路飞学城IT_Python爬虫第二章 Requests模块基础
路飞学城IT_Python爬虫第二章 Requests模块基础
案例2.1 爬取搜狗搜索结果
课程视频链接:https://www.bilibili.com/video/BV1Yh411o7Sz/?p=7
UA检测:服务器会根据访问请求的User-Agent字段判断,访问自己的是什么类型的电脑和什么类型的浏览器。有的服务器会拒绝来自爬虫的访问请求
UA伪装:在调用get方法时把User-Agent字段伪装成浏览器访问时的字段,进而从服务器获取HTML数据
当需要动态选择爬取的URL链接时,可以通过带参调用的方式把信息添加到URL中
"""
实战案例2.1
任务目标:根据输入的关键词,爬取该关键词通过搜狗引擎搜索得到的结果网页
知识点:带参调用request.get() UA检测和UA伪装
"""
import requests
if __name__ == "__main__":
# UA伪装:将浏览器对应的User-Agent封装到字典中
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.83 Safari/537.36 "
}
baseurl = "https://www.sogou.com/web?"
keyword = input("请输入要查找的词汇:")
param = { # 以字典的形式存储查询的关键字
'query': keyword
}
# 以带参数的方式调用get方法
response = requests.get(baseurl, params=param, headers=headers)
print(response.text)
案例2.2 破解百度翻译
课程视频链接:https://www.bilibili.com/video/BV1Yh411o7Sz/?p=8
抓包分析:通过分析向百度翻译网页输入单词时候产生的XHR信息,在Network/Headers中找到Request URL是https://fanyi.baidu.com/sug,Request Method是POST,Response返回的Contetnt-Type是application/json
通过requests.post()向服务器发送请求,并通过response.json()得到返回的字典对象
"""
实战案例2.2
任务目标:根据输入的关键词,爬取百度翻译的结果
知识点:抓包分析 带参调用request.post() 存储json文件
"""
import json
import requests
if __name__ == "__main__":
# 1.制定url
post_url = 'https://fanyi.baidu.com/sug'
kw = input("请输入要翻译的单词:")
# 2.以字典的形式存储要翻译的单词
data = {
'kw': kw
}
# 3.UA伪装
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.83 Safari/537.36 "
}
# 4.请求发送
response = requests.post(url=post_url, data=data, headers=headers)
# 5.获取相应数据 (只有确认返回类型是json才能调用json方法 返回字典对象)
dic_obj = response.json()
print(dic_obj)
# 6.持久化存储
fp = open('./{}.json'.format(kw), 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
print("爬取结束")
案例2.3 爬取豆瓣电影排行榜
课程视频链接:https://www.bilibili.com/video/BV1Yh411o7Sz/?p=9
抓包分析:在Network/Headers中找到Request URL是https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20,Request Method是GET,Response返回的Contetnt-Type是application/json
"""
实战案例2.3
任务目标:爬取豆瓣喜剧类型电影排行榜
知识点:抓包分析 带参调用request.get() 存储json文件
"""
import json
import requests
if __name__ == "__main__":
# 1.制定url
url = "https://movie.douban.com/j/chart/top_list"
# Request URL中的参数信息,可以通过字典的方式写入param中,并作为get方法的参数使用
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": "0", # 从第几部电影中取
"limit": "20" # 一次取出的电影个数
}
# 2.UA伪装
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.83 Safari/537.36 "
}
# 3.请求发送
response = requests.get(url=url, params=param, headers=headers)
# 4.获取数据
list_data = response.json()
# 5.持久化存储
fp = open('./豆瓣电影排行榜.json', "w", encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print("爬取结束")
案例2.4 爬取肯德基餐厅查询结果
课程视频链接:https://www.bilibili.com/video/BV1Yh411o7Sz/?p=10
抓包分析:在Network/Headers中找到Request URL是http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword,Request Method是POST,Response返回的Contetnt-Type是txt/plain
"""
实战案例2.4
任务目标:根据输入的关键词,爬取肯德基餐厅查询的结果
知识点:抓包分析 带参调用request.post()
"""
import json
import requests
if __name__ == "__main__":
# 1.制定url
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
kw = input("请输入餐厅关键字:")
# 2.以字典的形式存储关键字
data = {
"cname": "",
"pid": "",
"keyword": kw,
"pageIndex": '1',
"pageSize": '10'
}
# 3.UA伪装
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.83 Safari/537.36 "
}
# 4.请求发送
response = requests.post(url=post_url, data=data, headers=headers)
# 5.获取相应数据 (只有确认返回类型是json才能调用json方法 返回字典对象)
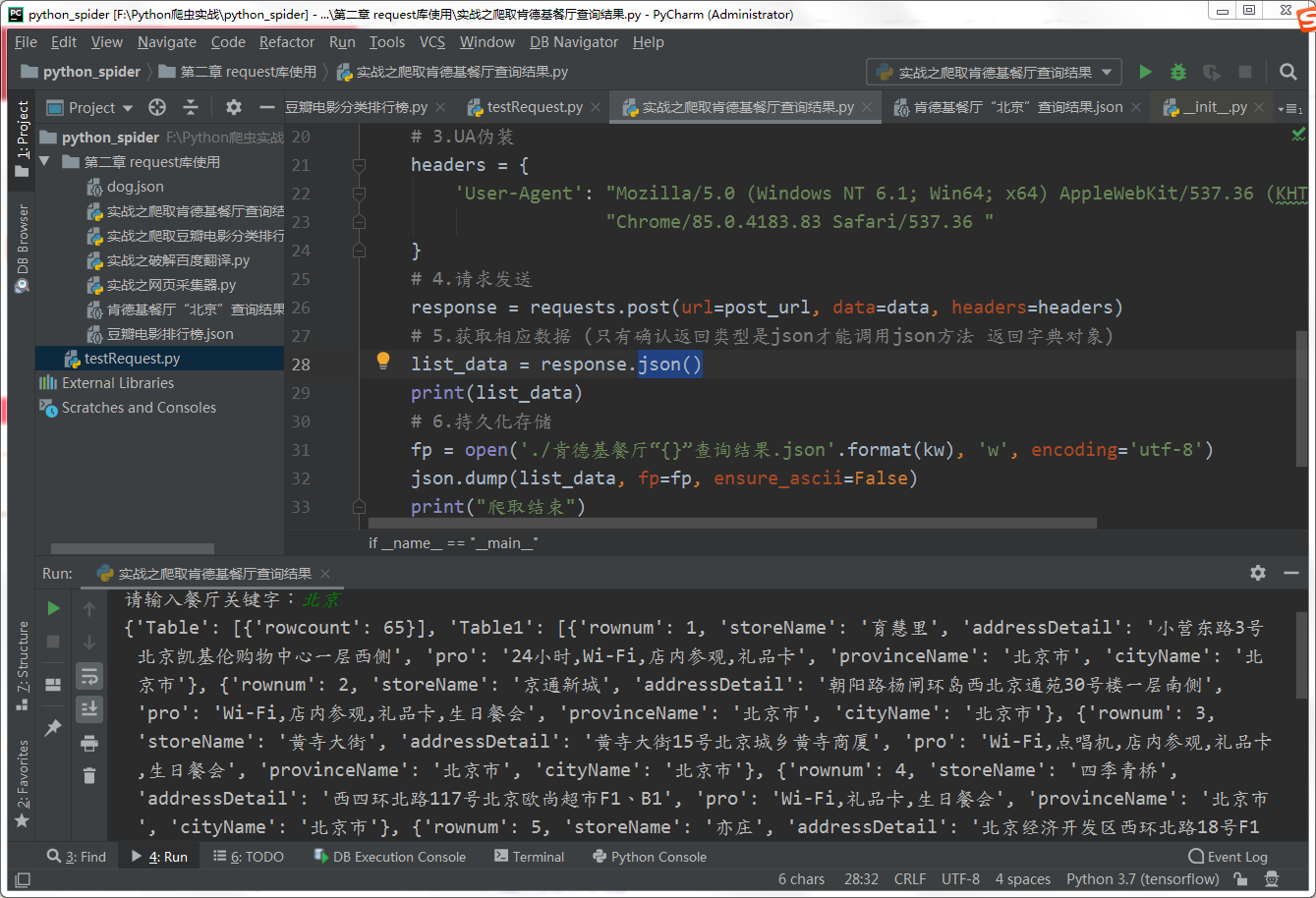
list_data = response.json()
print(list_data)
# 6.持久化存储
fp = open('./肯德基餐厅“{}”查询结果.json'.format(kw), 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print("爬取结束")
疑问:为什么返回txt类型却不能调用response的text方法,只能调用json?
案例2.5 爬取药监总局相关数据
课程视频链接:https://www.bilibili.com/video/BV1Yh411o7Sz/?p=11
抓包分析:Response返回的json信息中没有直接出现想要爬取的,具有各个企业详细信息的URL,但是有每个企业的id。打开每个企业的详情页,发现URL除了id不同,其他部分都是一样的。
再继续通过抓包分析详情页,发现内容也是动态加载出来的,都是向http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById发送了POST请求,data参数中带有企业特有的id信息,从而获得结果的。
所以先在首页POST获得所有企业的id,然后根据id发送POST请求得到每个企业的详情页
"""
实战案例2.5
任务目标:根据输入的数字,爬取相应页数的化妆品公司信息
知识点:抓包分析 两次追踪动态加载的内容
"""
import json
import requests
if __name__ == "__main__":
# 1.UA伪装
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.83 Safari/537.36 "
}
# 2.总的查询页url准备
base_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
n = eval(input("请输入想要查询的总页数(共355页):"))
for i in range(1, n+1):
data = {
"on": "true",
"page": "1",
"pageSize": "15",
"productName": '',
'conditionType': '1',
'applyname': ''
}
# 3.拿到包含企业id的json信息
response = requests.post(base_url, data=data, headers=headers)
json_ids = response.json()
# 4.从字典中提取企业的id到list中
id_list = []
for dic in json_ids['list']:
id_list.append(dic['ID'])
# 5.遍历id获得所有详情页
query_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
all_data_list = []
for id in id_list:
data = {
'id': id
}
detail_json = requests.post(query_url, data=data, headers=headers).json()
all_data_list.append(detail_json)
# 6.持久化存储
fp = open('./2.5alldata.js', 'w', encoding='utf-8')
json.dump(all_data_list, fp=fp, ensure_ascii=False)
print("爬取完毕")
总结
- 在爬取任何网页之间,首先要进行抓包分析。判断需要爬取的内容是静态的还是动态的,如果是动态的,是通过什么类型的请求(POST/GET)向什么URL得到的什么类型(TXT/JSON)的response,传递了哪些参数。然后使用request库模拟这一过程
- 因为有的服务器会进行UA检测并拒绝爬虫的访问,所以请求之前要进行UA伪装
- 得到结果后根据结果的类型和特点做相应的处理,并保存在本地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号