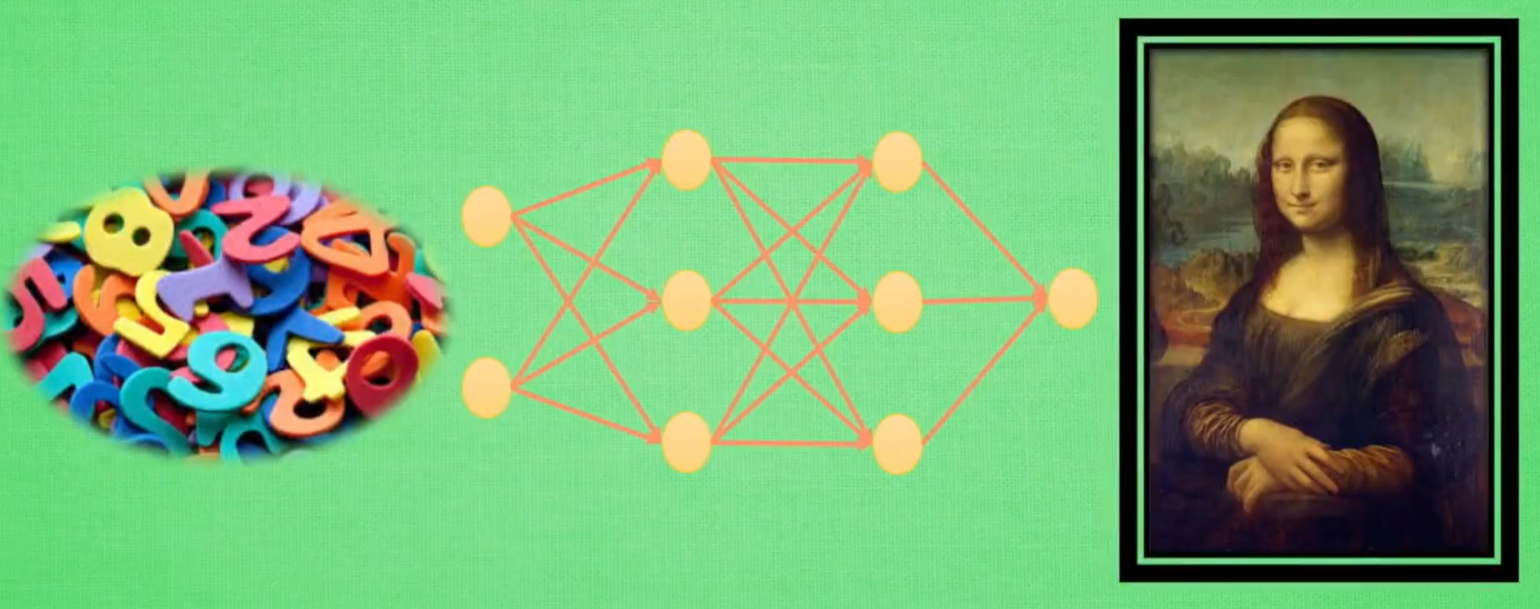
Generator:随机生成画作
Discriminator:通过带标签的画作,学习判别画作的好坏,进一步指导Generator生成画作
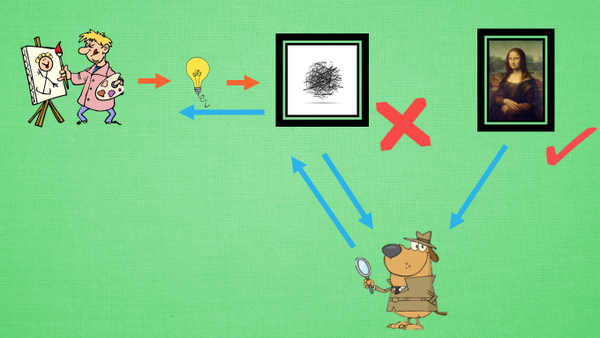
GAN网络
1. Generator根据随机数生成数据
2. Discriminator学习判断那些是真实数据,反向传递给Generator
3. Generator生成更真实的数据

2.8 神经网络的黑盒不黑
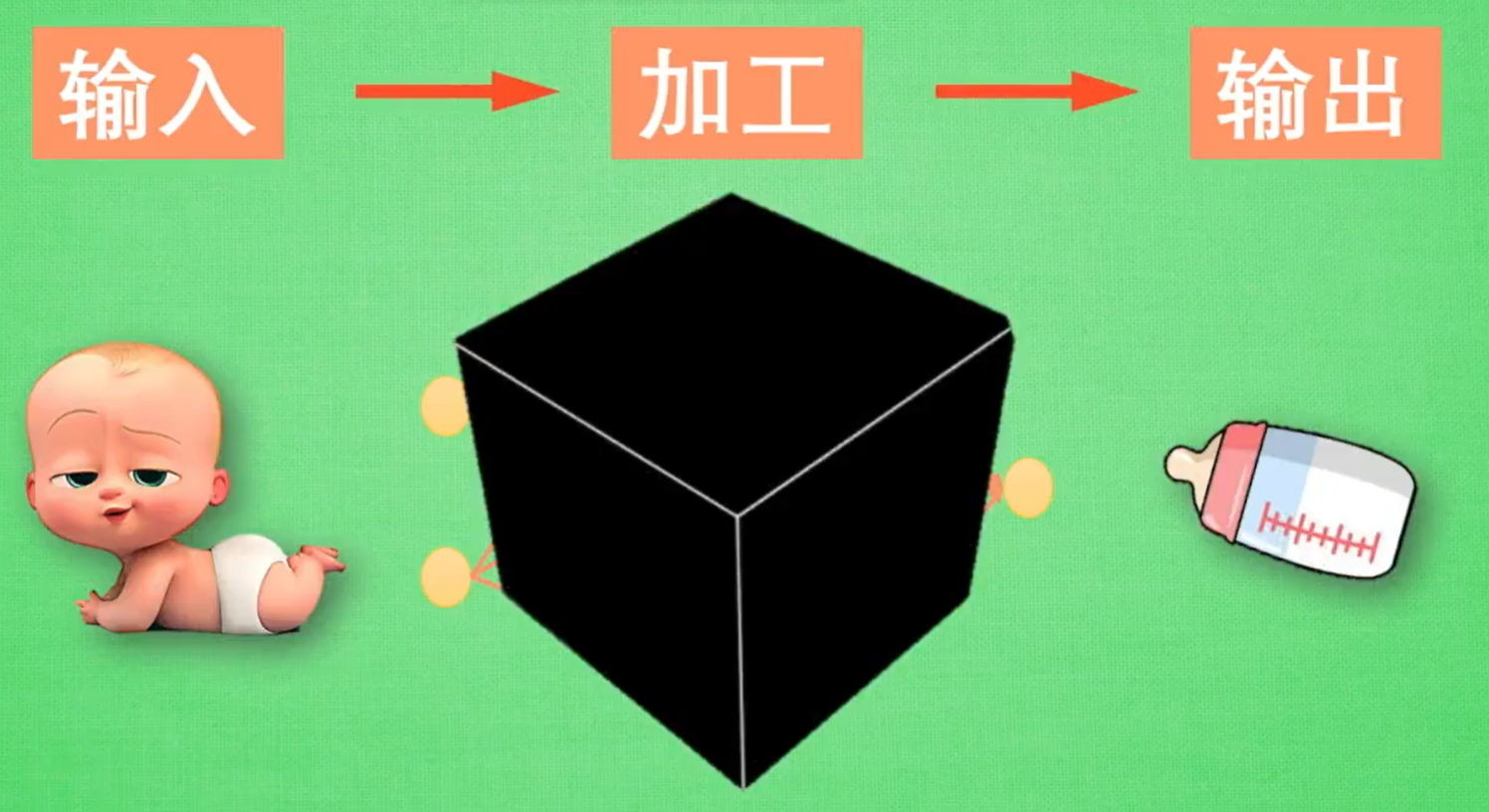
神经网络的分层:输入 -> 代表特征1 -> 代表特征2 -> 输出

高级玩法:迁移学习(Transfer Learning)
保留一个神经网络的理解能力(转换代表特征的能力),套上另一个神经网络,用这种移植的方式进行再训练
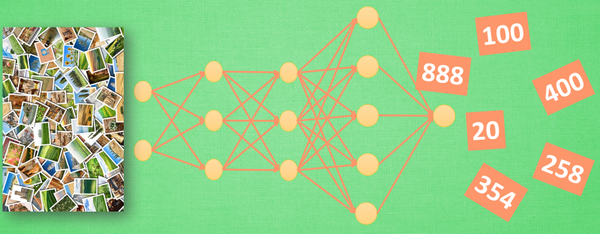
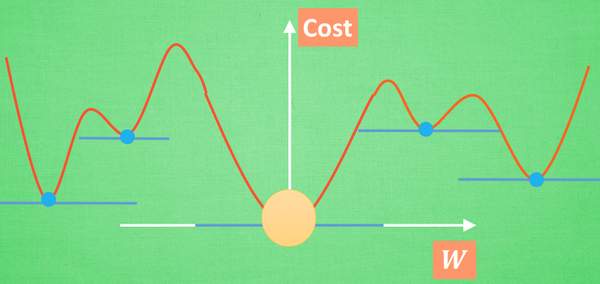
2.9 神经网络:梯度下降(Gradient Descent)
优化问题分类:牛顿法(Newton's method)、最小二乘法(Least Squares method)、梯度下降法(神经网络,...)
误差方程(cost function):计算预测数值与实际数值之间的差别

全局最优(Globa minima) & 局部最优(Local minima)
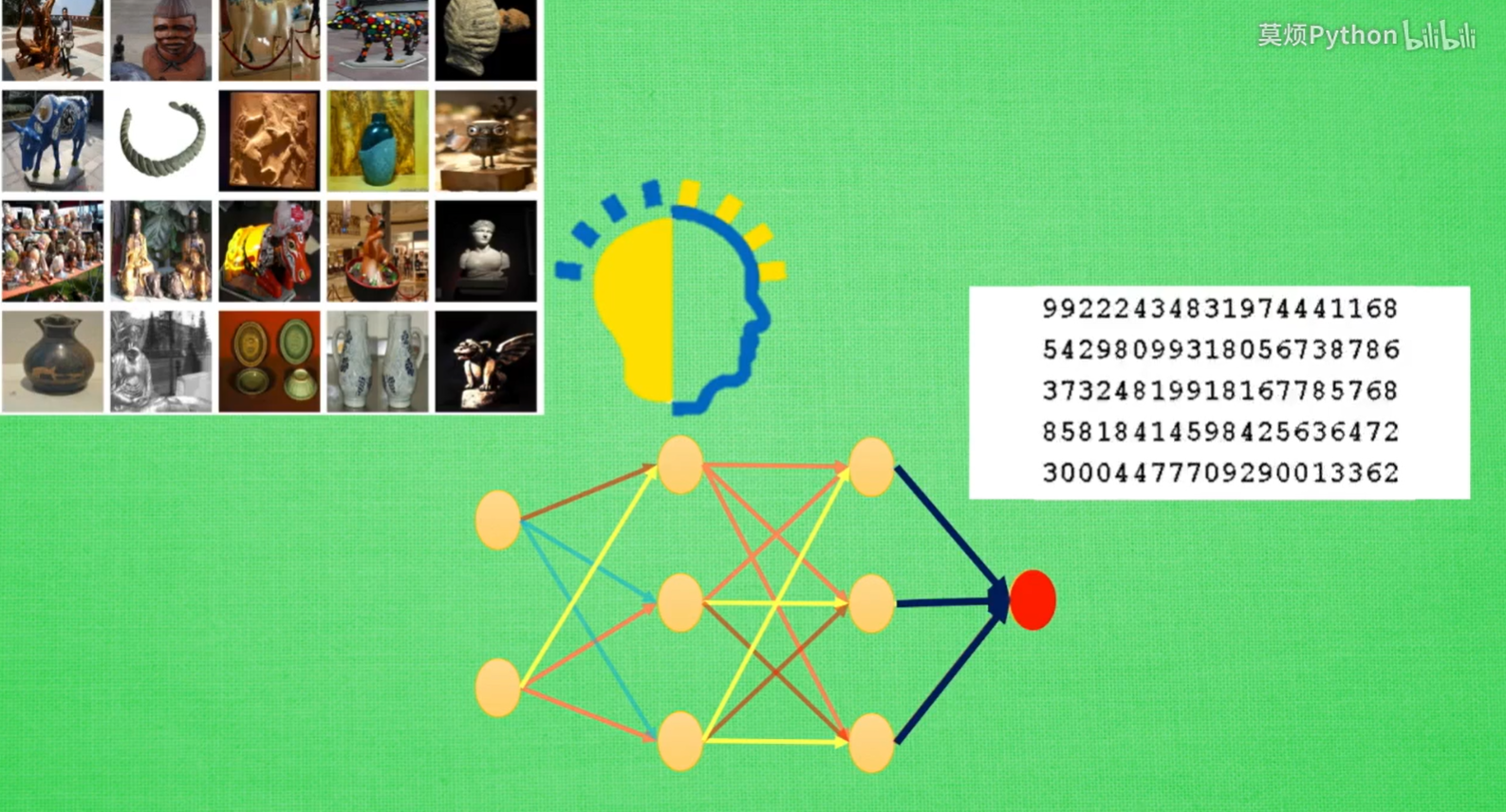
2.10 迁移学习(Transfer Learning)
适用场景:已经训练好的图片分类模型,去掉输出层,保留对图片的理解能力,用于新的图片评估任务

不适用的场景:迁移前的数据和迁移后的数据差距很大
新玩法:多任务学习,或者强化学习中的 learning to learn
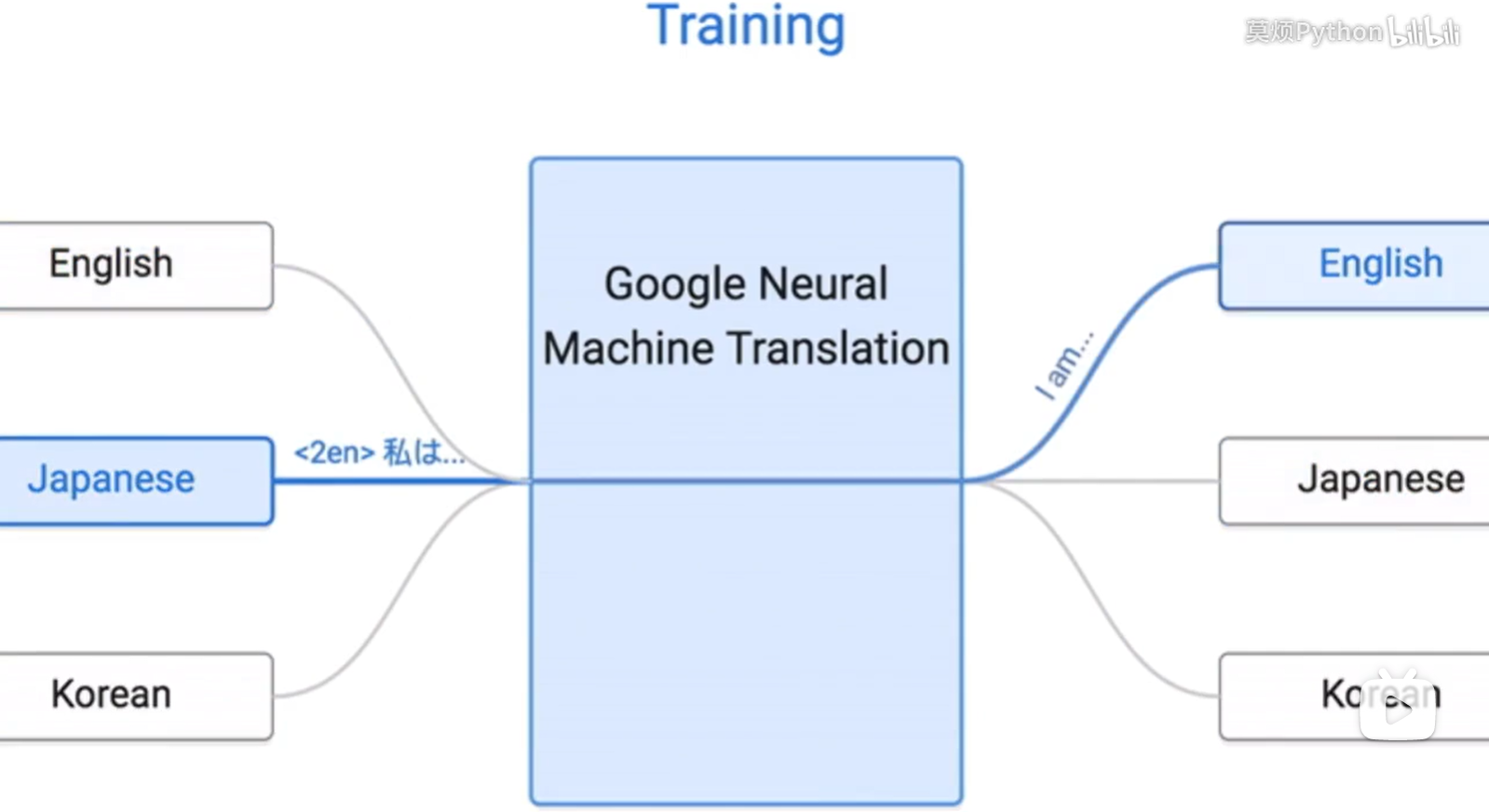
应用:不同语言之间的翻译
神经网络技巧
3.1 检验神经网络(Evaluation)
数据集分类:0.7训练数据,0.3测试数据
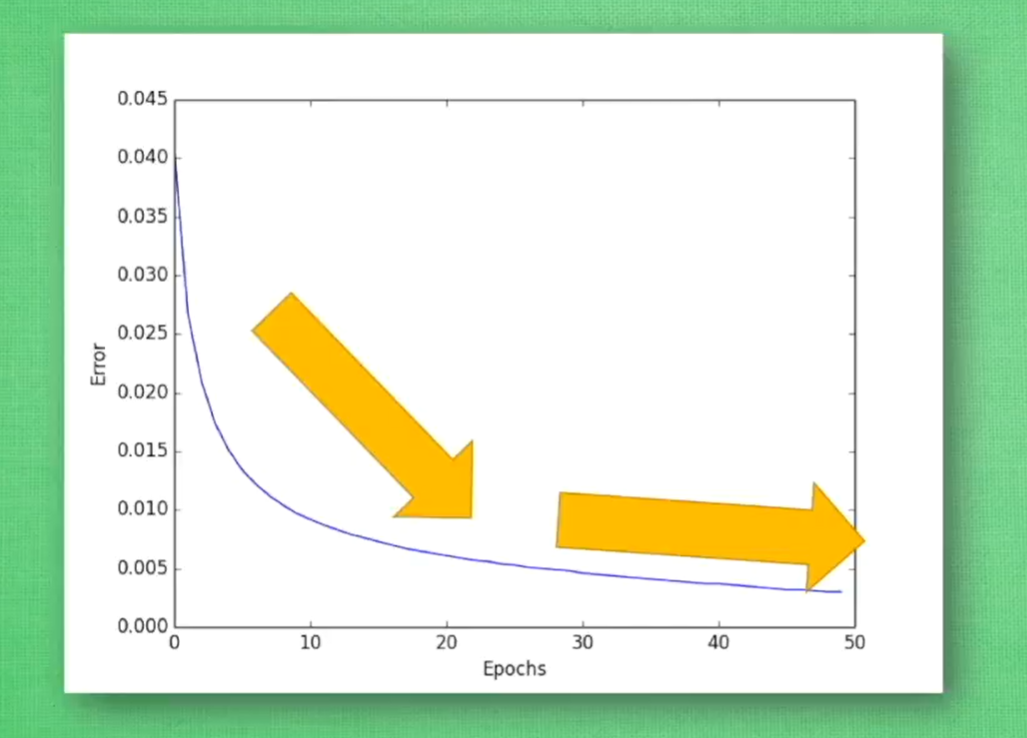
误差曲线(Error)
精确曲线(Accuracy)
- R2 score:适用于分类和回归问题
- F1 score:测量不均衡数据的精度
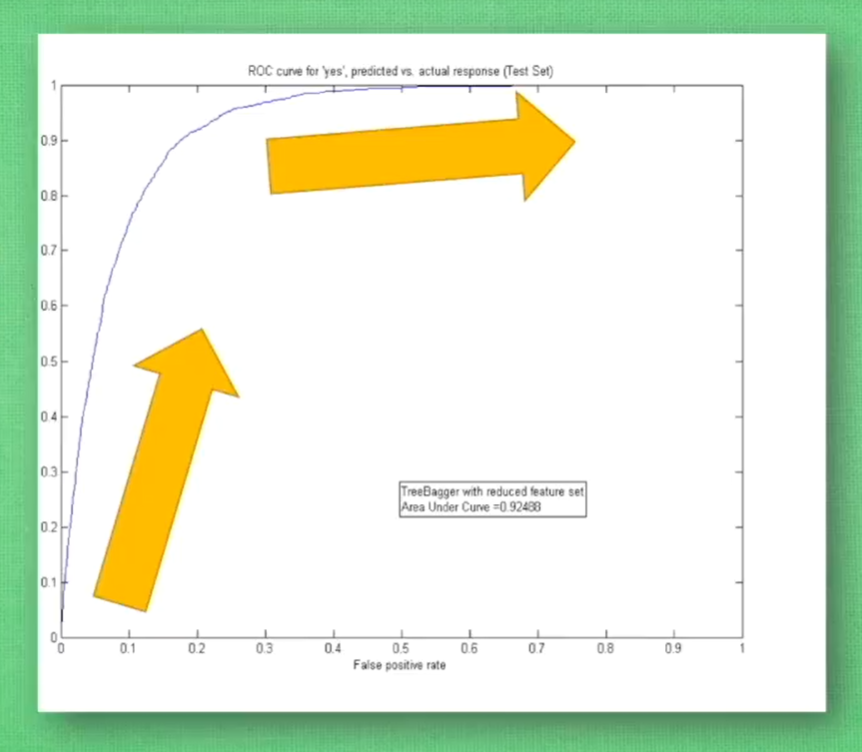
过拟合(overfitting)
- 增加数据量
- L1/L2 regularization
- Dropout
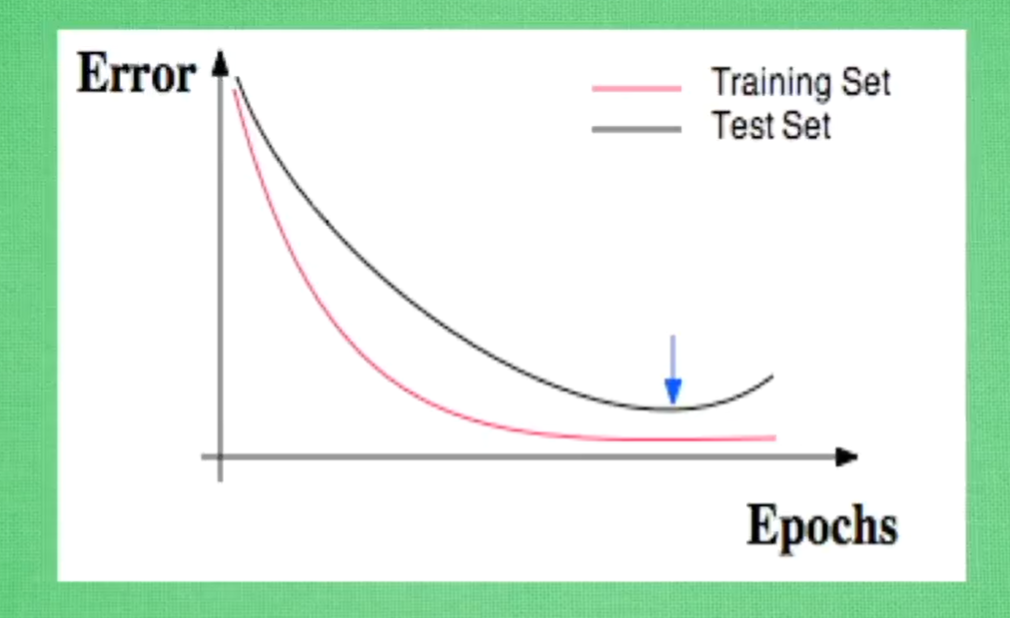
交叉验证:横坐标设置为需要测试的某一参数,纵坐标为误差值或精度值
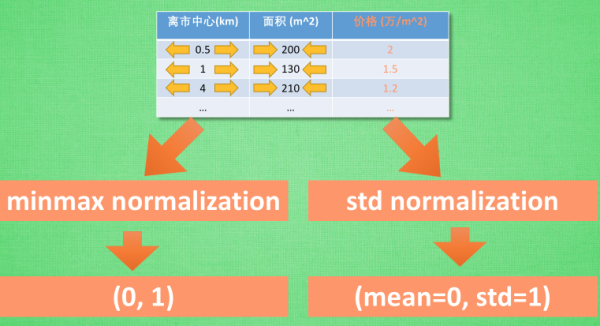
3.2 特征标准化(Feature Normalization)
min-max normalization
数据在(0,1)之间分布
std normalization
mean=0(均值), std=1(方差)
3.3 选择好特征(Good Features)
- 避免无意义的信息
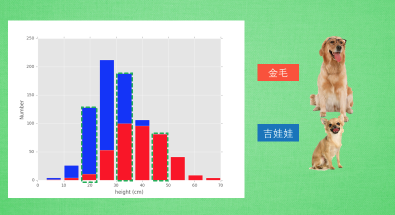
单一特征有时不能够很好的进行区分,此时需要多个特征进行验证


1 import matplotlib.pyplot as plt 2 import numpy as np 3 4 gold, chihh = 400, 400 5 6 gold_height = 40+10*np.random.randn(gold) 7 chihh_height = 25+6*np.random.randn(chihh) 8 9 plt.hist([gold_height, chihh_height], stacked=True, color=['r', 'b']) 10 plt.show()

- 避免重复性的信息
- 避免复杂的信息
测量步行时间时,特征信息选择AB间的距离,而不是AB间的经纬度
3.4 过拟合(Overfitting)
L1/L2 regularization
避免参数W变化太大(曲线过于扭曲)

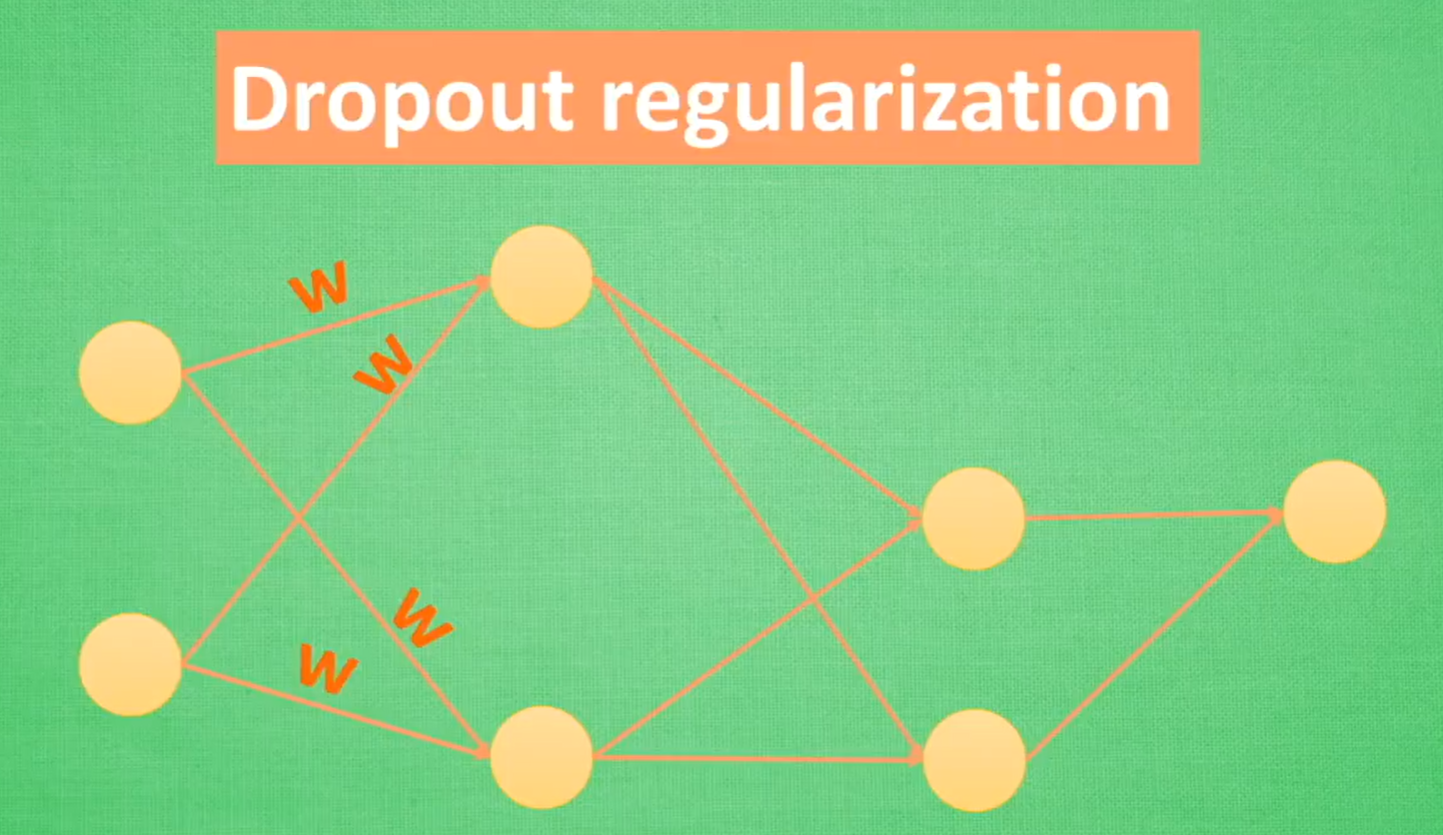
Dropout regularization
每次训练都随机忽略一些神经元,使得预测结果不依赖其中某些特定神经元
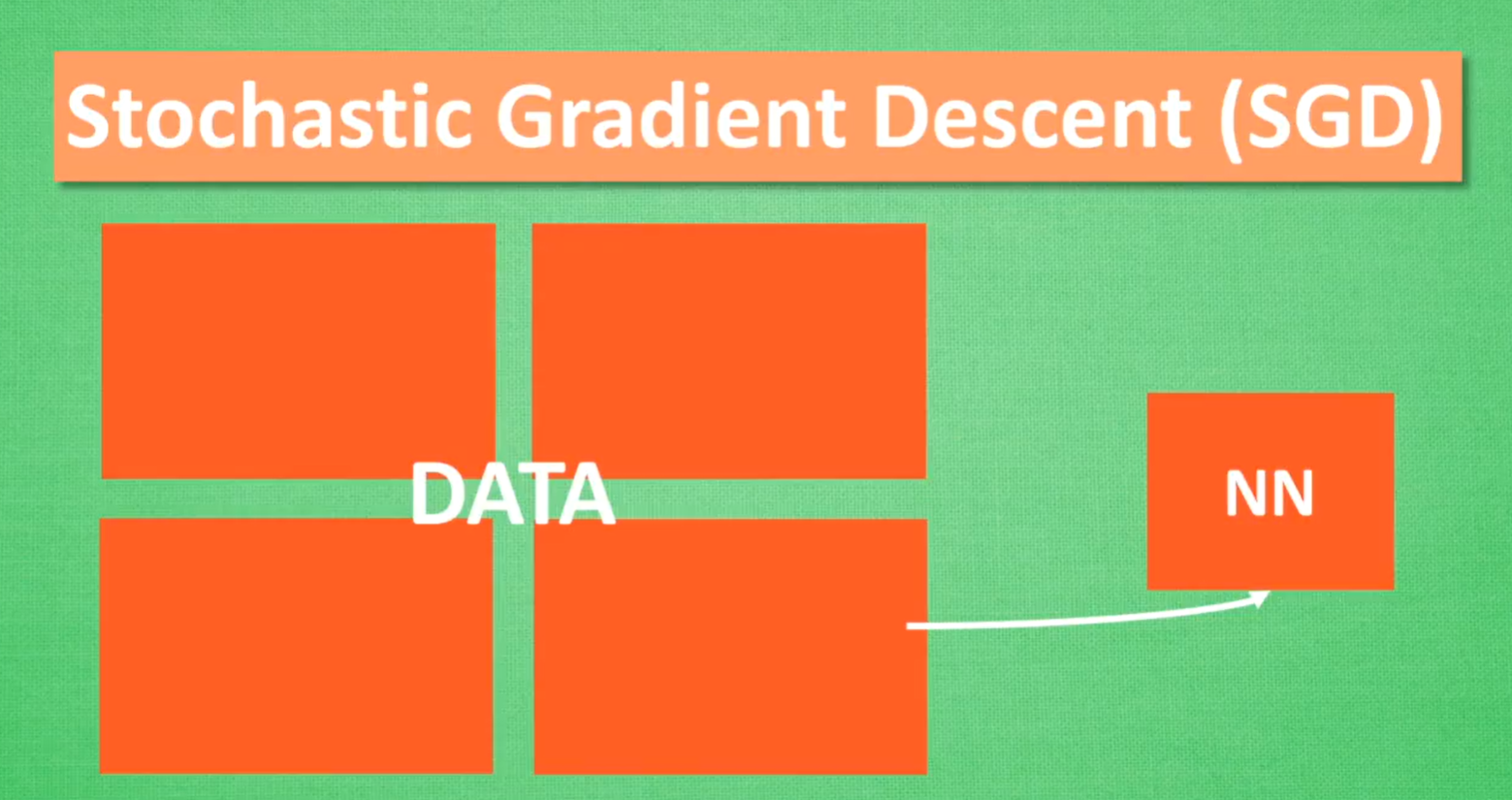
3.5 优化器(Optimizer,加速神经网络训练)
SGD(Stochastic Gradient Descent)
数据分批训练
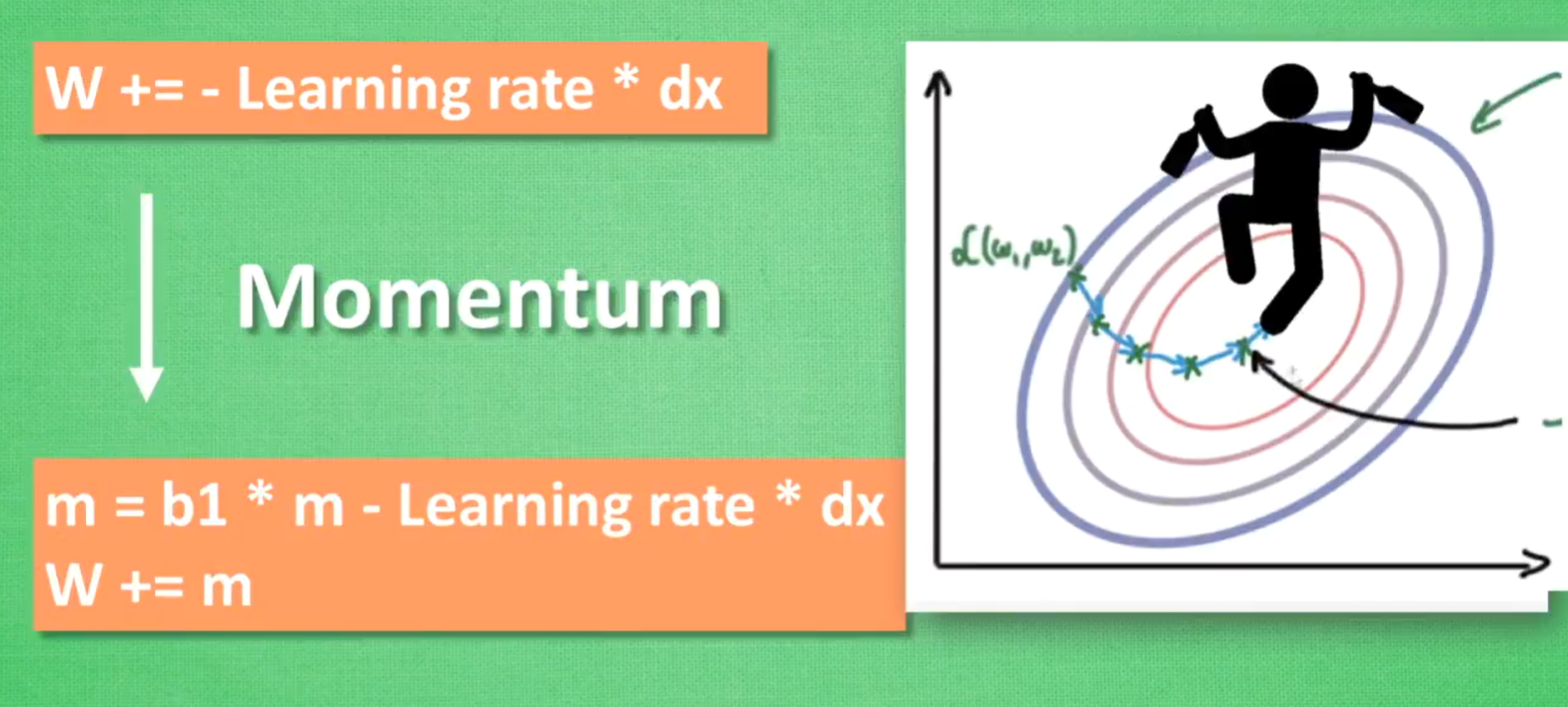
Momentum
优化网络参数
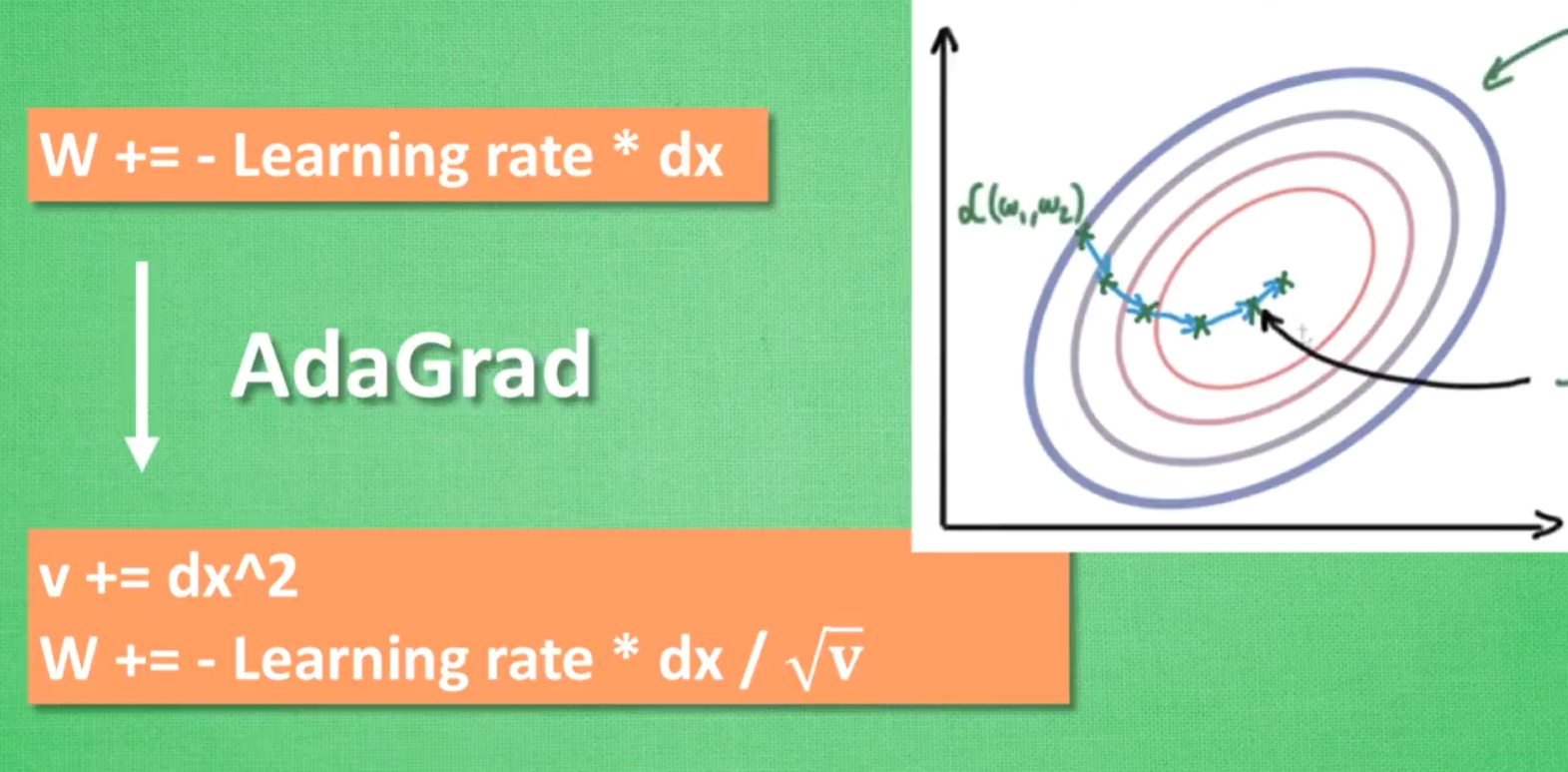
AdaGrad
优化学习率
RMSProp
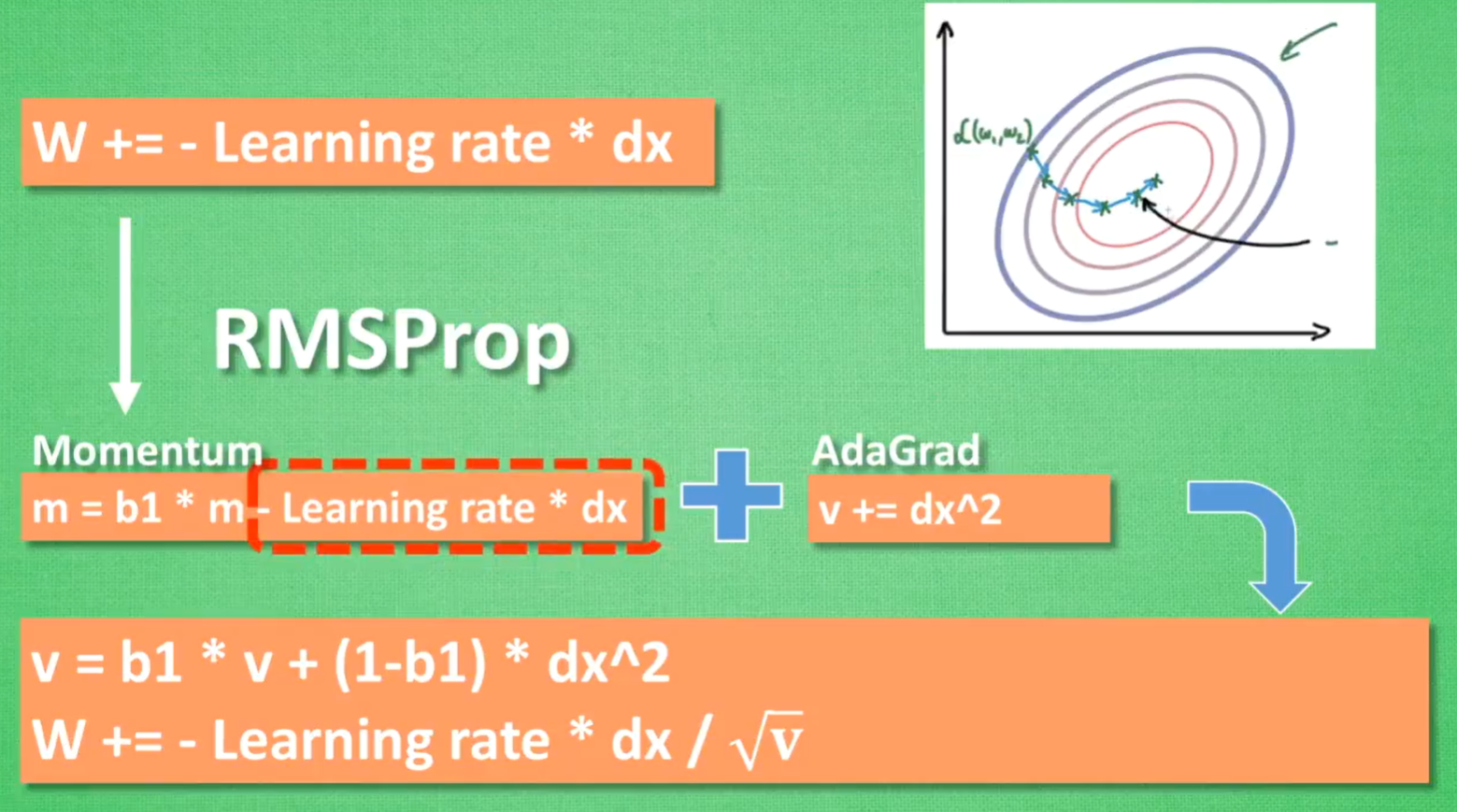
Adam

3.6 处理不均衡数据(Imbalanced data)
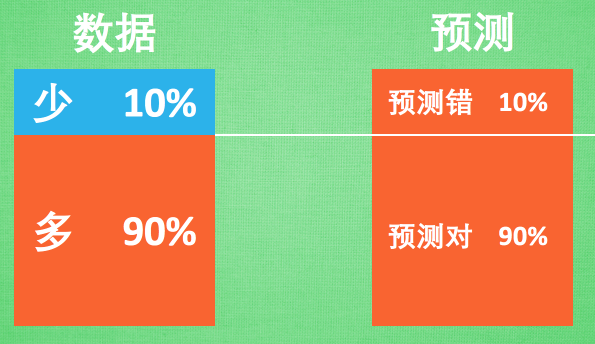
获取更多数据

更换评判方式

重组数据:复制少数样本 / 砍掉多数样本

其他机器学习方法:如决策树
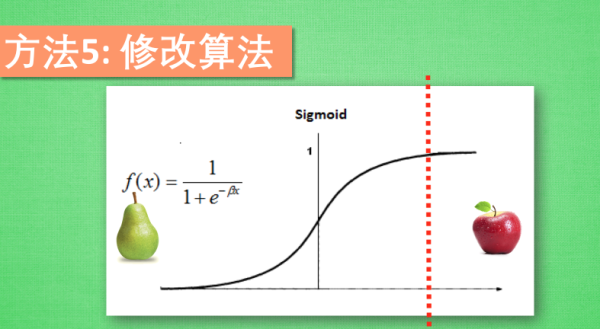
修改算法:调整预测通过的门槛
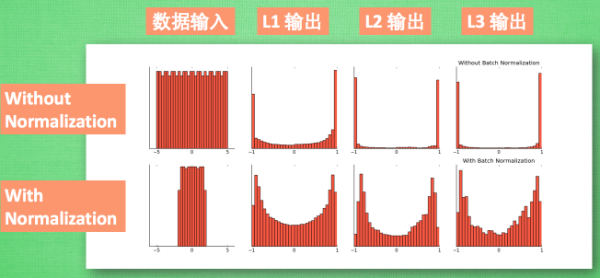
3.7 批标准化(Batch Normalization)
数据标准化:将分散数据统一的方法
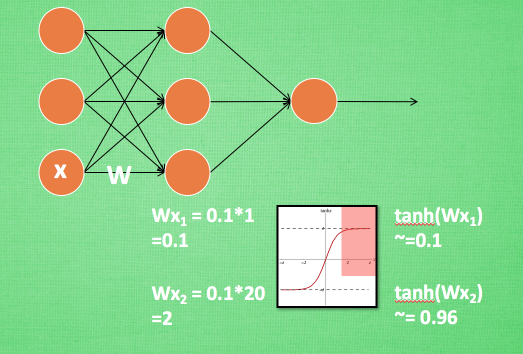
逐层进行标准化:解决激励函数处于饱和阶段(W>2,tahh~1)对x的扩大变得不再敏感
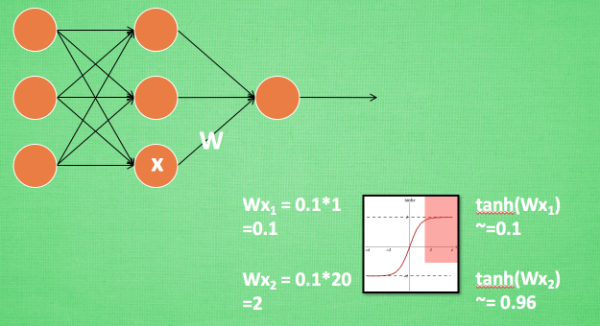
BN添加位置:批数据进行前向传递forward propagation的时候,全连接+BN+激活函数
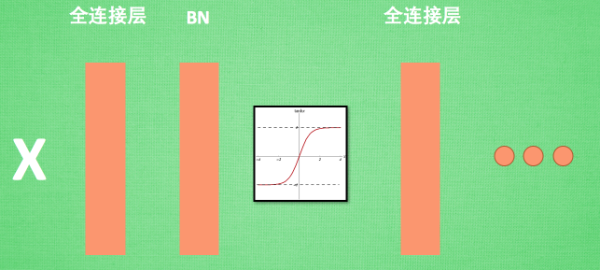
BN效果:更好的传达各层计算结果值的分布
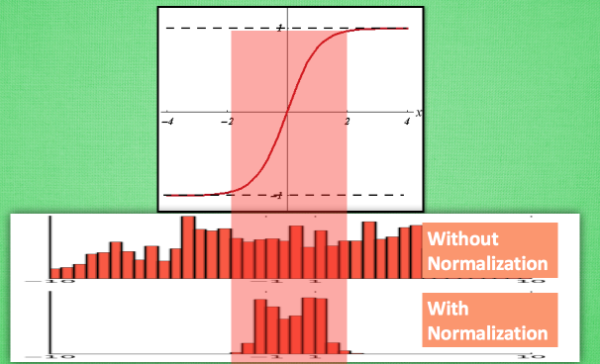
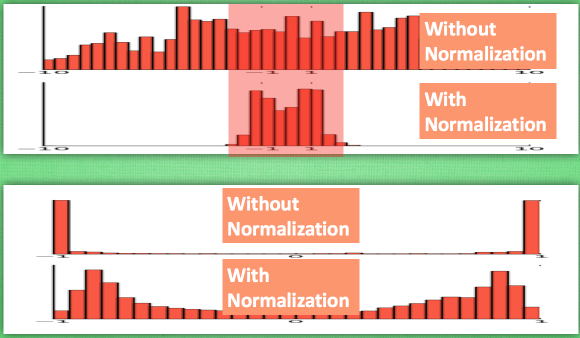
BN算法:反向操作将标准化后的数据再扩展和平移,并让神经网络学着使用和修改扩展参数γ和平移参数β,来加强或低效标准化的操作

3.8 L1 / L2 正规化(Regularization)
解决过拟合问题
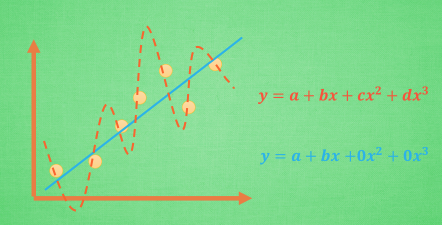
L1 / L2 Regularization:增加参数值的大小对误差的影响
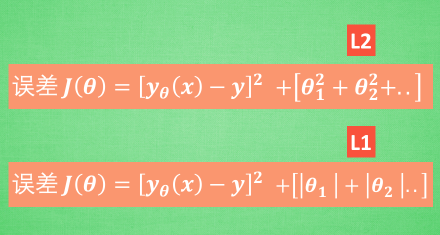
核心思想:避免某一参数的决定性作用过强
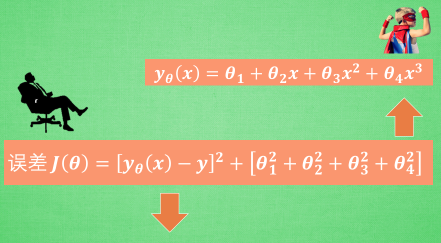
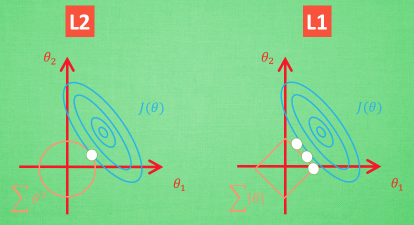
图像化:切点位置能够使得表达式中两个误差和最小,此外,L1具有不稳定性
统一表达式:交叉验证的方法选择参数λ
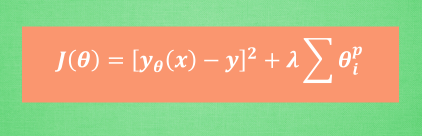
自然语言处理
4.1 什么是自然语言处理 NLP
检索
翻译
对话

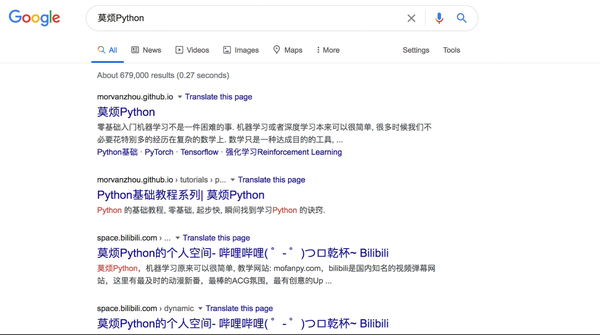
4.2 你天天用的搜索引擎是怎么工作的 - 文章向量化(TF-IDF)
构建索引:爬虫获取网络信息,放入数据池,构建索引,搜索获取

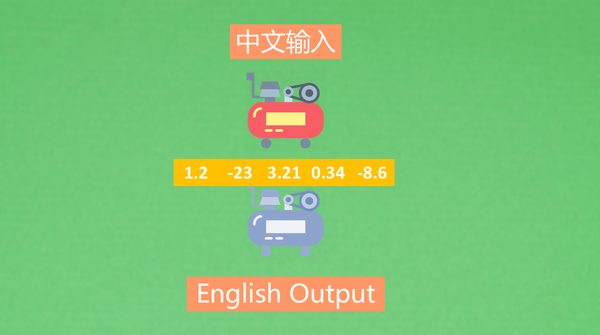
数值匹配搜索(多模态搜索):检索内容 -> 数值1 -> 数值匹配 -> 数值2 -> 返回结果

搜索过滤
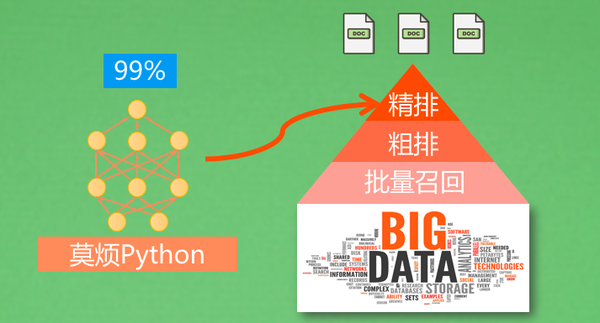
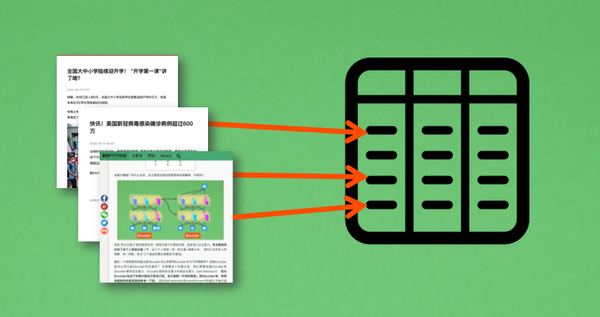
批量召回:正排索引 / 倒排索引
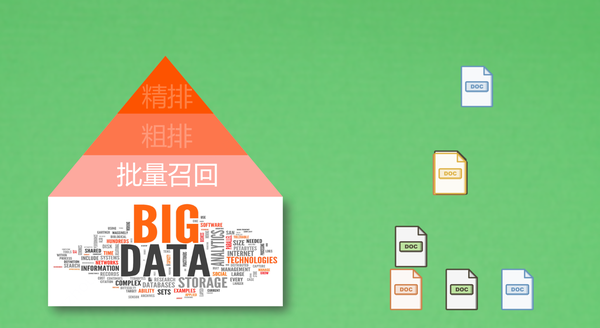
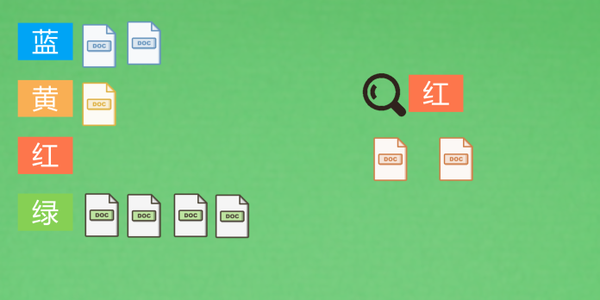
粗排:TF-IDF(Term-Frequency Inverse Document Frequency)
词频(TF):以文章为单位统计单词出现的次数,但是语气词和“你我他”这类词会出现很多次,光靠TF没办法除去这些词的影响,此时IDF就能帮忙
逆文本频率指数(IDF):判断全部文章中出现某个词的频率的高低,用以判断某一词的区分能力


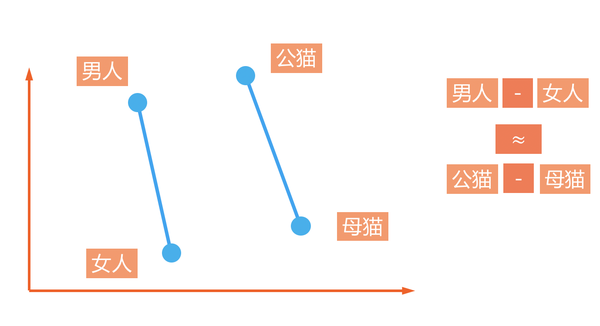
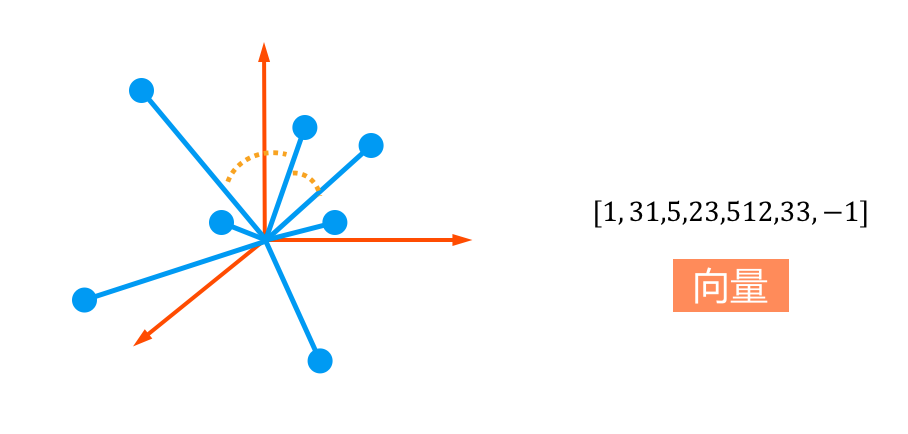
4.3 机器是这样理解语言 - 词向量(Word2Vec)
词汇的相似程度:距离,夹角(cosine)
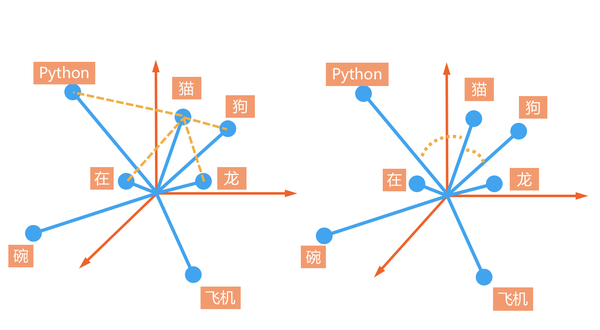
中性词:高频,靠近原点,能够与很多词混搭(在家,在这,在吗)
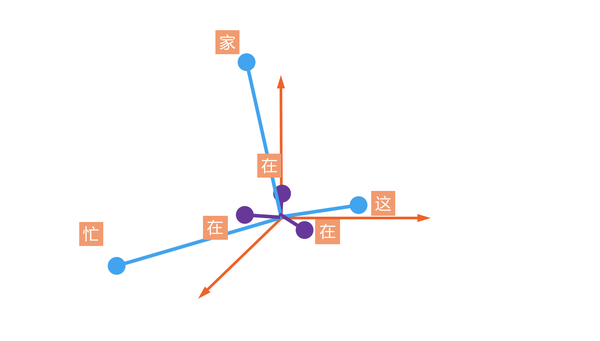
词向量训练:前后文预测中间词,中间词预测前后文

词向量用法:作为预训练特征,输入进另一个模型
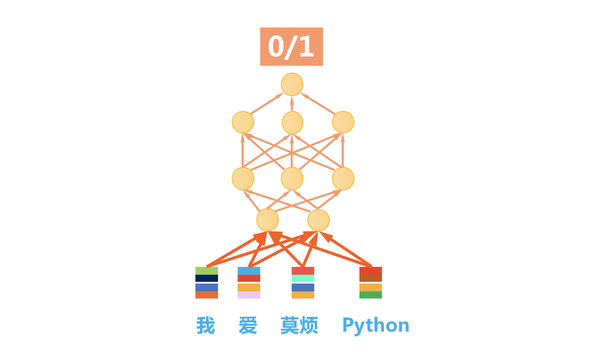
词向量之间的关系
构造词向量:Word2Vec
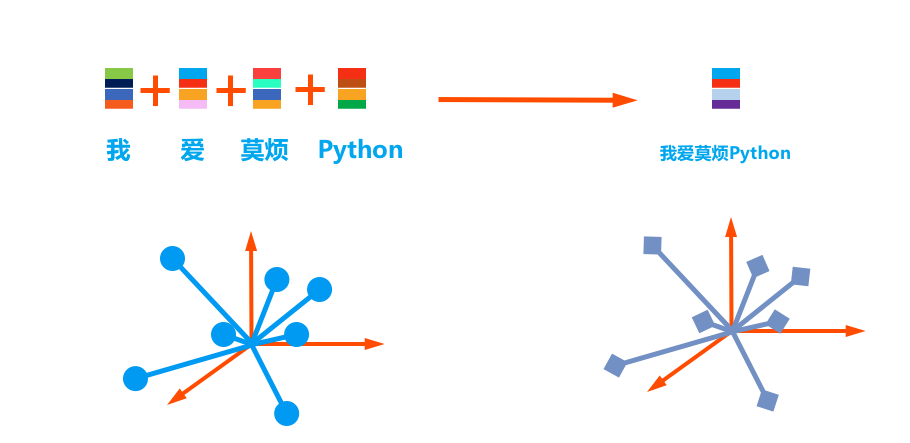
4.4 机器是这样理解语言 - 句向量(Seq2Seq)
词向量表示
从词向量到句向量:(RNN) Encoding -> Decoding (RNN)
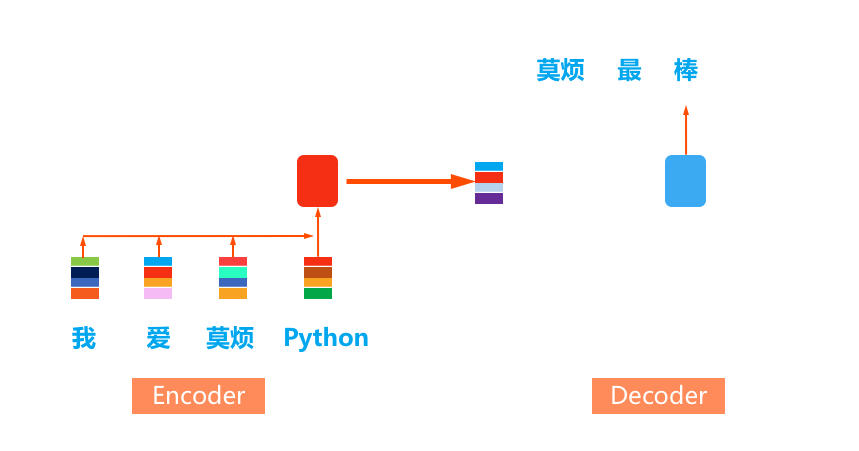
构造句向量:Seq2Seq框架
4.5 请注意用词 - 语言模型的注意力(Attention)
人类的注意力
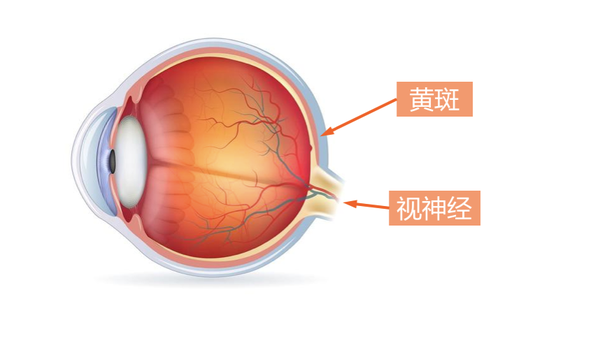
图像识别的注意力
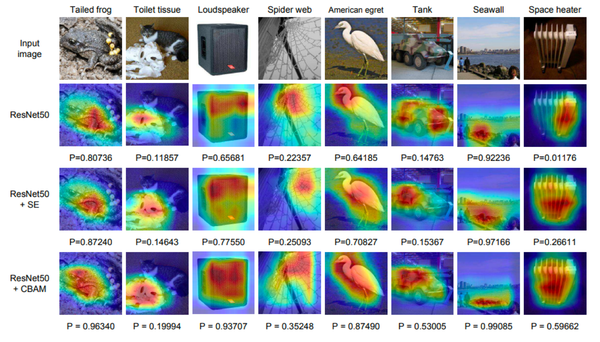
语言处理的注意力

4.6 请注意注意力 - 将注意力发挥到极致(Transformer)
视觉的多次注意
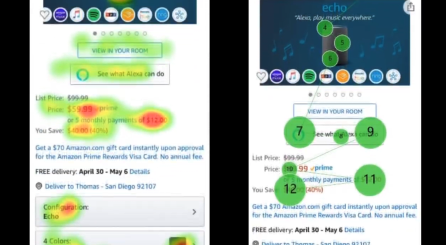
语言的多次注意

注意力模型(Transformer)
多个人同时观察一句话,分别给出各自的注意力,再汇总他们的结论,这种方法相比单人观察,能够有效提升效率
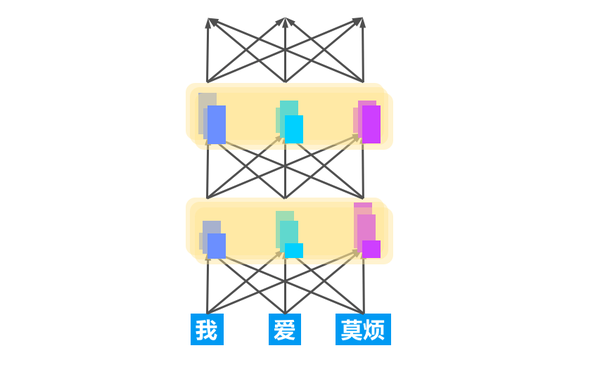
4.7 肩膀上的眺望 - 预训练语言模型
人类知识的传递:写书(知识编码) -> 读书(知识解码)
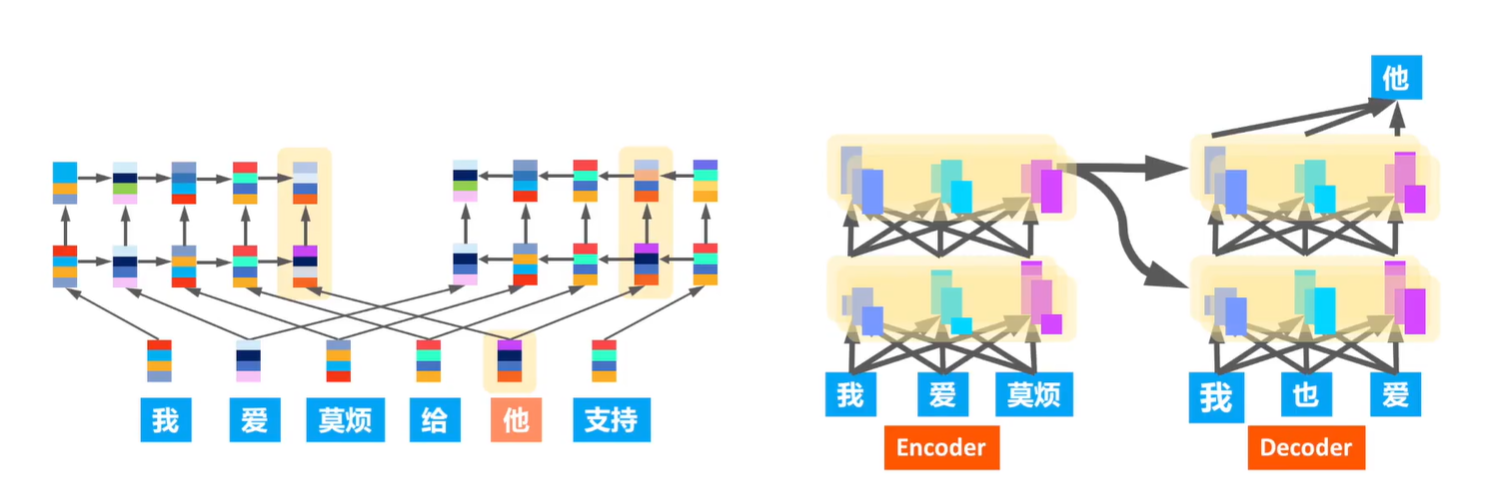
机器知识的传递:模型迁移技术(稍作修改,顺应变化)
强化学习
5.1 什么是强化学习(Reinforcement Learning)
强化学习过程: 一开始什么都不懂 -> 不断尝试学习 -> 找到规律 -> 达到目标
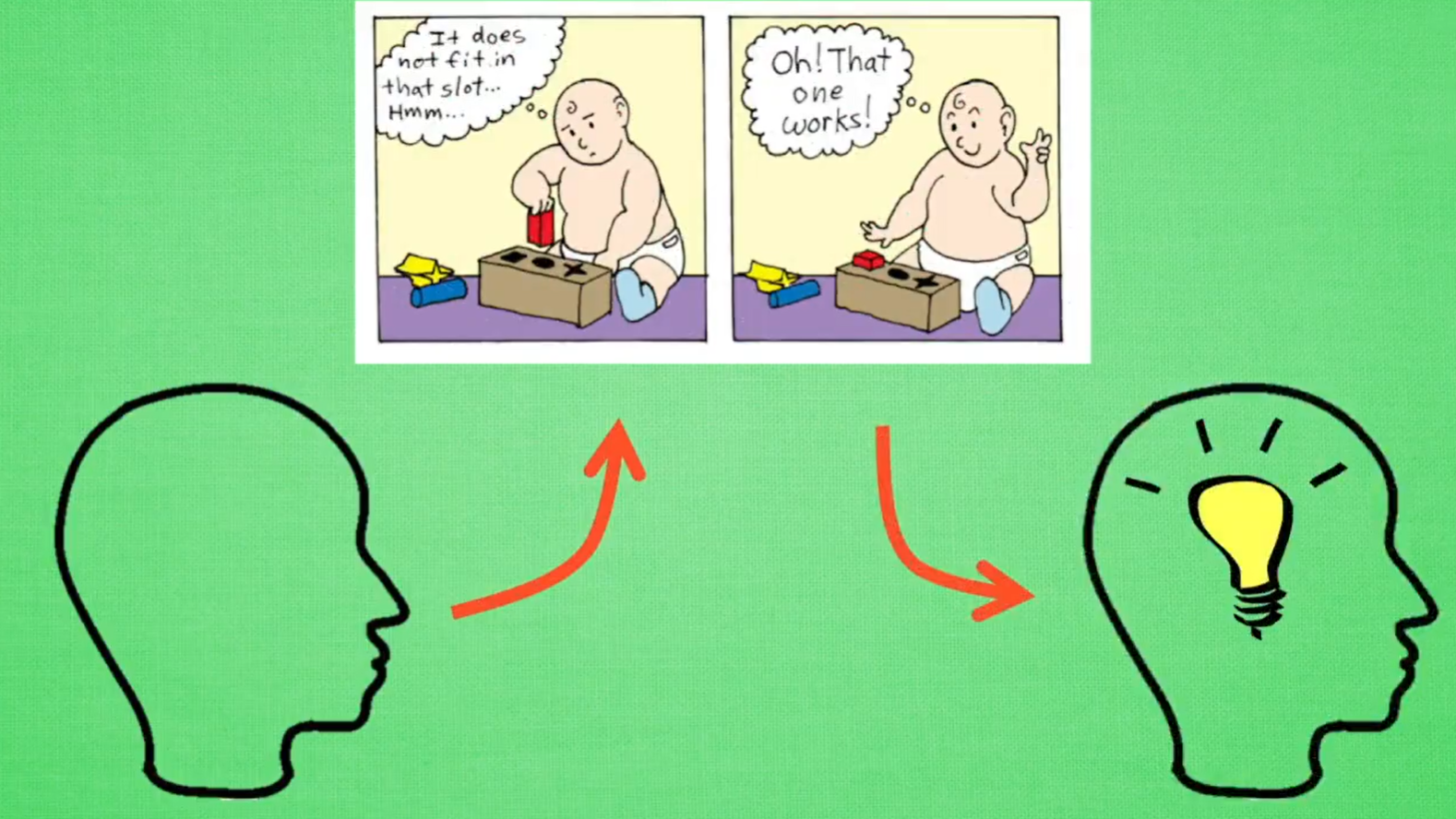
举例:AlphaGo下象棋,AI玩Atari游戏

学习方式:打分,正确行为高分,错误行为低分,继续正确行为,避免错误行为(类似于监督学习中的,正确标签)
- 强化学习:学习过程中获取标签,获取规律,提高得分
- 监督学习:标签一开始就全部给出

强化学习算法

5.2 强化学习方法汇总
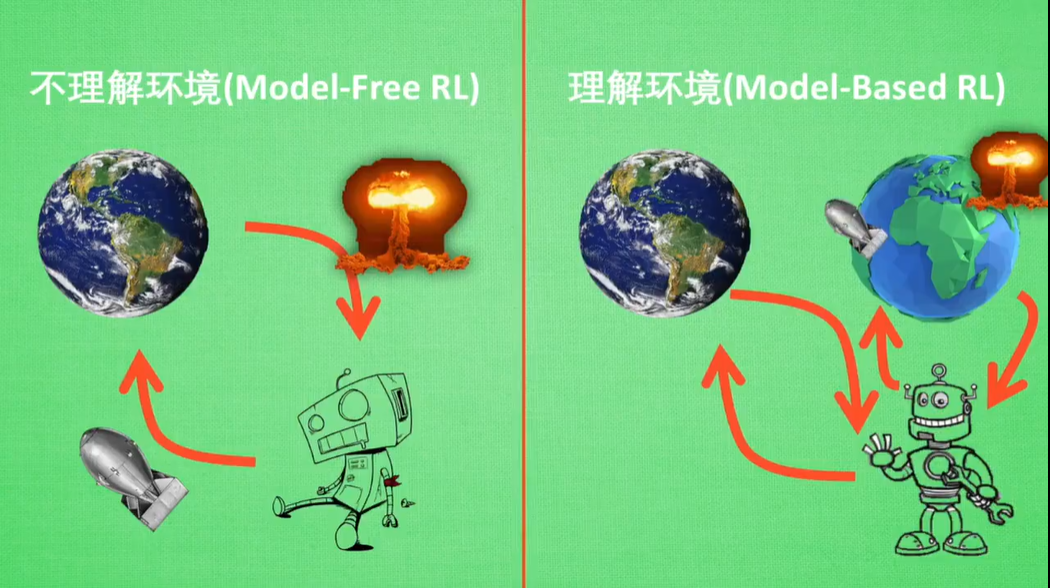
Model-Free RL:不理解环境,向真实环境中投放炸弹,结果把自己也炸死
Model-Based RL:理解自己所处的环境,在虚拟环境中进行试验(为现实世界建模),不影响自己所处的真实环境
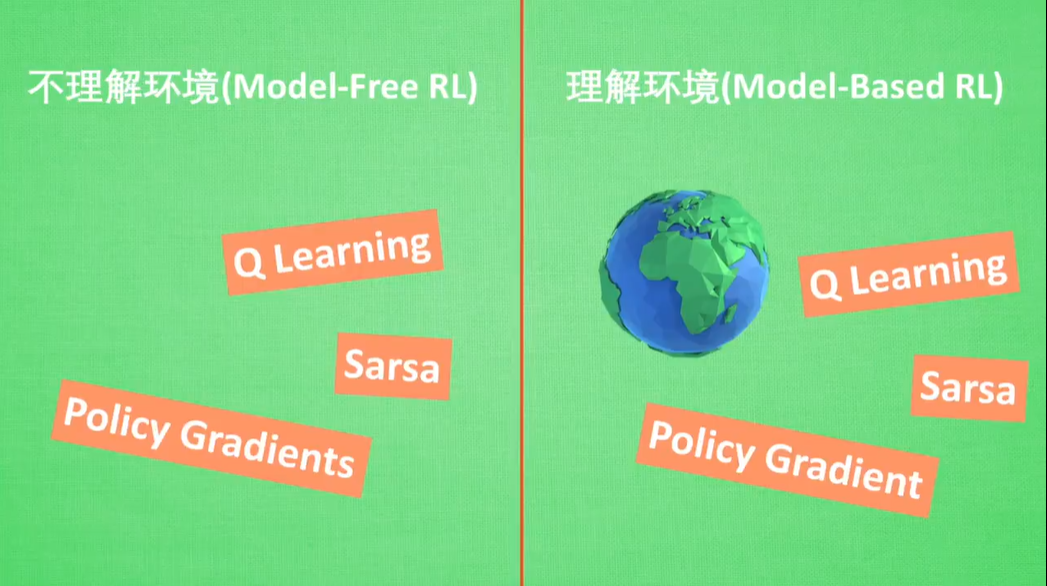
二者使用方法相同,区别在于在在真实环境建模还是虚拟环境建模
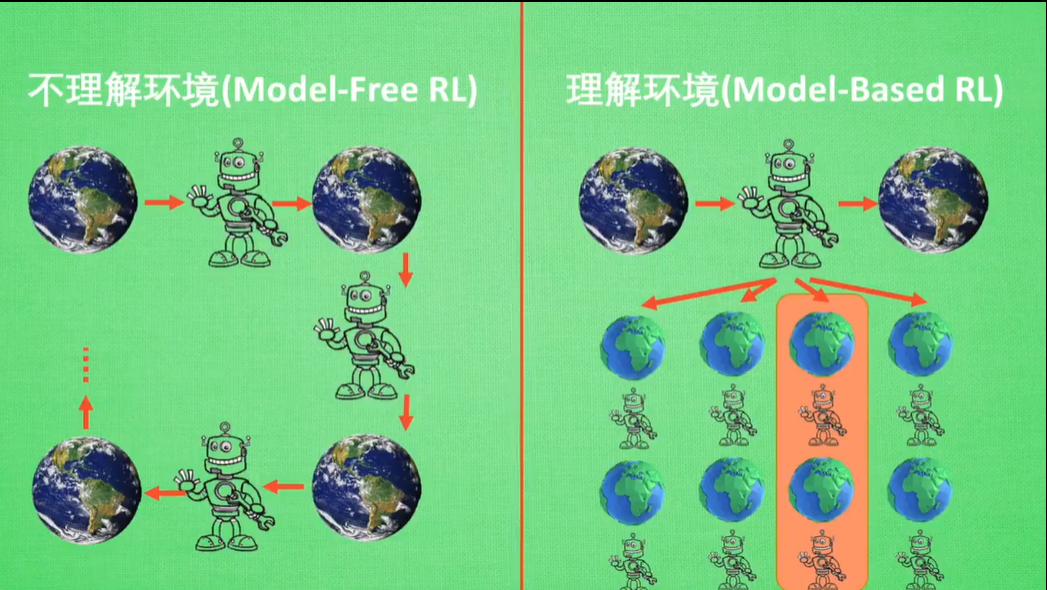
二者最主要的差距就是,Model-Based RL能够通过想象模拟下一步行为,从择优选取最佳行为
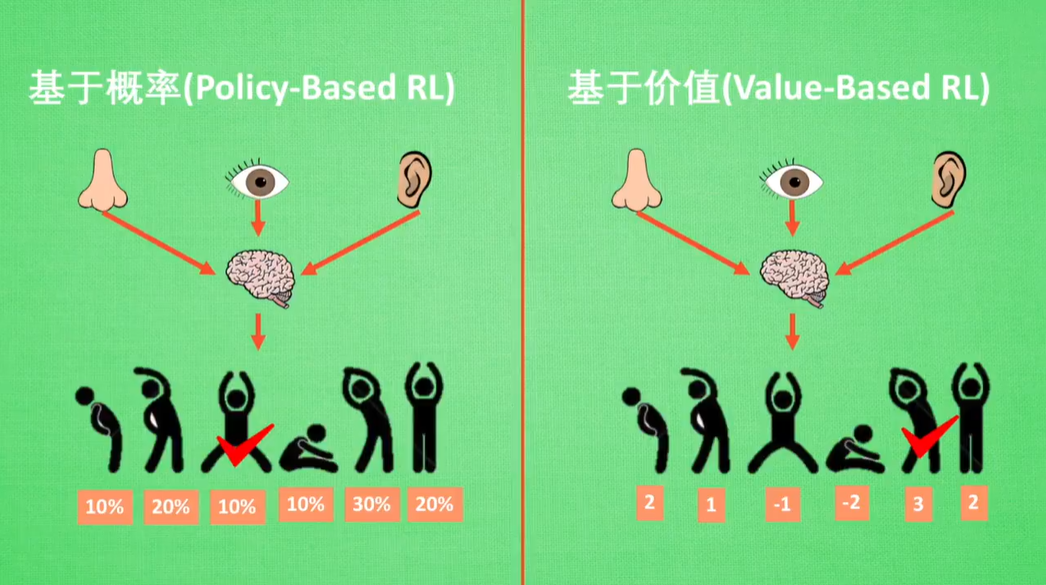
Policy-Based RL:有可能选择低概率行为
Value-Based RL:直接选取价值最高的行为
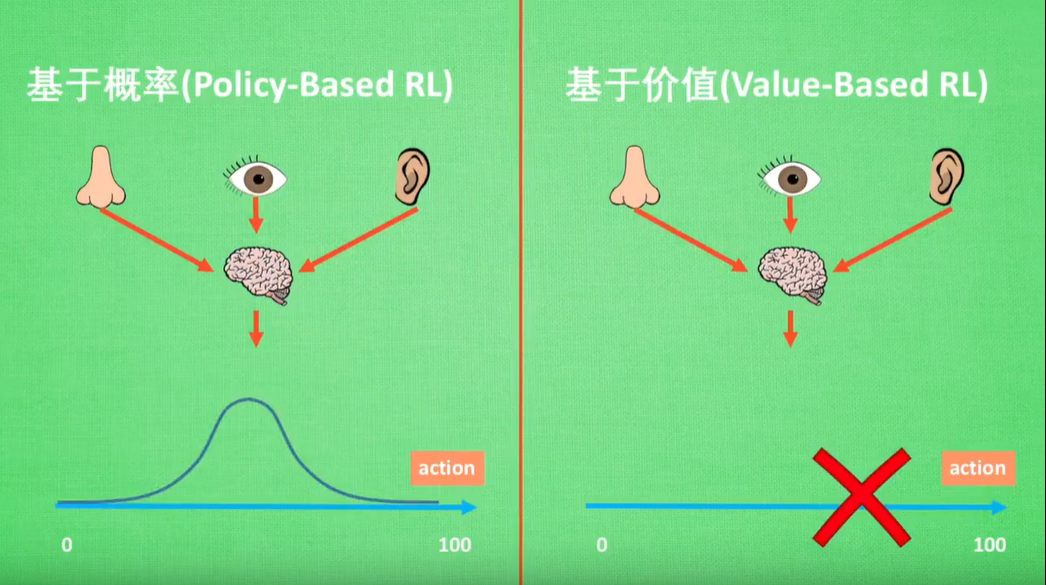
Policy-Based RL:动作连续
Value-Based RL:动作离散
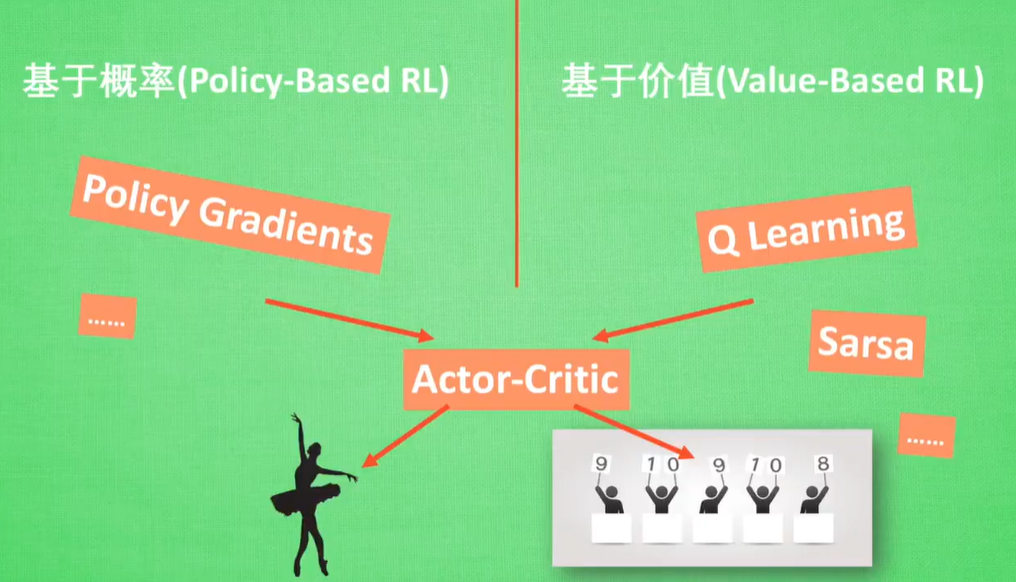
Actor-Critic:Actor基于概率做出动作,Critic基于做出的动作给出动作的下值
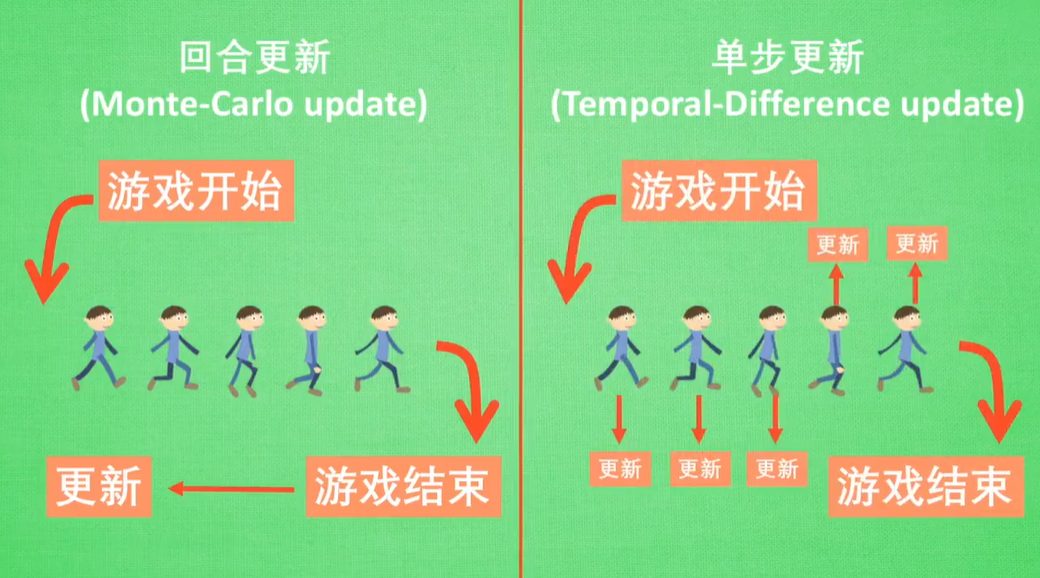
Monte-Carlo update:回合结束再更新
Temporal-Difference update:单步结束就更新

目前单步更新方法更有效率
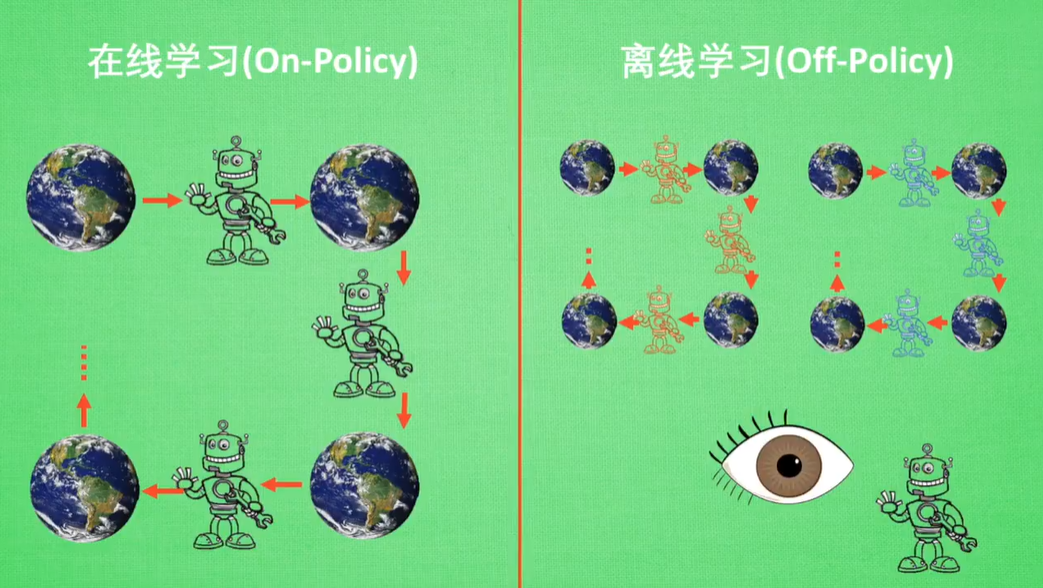
On-Policy:本人在场,边玩儿边学习
Off-Policy:自己玩儿或看着别人玩儿,学习自己或别人的过往经历

On-Policy:Sarsa -> Sarsa lambda
Off-Policy:Q Learning -> Deep-Q-Learning
5.3 Q Learning

根据奖励值的大小选择下一步的行为
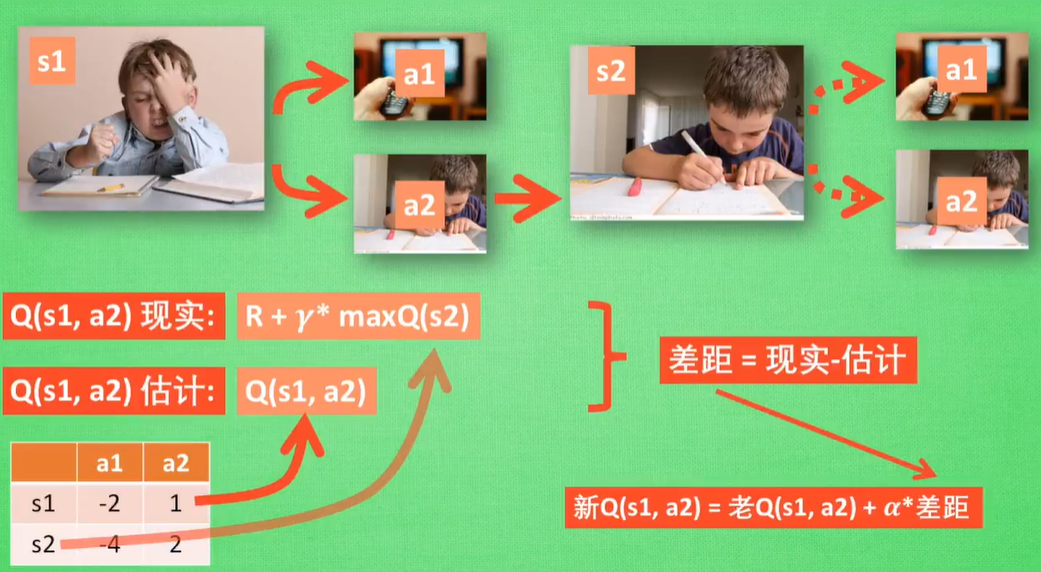
根据 Q 表的估计, 因为在 s1 中, a2 的值比较大, 通过之前的决策方法, 我们在 s1 采取了 a2, 并到达 s2, 这时我们开始更新用于决策的 Q 表, 接着我们并没有在实际中采取任何行为, 而是再想象自己在 s2 上采取了每种行为, 分别看看两种行为哪一个的 Q 值大, 比如说 Q(s2, a2) 的值比 Q(s2, a1) 的大, 所以我们把大的 Q(s2, a2) 乘上一个衰减值 gamma (比如是0.9) 并加上到达s2时所获取的奖励 R (这里还没有获取到我们的棒棒糖, 所以奖励为 0), 因为会获取实实在在的奖励 R , 我们将这个作为我现实中 Q(s1, a2) 的值, 但是我们之前是根据 Q 表估计 Q(s1, a2) 的值. 所以有了现实和估计值, 我们就能更新Q(s1, a2) , 根据 估计与现实的差距, 将这个差距乘以一个学习效率 alpha 累加上老的 Q(s1, a2) 的值 变成新的值. 但时刻记住, 我们虽然用 maxQ(s2) 估算了一下 s2 状态, 但还没有在 s2 做出任何的行为, s2 的行为决策要等到更新完了以后再重新另外做. 这就是 off-policy 的 Q learning 是如何决策和学习优化决策的过程.

ε-greedy=0.9,90%概率选择Q表的最优值选择行为,10%概率随机选择行为
0<α<1,表示随机效率,表示这一次的误差有多少需要被学习
0<γ<1,表示未来奖励的衰减值

距离当前状态越远的奖励衰减越严重
γ=1,未来的奖励没有任何的衰减
γ=0,表示未来没有奖励,即只在乎最近的最大奖励
0<γ<1,表示不仅仅看到眼前的利益,对远处的价值也有所评判
5.4 Sarsa
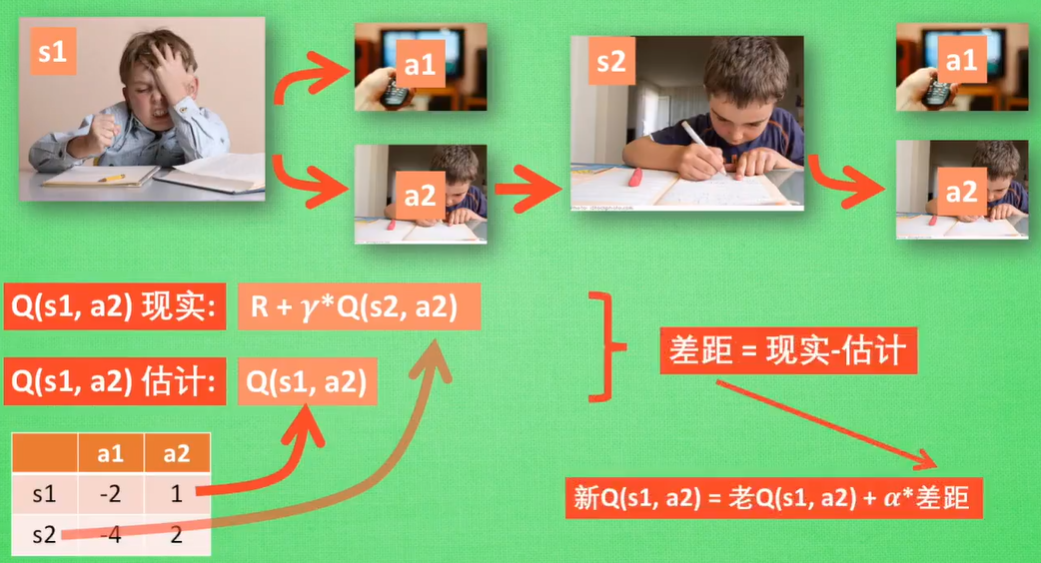
Q Learning只是估计下一步的奖励值,不一定实践
Sarsa则是说到做到,其余跟Q Learning一样

Q-Learning:说道不一定做到,Off-Policy
Sarsa:说道做到,On-Policy
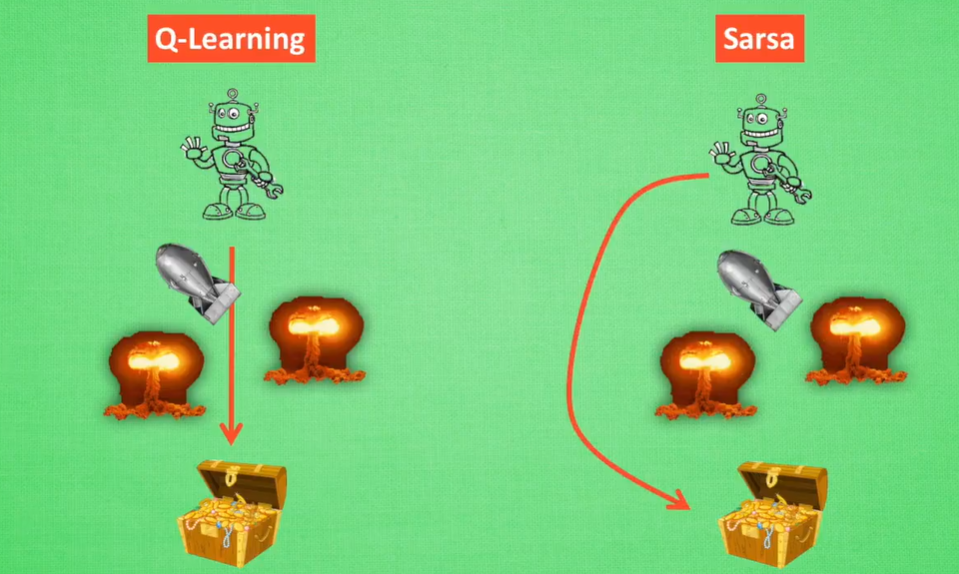
Q-Learning:永远会选择捷径
Sarsa:最安全的道路
5.5 Sarsa (lambda)
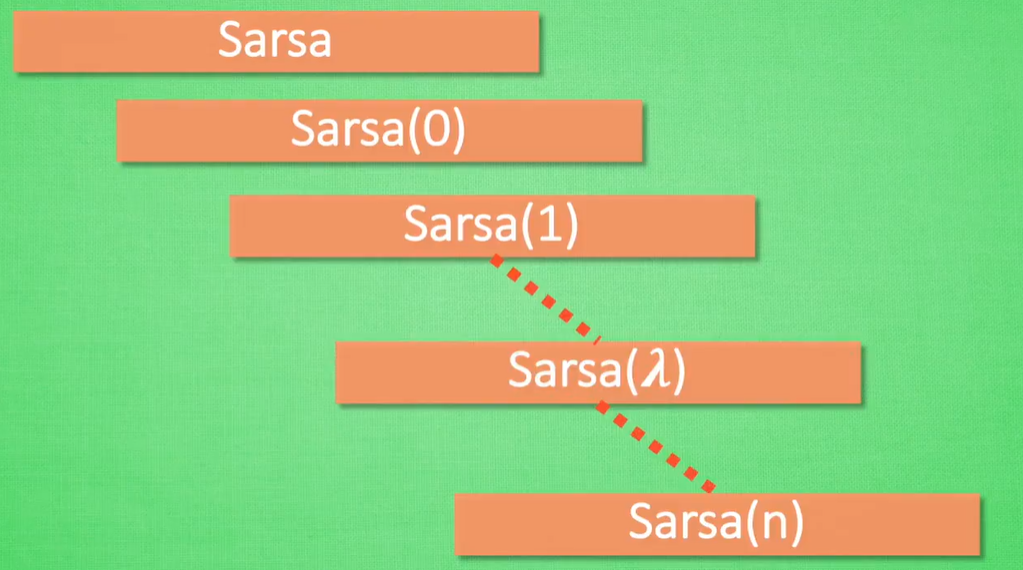
Sarsa(0),单步更新,每走一步更新一次行为准则
Sarsa(1),走完一步,再走一步,再更新
Sarsa(n),这回合走了n步,再更新
Sarsa(λ),设置该回合要走的步数
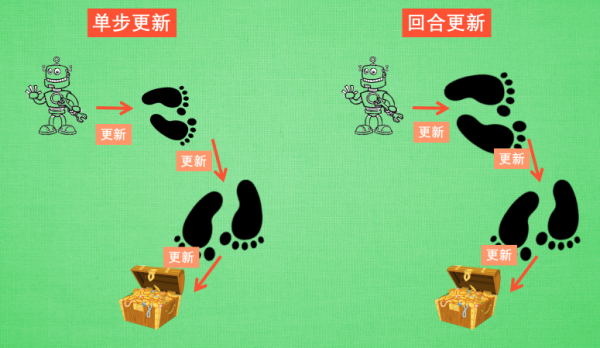
单步更新:直到获取宝藏,才为获取宝藏的上一步更新
回合更新:回合结束之后,对本回合所经历的所有步都更新
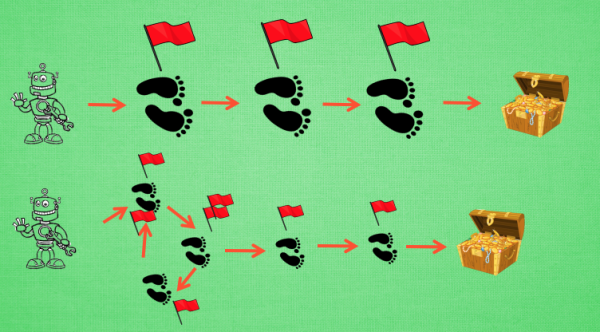
这种情况下回合更新就会很没有效率
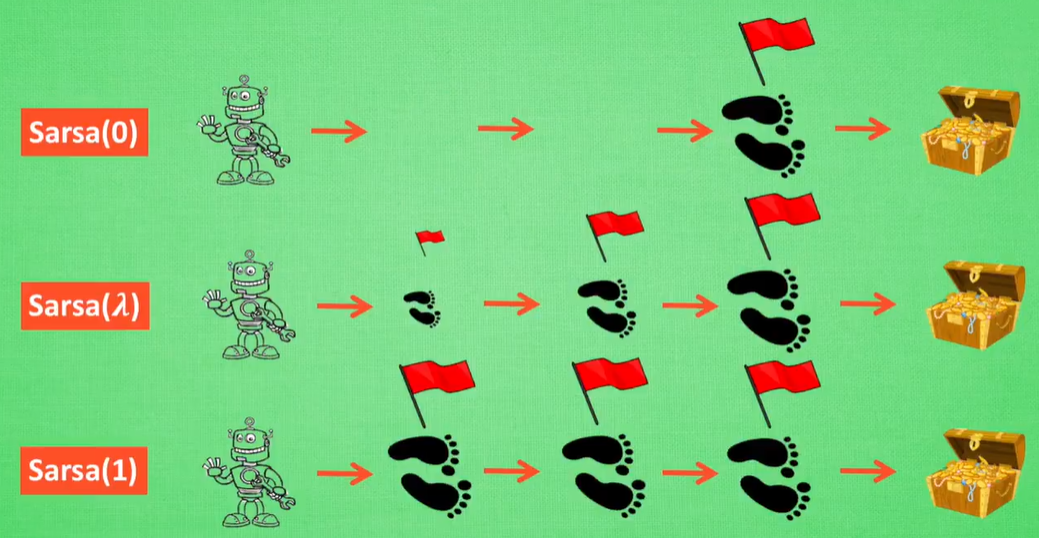
λ=0,表示Sarsa单步更新
λ=1,表示回合更新
0<λ<1,取值越大,距离宝藏越近的步,更新力度越大
5.6 DQN(Deep Q Network)
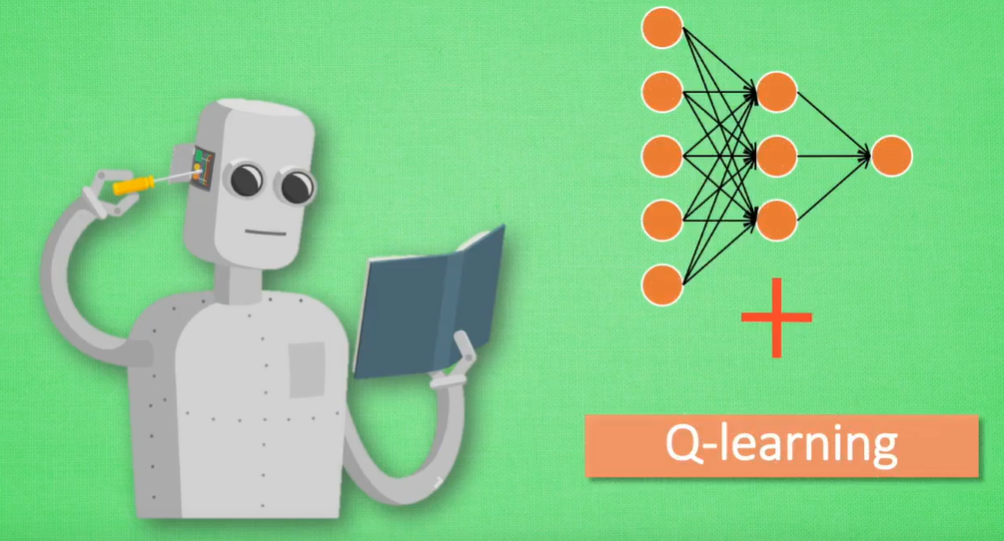
DQN:神经网络+Q-Learning

表格存储状态太复杂,且计算机装不下,搜索也是很耗时的事情
方法一:状态和动作 -> 神经网络 -> 生成Q值
方法二:状态 -> 神经网络 -> 各种可行的值
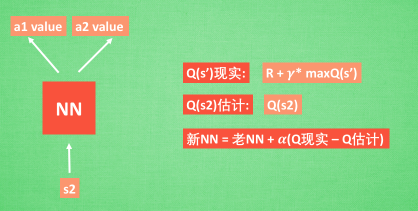
接下来我们基于第二种神经网络来分析, 我们知道, 神经网络是要被训练才能预测出准确的值. 那在强化学习中, 神经网络是如何被训练的呢? 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替. 同样我们还需要一个 Q 估计 来实现神经网络的更新. 所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距. 我们整理一下.
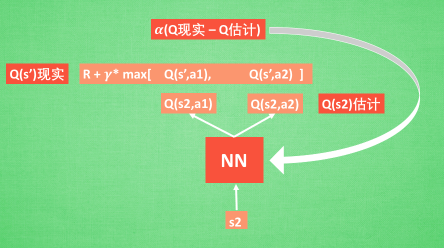
我们通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward. 而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s' 的估计. 最后再通过刚刚所说的算法更新神经网络中的参数.

Experience replay,DQN每次更新的时候,随机抽取一些以往的经历进行学习
Fixd Q-targets,使用两个结构相同但参数不同的神经网络,预测 Q 估计 的神经网络具备最新的参数,而预测 Q 现实 的神经网络使用的参数则是很久以前的。
5.7 Policy Gradients
通过奖惩机制,决定下一次选择某一行为的可能性是增大还是减小
5.8 Actor Critic
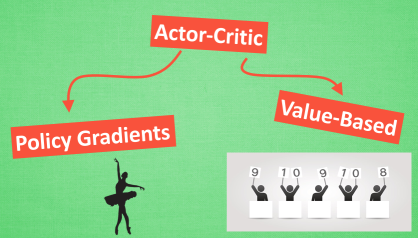
Actor-Critc,Policy Gradients + Value-Based ( Q-Learning)

Actor需要奖惩机制来选择行为,而Critic学习这种奖惩机制,来指导Actor的行为
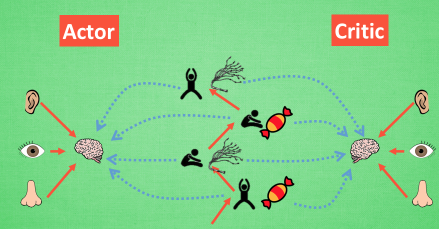
Actor-Critic 每次都是在连续的状态中更新参数,因此看待问题比较片面

DDPG的引入,解决了连续预测上学不到其他东西的问题
5.9 DDPG (Deep Deterministic Policy Gradients)
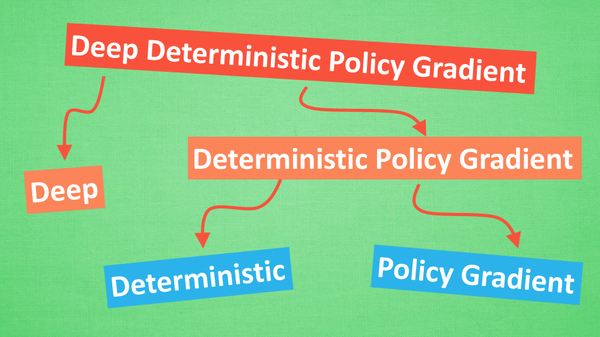
DDPG的拆解
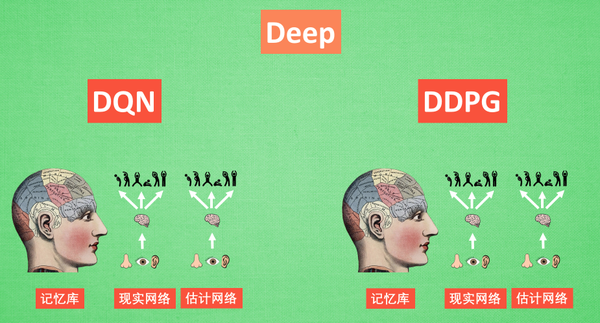
Deep,更深层次的DQN
DDPG的网络形式要比DQN更加复杂
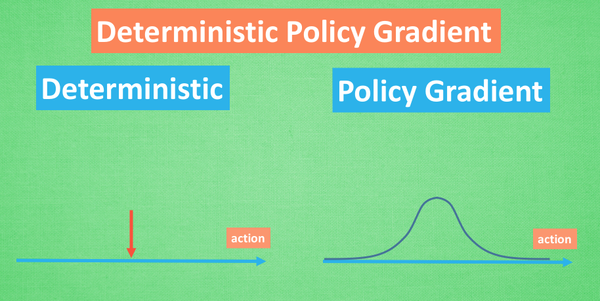
Deterministic,改变了输出动作的过程,只在连续变量中输出一个动作值
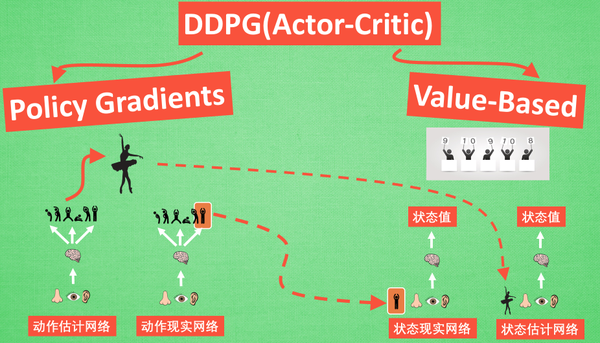
Policy Gradients,动作估计网络 + 动作现实网络
- 估计网络输出实时动作,供actor在现实中实行
- 现实网络用来更新Value-Based
Value-Based,状态现实网络 + 状态估计网络
- 状态现实网络用动作现实网络的动作 + 状态的观测值进行分析
- 状态估计网络用Actor施加的动作当做输入
5.10 A3C (Asynchronous Advantage Actor-Critic)
平行宇宙
多核训练,提升效率
5.11 AlphaGo Zero 为什么更厉害?
AlphaGo

蒙特卡洛树搜索 + 深度搜索
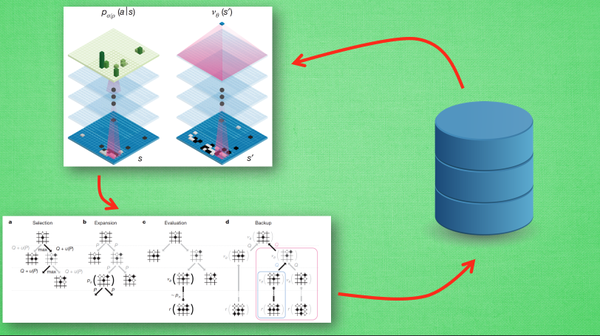
神经网络:一个网络基于当前状态给出下一步的动作,一个神经网络用来评估当前状态是否有利
AlphaGo Zero

无师自通
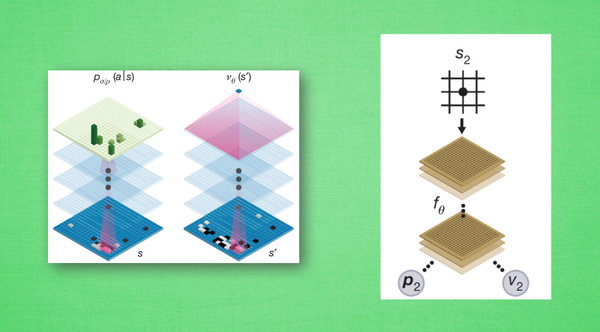
两套神经网络融合为一个神经网络系统

使用TPU训练
进化算法
6.1 遗传算法(Genetic Algorithm)

遗传算法:重组+变异(翻转标签)
6.2 进化策略(Evolution Strategy)
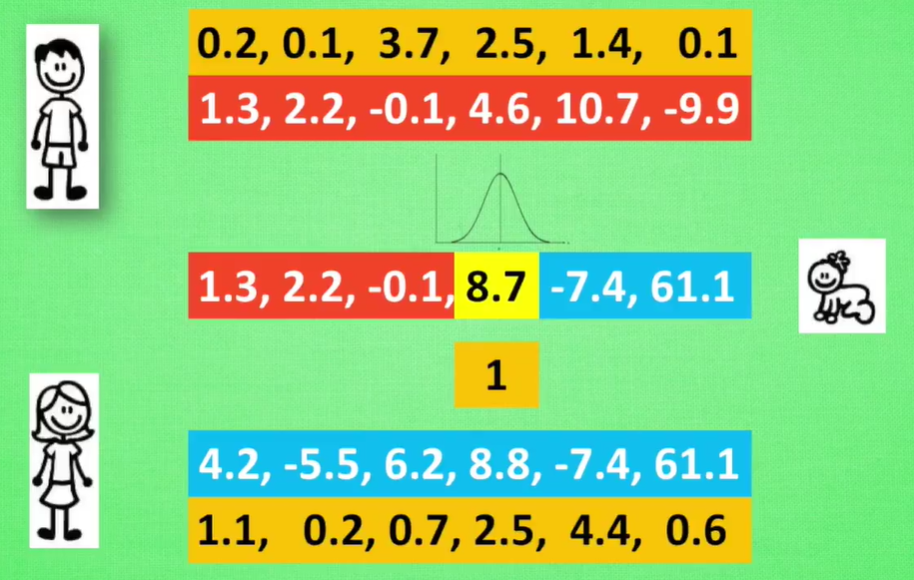
进化策略:DNA通过实数表示,引入变异强度,能够遗传
6.3 神经网络进化(Neuro - Evolution)
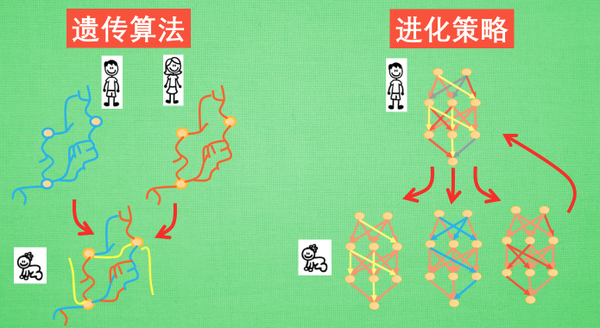
遗传算法:通过父母神经网络的交叉配对,形成新的神经网络,再经过变异,获取新的能力,再放入现实,经过适者生存的法则
进化策略:由固定结构的神经网络,生成很多结构相同,联结强度稍稍不同的网络结构,下一代的神经网络是所有网络综合体,好宝宝的联结占有更多的比例
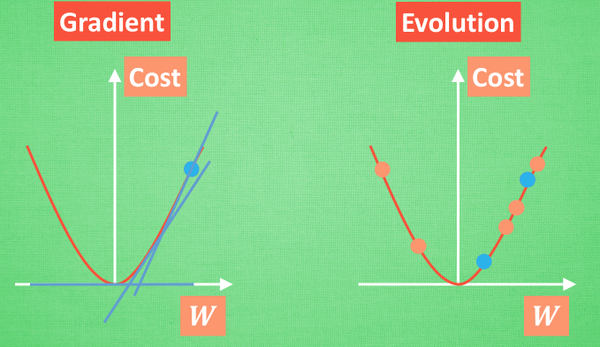
用原始的点创造出很多新的点,再通过新的点确定下一代的起点,能够有效避免局部最优
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号